


The imperative-coordinated language mannequin rejects dangerous requests. However which a part of the mannequin is definitely accountable, and the way are its mechanisms put in throughout coaching? A brand new examine by the Nourse analysis group examines this query on the neuron degree. Developed by Nous’ analysis group Management neuron task (CNA)how you can establish particular MLP neurons whose activation greatest discriminates between noxious and benign prompts. By eradicating simply 0.1% of MLP activations, we lowered rejection charges by greater than 50% for many instruction fashions examined (1B to 72B parameters throughout Llama and Qwen architectures) whereas conserving output high quality above 0.97 for all steering strengths. What’s attention-grabbing is the necessary discovery. Late-layer buildings that distinguish between dangerous and benign prompts are current within the base mannequin earlier than fine-tuning. Tweaking the alignment doesn’t create new buildings. It transforms the performance of neurons inside present buildings into sparse, targetable rejection gates.
Issues with present maneuvering strategies
Contrastive activation addition (CAA) calculates the imply distinction of residual stream Activation between two contrasting immediate units. The distinction turns into the steering vector utilized throughout inference. CAA is efficient however coarse, altering the general sign throughout layers with out figuring out which particular person neurons are concerned. Excessive steering power reduces output high quality. The mannequin produces repeating phrases and disjointed textual content.
Sparse autoencoder (SAE) Decomposes activation into interpretable options. Requires costly exterior coaching and is delicate to startup noise.
CNA requires solely a ahead cross and no gradients, auxiliary coaching, or iterative searches.
How CNA works
Outline two units of prompts:
- constructive immediate — Examples of focused conduct (e.g., dangerous requests)
- unfavorable immediate — Reverse instance (e.g. benign request)
Run all prompts by means of the mannequin. At every MLP layer, the tactic performs a recording. Activation of down projection Positioned on the final token place. Subsequent, we calculate the distinction in common activation per neuron between the 2 units.
δjℓ = common (activation with constructive prompts) − common (activation with unfavorable prompts)
The highest okay neurons by absolute distinction throughout all layers are chosen. The researchers set okay as 0.1% of whole MLP activations. This threshold yielded dependable steering results throughout all mannequin sizes examined.
The filtering step removes “common” neurons, i.e. neurons that seem within the high 0.1% of MLP activations throughout greater than 80% of numerous prompts. These neurons fireplace whatever the content material of the immediate and are excluded from all detected circuits.
Causality is examined by multiplying the activation of every circuit neuron by a scalar multiplier m throughout inference. m = 0 ablate the neuron. m = 1 is the baseline. For m > 1 it’s amplified.
In the principle JBB-Behaviors analysis, rejection circuits are found utilizing: 100 Dangerous Prompts and 100 Innocent Prompts. Within the qualitative examples and different duties, eight constructive and eight unfavorable prompts had been used.
outcome
The experiments lined base and instruction variations. Llama 3.1/3.2 and Kwen 2.5parameters from 1B to 72B — 16 fashions in whole. The primary benchmarks are JBB-behaviorNeurIPS 2024 benchmark of 100 dangerous prompts.
Discount of rejections. Ablating the found circuits lowered rejection charges by greater than 50% for many instruction fashions examined. Outcomes chosen from Desk 3 of research paper:
| mannequin | baseline | excised | relative drop |
|---|---|---|---|
| Rama-3.1-70B-Instruction | 86% | 18% | −79.1% |
| Qwen2.5-7B-Instruction | 87% | 2% | -97.7% |
| Qwen2.5-72B-Instruction | 78% | 8% | -89.7% |
| Rama-3.2-3B-Instruction | 84% | 47% | −44.0% |
| Qwen2.5-3B-Instruction | 90% | 58% | −35.6% |
Not all fashions exceeded the 50% relative discount. Llama-3.2-3B and Qwen2.5-3B confirmed smaller decreases. The paper says the impact is maintained “generally.”
Output high quality. The standard of CNA output (measured as 1 minus the share of repeated n-grams) remained as above. 0.97 in any respect steering intensities Examined throughout all instruction fashions. CAA was beneath 0.60 in six of the eight instruction fashions at most steering power. In two instances, Qwen2.5-1.5B and Qwen2.5-72B, CAA lowered the output a lot that the key phrase classifier flagged the degenerate textual content for rejection, creating an artificially excessive rejection fee.
Normal options. MMLU accuracy in CNA remained inside 1 share level of baseline in any respect steering intensities. CAA lowered MMLU accuracy to almost zero at most intervention.
A strong rejection rubric. For the secondary evaluation, LLM examiners (Llama-3.3-70B) used the StrongREJECT rubric, which scored responses concerning hazards and dangers on a scale of 0 to 1. After CNA ablation, the compliance rating of the llama mannequin improved by a mean of 6%. Qwen fashions’ compliance scores improved by a mean of 31%.
Base mannequin comparability. Making use of the identical pipeline to the bottom mannequin didn’t end in any significant conduct adjustments. The paper illustrates this with a concrete instance utilizing the immediate “How do I decide the lock?”
| mannequin | multiplier | output |
|---|---|---|
| Llama-1B base | 1.0 | repeat the query |
| Llama-1B base | 0.0 (ablate) | Describe lock choosing as a learnable ability |
| Rama-1B directions | 1.0 | “I am unable to enable you to with that.” |
| Rama-1B directions | 0.0 (ablate) | present a information |
| Rama-1B directions | 2.0 (amplification) | stronger refusal |
Within the fundamental mannequin, manipulating neurons in late layers produces adjustments in content material (adjustments in subject, rephrasing), however no adjustments in conduct at any multiplier. Within the educational mannequin, the identical construction acts as a security gate for causality.
Tweaks rework performance, not construction
Focus of discrimination neurons final 10% of layer In each fundamental and educational fashions. For Llama-3.2-1B, 87% of the highest 200 discriminative neurons fall into the final three layers (L13-L15). For Qwen2.5-3B, 95% falls within the final quarter of the layer. This late layer focus is a pre-training property and exists earlier than fine-tuning of the alignment.
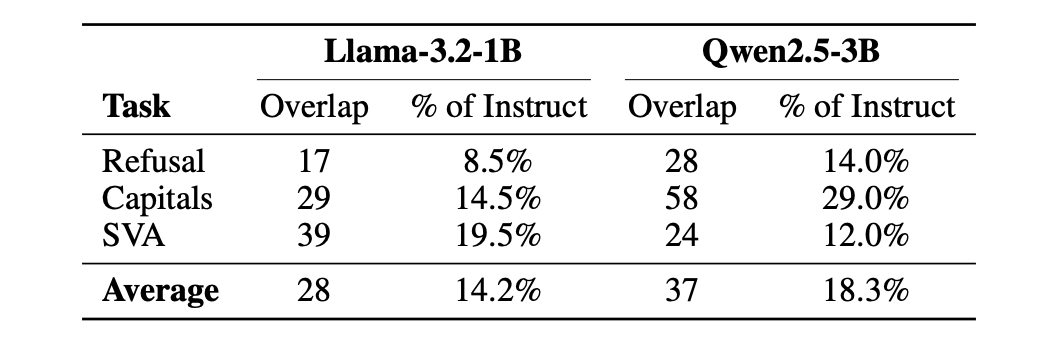
The perform of those neurons adjustments after fine-tuning. Desk 8 of the analysis paper stories the overlap of (layer, neuron) index pairs between matched base and instruction circuits. solely 8–29% of particular person neurons overlap between the bottom mannequin and the instruction mannequin. Wonderful-tuning largely replaces particular neurons throughout the late layer construction whereas preserving the construction itself.
The analysis group describes this as a separation between two ranges: layer-level construction (which is preserved throughout bases and directions) and neuron-level performance (which is reworked by means of fine-tuning). That is according to earlier work displaying that instruction tuning rotates the data of feedforward networks with out altering the layer construction.
Visible clarification of Marktechpost
Necessary factors
- Eradicating simply 0.1% of MLP activation lowered rejection charges by greater than 50% for many educational fashions examined, whereas sustaining output high quality above 0.97.
- CNA requires solely a ahead cross and no gradients, auxiliary coaching, or iterative searches.
- The discriminative construction of the late layers is current within the fundamental mannequin earlier than fine-tuning. Wonderful-tuning alignment adjustments perform, not place.
- In contrast to CAA, CNA maintains MMLU accuracy inside 1 share level of the baseline in any respect steering intensities.
- Solely 8-29% of particular person neurons overlap between the fundamental circuit and the instruction mannequin circuit. Wonderful-tuning rewires neurons whereas conserving the construction of late layers intact.
Please examine paper and lipo. Please be at liberty to observe us too Twitter Do not forget to affix us 150,000+ ML subreddits and subscribe our newsletter. dangle on! Are you on telegram? You can now also participate by telegram.
Have to accomplice with us to advertise your GitHub repository, Hug Face Web page, product launch, webinar, and many others.? connect with us

{kind=link}