


Deep studying, notably in NLP, picture evaluation, and biology, has more and more centered on growing fashions that provide each computational effectivity and sturdy representational energy. The eye mechanism is revolutionary and may now deal with sequence modeling duties higher. Nonetheless, the computational complexity related to these mechanisms will increase quadratically with array size, making them a major bottleneck when managing lengthy context duties corresponding to genomics or pure language processing. Develop into. With the ever-increasing have to course of massive and sophisticated datasets, researchers want to seek out extra environment friendly and scalable options.
The primary problem on this space is to scale back the computational load of consideration mechanisms whereas preserving their expressive energy. Many approaches have tried to handle this drawback by making the eye matrix sparse or by adopting low-rank approximations. Strategies corresponding to Reformer, Routing Transformer, and Linformer have been developed to extend the computational effectivity of consideration mechanisms. Nonetheless, these strategies battle to completely stability computational complexity and expressiveness. Some fashions use these strategies together with dense consideration layers to extend expressiveness whereas sustaining computational feasibility.
A brand new architectural innovation often known as Orchid This was revealed in a research carried out by the College of Waterloo. This revolutionary sequence modeling structure integrates a data-dependent convolution mechanism to beat the restrictions of conventional attention-based fashions. Orchid is designed to deal with the distinctive challenges of sequence modeling, particularly his second-order complexity. By leveraging new data-dependent convolutional layers, Orchid makes use of an adjustable neural community to dynamically regulate the kernel primarily based on enter knowledge, permitting it to effectively deal with sequence lengths as much as 131K. This dynamic convolution ensures environment friendly filtering of lengthy sequences and offers scalability with sublinear complexity.
The core of Orchid lies in a brand new data-dependent convolutional layer. This layer makes use of a tuning neural community to adapt the kernel, vastly enhancing Orchid’s skill to successfully filter lengthy sequences. The conditioning community ensures that the kernel adapts to the enter knowledge and enhances the mannequin’s skill to seize long-range dependencies whereas sustaining computational effectivity. This structure achieves excessive expressiveness and sublinear scalability with O(LlogL) complexity by incorporating gate operations. This permits Orchid to deal with sequence lengths far past the boundaries of dense consideration layers, offering superior efficiency for sequence modeling duties.
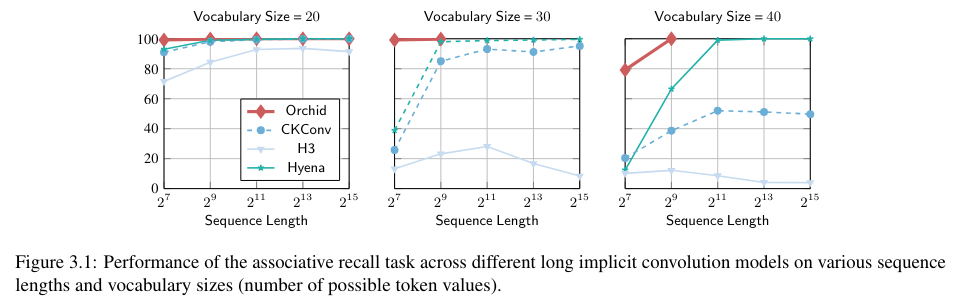
This mannequin performs higher than conventional attention-based fashions corresponding to BERT and Imaginative and prescient Transformers throughout the whole area of small mannequin measurement. In associative recall duties, Orchid persistently achieved better than 99% accuracy with as much as 131K sequences. In comparison with the BERT base, the Orchid-BERT base achieves a 1.0 level enchancment within the GLUE rating regardless of having 30% fewer parameters. Equally, Orchid-BERT-large outperforms his BERT-large in GLUE efficiency whereas lowering the variety of parameters by 25%. These efficiency benchmarks spotlight Orchid’s potential as a flexible mannequin for more and more massive and sophisticated datasets.

In conclusion, Orchid efficiently addresses the computational complexity limitations of conventional consideration mechanisms and offers an revolutionary method to sequence modeling in deep studying. Orchid makes use of data-dependent convolutional layers to successfully tune the kernel primarily based on enter knowledge, attaining sublinear scalability whereas sustaining excessive expressiveness. Orchid units a brand new benchmark in sequence modeling, enabling extra environment friendly deep studying fashions to deal with more and more massive datasets.
Please examine paper. All credit score for this research goes to the researchers of this mission.Do not forget to comply with us twitter.Please be part of us telegram channel, Discord channeland linkedin groupsHmm.
When you like what we do, you will love Newsletter..
Do not forget to affix us 41,000+ ML subreddits
![]()
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in double diploma in supplies from the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic and is consistently researching purposes in areas corresponding to biomaterials and biomedicine. With a powerful background in supplies science, he explores new advances and creates alternatives to contribute.

{kind=link}