


Deploying massive language fashions (LLMs) at scale on Amazon SageMaker AI Inference makes observability a vital pillar of any manufacturing machine studying (ML) technique. In contrast to standard software program that returns deterministic outputs, LLMs generate variable, free-form responses which are troublesome to validate with commonplace metrics. LLM output high quality can change over time as enter distributions shift, and high quality monitoring helps detect these modifications early. For generative AI workloads, observability additionally consists of the mannequin serving infrastructure, the place unpredictable token consumption, GPU reminiscence stress, and latency spikes make capability planning and price management a shifting goal.
A complete observability strategy for LLM inference should tackle two distinct however complementary dimensions: mannequin serving infrastructure (amount) and LLM high quality. Amount monitoring focuses on the operational well being of inference infrastructure, monitoring request throughput and useful resource utilization. These metrics assist detect bottlenecks, right-size compute assets, and management prices. High quality monitoring focuses on the efficiency of the LLMs themselves, evaluating response accuracy, compliance, and consistency over time.
Most groups construct LLM observability in levels. The primary stage establishes visibility into core operational metrics corresponding to latency, errors, and useful resource utilization. These indicators verify the reliability of inference endpoints. The following stage provides LLM high quality via sampling and analysis, which floor points corresponding to mannequin drift, degradation, or surprising habits in generated responses.
With each dimensions in place, you’ll be able to introduce thresholds and automatic alerts that mix infrastructure and high quality indicators. Over time, the follow extends to comparative evaluation throughout fashions and configurations so you’ll be able to repeatedly tune value, efficiency, and output high quality. Amount and high quality metrics are interdependent: an endpoint can seem operationally wholesome whereas producing poor or unsafe responses, or it might ship high-quality outputs whereas operating inefficiently on over-provisioned infrastructure. Manufacturing-grade LLM observability emerges when each dimensions are monitored, correlated, and optimized collectively.
This put up demonstrates a complete observability answer utilizing Amazon Managed Grafana dashboards that gives a holistic view of each high quality and amount for LLMs served on Amazon SageMaker AI endpoints with inference parts.
Workflow structure
For full visibility into LLMs throughout the 2 monitoring dimensions of amount and high quality, we constructed an answer utilizing three core AWS companies, every chosen for a selected function in LLM observability. The next high-level information circulate diagram exhibits the three core parts: Amazon SageMaker AI endpoints with inference parts, Amazon CloudWatch, and Amazon Managed Grafana.
Amazon SageMaker AI Inference Parts function the mannequin internet hosting layer. A single SageMaker AI endpoint can host a number of inference parts, every operating a special LLM (for instance, gpt-oss-20b and Qwen2.5-7B-Instruct as proven within the previous structure). Inference parts allow you to deploy, scale, and handle a number of fashions on shared infrastructure whereas conserving per-model isolation for visitors routing, scaling insurance policies, and metric attribution.
Amazon CloudWatch serves because the centralized metrics retailer. It receives two distinct streams of information from every inference element: enhanced metrics and customized high quality metrics. Enhanced metrics are printed routinely by SageMaker AI once you allow them on the endpoint configuration. The metrics embrace instance-level, container-level, and per-GPU dimensions, providing you with granular visibility into invocation counts, latency, error charges, and GPU/CPU utilization per mannequin. Enhanced metrics are logged to the /aws/sagemaker/InferenceComponents/<model-name> namespace (for instance, /aws/sagemaker/InferenceComponents/gpt-oss-20b). For particulars, see the Amazon SageMaker AI enhanced metrics documentation and the improved metrics deep-dive weblog put up.
Customized high quality metrics seize LLM output high quality, corresponding to composite high quality scores, security scores, and analysis latency. These are printed to a separate user-configured CloudWatch namespace at /aws/sagemaker/inference-quality/<model-name>, which retains high quality indicators cleanly separated from operational metrics. The next desk summarizes the 2 CloudWatch metric namespaces.
| CloudWatch Metric Namespace | Captures | Goal |
| /aws/sagemaker/InferenceComponents/ | Enhanced metrics: instance-level, container-level, and per-GPU dimensions | Supplies granular visibility into invocation counts, latency, error charges, and GPU/CPU utilization per mannequin |
| /aws/sagemaker/inference-quality/ | Customized high quality metrics: composite high quality scores, security scores, and analysis latency | Captures LLM output high quality indicators, stored cleanly separated from operational metrics |
Amazon Managed Grafana offers the visualization layer, utilizing CloudWatch as its native information supply. On this put up, we describe two devoted dashboards that floor SageMaker AI endpoint LLM amount and high quality metrics, as proven within the following screenshot.
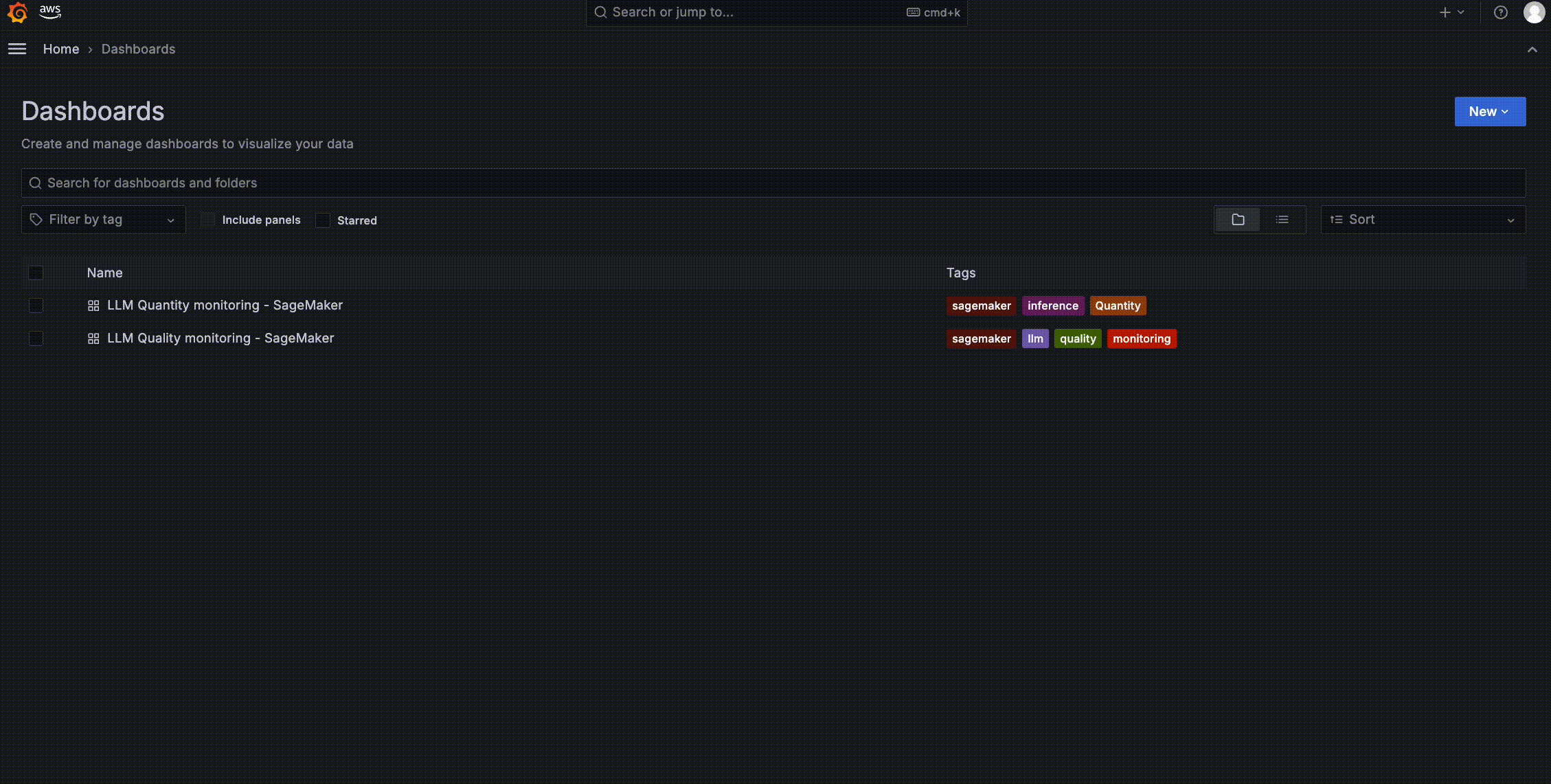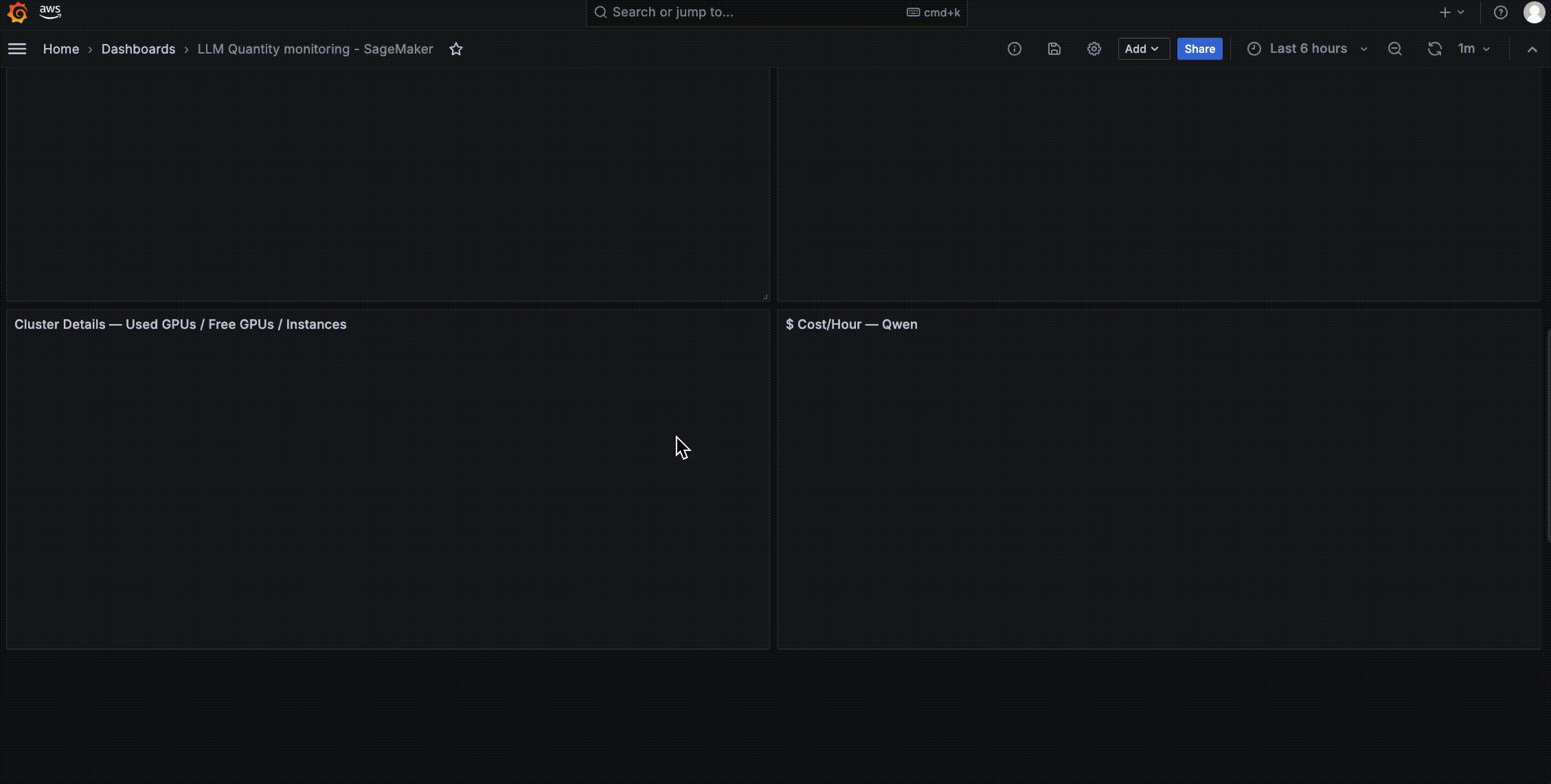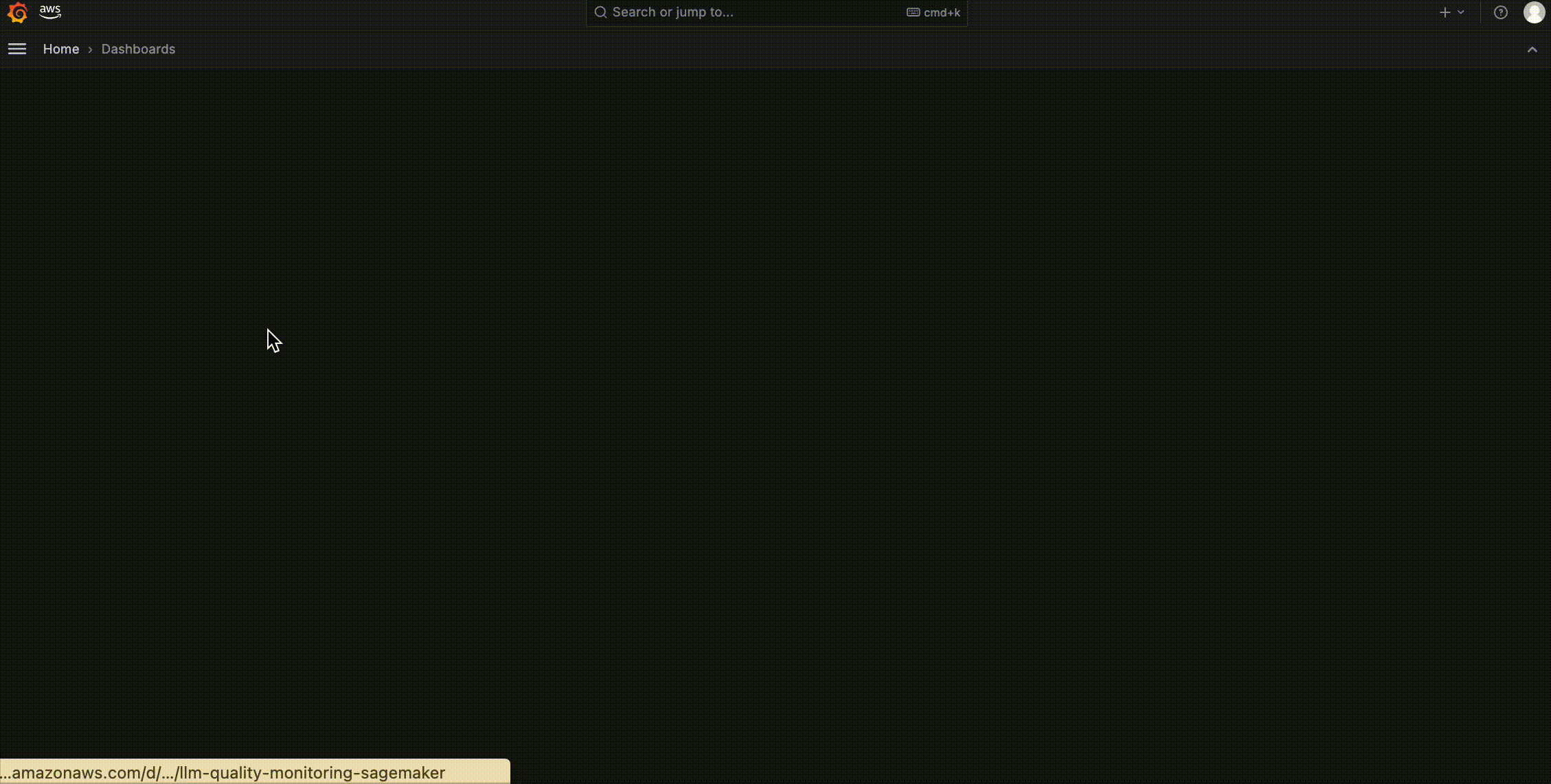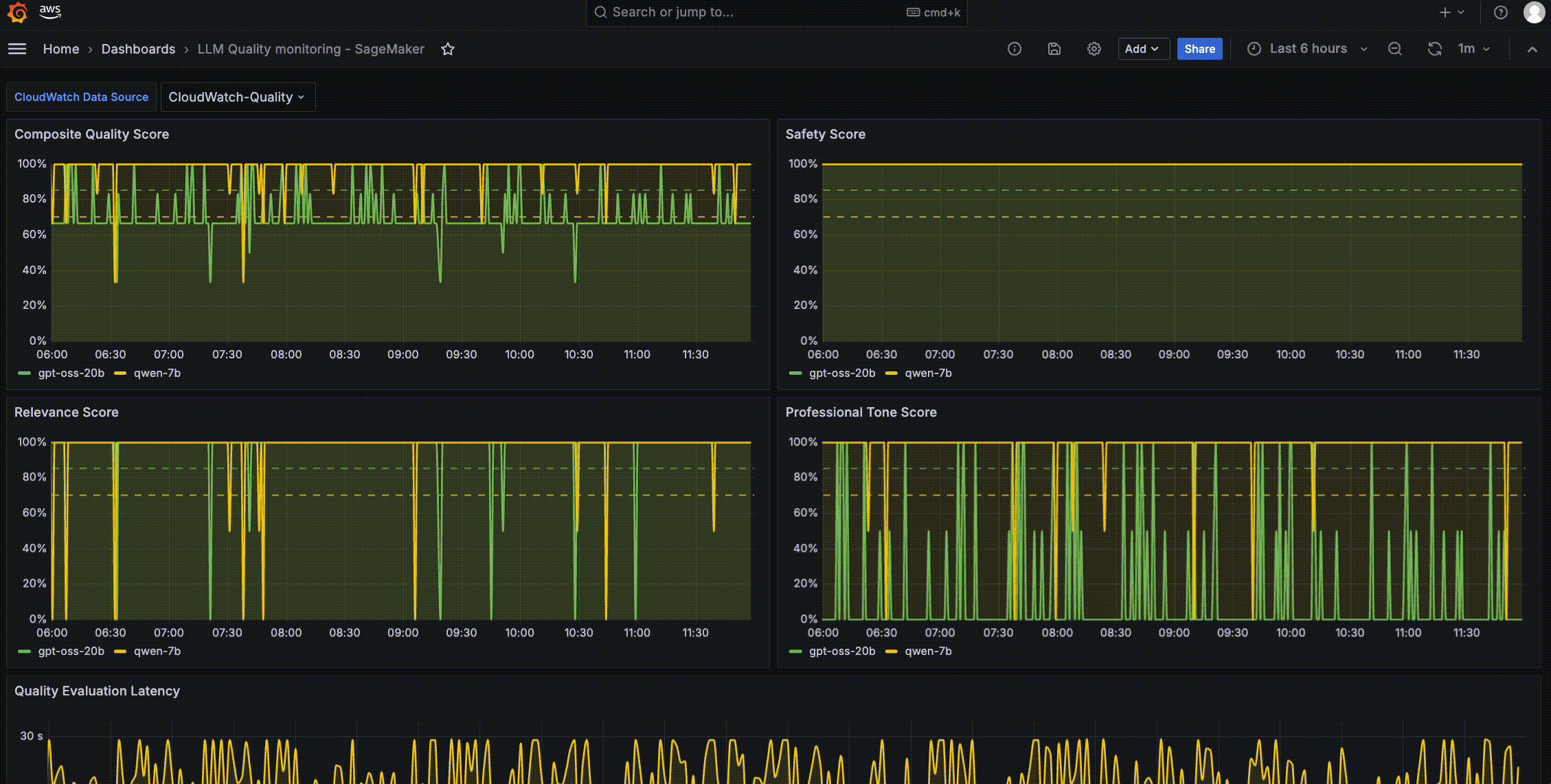
The Grafana quantity-based dashboard shows GPU reminiscence utilization, CPU utilization, and invocation metrics per inference element. The standard-based Grafana dashboard shows composite high quality scores, security scores, and high quality analysis latency, in contrast throughout fashions, as proven within the following picture. You possibly can lengthen the Grafana dashboard by creating new dashboards based mostly on what you are promoting or utility use circumstances.
Monitoring amount
Amount monitoring offers you operational visibility into LLMs served on SageMaker AI endpoints. With out it, you’ll be able to lose monitor of visitors patterns, useful resource saturation, value attribution, and scaling habits, all of which straight impression availability and spend. For multi-model endpoints utilizing inference parts, amount monitoring solutions vital operational questions: What number of requests is every mannequin serving? Are GPUs right-sized or over-provisioned? Which mannequin is driving value?
Past infrastructure metrics, amount monitoring helps you assess the operational well being and enterprise impression of your LLM inference parts throughout efficiency and reliability, useful resource utilization, and any enterprise metrics particular to your group. Collectively, these views present the place latency is going on, whether or not value will increase are pushed by visitors development or inefficient GPU allocation, and whether or not scaling insurance policies are responding appropriately to demand.
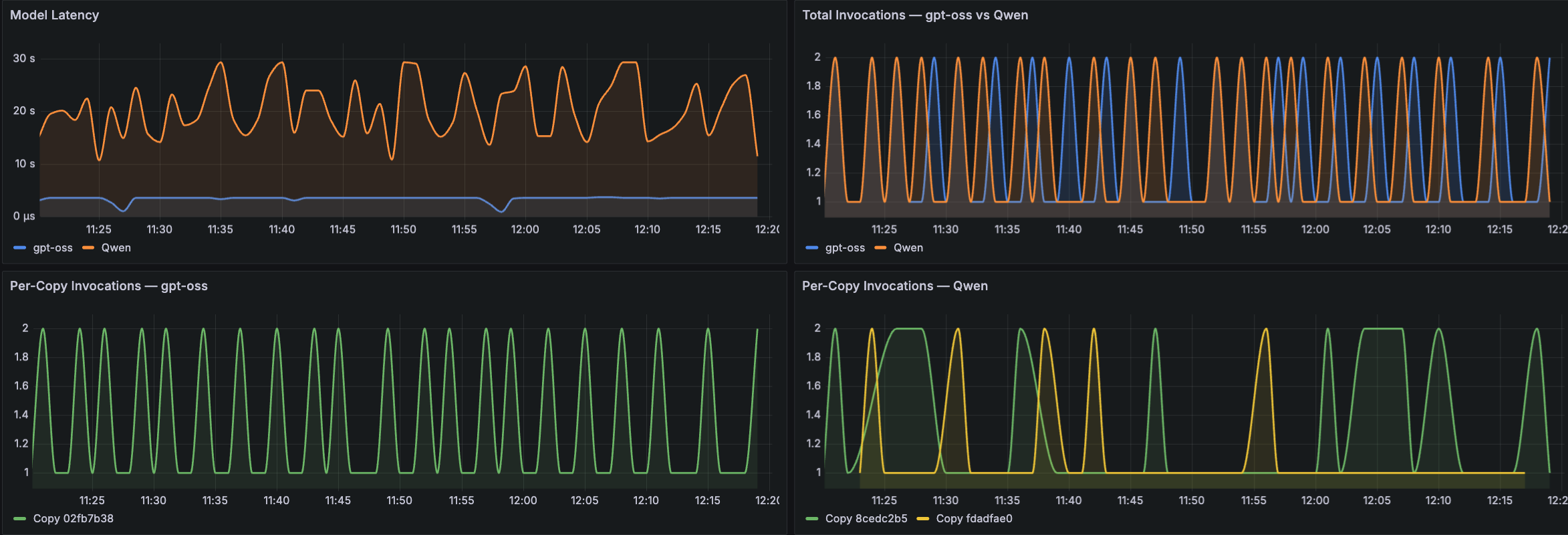
The next Amazon Managed Grafana dashboard samples put these amount monitoring dimensions into follow throughout three key areas. The primary group of panels covers LLM invocations and latency. As proven within the following pattern Grafana dashboard output, panels show Mannequin Latency as a time-series development, Complete Invocations evaluating fashions (for instance, gpt-oss versus Qwen), and Per-Copy Invocations damaged down for every mannequin. These panels assist operators perceive request throughput patterns, determine latency spikes, and evaluate invocation distribution throughout mannequin copies.
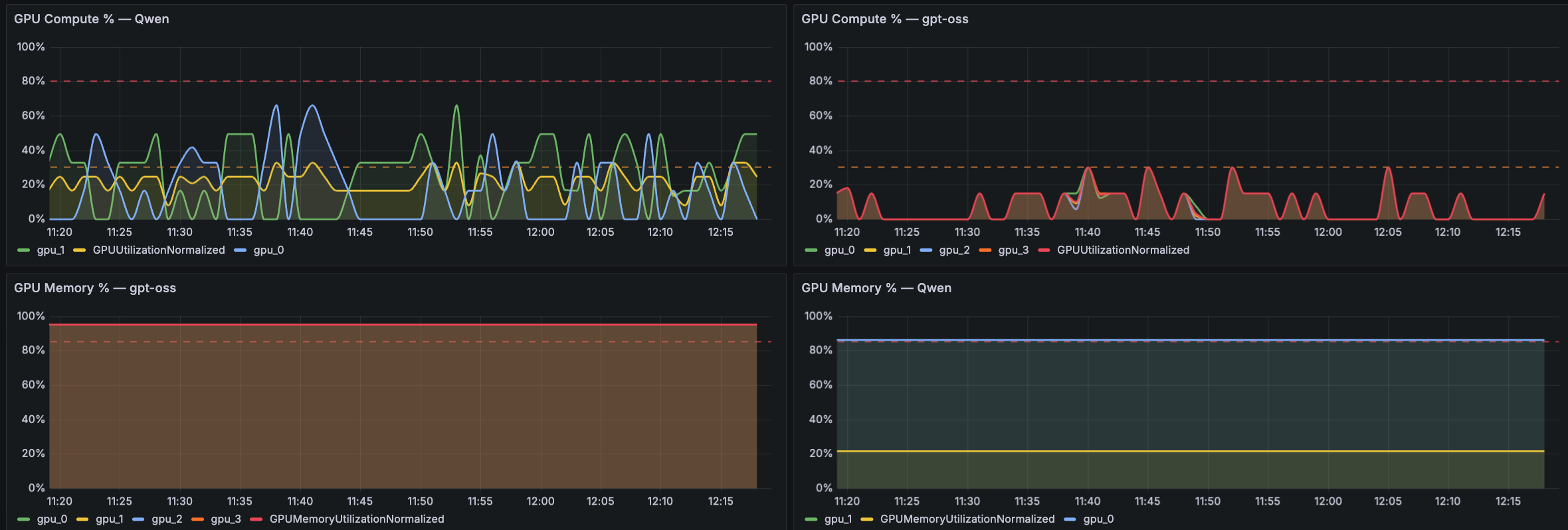
The following panel focuses on GPU compute and reminiscence utilization. The next Grafana dashboard samples current GPU Compute share and GPU Reminiscence share panels for each the fashions (for instance, Qwen and gpt-oss). This cross-model comparability helps ML engineers and web site reliability engineers (SREs) rapidly decide whether or not a efficiency difficulty is GPU-compute-bound or memory-limited, and whether or not one mannequin is consuming disproportionate assets on shared infrastructure.
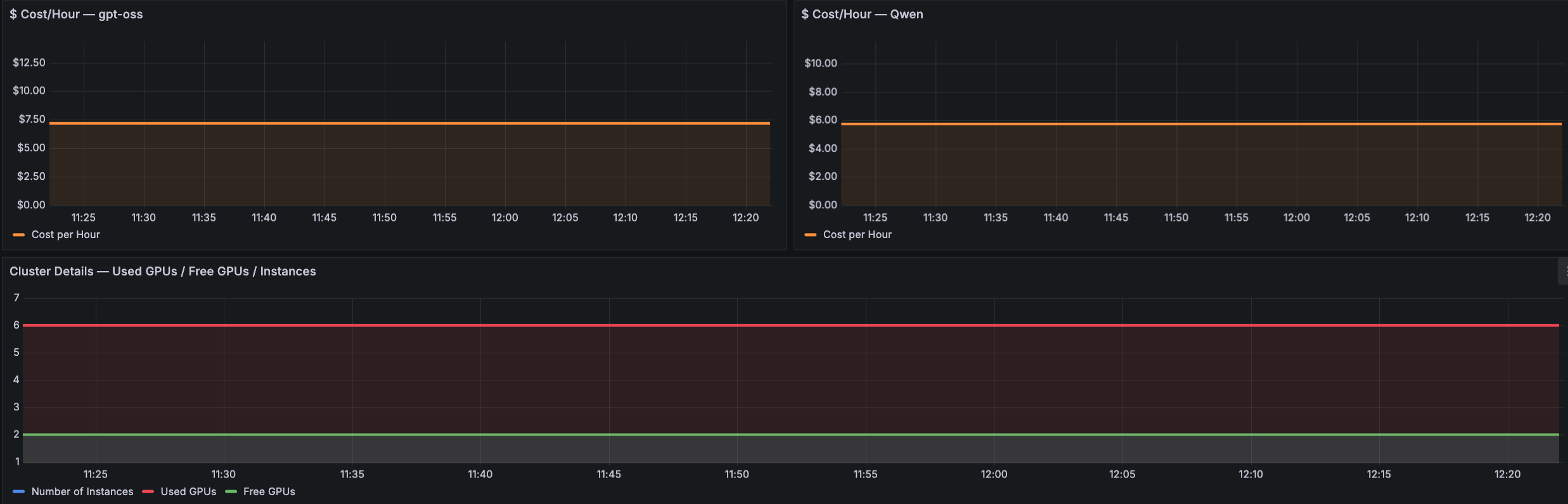
The third set of panels offers endpoint utilization and price particulars. The next Cluster Overview and Price Grafana dashboard pattern exhibits Used GPUs versus Free GPUs and Complete Situations to visualise cluster capability, alongside per-model Price/hour panels (for instance, gpt-oss and Qwen). This view exhibits which mannequin is driving value, whether or not GPUs are over-provisioned or saturated, and whether or not auto scaling insurance policies are responding to demand.
The next desk summarizes the three amount monitoring areas lined within the Grafana dashboard, together with their related metrics and objective:
| Metric Sort | Dashboard Metric Names | Captures | Goal |
| Mannequin Invocations & Latency | Mannequin Latency, Complete Invocations (gpt-oss vs Qwen), Per-Copy Invocations (gpt-oss), Per-Copy Invocations (Qwen) | Request throughput, response time, and per-copy invocation distribution | Determine latency spikes, evaluate mannequin throughput, and perceive invocation load balancing throughout copies |
| GPU Compute & Reminiscence Utilization | GPU Compute % (Qwen), GPU Compute % (gpt-oss), GPU Reminiscence % (Qwen), GPU Reminiscence % (gpt-oss) | Per-model GPU compute and reminiscence utilization percentages | Decide if points are GPU-compute-bound or memory-limited, and detect disproportionate useful resource consumption throughout fashions |
| Endpoint Utilization & Price | Used GPUs / Free GPUs / Situations, Price/hour (gpt-oss), Price/hour (Qwen) | Cluster capability, GPU allocation standing, and per-model hourly value attribution | Determine value drivers, detect over-provisioned or saturated GPUs, and validate auto scaling responsiveness |
Collectively, these dashboards give operators a single pane of glass to correlate value, capability, and utilization throughout fashions served on the endpoint. To arrange these dashboards in your setting, comply with the AWS samples GitHub repository sample notebook and lengthen the answer to create dashboards tailor-made to your group’s necessities.
Monitoring high quality
Whereas amount metrics inform you whether or not the LLM serving infrastructure is wholesome, high quality metrics inform you whether or not LLMs are nonetheless performing as anticipated. LLM efficiency can degrade silently over time due to modifications in enter immediate distributions, idea drift, or shifts in real-world circumstances. In contrast to a latency spike or a 500 error, high quality degradation not often triggers conventional alerts.
High quality monitoring addresses this by evaluating mannequin outputs throughout dimensions that matter to the enterprise: response high quality (relevance to consumer queries, factual accuracy, completeness, and consistency), security and compliance (dangerous content material detection, bias monitoring, privateness compliance, and regulatory adherence), consumer expertise high quality (helpfulness, readability, acceptable tone, and multi-turn dialog coherence), and domain-specific high quality (technical accuracy for specialised domains, quotation high quality for Retrieval Augmented Era (RAG) purposes, and code correctness for programming assistants). Collectively, these dimensions assist governance groups implement guardrails, product homeowners monitor user-facing high quality over time, and information scientists pinpoint whether or not a high quality drop is attributable to a selected immediate sample, a mannequin replace, or an information distribution shift.
The next Amazon Managed Grafana dashboard pattern output demonstrates high quality monitoring throughout the SageMaker AI endpoint inference parts (for instance, LLMs gpt-oss-20b and Qwen2.5-7B-Instruct). The instance dashboard tracks 4 high quality scores, every displayed as a time-series line chart with configurable alert thresholds (proven as dashed traces at roughly 85% and 95%). The primary panel exhibits the Composite High quality Rating, an mixture well being indicator that mixes high quality dimensions. This metric shows the general high quality development over time, making it simple to identify sustained degradation versus intermittent high quality drops which will correlate with particular immediate sorts.
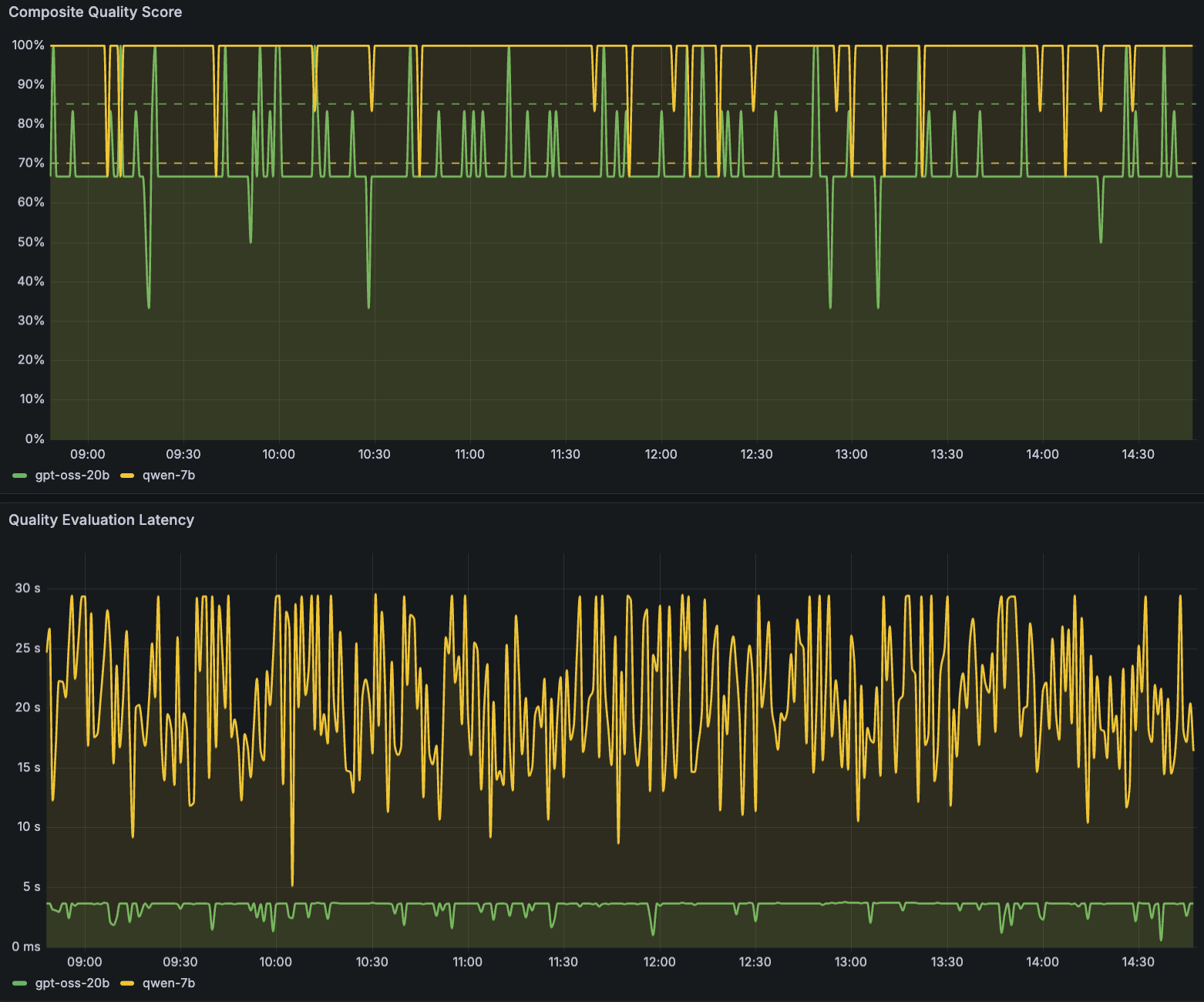
The second group of panels tracks particular LLM response high quality metrics: Security Rating, Relevance Rating, and Skilled Tone Rating. Security Rating displays dangerous or non-compliant content material detection. On the dashboard output, this rating stays essentially the most secure of all 4 metrics, constantly hovering inside the goal threshold band, which signifies dependable security guardrails throughout each fashions. Relevance Rating measures how effectively LLM responses tackle consumer intent, serving to groups determine immediate classes which will problem an LLM’s comprehension. Skilled Tone Rating evaluates whether or not outputs preserve an acceptable tone for the deployment context.
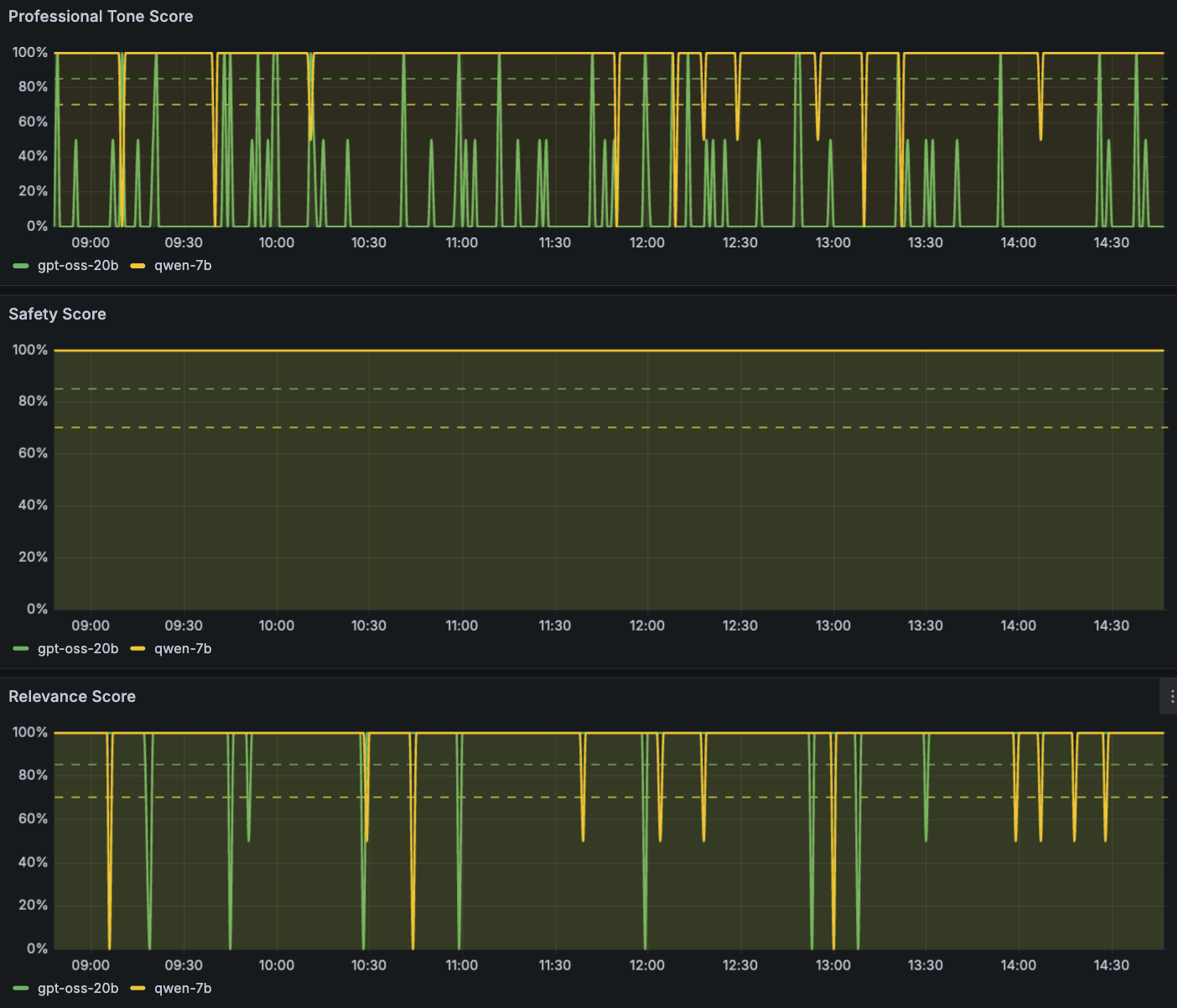
These high quality scores are computed utilizing analysis metrics corresponding to an LLM-as-judge sample with configurable analysis rubrics. In these examples, we use Anthropic Claude Sonnet 4.6 served through Amazon Bedrock because the evaluator mannequin, which is permitted underneath commonplace Amazon Bedrock service phrases for LLM-as-judge use circumstances. You possibly can substitute your individual analysis system, offered you verify the chosen mannequin’s phrases allow evaluating outputs from different fashions, you confirm the data-residency necessities are met, and also you pin the evaluator mannequin to a selected model so high quality scores stay comparable over time.
At a look, you’ll be able to evaluate high quality throughout LLMs aspect by aspect, figuring out which LLM is extra secure, which high quality dimension is the first threat driver, and whether or not high quality points are intermittent (suggesting sensitivity to particular immediate sorts) or sustained (suggesting mannequin degradation). Past visualization, threshold-based alert guidelines are deployed routinely through Grafana Alerting, dimensioned by the inference element in order that alerts hearth per inference element. When a high quality rating breaches its configured threshold, you’ll be able to obtain these notifications through Amazon Easy Notification Service (Amazon SNS), enabling speedy SRE triage. Trendy SRE groups use their current automated triage processes, for instance by integrating these alerts with Slack, PagerDuty, or OpsGenie to chop response instances to seconds by routinely correlating logs, classifying alert severity, and prioritizing incidents for mitigation.
The next Grafana Alerting dashboard pattern output exhibits threshold-based alert guidelines firing per inference element, with notifications routed to configured channels for speedy SRE triage.
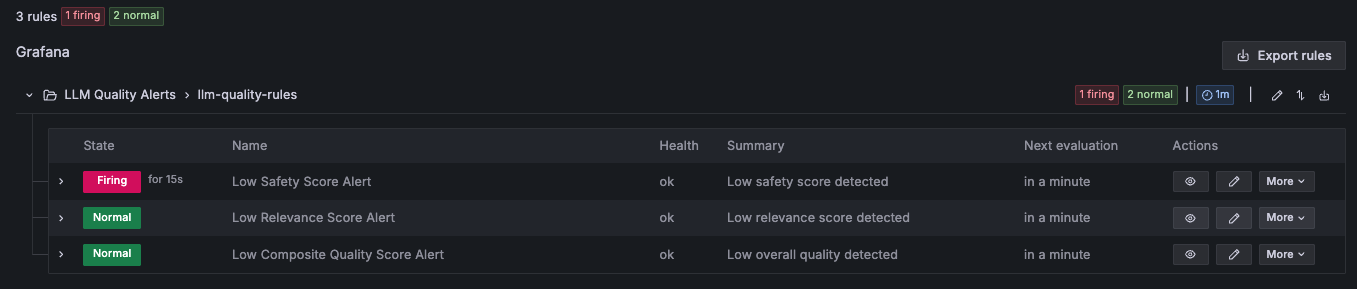
This view offers governance and product groups the proof wanted to make selections about engineering changes, remediation actions, root trigger evaluation, mannequin swapping, or different refinements. To arrange this dashboard in your setting and study extra in regards to the high quality metrics, comply with the AWS samples GitHub repository notebook.
Conclusion
Observability of LLM inference stacks in manufacturing requires greater than monitoring uptime and error charges. As this put up demonstrated, a complete technique should tackle two complementary dimensions: amount and high quality. Amount covers the operational well being of your infrastructure, together with GPU utilization, value attribution, scaling habits, and request throughput. High quality covers the continuing efficiency of your fashions, together with response relevance, security compliance, factual accuracy, {and professional} tone.
By combining Amazon SageMaker AI endpoint enhanced metrics, Amazon CloudWatch, and Amazon Managed Grafana, you’ll be able to construct a unified observability layer with out customized instrumentation. Enhanced metrics offer you per-model, per-GPU granularity on shared infrastructure. CloudWatch offers a single metrics retailer for each operational and high quality indicators. Grafana brings it collectively in dashboards that serve completely different stakeholders: SREs monitoring useful resource saturation and scaling, governance groups monitoring security and compliance thresholds, and product homeowners evaluating mannequin high quality aspect by aspect.
To get began, take a look at the AWS samples GitHub repository, which incorporates pattern notebooks to configure enhanced metrics, publish custom quality metrics and alerts, and arrange the Grafana dashboards proven on this put up.
Concerning the authors

{kind=link}