


Retrieval Augmented Era (RAG) is a elementary strategy for constructing superior generative AI functions that join massive language fashions (LLMs) to enterprise information. Nonetheless, crafting a dependable RAG pipeline isn’t a one-shot course of. Groups typically want to check dozens of configurations (various chunking methods, embedding fashions, retrieval methods, and immediate designs) earlier than arriving at an answer that works for his or her use case. Moreover, administration of high-performing RAG pipeline includes complicated deployment, with groups typically utilizing guide RAG pipeline administration, resulting in inconsistent outcomes, time-consuming troubleshooting, and problem in reproducing profitable configurations. Groups battle with scattered documentation of parameter decisions, restricted visibility into element efficiency, and the lack to systematically examine totally different approaches. Moreover, the dearth of automation creates bottlenecks in scaling the RAG options, will increase operational overhead, and makes it difficult to keep up high quality throughout a number of deployments and environments from growth to manufacturing.
On this put up, we stroll by the way to streamline your RAG growth lifecycle from experimentation to automation, serving to you operationalize your RAG answer for manufacturing deployments with Amazon SageMaker AI, serving to your staff experiment effectively, collaborate successfully, and drive steady enchancment. By combining experimentation and automation with SageMaker AI, you’ll be able to confirm that the whole pipeline is versioned, examined, and promoted as a cohesive unit. This strategy offers complete steerage for traceability, reproducibility, and threat mitigation because the RAG system advances from growth to manufacturing, supporting steady enchancment and dependable operation in real-world eventualities.
Resolution overview
By streamlining each experimentation and operational workflows, groups can use SageMaker AI to quickly prototype, deploy, and monitor RAG functions at scale. Its integration with SageMaker managed MLflow offers a unified platform for monitoring experiments, logging configurations, and evaluating outcomes, supporting reproducibility and sturdy governance all through the pipeline lifecycle. Automation additionally minimizes guide intervention, reduces errors, and streamlines the method of selling the finalized RAG pipeline from the experimentation section immediately into manufacturing. With this strategy, each stage from information ingestion to output technology operates effectively and securely, whereas making it easy to transition validated options from growth to manufacturing deployment.
For automation, Amazon SageMaker Pipelines orchestrates end-to-end RAG workflows from information preparation and vector embedding technology to mannequin inference and analysis all with repeatable and version-controlled code. Integrating steady integration and supply (CI/CD) practices additional enhances reproducibility and governance, enabling automated promotion of validated RAG pipelines from growth to staging or manufacturing environments. Selling a complete RAG pipeline (not simply a person subsystem of the RAG answer like a chunking layer or orchestration layer) to larger environments is crucial as a result of information, configurations, and infrastructure can differ considerably throughout staging and manufacturing. In manufacturing, you typically work with stay, delicate, or a lot bigger datasets, and the way in which information is chunked, embedded, retrieved, and generated can affect system efficiency and output high quality in methods that aren’t all the time obvious in decrease environments. Every stage of the pipeline (chunking, embedding, retrieval, and technology) have to be totally evaluated with production-like information for accuracy, relevance, and robustness. Metrics at each stage (reminiscent of chunk high quality, retrieval relevance, reply correctness, and LLM analysis scores) have to be monitored and validated earlier than the pipeline is trusted to serve actual customers.
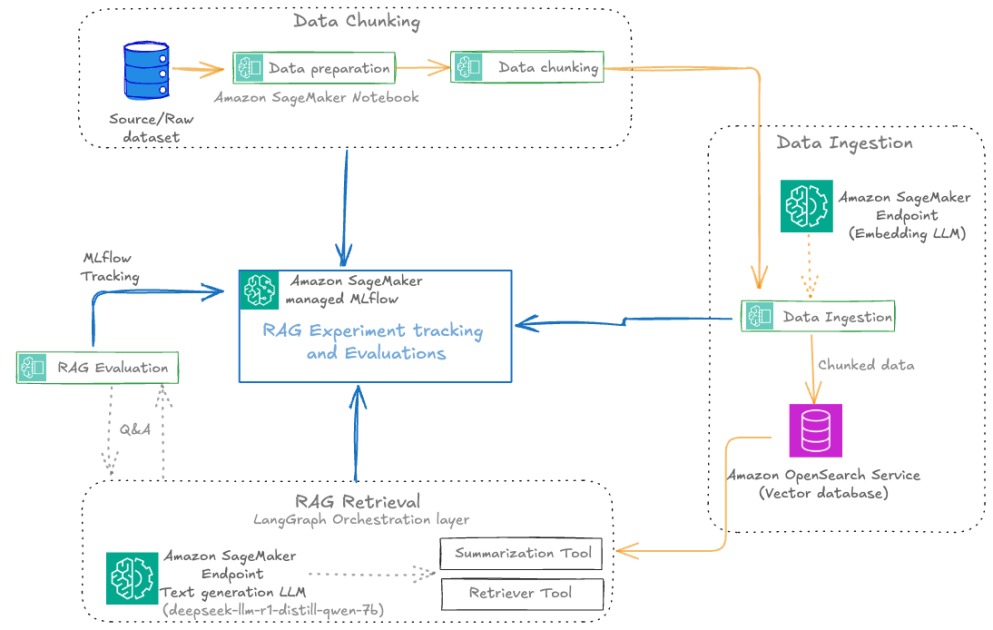
The next diagram illustrates the structure of a scalable RAG pipeline constructed on SageMaker AI, with MLflow experiment monitoring seamlessly built-in at each stage and the RAG pipeline automated utilizing SageMaker Pipelines. SageMaker managed MLflow offers a unified platform for centralized RAG experiment monitoring throughout all pipeline levels. Each MLflow execution run whether or not for RAG chunking, ingestion, retrieval, or analysis sends execution logs, parameters, metrics, and artifacts to SageMaker managed MLflow. The structure makes use of SageMaker Pipelines to orchestrate the whole RAG workflow by versioned, repeatable automation. These RAG pipelines handle dependencies between vital levels, from information ingestion and chunking to embedding technology, retrieval, and closing textual content technology, supporting constant execution throughout environments. Built-in with CI/CD practices, SageMaker Pipelines allow seamless promotion of validated RAG configurations from growth to staging and manufacturing environments whereas sustaining infrastructure as code (IaC) traceability.
For the operational workflow, the answer follows a structured lifecycle: Throughout experimentation, information scientists iterate on pipeline elements inside Amazon SageMaker Studio notebooks whereas SageMaker managed MLflow captures parameters, metrics, and artifacts at each stage. Validated workflows are then codified into SageMaker Pipelines and versioned in Git. The automated promotion section makes use of CI/CD to set off pipeline execution in goal environments, rigorously validating stage-specific metrics (chunk high quality, retrieval relevance, reply correctness) in opposition to manufacturing information earlier than deployment. The opposite core elements embody:
- Amazon SageMaker JumpStart for accessing the most recent LLM fashions and internet hosting them on SageMaker endpoints for mannequin inference with the embedding mannequin
huggingface-textembedding-all-MiniLM-L6-v2and textual content technology mannequindeepseek-llm-r1-distill-qwen-7b. - Amazon OpenSearch Service as a vector database to retailer doc embeddings with the OpenSearch index configured for k-nearest neighbors (k-NN) search.
- The Amazon Bedrock mannequin
anthropic.claude-3-haiku-20240307-v1:0as an LLM-as-a-judge element for all of the MLflow LLM evaluation metrics. - A SageMaker Studio pocket book for a growth atmosphere to experiment and automate the RAG pipelines with SageMaker managed MLflow and SageMaker Pipelines.
You’ll be able to implement this agentic RAG answer code from the GitHub repository. Within the following sections, we use snippets from this code within the repository for instance RAG pipeline experiment evolution and automation.
Stipulations
It’s essential to have the next conditions:
- An AWS account with billing enabled.
- A SageMaker AI area. For extra data, see Use fast setup for Amazon SageMaker AI.
- Entry to a operating SageMaker managed MLflow monitoring server in SageMaker Studio. For extra data, see the directions for establishing a brand new MLflow monitoring server.
- Entry to SageMaker JumpStart to host LLM embedding and textual content technology fashions.
- Entry to the Amazon Bedrock basis fashions (FMs) for RAG analysis duties. For extra particulars, see Subscribe to a mannequin.
SageMaker MLFlow RAG experiment
SageMaker managed MLflow offers a robust framework for organizing RAG experiments, so groups can handle complicated, multi-stage processes with readability and precision. The next diagram illustrates the RAG experiment levels with SageMaker managed MLflow experiment monitoring at each stage. This centralized monitoring gives the next advantages:
- Reproducibility: Each experiment is absolutely documented, so groups can replay and examine runs at any time
- Collaboration: Shared experiment monitoring fosters information sharing and accelerates troubleshooting
- Actionable insights: Visible dashboards and comparative analytics assist groups establish the affect of pipeline modifications and drive steady enchancment
The next diagram illustrates the answer workflow.
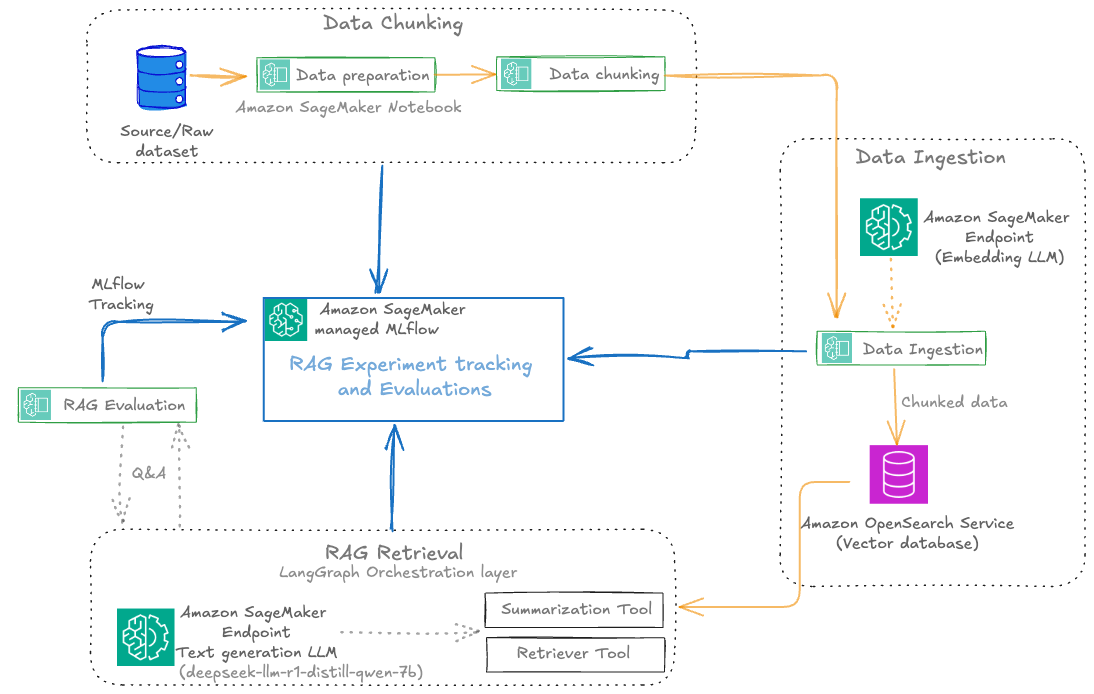
Every RAG experiment in MLflow is structured as a top-level run beneath a selected experiment title. Inside this top-level run, nested runs are created for every main pipeline stage, reminiscent of information preparation, information chunking, information ingestion, RAG retrieval, and RAG analysis. This hierarchical strategy permits for granular monitoring of parameters, metrics, and artifacts at each step, whereas sustaining a transparent lineage from uncooked information to closing analysis outcomes.
The next screenshot reveals an instance of the experiment particulars in MLflow.
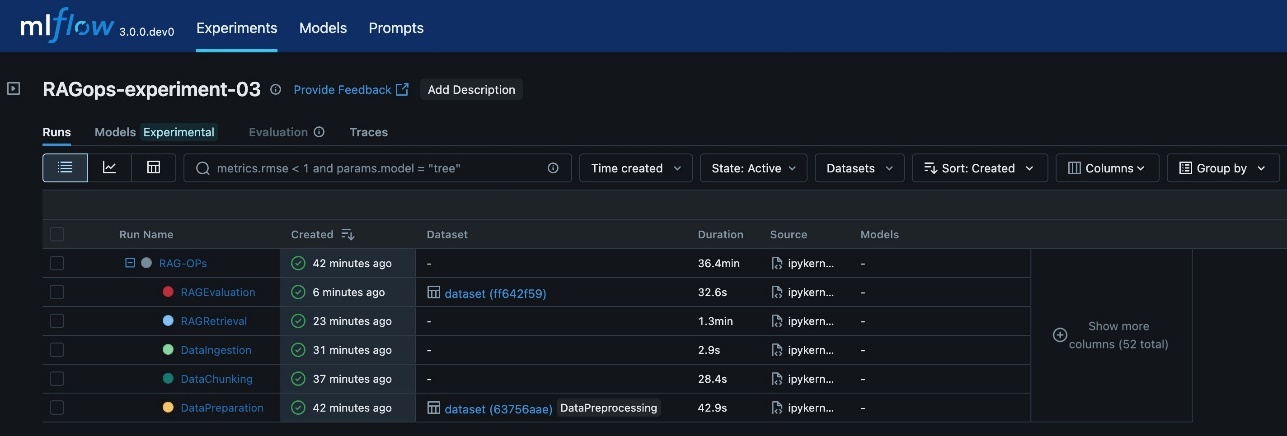
The assorted RAG pipeline steps outlined are:
- Knowledge preparation: Logs dataset model, preprocessing steps, and preliminary statistics
- Knowledge chunking: Data chunking technique, chunk dimension, overlap, and ensuing chunk counts
- Knowledge ingestion: Tracks embedding mannequin, vector database particulars, and doc ingestion metrics
- RAG retrieval: Captures retrieval mannequin, context dimension, and retrieval efficiency metrics
- RAG analysis: Logs analysis metrics (reminiscent of reply similarity, correctness, and relevance) and pattern outcomes
This visualization offers a transparent, end-to-end view of the RAG pipeline’s execution, so you’ll be able to hint the affect of modifications at any stage and obtain full reproducibility. The structure helps scaling to a number of experiments, every representing a definite configuration or speculation (for instance, totally different chunking methods, embedding fashions, or retrieval parameters). MLflow’s experiment UI visualizes these experiments facet by facet, enabling side-by-side comparability and evaluation throughout runs. This construction is particularly worthwhile in enterprise settings, the place dozens and even a whole lot of experiments could be carried out to optimize RAG efficiency.
We use MLflow experimentation all through the RAG pipeline to log metrics and parameters, and the totally different experiment runs are initialized as proven within the following code snippet:
RAG pipeline experimentation
The important thing elements of the RAG workflow are ingestion, chunking, retrieval, and analysis, which we clarify on this part. The MLflow dashboard makes it easy to visualise and analyze these parameters and metrics, supporting data-driven refinement of the chunking stage inside the RAG pipeline.

Knowledge ingestion and preparation
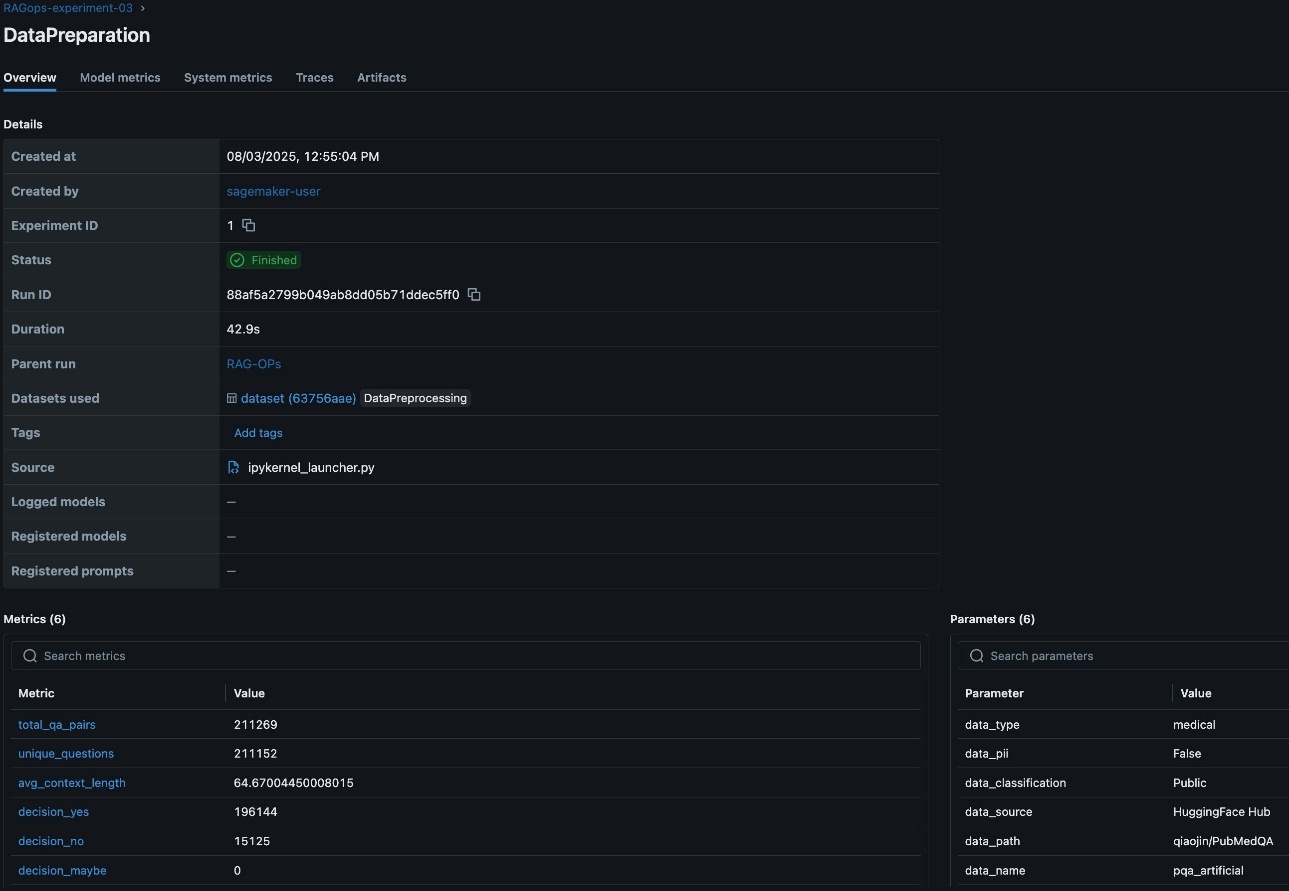
Within the RAG workflow, rigorous information preparation is foundational to downstream efficiency and reliability. Monitoring detailed metrics on information high quality, reminiscent of the full variety of question-answer pairs, the rely of distinctive questions, common context size, and preliminary analysis predictions, offers important visibility into the dataset’s construction and suitability for RAG duties. These metrics assist validate the dataset is complete, various, and contextually wealthy, which immediately impacts the relevance and accuracy of the RAG system’s responses. Moreover, logging vital RAG parameters like the information supply, detected personally identifiable data (PII) sorts, and information lineage data is important for sustaining compliance, reproducibility, and belief in enterprise environments. Capturing this metadata in SageMaker managed MLflow helps sturdy experiment monitoring, auditability, environment friendly comparability, and root trigger evaluation throughout a number of information preparation runs, as visualized within the MLflow dashboard. This disciplined strategy to information preparation lays the groundwork for efficient experimentation, governance, and steady enchancment all through the RAG pipeline. The next screenshot reveals an instance of the experiment run particulars in MLflow.
Knowledge chunking
After information preparation, the subsequent step is to separate paperwork into manageable chunks for environment friendly embedding and retrieval. This course of is pivotal, as a result of the standard and granularity of chunks immediately have an effect on the relevance and completeness of solutions returned by the RAG system. The RAG workflow on this put up helps experimentation and RAG pipeline automation with each fixed-size and recursive chunking methods for comparability and validations. Nonetheless, this RAG answer will be expanded to many different chucking methods.
FixedSizeChunkerdivides textual content into uniform chunks with configurable overlapRecursiveChunkersplits textual content alongside logical boundaries reminiscent of paragraphs or sentences
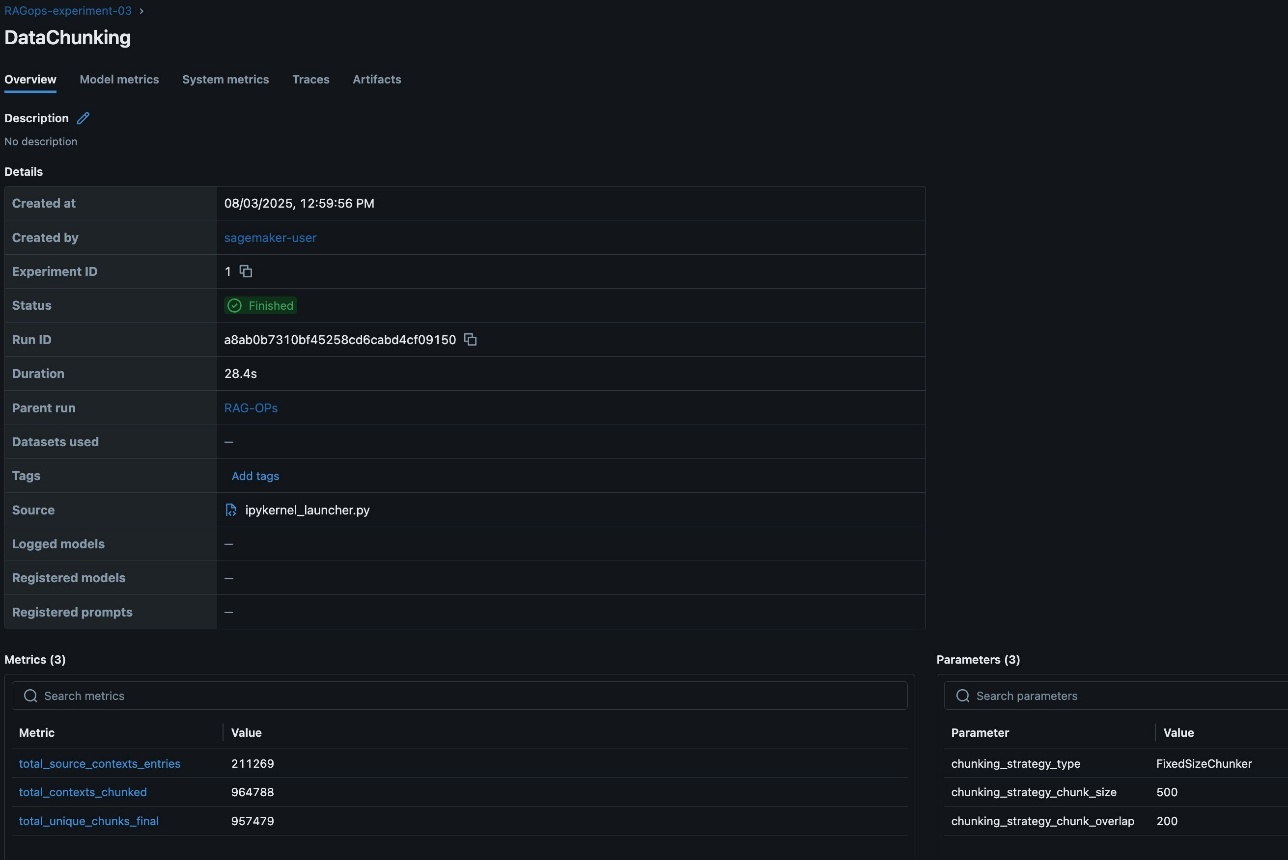
Monitoring detailed chunking metrics reminiscent of total_source_contexts_entries, total_contexts_chunked, and total_unique_chunks_final is essential for understanding how a lot of the supply information is represented, how successfully it’s segmented, and whether or not the chunking strategy is yielding the specified protection and uniqueness. These metrics assist diagnose points like extreme duplication or under-segmentation, which may affect retrieval accuracy and mannequin efficiency.
Moreover, logging parameters reminiscent of chunking_strategy_type (for instance, FixedSizeChunker), chunking_strategy_chunk_size (for instance, 500 characters), and chunking_strategy_chunk_overlap present transparency and reproducibility for every experiment. Capturing these particulars in SageMaker managed MLflow helps groups systematically examine the affect of various chunking configurations, optimize for effectivity and contextual relevance, and keep a transparent audit path of how chunking selections evolve over time. The MLflow dashboard makes it easy to visualise and analyze these parameters and metrics, supporting data-driven refinement of the chunking stage inside the RAG pipeline. The next screenshot reveals an instance of the experiment run particulars in MLflow.
After the paperwork are chunked, the subsequent step is to transform these chunks into vector embeddings utilizing a SageMaker embedding endpoint, after which the embeddings are ingested right into a vector database reminiscent of OpenSearch Service for quick semantic search. This ingestion section is essential as a result of the standard, completeness, and traceability of what enters the vector retailer immediately decide the effectiveness and reliability of downstream retrieval and technology levels.
Monitoring ingestion metrics such because the variety of paperwork and chunks ingested offers visibility into pipeline throughput and helps establish bottlenecks or information loss early within the course of. Logging detailed parameters, together with the embedding mannequin ID, endpoint used, and vector database index, is crucial for reproducibility and auditability. This metadata helps groups hint precisely which mannequin and infrastructure have been used for every ingestion run, supporting root trigger evaluation and compliance, particularly when working with evolving datasets or delicate data.
Retrieval and technology
For a given question, we generate an embedding and retrieve the top-k related chunks from OpenSearch Service. For reply technology, we use a SageMaker LLM endpoint. The retrieved context and the question are mixed right into a immediate, and the LLM generates a solution. Lastly, we orchestrate retrieval and technology utilizing LangGraph, enabling stateful workflows and superior tracing:
With the GenerativeAI agent outlined with LangGraph framework, the agentic layers are evaluated for every iteration of RAG growth, verifying the efficacy of the RAG answer for agentic functions. Every retrieval and technology run is logged to SageMaker managed MLflow, capturing the immediate, generated response, and key metrics and parameters reminiscent of retrieval efficiency, top-k values, and the precise mannequin endpoints used. Monitoring these particulars in MLflow is crucial for evaluating the effectiveness of the retrieval stage, ensuring the returned paperwork are related and that the generated solutions are correct and full. It’s equally vital to trace the efficiency of the vector database throughout retrieval, together with metrics like question latency, throughput, and scalability. Monitoring these system-level metrics alongside retrieval relevance and accuracy makes positive the RAG pipeline delivers appropriate and related solutions and meets manufacturing necessities for responsiveness and scalability. The next screenshot reveals an instance of the Langraph RAG retrieval tracing in MLflow.
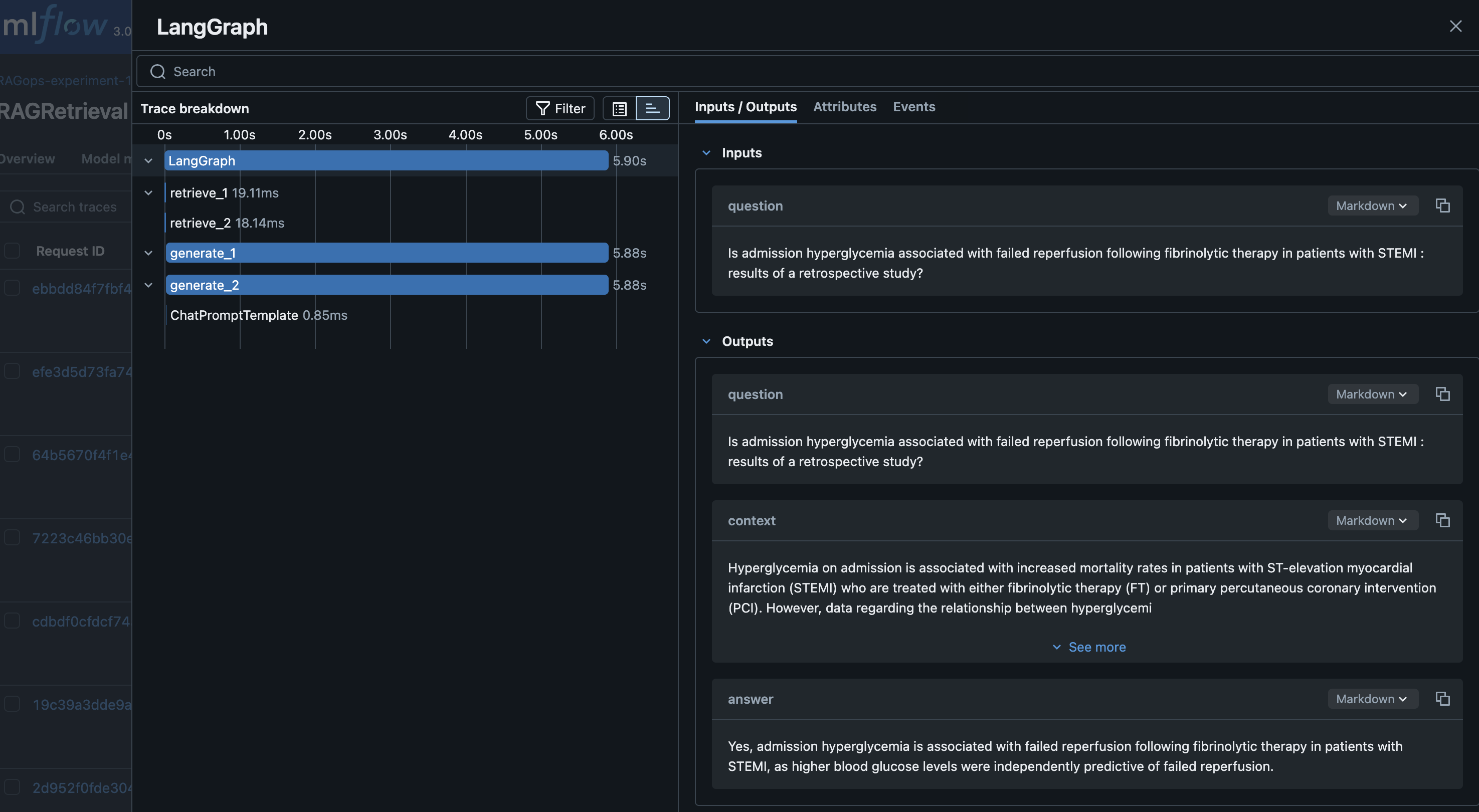
RAG Analysis
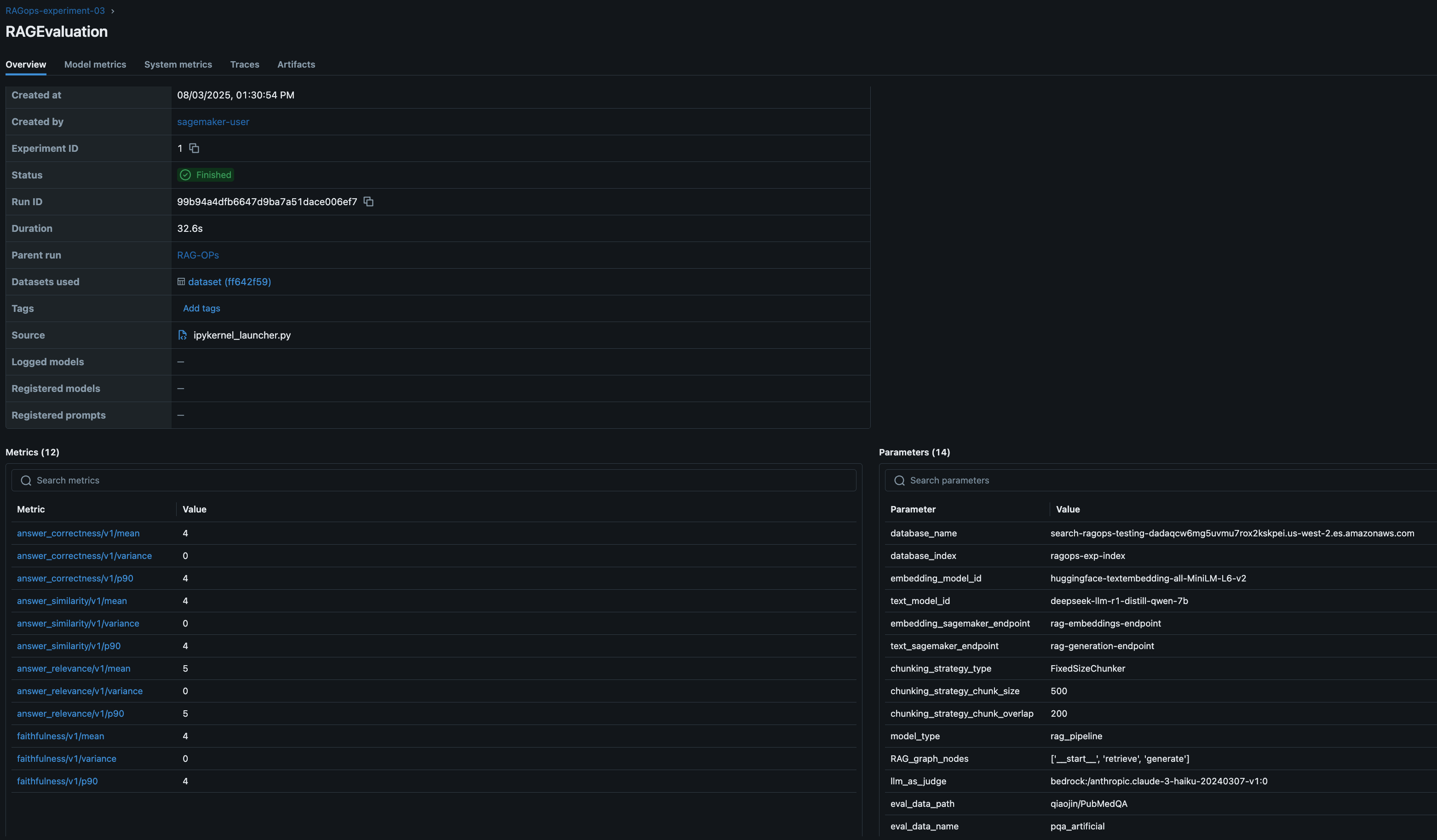
Analysis is carried out on a curated check set, and outcomes are logged to MLflow for fast comparability and evaluation. This helps groups establish the best-performing configurations and iterate towards production-grade options. With MLflow you’ll be able to consider the RAG answer with heuristics metrics, content material similarity metrics and LLM-as-a-judge. On this put up, we consider the RAG pipeline utilizing superior LLM-as-a-judge MLflow metrics (reply similarity, correctness, relevance, faithfulness):
The next screenshot reveals an RAG analysis stage experiment run particulars in MLflow.
You should utilize MLflow to log all metrics and parameters, enabling fast comparability of various experiment runs. See the next code for reference:
By utilizing MLflow’s analysis capabilities (reminiscent of mlflow.consider()), groups can systematically assess retrieval high quality, establish potential gaps or misalignments in chunking or embedding methods, and examine the efficiency of various retrieval and technology configurations. MLflow’s flexibility permits for seamless integration with exterior libraries and analysis libraries reminiscent of RAGAS for complete RAG pipeline evaluation. RAGAS is an open supply library that present instruments particularly for analysis of LLM functions and generative AI brokers. RAGAS contains the tactic ragas.evaluate() to run evaluations for LLM brokers with the selection of LLM fashions (evaluators) for scoring the analysis, and an in depth record of default metrics. To include RAGAS metrics into your MLflow experiments, consult with the next GitHub repository.
Evaluating experiments
Within the MLflow UI, you’ll be able to examine runs facet by facet. For instance, evaluating FixedSizeChunker and RecursiveChunker as proven within the following screenshot reveals variations in metrics reminiscent of answer_similarity (a distinction of 1 level), offering actionable insights for pipeline optimization.
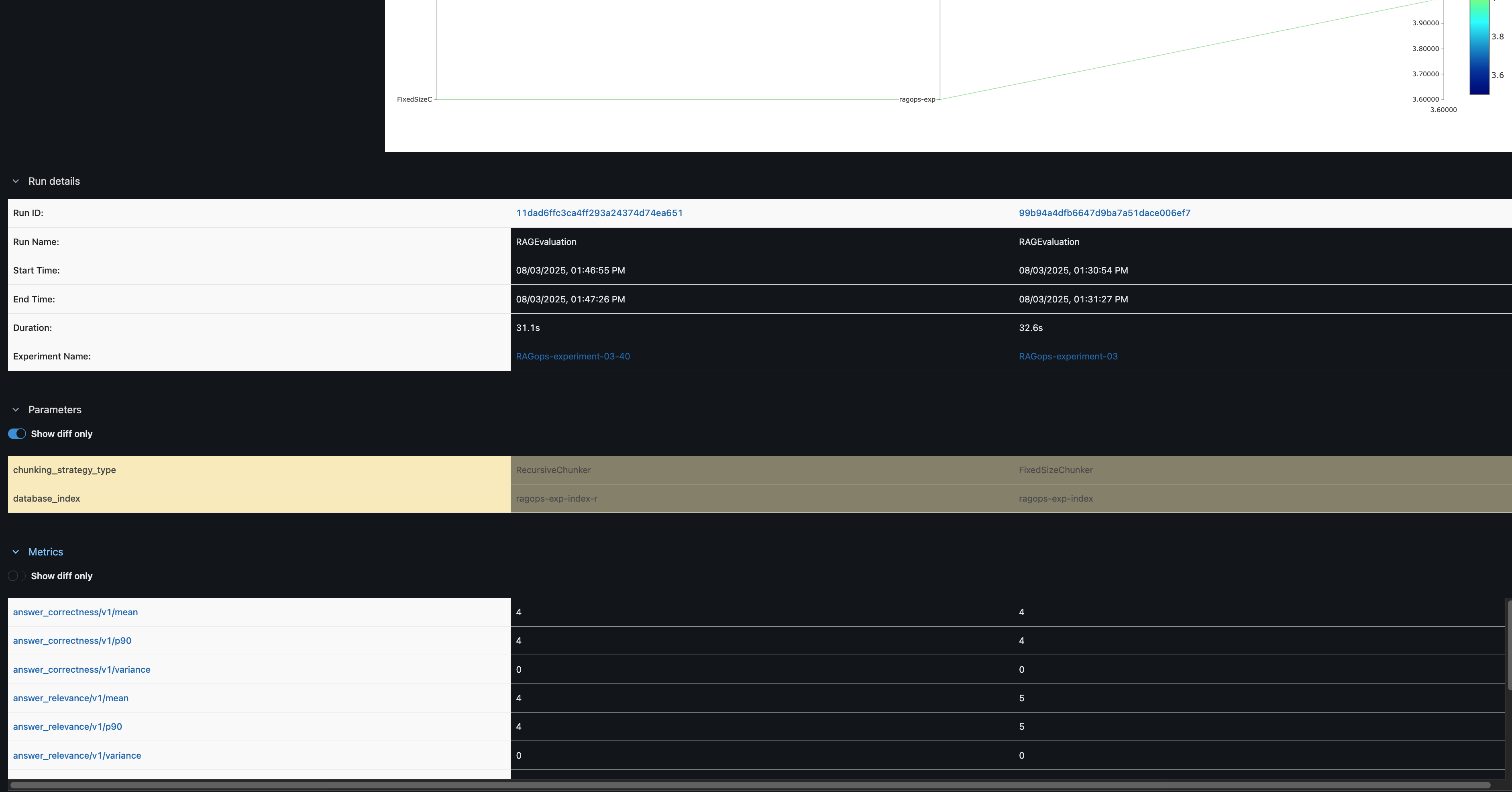
Automation with Amazon SageMaker pipelines
After systematically experimenting with and optimizing every element of the RAG workflow by SageMaker managed MLflow, the subsequent step is remodeling these validated configurations into production-ready automated pipelines. Though MLflow experiments assist establish the optimum mixture of chunking methods, embedding fashions, and retrieval parameters, manually reproducing these configurations throughout environments will be error-prone and inefficient.
To supply the automated RAG pipeline, we use SageMaker Pipelines, which helps groups codify their experimentally validated RAG workflows into automated, repeatable pipelines that keep consistency from growth by manufacturing. By changing the profitable MLflow experiments into pipeline definitions, groups can ensure that the very same chunking, embedding, retrieval, and analysis steps that carried out effectively in testing are reliably reproduced in manufacturing environments.
SageMaker Pipelines gives a serverless workflow orchestration for changing experimental pocket book code right into a production-grade pipeline, versioning and monitoring pipeline configurations alongside MLflow experiments, and automating the end-to-end RAG workflow. The automated Sagemaker pipeline-based RAG workflow gives dependency administration, complete customized testing and validation earlier than manufacturing deployment, and CI/CD integration for automated pipeline promotion.
With SageMaker Pipelines, you’ll be able to automate your total RAG workflow, from information preparation to analysis, as reusable, parameterized pipeline definitions. This offers the next advantages:
- Reproducibility – Pipeline definitions seize all dependencies, configurations, and executions logic in version-controlled code
- Parameterization – Key RAG parameters (chunk sizes, mannequin endpoints, retrieval settings) will be shortly modified between runs
- Monitoring – Pipeline executions present detailed logs and metrics for every step
- Governance – Constructed-in lineage monitoring helps full audibility of knowledge and mannequin artifacts
- Customization – Serverless workflow orchestration is customizable to your distinctive enterprise panorama, with scalable infrastructure and adaptability with situations optimized for CPU, GPU, or memory-intensive duties, reminiscence configuration, and concurrency optimization
To implement a RAG workflow in SageMaker pipelines, every main element of the RAG course of (information preparation, chunking, ingestion, retrieval and technology, and analysis) is included in a SageMaker processing job. These jobs are then orchestrated as steps inside a pipeline, with information flowing between them, as proven within the following screenshot. This construction permits for modular growth, fast debugging, and the flexibility to reuse elements throughout totally different pipeline configurations.
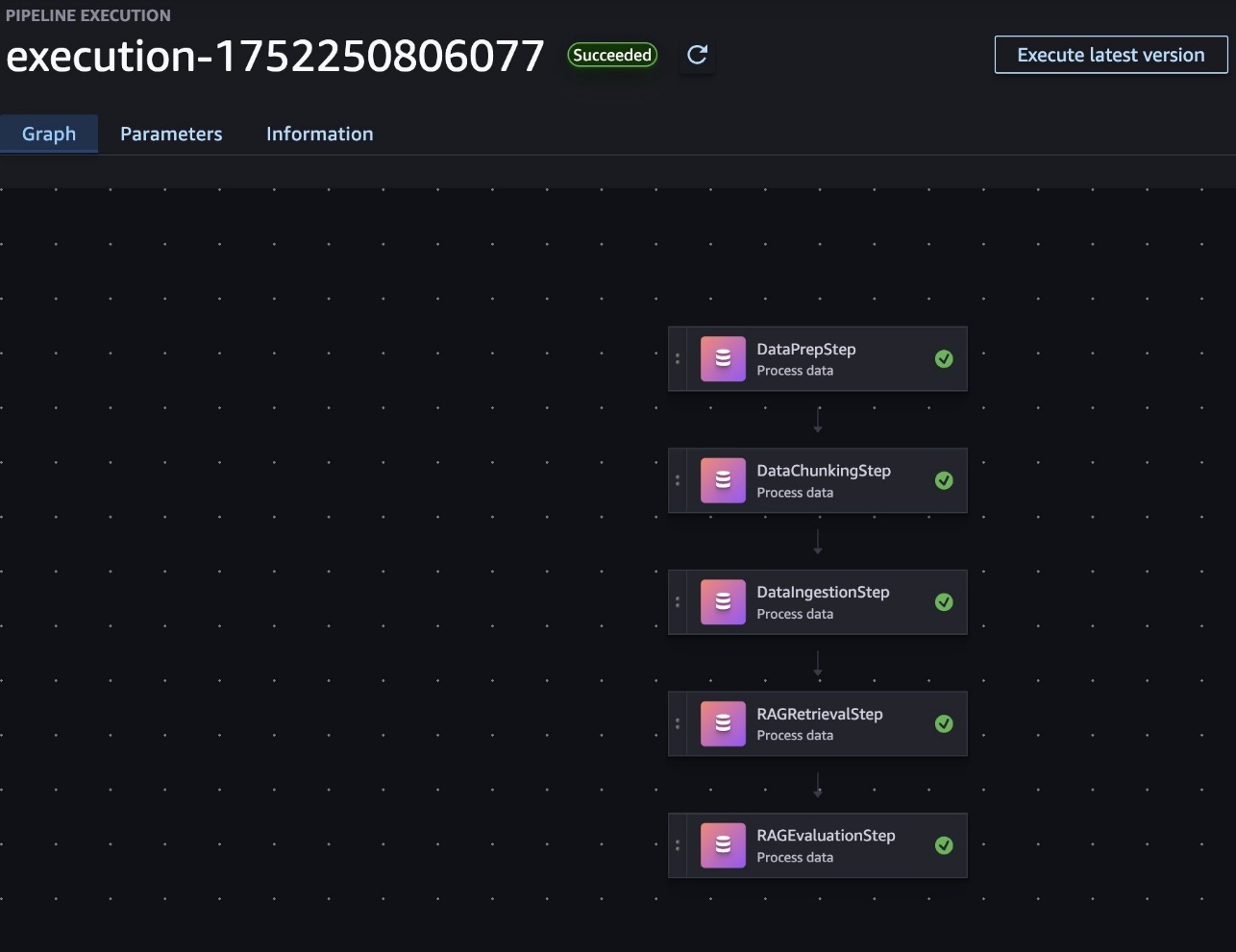
The important thing RAG configurations are uncovered as pipeline parameters, enabling versatile experimentation with minimal code modifications. For instance, the next code snippets showcase the modifiable parameters for RAG configurations, which can be utilized as pipeline configurations:
On this put up, we offer two agentic RAG pipeline automation approaches to constructing the SageMaker pipeline, every with personal advantages: single-step SageMaker pipelines and multi-step pipelines.
The only-step pipeline strategy is designed for simplicity, operating the whole RAG workflow as one unified course of. This setup is good for easy or much less complicated use instances, as a result of it minimizes pipeline administration overhead. With fewer steps, the pipeline can begin shortly, benefitting from decreased execution instances and streamlined growth. This makes it a sensible choice when speedy iteration and ease of use are the first issues.
The multi-step pipeline strategy is most popular for enterprise eventualities the place flexibility and modularity are important. By breaking down the RAG course of into distinct, manageable levels, organizations achieve the flexibility to customise, swap, or prolong particular person elements as wants evolve. This design permits plug-and-play adaptability, making it easy to reuse or reconfigure pipeline steps for varied workflows. Moreover, the multi-step format permits for granular monitoring and troubleshooting at every stage, offering detailed insights into efficiency and facilitating sturdy enterprise administration. For enterprises looking for most flexibility and the flexibility to tailor automation to distinctive necessities, the multi-step pipeline strategy is the superior alternative.
CI/CD for an agentic RAG pipeline
Now we combine the SageMaker RAG pipeline with CI/CD. CI/CD is vital for making a RAG answer enterprise-ready as a result of it offers sooner, extra dependable, and scalable supply of AI-powered workflows. Particularly for enterprises, CI/CD pipelines automate the combination, testing, deployment, and monitoring of modifications within the RAG system, which brings a number of key advantages, reminiscent of sooner and extra dependable updates, model management and traceability, consistency throughout environments, modularity and adaptability for personalisation, enhanced collaboration and monitoring, threat mitigation, and value financial savings. This aligns with basic CI/CD advantages in software program and AI methods, emphasizing automation, high quality assurance, collaboration, and steady suggestions important to enterprise AI readiness.
When your SageMaker RAG pipeline definition is in place, you’ll be able to implement sturdy CI/CD practices by integrating your growth workflow and toolsets already enabled at your enterprise. This setup makes it potential to automate code promotion, pipeline deployment, and mannequin experimentation by easy Git triggers, so modifications are versioned, examined, and systematically promoted throughout environments. For demonstration, on this put up, we present the CI/CD integration utilizing GitHub Actions and by utilizing GitHub Actions because the CI/CD orchestrator. Every code change, reminiscent of refining chunking methods or updating pipeline steps, triggers an end-to-end automation workflow, as proven within the following screenshot. You should utilize the identical CI/CD sample together with your alternative of CI/CD device as a substitute of GitHub Actions, if wanted.
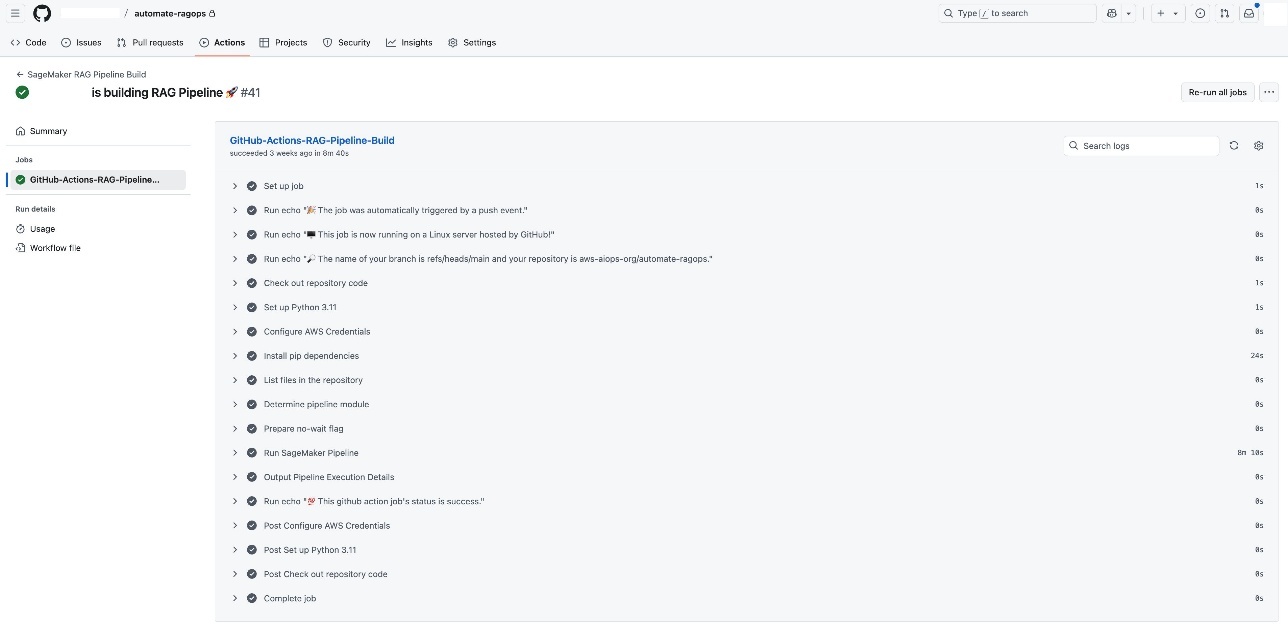
Every GitHub Actions CI/CD execution routinely triggers the SageMaker pipeline (proven within the following screenshot), permitting for seamless scaling of serverless compute infrastructure.
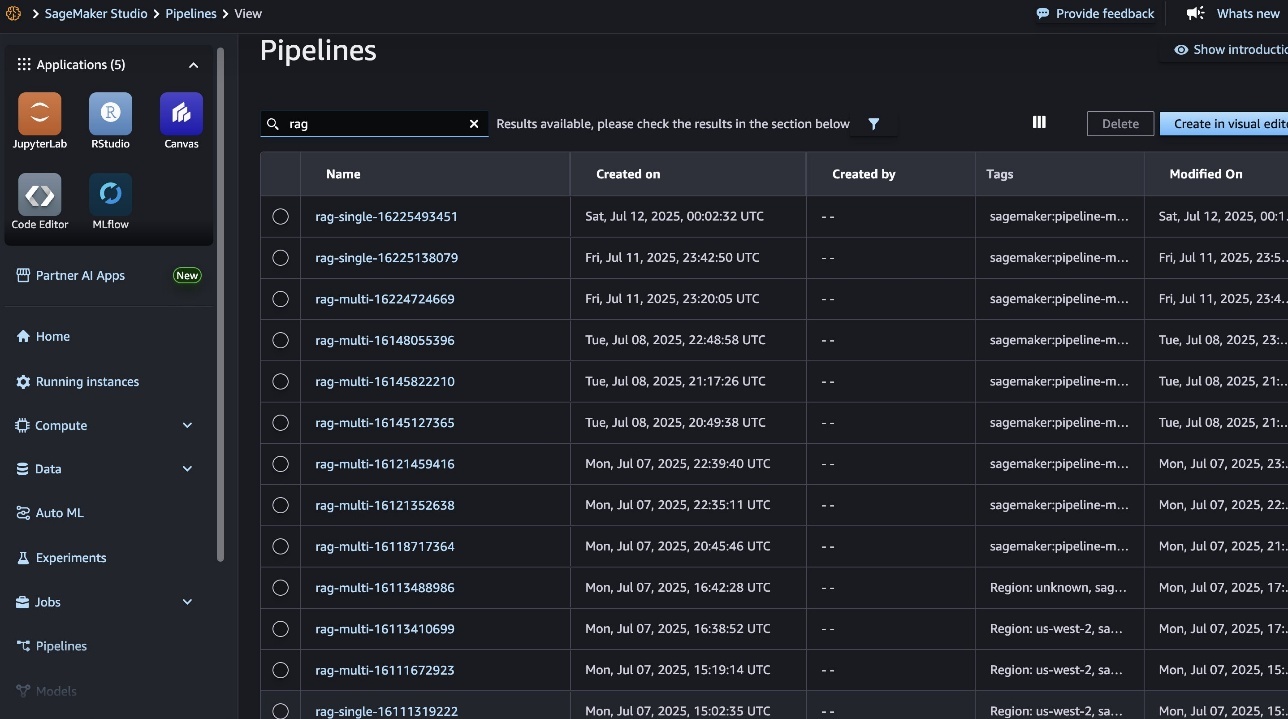
All through this cycle, SageMaker managed MLflow data each executed pipeline (proven within the following screenshot), so you’ll be able to seamlessly overview outcomes, examine efficiency throughout totally different pipeline runs, and handle the RAG lifecycle.
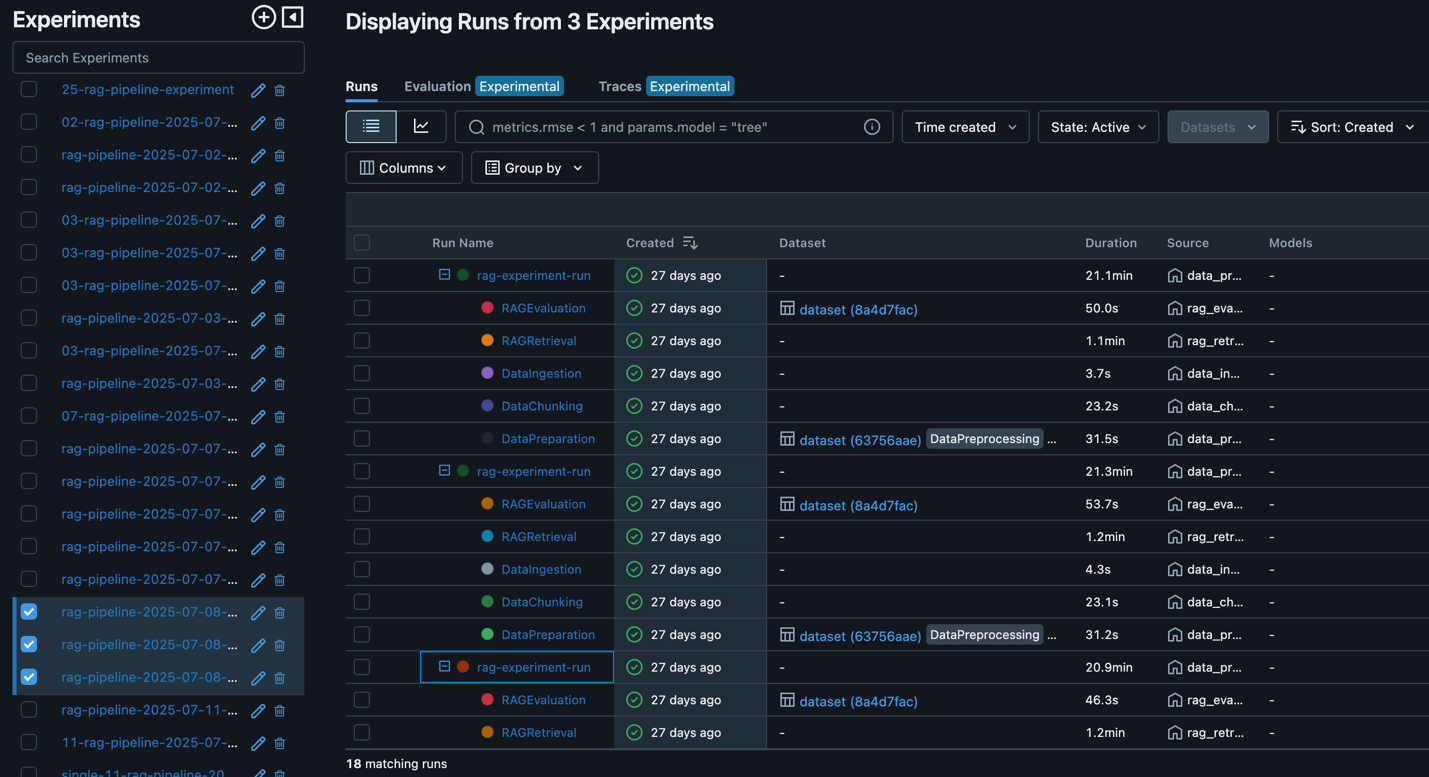
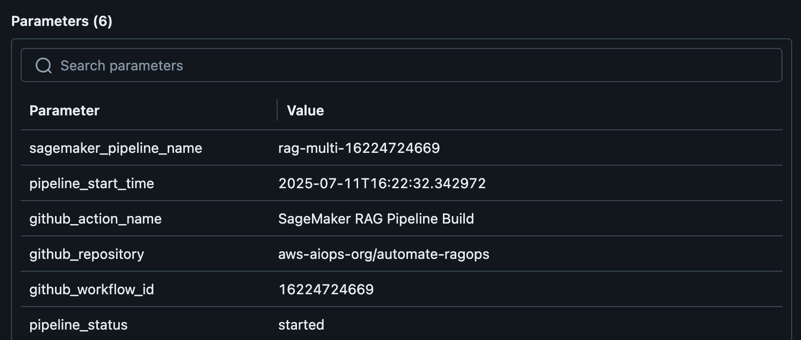
After an optimum RAG pipeline configuration is set, the brand new desired configuration (Git model monitoring captured in MLflow as proven within the following screenshot) will be promoted to larger levels or environments immediately by an automatic workflow, minimizing guide intervention and lowering threat.
Clear up
To keep away from pointless prices, delete assets such because the SageMaker managed MLflow monitoring server, SageMaker pipelines, and SageMaker endpoints when your RAG experimentation is full. You’ll be able to go to the SageMaker Studio console to destroy assets that aren’t wanted anymore or name acceptable AWS APIs actions.
Conclusion
By integrating SageMaker AI, SageMaker managed MLflow, and Amazon OpenSearch Service, you’ll be able to construct, consider, and deploy RAG pipelines at scale. This strategy offers the next advantages:
- Automated and reproducible workflows with SageMaker Pipelines and MLflow, minimizing guide steps and lowering the danger of human error
- Superior experiment monitoring and comparability for various chunking methods, embedding fashions, and LLMs, so each configuration is logged, analyzed, and reproducible
- Actionable insights from each conventional and LLM-based analysis metrics, serving to groups make data-driven enhancements at each stage
- Seamless deployment to manufacturing environments, with automated promotion of validated pipelines and sturdy governance all through the workflow
Automating your RAG pipeline with SageMaker Pipelines brings extra advantages: it permits constant, version-controlled deployments throughout environments, helps collaboration by modular, parameterized workflows, and helps full traceability and auditability of knowledge, fashions, and outcomes. With built-in CI/CD capabilities, you’ll be able to confidently promote your total RAG answer from experimentation to manufacturing, figuring out that every stage meets high quality and compliance requirements.
Now it’s your flip to operationalize RAG workflows and speed up your AI initiatives. Discover SageMaker Pipelines and managed MLflow utilizing the answer from the GitHub repository to unlock scalable, automated, and enterprise-grade RAG options.
About the authors
 Sandeep Raveesh is a GenAI Specialist Options Architect at AWS. He works with prospects by their AIOps journey throughout mannequin coaching, generative AI functions like brokers, and scaling generative AI use instances. He additionally focuses on Go-To-Market methods, serving to AWS construct and align merchandise to unravel business challenges within the generative AI area. You’ll find Sandeep on LinkedIn.
Sandeep Raveesh is a GenAI Specialist Options Architect at AWS. He works with prospects by their AIOps journey throughout mannequin coaching, generative AI functions like brokers, and scaling generative AI use instances. He additionally focuses on Go-To-Market methods, serving to AWS construct and align merchandise to unravel business challenges within the generative AI area. You’ll find Sandeep on LinkedIn.
 Blake Shin is an Affiliate Specialist Options Architect at AWS who enjoys studying about and dealing with new AI/ML applied sciences. In his free time, Blake enjoys exploring the town and taking part in music.
Blake Shin is an Affiliate Specialist Options Architect at AWS who enjoys studying about and dealing with new AI/ML applied sciences. In his free time, Blake enjoys exploring the town and taking part in music.

{kind=link}