


Massive-scale language fashions require large human datasets. So what if all of the fashions needed to create their very own curriculum and learn to use the instruments themselves? A crew of researchers from UNC-Chapel Hill, Salesforce Analysis, and Stanford College introduces Agent0, a totally autonomous framework that evolves high-performance brokers with out exterior information via multistep coevolution and seamless instrument integration.
Agent0 is meant for mathematical and common reasoning. This reveals that with cautious process era and gear integration rollout, it’s potential to exceed the native capabilities of the bottom mannequin throughout 10 benchmarks.
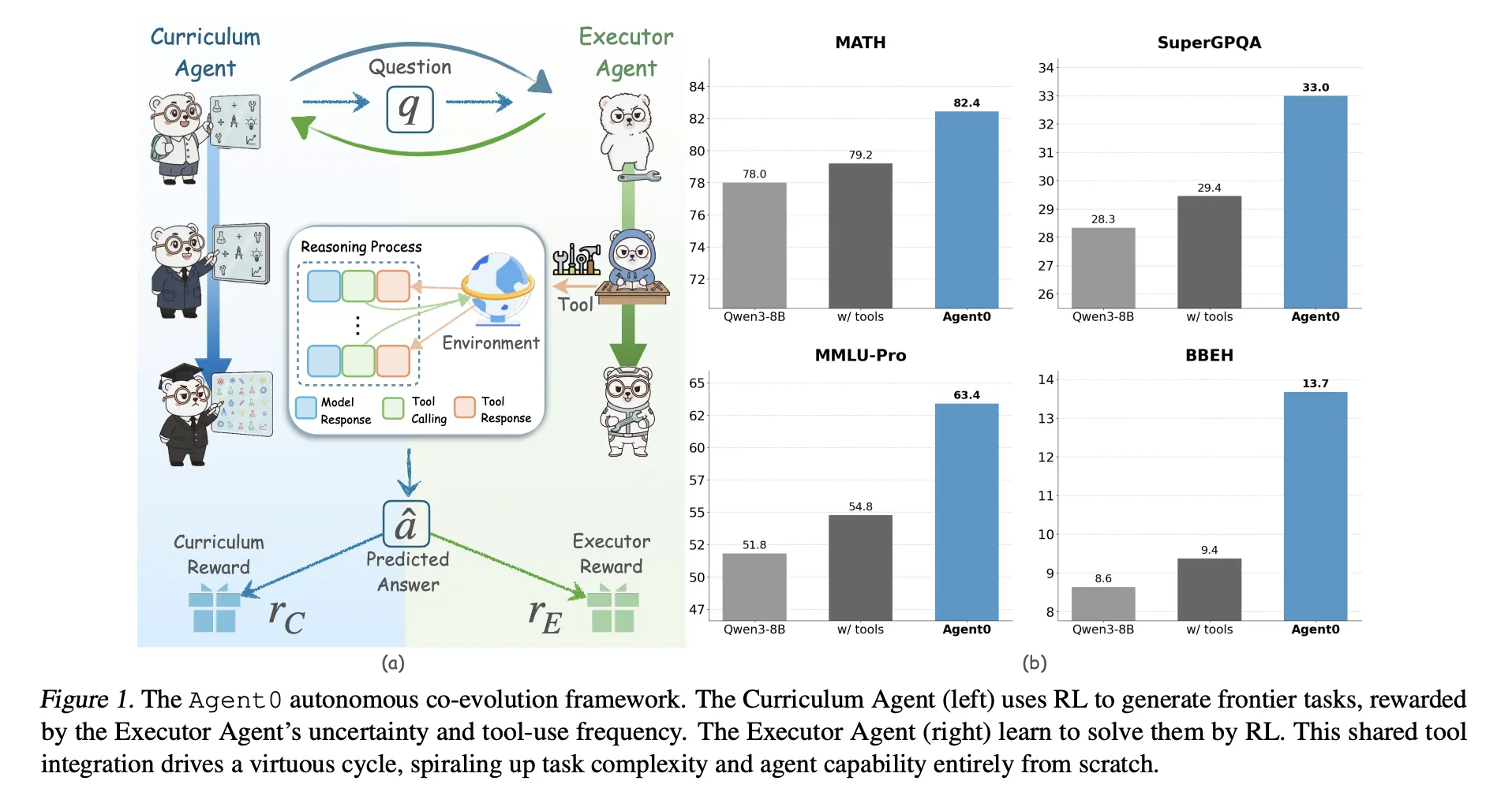
Two brokers from one base mannequin
Agent0, for instance, begins with base coverage π_base. Qwen3 4B base or Qwen3 8B base. This coverage is reproduced under.
- be curriculum agent πθ to generate the duty,
- of Executor Agent Remedy these duties with Python instruments πϕ.
Coaching progresses in iterations, with two levels in every iteration.
- evolution of curriculum: The curriculum agent generates batches of duties. For every process, the executor samples a number of responses. Composite rewards measure how unsure the performer is, how typically they use the instrument, and the way various their batches are. πθ is up to date as follows. Group relative coverage optimization (GRPO) Make the most of this reward.
- Evolution of the executor: Educated curriculum brokers are frozen. Numerous duties shall be generated. Agent0 filters this pool to maintain solely duties near the performer’s purposeful frontier after which trains the performer on these duties utilizing an ambiguity-aware RL goal referred to as . Ambiguity Dynamic Coverage Optimization (ADPO).
This loop types a suggestions cycle. As performers are empowered with code interpreters, curricula should generate extra advanced and tool-dependent issues to maintain their rewards excessive.

How curriculum brokers grade duties?
Curriculum rewards are a mixture of three indicators:
reward of uncertainty: For every generated process x, the executor samples okay responses and votes the bulk for the pseudo-response. Self-consistency p^(x) is the proportion of solutions that match this majority. The reward is highest when p^ is near 0.5, and the reward is decrease if the duty is simply too straightforward or too tough. This facilitates a tough however solvable process for immediately’s practitioners.
Software utilization reward: An executor can set off the sandbox code interpreter utilizing: python Tag and obtain tagged outcomes output. Agent0 counts the variety of instrument calls within the trajectory and provides a scaled capped reward by setting the cap C to 4 in our experiments. This prioritizes duties that truly require instrument calls quite than pure psychological arithmetic.
Repetition penalty: Inside every curriculum batch, Agent0 measures the pairwise similarity between duties utilizing BLEU-based distance. Duties are clustered and the penalty interval will increase with the dimensions of the cluster. This prevents the curriculum from producing numerous near-duplicates.
The composite reward multiplies the format test by a weighted sum of the uncertainty and the instrument reward minus the repetition penalty. This composite worth is enter to GRPO to replace πθ.
How do practitioners be taught from noisy self-labels??
The executor can also be skilled with GRPO, however in multiturn, the instrument makes use of built-in trajectories and pseudo-labels as an alternative of ground-truth solutions.
Building of frontier dataset: After repeated curriculum coaching, a frozen curriculum generates a big pool of candidates. For every process, Agent0 calculates the self-consistency p^(x) with the present executor and retains solely these duties for which p^ is throughout the info band (e.g. 0.3 to 0.8). This defines difficult frontier datasets that keep away from trivial or not possible issues.
Multi-turn instrument integration rollout: For every frontier process, the executor generates a trajectory that may interleave:
- pure language inference tokens,
pythoncode section,outputSoftware suggestions.
When a instrument name is seen, era is paused and the code is executed within the sandbox interpreter constructed on high. VerLToolsand resume relying on the outcomes. The trajectory ends when the mannequin internally generates the ultimate reply. {boxed ...} tag.
A majority vote throughout the sampled trajectories defines the pseudo-label and last reward for every trajectory.
ADPO, ambiguity-aware RL: Normal GRPO treats all samples equally, however turns into unstable when the labels are obtained from majority voting on ambiguous duties. ADPO modifies GRPO in two methods utilizing p^ as an ambiguity sign.
- The normalized benefit is scaled by an element that will increase with self-consistency, so trajectories from unreliable duties contribute much less.
- This units a dynamic clipping higher certain for significance ratios that relies on self-consistency. Empirical evaluation reveals that mounted high clipping primarily impacts low likelihood tokens. ADPO adaptively relaxes this certain, bettering exploration of unsure duties. Elevated likelihood of clipped tokens statistics.

Outcomes of mathematical and common reasoning
Agent0 is carried out on high model and was evaluated Qwen3 4B base and Qwen3 8B base. Use the sandboxed Python interpreter as a single exterior instrument.
The analysis crew evaluated the next 10 benchmarks:
- mathematical reasoning: AMC, Minerva, MATH, GSM8K, Olympic bench, AIME24, AIME25.
- common reasoning: SuperGPQA, MMLU Professional, BBEH.
Most datasets report move@1 and AMC and AIME duties report means@32.
for Qwen3 8B baseagent 0 reaches:
- The mathematical imply is 58.2 vs. 49.2 for the bottom mannequin;
- The general common common is 42.1 in comparison with 34.5 for the bottom mannequin.
Agent0 additionally improves on a powerful data-free baseline, together with: R zero, absolute zero, spiral and socrates zerowith or with out instruments. Qwen3 8B outperforms R Zero by 6.4 factors and Absolute Zero by 10.6 factors on common. It additionally beats Socratic Zero, which depends on an exterior OpenAI API.
Over three coevolutionary iterations, Qwen3 8B’s common math efficiency elevated from 55.1 to 58.2, and common reasoning additionally improved with every iteration. This confirms secure self-improvement quite than collapse.
Qualitative examples present that curriculum duties evolve from fundamental geometry inquiries to advanced constraint satisfaction issues, whereas performer trajectories mix reasoning textual content and Python calls to reach on the right reply.
Necessary factors
- Fully data-free co-evolution: Agent0 eliminates exterior datasets and human annotations. The 2 brokers, curriculum agent and executor agent, are initialized from the identical base LLM and co-evolved solely via reinforcement studying and Python instruments.
- Frontier curriculum from self-uncertainty: The curriculum agent makes use of performer self-consistency and gear utilization to attain duties. It learns find out how to generate frontier duties that explicitly require inference built-in into instruments, that are neither straightforward nor not possible.
- ADPO makes use of pseudo-labels to stabilize RL: Executors are skilled utilizing Ambiguity Dynamic Coverage Optimization. ADPO de-weights extremely ambiguous duties and adjusts the clipping vary primarily based on self-consistency. This makes GRPO-style updates secure even when rewards come from majority-voted pseudo-labels.
- Constant progress in arithmetic and common reasoning: On the Qwen3 8B base, Agent0 improves the maths benchmark from a mean of 49.2 to 58.2 and common reasoning from 34.5 to 42.1. This corresponds to a relative enchancment of roughly 18 % and 24 %.
- Outperforms earlier zero information frameworks: Agent0 outperforms earlier self-evolving strategies throughout 10 benchmarks, together with those who already use instruments and exterior APIs, equivalent to R Zero, Absolute Zero, SPIRAL, and Socratic Zero. This reveals that co-evolution and built-in design of instruments is a significant step past earlier single-round self-play approaches.
Modifying notes
Agent0 is a crucial step towards sensible data-free reinforcement studying for tool-integrated inference. This reveals that the bottom LLM can act as each a curriculum agent and an executor agent, and that GRPO with ADPO and VeRL instruments can drive secure enhancements from majority-voted spurious labels. The strategy additionally reveals that the coevolution built-in into the instrument can outperform earlier zero information frameworks equivalent to R Zero and Absolute Zero on a powerful Qwen3 baseline. Agent0 makes a powerful case that self-evolving, tool-integrated LLM brokers have gotten a viable coaching paradigm.
Please test paper and lipo. Please be at liberty to test it out GitHub page for tutorials, code, and notebooks. Please be at liberty to comply with us too Twitter Do not forget to affix us 100,000+ ML subreddits and subscribe our newsletter. dangle on! Are you on telegram? You can now also participate by telegram.

Michal Sutter is an information science professional with a grasp’s diploma in information science from the College of Padova. With a powerful basis in statistical evaluation, machine studying, and information engineering, Michal excels at remodeling advanced datasets into actionable insights.

{kind=link}