


Multimodal large-scale language fashions (MLLMs) are a cutting-edge innovation in synthetic intelligence that mixes the capabilities of language and imaginative and prescient fashions to deal with advanced duties resembling visible query answering and picture captioning. These fashions leverage large-scale pre-training and combine a number of knowledge modalities to considerably enhance efficiency in a wide range of functions. The mixing of language and visible knowledge allows these fashions to carry out duties beforehand not potential with single-modality fashions, representing a significant development in AI.
The primary situation with MLLM is its intensive useful resource necessities, which severely hinders its widespread adoption. Coaching these fashions requires enormous computational assets, which are sometimes solely obtainable to massive enterprises with deep budgets. For instance, coaching a mannequin like MiniGPT-v2 requires over 800 GPU hours on an NVIDIA A100 GPU, which is cost-prohibitive for a lot of educational researchers and small and medium-sized enterprises. Furthermore, the excessive computational price of inference additional exacerbates this situation, making it troublesome to deploy these fashions in resource-constrained environments resembling edge computing.
✅ [Featured Article] LLMWare.ai named to the 2024 GitHub Accelerator: Small, specialised language fashions allow the subsequent wave of enterprise RAG innovation
Present strategies to deal with these challenges concentrate on optimizing the effectivity of MLLM. Fashions resembling OpenAI’s GPT-4V and Google’s Gemini obtain good efficiency by means of intensive pre-training, however their computational necessities restrict their use. Analysis has explored varied methods to create environment friendly MLLMs by decreasing mannequin measurement and optimizing computational methods. This consists of leveraging pre-training information for every modality, which reduces the necessity to prepare fashions from scratch and saves assets.
Researchers from Tencent, SJTU, BAAI, and ECNU carried out an intensive survey on environment friendly MLLM and categorized latest advances into a number of key areas: structure, imaginative and prescient processing, language mannequin effectivity, coaching methods, knowledge use, and sensible functions. Their work offers a complete overview of the sector and provides a structured method to rising useful resource effectivity with out sacrificing efficiency. The work highlights the significance of creating light-weight architectures and specialised parts tuned for effectivity optimization.
Environment friendly MLLM employs a number of revolutionary methods to deal with the useful resource consumption situation. This consists of introducing light-weight architectures designed to cut back parameter and computational complexity. For instance, fashions resembling MobileVLM and LLaVA-Phi use imaginative and prescient token compression and environment friendly imaginative and prescient language projectors to extend effectivity. Imaginative and prescient token compression, for instance, reduces the computational burden by compressing high-resolution pictures into extra manageable patch options, considerably decreasing the computational price related to processing massive quantities of visible knowledge.
The examine reveals important efficiency enhancements for environment friendly MLLM. By using token compression and light-weight mannequin buildings, these fashions obtain important computational effectivity beneficial properties, broadening their scope of software. For instance, LLaVA-UHD helps processing pictures with as much as 6x the decision at 94% of the computational complexity in comparison with earlier fashions. This makes it potential to coach these fashions in educational environments, with some fashions skilled in simply 23 hours utilizing eight A100 GPUs. These effectivity beneficial properties don’t come on the expense of efficiency, with fashions resembling MobileVLM displaying aggressive outcomes on high-resolution picture and video understanding duties.
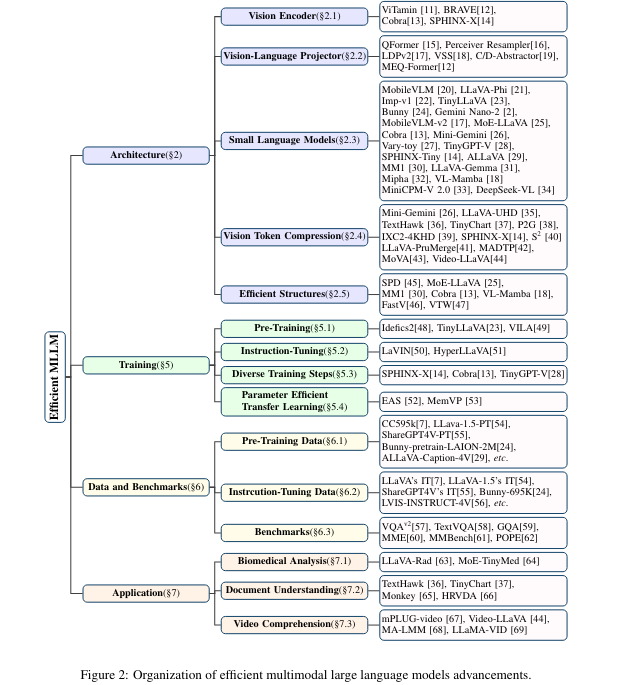
The primary takeaways from this survey on environment friendly multimodal large-scale language fashions are:
- Useful resource necessities: MLLMs like MiniGPT-v2 require over 800 hours on an NVIDIA A100 GPU to coach, making it troublesome for smaller organizations to leverage these fashions, and the excessive computational price of inference additional limits deployment in resource-constrained environments.
- Optimization methods: This analysis focuses on creating environment friendly MLLM by decreasing the mannequin measurement, optimizing the computational technique, and leveraging pre-trained modality information to save lots of assets.
- Pay as you go Classification: The survey categorizes advances into structure, imaginative and prescient processing, language mannequin effectivity, coaching methods, knowledge use, and sensible functions, offering a complete overview of the sector.
- Imaginative and prescient Token Compression: Methods resembling imaginative and prescient token compression scale back the computational burden by compressing high-resolution pictures into extra manageable patch options, considerably decreasing computational prices.
- Coaching Effectivity: Environment friendly MLLM may be skilled in an educational atmosphere, with some fashions skilled in simply 23 hours utilizing eight A100 GPUs. Adaptive visible token discount and multi-scale data fusion improve fine-grained visible recognition.
- Efficiency enhancements: Fashions such because the LLaVA-UHD help picture processing at as much as six instances the decision with 94% of the computational effort in comparison with earlier fashions, delivering important effectivity beneficial properties.
- Environment friendly structure: MLLM makes use of a lighter-weight structure, efficiency-focused parts, and novel coaching strategies to realize notable efficiency beneficial properties whereas decreasing useful resource consumption.
- Cut back characteristic data: Methods resembling funnel transformers and set transformers scale back the dimensionality of enter options whereas retaining vital data, enhancing computational effectivity.
- Approximate Be aware: Kernelization and low-rank strategies remodel and decompose high-dimensional matrices, making the eye mechanism extra environment friendly.
- Understanding the documentation and movies: Environment friendly MLLM has been utilized to doc and video understanding, and fashions resembling TinyChart and Video-LLaVA tackle the challenges of high-resolution picture and video processing.
- Data Distillation and Quantization: Data distillation permits smaller fashions to study from bigger ones, and quantization reduces the accuracy of ViT fashions, decreasing reminiscence utilization and computational complexity whereas sustaining accuracy.
In conclusion, analysis on environment friendly MLLM addresses important obstacles to the extra widespread use of MLLM by proposing methods to cut back useful resource consumption and enhance accessibility. By creating light-weight architectures, optimizing computational methods, and using revolutionary methods resembling imaginative and prescient token compression, researchers have made important advances within the area of MLLM. These efforts have enabled researchers and organizations to leverage these highly effective fashions and improve their applicability in real-world situations resembling edge computing and resource-limited environments. The advances highlighted on this examine present a roadmap for future analysis and spotlight the potential for environment friendly MLLM to democratize superior AI capabilities and enhance their real-world applicability.
Please verify paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, remember to observe us. twitter. take part Telegram Channel, Discord Channeland LinkedIn GroupsUp.
Should you like our work, you’ll love our Newsletter..
Please be a part of us 43,000+ ML subreddits
![]()
Aswin AK is a Consulting Intern at MarkTechPost. He’s pursuing a twin diploma from Indian Institute of Expertise Kharagpur. He’s enthusiastic about Information Science and Machine Studying and has a robust educational background and sensible expertise in fixing real-world cross-domain issues.

{kind=link}