


Monetary establishments course of hundreds of advanced paperwork each day. Optical Character Recognition (OCR) errors in monetary information can propagate via interconnected calculations, affecting analytical accuracy. Whereas a single OCR error in a regular authorized doc may require solely a fast handbook correction, the identical mistake in monetary information can cascade via interconnected calculations, resulting in systematic errors in evaluation and doubtlessly expensive to organizations.
Conventional OCR instruments fall critically brief when processing the advanced monetary paperwork that establishments deal with each day—stability sheets, earnings statements, SEC filings, analysis reviews, and audit supplies. These paperwork characteristic intricate desk buildings with merged cells and hierarchical information, multi-column layouts with interconnected references, and context-dependent info requiring semantic understanding. Conventional OCR approaches deal with these paperwork as photos, lacking the structural relationships and contextual nuances that make monetary paperwork significant. The result’s a cascade of handbook corrections, information entry delays, and systematic analytical errors.
This submit demonstrates the best way to construct a documentation extraction and mannequin fine-tuning pipeline that addresses these vital challenges. By combining Pulse AI’s superior doc understanding capabilities with the highly effective AI providers of Amazon Bedrock, organizations can obtain enterprise-grade accuracy and extract contextually related monetary insights at scale. Amazon Bedrock delivers absolutely managed mannequin customization with zero machine studying (ML) ops overhead, on-demand deployment with out capability planning, and the Nova mannequin household gives robust cost-to-performance traits, so groups can deal with innovation slightly than infrastructure.
Not like conventional monolithic OCR pipelines,Pulse integrates imaginative and prescient language fashions with classical ML parts particularly engineered for doc understanding, creating an clever answer that extracts structured information with semantic consciousness, generates improved supervised fine-tuning datasets for monetary area fashions, and allows deployment of {custom} giant language fashions (LLMs) skilled in your particular monetary information. Pulse is deployed throughout world enterprises together with Samsung, Cloudera, Howard Hughes, and Fortune 500 monetary establishments and main non-public fairness corporations processing excessive volumes of economic and operational paperwork.
In a single deployment, a batch of about 1,000 advanced monetary paperwork that beforehand required multi day turnaround was processed in beneath three hours, producing structured, auditable outputs prepared for downstream analytics and AI purposes.
Fig 1 : Doc processing workflows: Conventional vs. Pulse
In abstract, Pulse AI and Amazon Bedrock collectively gives:
- Pulse AI extracts structured, semantically-aware information from advanced monetary paperwork dealing with intricate tables, multi-column layouts, and hierarchical information.
- Amazon Bedrock fine-tunes Amazon Nova fashions on that high-quality information to create domain-specific intelligence on your group’s monetary conventions.
- Customized fashions then course of new paperwork with organization-specific understanding, decreasing handbook evaluate from days to hours.
The next workflow demonstrates an method to constructing clever monetary purposes powered. Beginning with uncooked monetary paperwork, the pipeline orchestrates a complicated sequence of steps—from doc processing and fine-tuning, and deployment—to create a {custom} AI answer tailor-made to monetary information evaluation and insights.
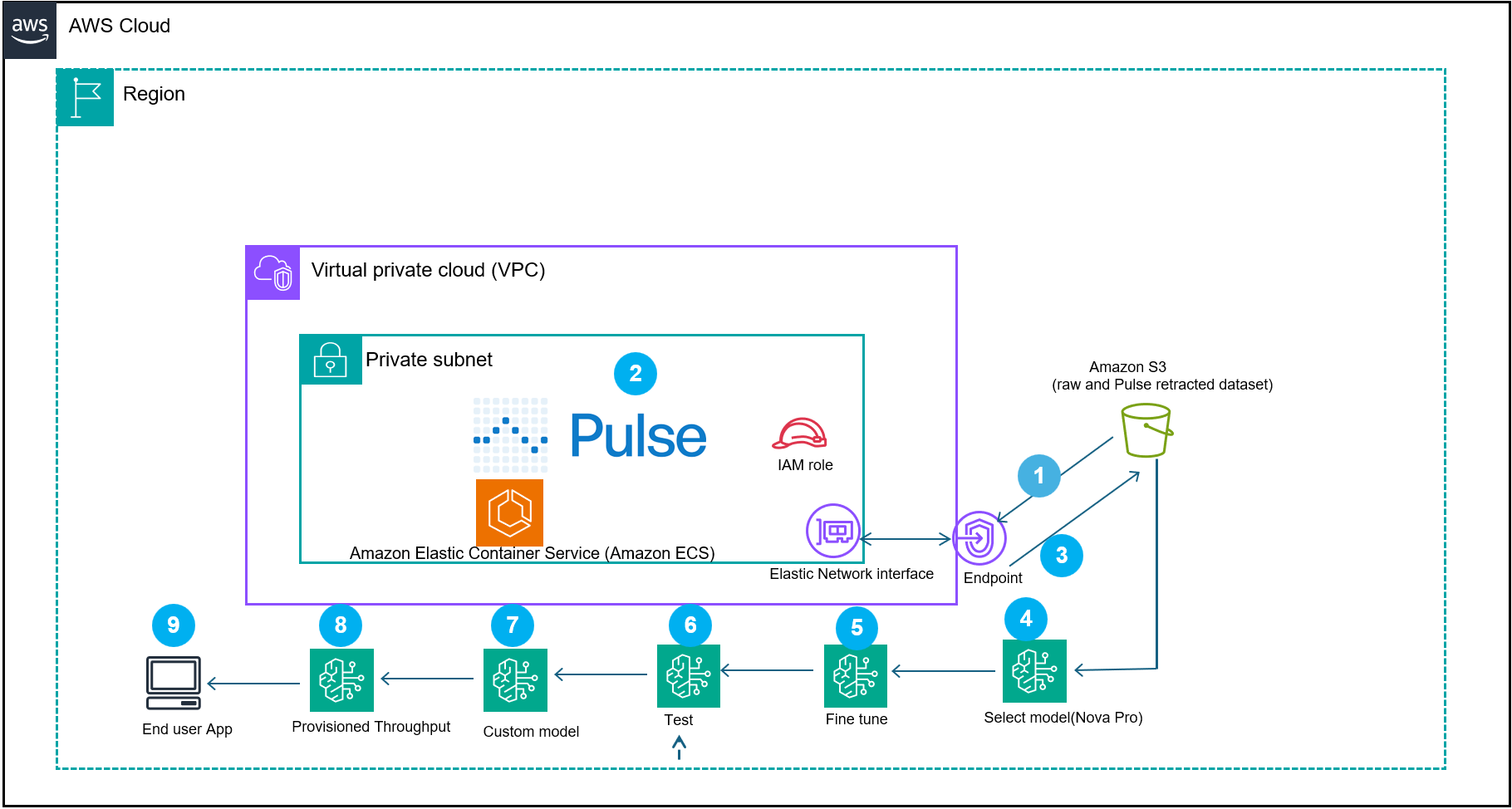
Fig 2: represents a doc processing reference structure workflow that demonstrates how Pulse AI, built-in with AWS providers, creates domain-specific fashions for clever doc processing (IDP)
The system begins by (step 1) ingesting the paperwork into the Pulse container in your VPC or Pulse software program as a service (SAAS) providing. The Pulse mannequin processes the monetary paperwork (step 2). The output of the extracted information will get transformed to Amazon Bedrock Nova Micro supervised fine-tuning format after which will get saved in an Amazon Easy Storage Service (Amazon S3) (step 3).
The workflow then makes use of different prolonged options of Amazon Bedrock:
A supervised fine-tuning job runs utilizing Amazon Nova Micro (amazon.nova-micro-v1:0) and a cost-efficient mannequin designed for text-based extraction duties with a 128K context window (Step 5 and 6). Nova Micro gives aggressive value efficiency. After job completion, deploy the ensuing mannequin for on-demand inference. It’s also possible to use Provisioned Throughput for mission-critical workloads that require constant efficiency. Use Take a look at in Playground to guage and examine responses. The ensuing {custom} mannequin is imported into Amazon Bedrock (step 8) and deployed with provisioned throughput (step 9) to energy a scalable end-user utility (step 10). This structure combines the area particular monetary dataset with the {custom} supervised fine-tuned mannequin, so organizations can construct production-ready AI purposes that perceive monetary context whereas sustaining efficiency and value effectivity.
Stipulations
You have to have the next conditions to observe together with this submit.
Word: This tutorial creates AWS assets that incur fees, together with: EC2 occasion (hourly), S3 storage (per GB-month), Amazon Bedrock fine-tuning (per coaching hour), provisioned throughput deployment (hourly), and AWS Secrets and techniques Supervisor (per secret per thirty days).
Step-by-step implementation
Observe these steps to arrange and configure your monetary doc processing pipeline utilizing Pulse AI and Amazon Bedrock.
- Navigate to the Pulse console and create an account.
- Launch an EC2 occasion utilizing the AWS Console.
- Navigate to the EC2 console.
- Select Launch Occasion.
- Within the AMI choice display, seek for Amazon Linux 2023 AMI.
- Choose Amazon Linux 2023 AMI.
- Within the occasion sort display, choose t3.medium.
- Create new key pair for SSH entry to the Linux occasion.
- Within the safety group configuration, add a rule to permit SSH (port 22) out of your IP tackle.
- Select Launch.
- Save the occasion ID that seems within the success message.
- Create your API key from the RunPulse.
- To search out your occasion’s public DNS,
- Navigate to the EC2 console.
- Choose your occasion.
- Copy the Public IPv4 DNS worth from the Particulars tab.
- To connect with your EC2 occasion, run the next SSH command. Substitute
YOUR_KEY_FILE.pemalong with your precise key pair filename andYOUR_INSTANCE_DNSwith the Public IPv4 DNS worth from step 4a:ssh -i YOUR_KEY_FILE.pem ec2-user@YOUR_INSTANCE_DNS Instance: ssh -i my-keypair.pem ec2-user@ec2-54-123-45-67.compute-1.amazonaws.com - In your EC2 occasion configure your AWS credentials by operating aws configure. When prompted, enter your Entry Key ID, secret entry key, Area (
us-east-1), and output format (json). - Retailer your Pulse API key in AWS Secrets and techniques Supervisor utilizing the command supplied:
aws secretsmanager create-secret --name pulse-api-key --secret-string "your-api-key" - Word down the ARN, because it required for the permissions coverage
Word: AWS Command Line Interface (AWS CLI) model 2 comes pre-installed on Amazon Linux 2023 AMIs by default.
- Below your EC2 occasion, set up the runpulse SDK.
- Set up pip:
sudo yum set up pip - Set up the Pulse Python SDK:
pip set up pulse-python-sdk
- Set up pip:
- In your EC2 occasion, create a file named bedrock-trust-policy.json in your present working listing with the configuration proven within the following part. You should utilize a textual content editor like nano or vi: nano
bedrock-trust-policy.json.- Create
bedrock-trust-policy.json{ "Model": "2012-10-17", "Assertion": [ { "Effect": "Allow", "Principal": { "Service": "bedrock.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "aws:SourceAccount": "your-aws-account-ID" }, "ArnLike": { "aws:SourceArn": "arn:aws:bedrock:us-east-1:your-aws-account-ID:model-customization-job/*" } } } ] } - Create
bedrock-permissions.json{ "Model": "2012-10-17", "Assertion": [ { "Sid": "S3AccessForFineTuning", "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject", "s3:ListBucket" ], "Useful resource": [ "arn:aws:s3:::your-bucket-name", "arn:aws:s3:::your-bucket-name/*" ] }, { "Sid": "SecretsManagerAccess", "Impact": "Permit", "Motion": [ "secretsmanager:GetSecretValue", "secretsmanager:PutSecretValue", "secretsmanager:CreateSecret", "secretsmanager:UpdateSecret", "secretsmanager:DescribeSecret" ], "Useful resource": [ "arn:aws:secretsmanager:us-east-1:your-aws-account-ID:secret:your-secret-name-*" ] } ] } - Then create the function:
aws iam create-role --role-name AmazonBedrock-FineTuning-S3-Position --assume-role-policy-document file://bedrock-trust-policy.json --description "Position for Bedrock fine-tuning with S3 and Secrets and techniques Supervisor entry"Anticipated output: JSON with function ARN, ID, and creation timestamp. Subsequent,
- Create
- Create the permissions coverage:
aws iam put-role-policy --role-name AmazonBedrock-FineTuning-S3-Position --policy-name Bedrock-S3-Entry-Coverage --policy-document file://bedrock-permissions.json
- View the function and belief coverage:
aws iam get-role --role-name AmazonBedrock-FineTuning-S3-Position- To extract the dataset from the reference financial document, run the next command on the EC2 occasion
# Retrieve API key from Secrets and techniques Supervisor. Safety finest observe: Don’t hardcode credentials. Retrieve from AWS Secrets and techniques Supervisor.
curl -X POST https://api.runpulse.com/extract -H "x-api-key: $(aws secretsmanager get-secret-value --secret-id pulse-api-key --query SecretString --output textual content)" -H "Content material-Sort: utility/json" -d '{ "file_url": "https://www.impact-bank.com/consumer/file/dummy_statement.pdf", "figureProcessing": {"description": true}, "extensions": {"altOutputs": {"returnHtml": true}} }'> pulse_output.jsonPulse AI pattern extracted json snippet:
{"bounding_boxes":{"Header":[{"average_word_confidence":0.9940000000000001,"bounding_box":[0.7418,0.04248181818181818,0.8901529411764706,0.042281818181818184,0.8901764705882352,0.05528181818181818,0.741835294117647,0.05548181818181818],"content material":"0a-Account # 12345678","id":"txt-8","original_content":"Account # 12345678","page_number":2}],"Web page Quantity":[{"average_word_confidence":0.99425,"bounding_box":[0.8071411764705881,0.24754545454545454,0.889635294117647,0.2474909090909091,0.8896588235294117,0.2616454545454545,0.8071529411764706,0.2617],"content material":"0a-Web page 1 of two","id":"txt-3","original_content":"Web page 1 of two","page_number":1},{"average_word_confidence":0.9925,"bounding_box":[0.8076235294117646,0.057600000000000005,0.8898117647058823,0.05738181818181818,0.8898705882352942,0.0704,0.8076823529411765,0.07061818181818182],"content material":"0a-Web page 2 of two","id":"txt-9","original_content":"Web page 2 of two","page_number":2}],"Tables":[{"cell_data":[{"confidence":0.9772562500000003,"location":{"coordinates":[0.0906,0.44435454545454545,0.8865647058823529,0.44499090909090905,0.8865647058823529,0.4685,0.0906,0.4678636363636363],"web page":1},"place":{"column":0,"row":0},"properties":{"spans_columns":4,"sort":"header"},"textual content":"0t-"},- Confirm the extraction succeeded by checking the file exists and incorporates legitimate JSON
jq empty pulse_output.json && echo "Legitimate JSON" || echo " Invalid JSON"- Subsequent, convert the extracted information to a Nova coaching dataset.
- Create a brand new file named convert_to_nova.py and paste the next code.
import jsonINPUT_FILE = "pulse_output.json" OUTPUT_FILE = "nova_dataset.jsonl"MAX_TOKENS = 30000 # Buffer beneath 32,768 limitdef estimate_tokens(textual content): """Tough token estimation: ~4 characters per token""" return len(textual content) // 4def create_truncated_samples(information): """Creates smaller coaching samples inside token limits""" samples = [] # Pattern 1: Header and Web page Quantity provided that "bounding_boxes" in information: if "Header" in information["bounding_boxes"] and "Web page Quantity" in information["bounding_boxes"]: header_sample = { "Header": information["bounding_boxes"]["Header"], "Web page Quantity": information["bounding_boxes"]["Page Number"] } samples.append({ "doc": header_sample, "extracted_data": header_sample }) # Samples 2-4: Particular person tables (truncated to twenty cells) if "Tables" in information["bounding_boxes"]: for i, desk in enumerate(information["bounding_boxes"]["Tables"][:3]): truncated_table = { "table_info": desk.get("table_info", {}), "cell_data": desk.get("cell_data", [])[:20] } samples.append({ "doc": {"Tables": [truncated_table]}, "extracted_data": {"Tables": [truncated_table]} }) # Samples 5-7: Textual content chunks (3 objects every) if "Textual content" in information["bounding_boxes"]: text_items = information["bounding_boxes"]["Text"] chunk_size = 3 for i in vary(0, min(9, len(text_items)), chunk_size): text_chunk = {"Textual content": text_items[i:i+chunk_size]} samples.append({ "doc": text_chunk, "extracted_data": text_chunk }) # Pattern 8: Title provided that "Title" in information["bounding_boxes"]: title_sample = {"Title": information["bounding_boxes"]["Title"]} samples.append({ "doc": title_sample, "extracted_data": title_sample }) return samplesdef convert_to_nova_format(pattern): """ Converts to Nova format with tutorial prompts for domain-specific studying This operate creates coaching samples that train the mannequin: 1. Monetary doc construction recognition (headers, tables, transactions) 2. Information sort standardization (dates to ISO 8601, quantities to numbers) 3. Hierarchical relationship preservation (accounts → transactions → particulars) 4. Out-of-sequence detection (objects marked with *) 5. Monetary area conventions (test numbers, terminal IDs, service provider information)""" doc_str = json.dumps(pattern["document"]) extract_str = json.dumps(pattern["extracted_data"]) total_tokens = estimate_tokens(doc_str) + estimate_tokens(extract_str) if total_tokens > MAX_TOKENS: print(f"Warning: Pattern too giant ({total_tokens} tokens), skipping...") return None return { "schemaVersion": "bedrock-conversation-2024", "messages": [ { "role": "user", "content": [{"text": doc_str}] }, { "function": "assistant", "content material": [{"text": extract_str}] } ] }# Learn inputwith open(INPUT_FILE, "r") as f: pulse_data = json.load(f)if isinstance(pulse_data, dict): pulse_data = [pulse_data]# Generate truncated samplesall_samples = []skipped = 0for document in pulse_data: truncated_samples = create_truncated_samples(document) for pattern in truncated_samples: nova_record = convert_to_nova_format(pattern) if nova_record: all_samples.append(nova_record) else: skipped += 1# Write to JSONLwith open(OUTPUT_FILE, "w") as f: for nova_record in all_samples: f.write(json.dumps(nova_record) + "n")print(f"✓ Created {len(all_samples)} coaching samples")print(f"✓ Skipped {skipped} samples that had been too giant")print(f"✓ Output saved to: {OUTPUT_FILE}")print(f"All samples are beneath {MAX_TOKENS} tokens (restrict: 32,768)")print(f"Subsequent steps:")print(f"1. Confirm: wc -l {OUTPUT_FILE}")print(f"2. Add: aws s3 cp {OUTPUT_FILE} s3://anypulse/training-data/nova_dataset.jsonl")print(f"3. Create new fine-tuning job")"""TRAINING FORMAT EXPLANATION:What this fine-tuning teaches Nova Micro:This conversion script creates coaching samples in a format that teaches Nova Micro domain-specific monetary doc understanding via sample studying. Whereas the coaching samples use a direct JSON-to-JSON mapping (consumer message incorporates Pulse extracted JSON, assistant message incorporates the identical structured JSON), the mannequin learns a number of key capabilities:1. DOCUMENT STRUCTURE RECOGNITION - Hierarchical relationships: Headers → Tables → Textual content → Web page Numbers - Bounding field spatial understanding: Coordinate techniques and component positioning - Multi-page doc dealing with: Web page quantity monitoring and cross-page references 2. FINANCIAL DATA PATTERNS - Desk construction preservation: Row/column semantics, cell-level extraction - Confidence rating interpretation: Excessive-confidence fields (0.99+) vs. decrease confidence - Information sort consistency: Account numbers, dates, financial quantities, test numbers 3. STRUCTURAL CONSISTENCY - Area naming conventions: "content material", "confidence", "page_number", "bounding_box" - Nested object relationships: Tables include cell_data arrays with place metadata - Metadata preservation: Original_content alongside normalized values for audit trails4. DOMAIN-SPECIFIC CONVENTIONS - Monetary doc sections: Headers, footers, transaction tables, abstract sections - Out-of-sequence detection: Objects marked with asterisk (*) in test numbers - Service provider information extraction: Terminal IDs, location info, transaction referencesLEARNING MECHANISM:The mannequin learns via publicity to Pulse AI's high-quality structured extraction patterns. By seeing a whole lot of examples of how Pulse buildings monetary doc information (with confidence scores, bounding containers, hierarchical relationships), Nova Micro internalizes these patterns and might apply them to new monetary paperwork.This method is efficient as a result of:- Pulse AI gives persistently structured, high-quality coaching data- The JSON schema is self-documenting (area names point out goal)- Repetition throughout samples reinforces structural patterns- Confidence scores train the mannequin which extractions are reliableALTERNATIVE APPROACHES:For manufacturing deployments requiring extra express process framing, think about including tutorial prompts to the coaching samples: instructional_prompt = f'''You're a monetary doc extraction specialist. Extract structured info from the next monetary doc and return it as legitimate JSON. Necessities: - Extract all key monetary information (accounts, balances, transactions, dates) - Use constant area naming (snake_case format) - Convert dates to ISO 8601 format (YYYY-MM-DD) - Symbolize financial quantities as numbers with forex metadata - Protect hierarchical relationships - Detect out-of-sequence objects (marked with *) Monetary Doc: {doc_str} Return solely the extracted JSON with out explanations.'''This tutorial method gives express necessities and process context, which may enhance generalization to doc varieties not seen throughout coaching. Nevertheless, for workflows the place Pulse AI handles extraction and the mannequin primarily learns to duplicate Pulse's output construction, the present direct mapping method is enough and avoids token overhead from prolonged directions.PRODUCTION CONSIDERATIONS:- Coaching dataset measurement: 100–500 samples for pilot, 5,000–10,000 for production- Analysis metrics: Examine fine-tuned mannequin output towards Pulse baseline- Iterative enchancment: Retrain quarterly with new doc varieties and edge cases- High quality monitoring: Monitor confidence scores and handbook evaluate charges post-deployment"""Run the conversion script: python3 convert_to_nova.py
It will generate a jsonl file: nova_dataset.jsonl
Nova Micro ought to be taught to do the next in another way after fine-tuning, Full Doc construction recognition, complete desk extraction, cross-document information integration and monetary doc conventions.
- Create the S3 bucket for coaching information (if not already created):
aws s3 mb s3://your-unique-bucket-name --region us-east-1Allow versioning for information safety:
aws s3api put-bucket-versioning --bucket your-unique-bucket-name --versioning-configuration Standing=Enabled- Write the Nova coaching dataset to your S3 coaching bucket for the Amazon Bedrock Nova positive tuning
aws s3 cp nova_dataset.jsonl s3://<your s3 bucket>/training-data/Word: Amazon Bedrock fine-tuning jobs and {custom} mannequin deployments incur fees. Overview Amazon Bedrock pricing at https://aws.amazon.com/bedrock/pricing/ earlier than continuing.
- Subsequent run the Amazon Bedrock coaching job
aws bedrock create-model-customization-job --job-name my-fine-tuning-job-nova-micro --custom-model-name my-custom-pulse-model-nova-micro --role-arn arn:aws:iam::<Your-AWS-Account>:function/AmazonBedrockNovaFineTuningRole --base-model-identifier amazon.nova-micro-v1:0:128k --training-data-config s3Uri=s3://<your-s3-bucket>/training-data/nova_dataset.jsonl --output-data-config s3Uri=s3://<your-s3-bucket>/output/ --hyper-parameters '{"epochCount":"2","learningRate":"0.00001","learningRateWarmupSteps":"10"}'- You possibly can monitor the coaching progress utilizing the console

Or by operating the next command
export CUSTOM_MODEL_ARN=$(aws bedrock get-model-customization-job --job-identifier "<JobArn>" --region us-east-1 --query 'outputModelArn' --output textual content)echo "Your {custom} mannequin ARN: $CUSTOM_MODEL_ARN"the jobArn might be retrieved from the console or from the output of the ran job.
As soon as full, the console will replicate the standing

- To deploy the brand new {custom} mannequin, run:
aws bedrock create-custom-model-deployment --model-deployment-name "my-custom-pulse-model-deployment" --model-arn "$CUSTOM_MODEL_ARN" --region us-east-1- To test the standing of the {custom} mannequin deployment
aws bedrock get-custom-model-deployment --custom-model-deployment-identifier "your-deployment-name-or-arn" --region us-east-1Standing “Energetic” confirms accomplished deployment
Confirm that the mannequin is prepared:
aws bedrock get-provisioned-model-throughput --provisioned-model-id <model-id> --region us-east-1Verify the standing reveals “InService” earlier than continuing to testingTesting utilizing the Amazon Bedrock playground.
Immediate used for testing :
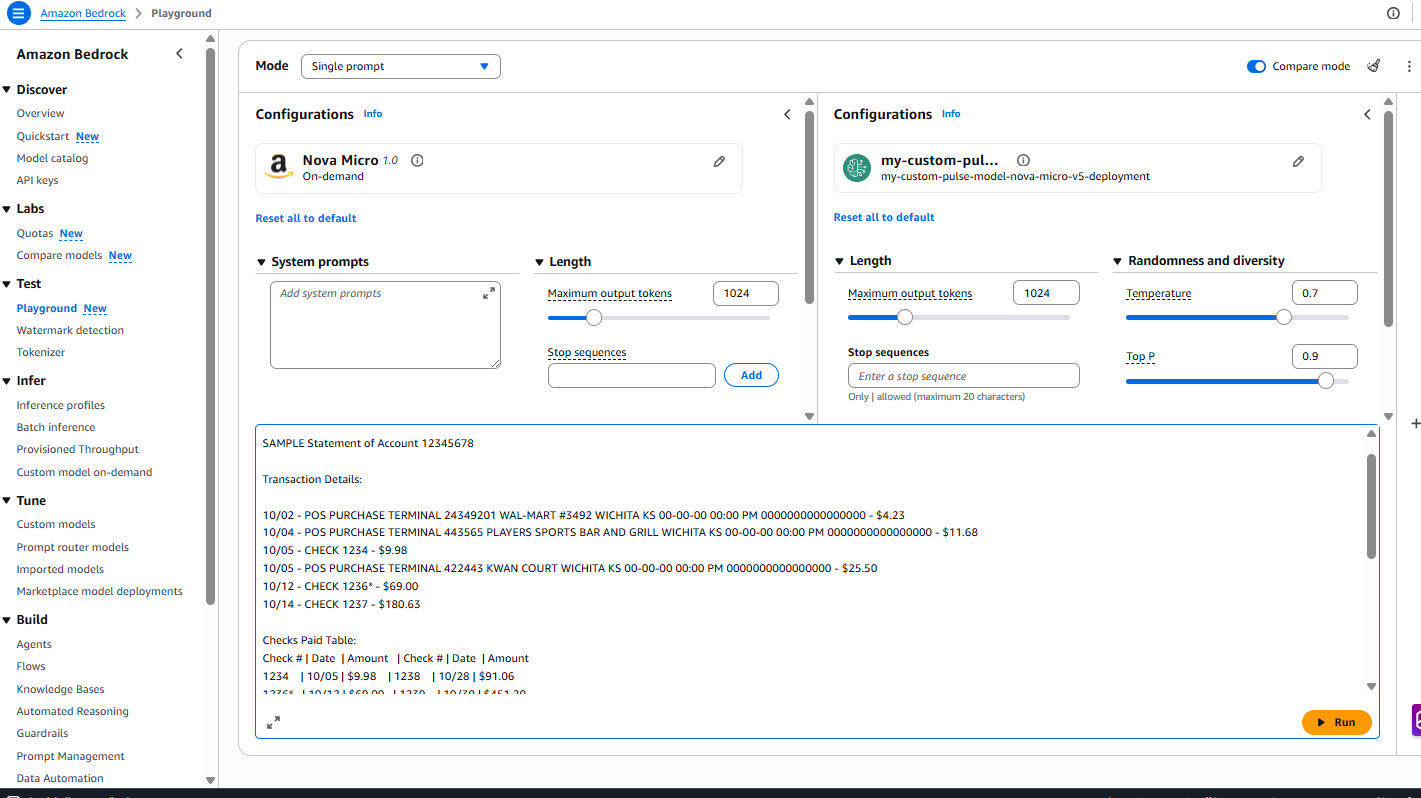
Outcomes:
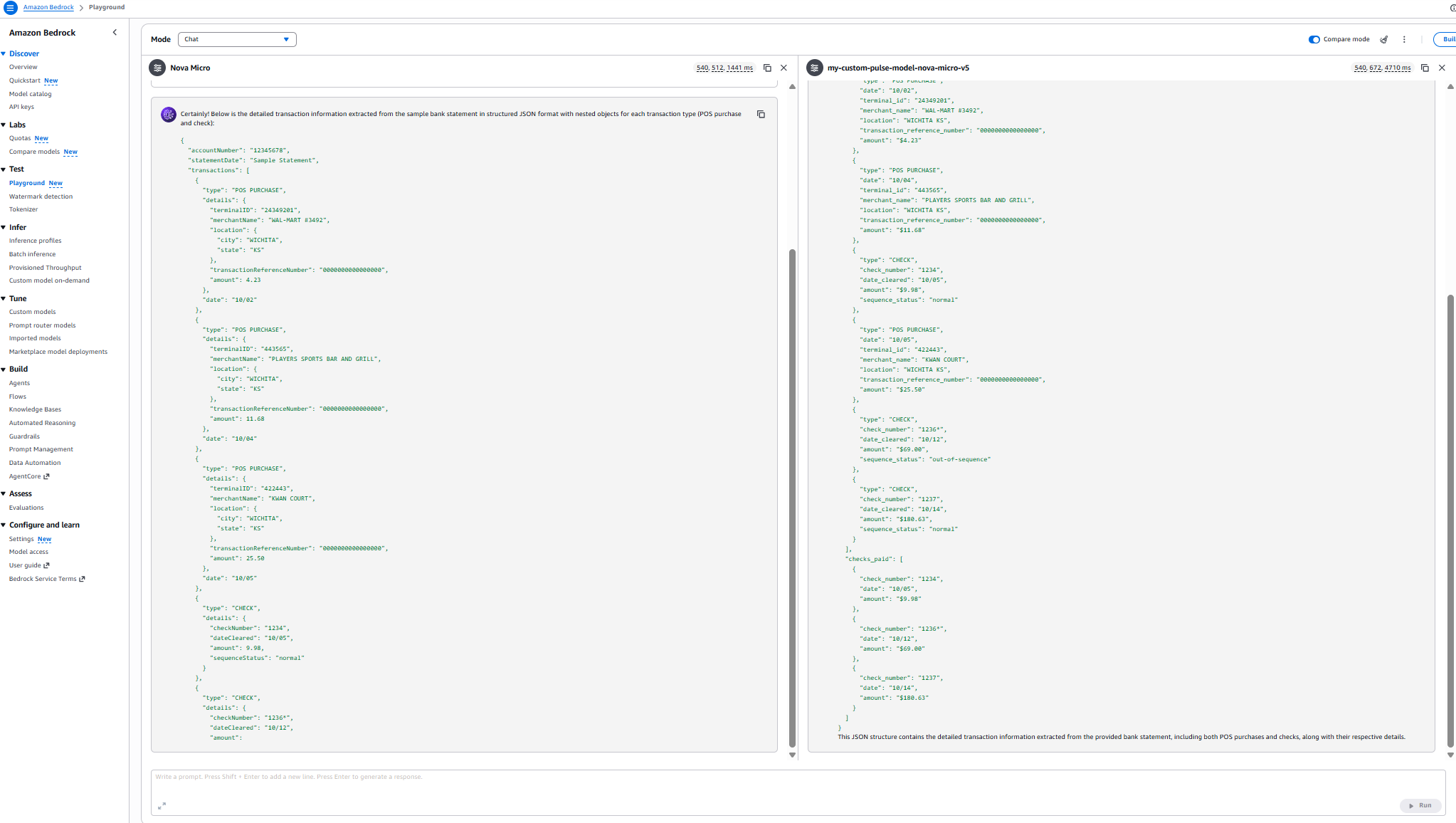
Efficiency comparability
Mannequin comparability: Area information analysis
| Metric | Nova Micro (Base) | my-custom-pulse-model-nova-micro-v5 |
| Latency | 540,508 ms (~9 min) | 543,600 ms (~9 min 3.6 sec) |
| Checks Extracted | 3 out of 6 | 6 out of 6 |
| POS Purchases Extracted | 3 out of three | 3 out of three |
| Transaction Group | Separated by sort | Chronological order |
| Completeness | 50% of test information | 100% of test information |
| Sequence Standing Accuracy | Partial (3 checks) | Full (all 6 checks) |
| JSON Construction | Segmented format | Unified transaction record |
| Area Data | Primary extraction | Complete doc understanding |
disclaimer :These metrics are particular to the pattern doc dataset. Your outcomes will fluctuate
Cleanup
Full the next cleanup duties to keep away from incurring fees.
- Delete the occasion profile:
aws iam delete-instance-profile --instance-profile-name BedrockTutorialProfile - Terminate the EC2 occasion:
aws ec2 terminate-instances --instance-ids <instance-id> - Delete the safety group:
aws ec2 delete-security-group --group-id <security-group-id> --region us-east-1 - Delete the important thing pair:
aws ec2 delete-key-pair --key-name <key-pair-name> --region us-east-1 - Delete the {custom} mannequin deployment:
aws bedrock delete-custom-model-deployment --custom-model-deployment-identifier <deployment-name> --region us-east-1 - Delete the {custom} mannequin:
aws bedrock delete-custom-model --model-identifier $CUSTOM_MODEL_ARN --region us-east-1
Warning: Information Loss Threat – The next instructions will completely delete all coaching information and outputs.
Earlier than continuing: 1) Confirm the S3 bucket incorporates solely tutorial information, 2) Again up any recordsdata that it’s essential retain, 3) Verify that you’ve famous the bucket identify appropriately.
- Delete the fine-tuning coaching information from S3:
aws s3 rm s3://<your-bucket>/training-data/ --recursive - Delete the fine-tuning job outputs from S3:
aws s3 rm s3://<your-bucket>/output/ --recursive - Delete the S3 bucket if not wanted:
aws s3 rb s3://<your-bucket> - Take away the IAM insurance policies:
aws iam delete-role-policy --role-name AmazonBedrock-FineTuning-S3-Position --policy-name Bedrock-S3-Entry-Coverage- Delete the Secrets and techniques Supervisor secret:
aws secretsmanager delete-secret --secret-id pulse-api-key --force-delete-without-recovery --region us-east-1 - Delete the fine-tuning job:
aws bedrock stop-model-customization-job --job-identifier <job-arn> --region us-east-1
This AWS weblog gives detailed directions for iterative fine-tuning, so you possibly can construct upon beforehand custom-made fashions for steady enchancment with out ranging from scratch.Pulse converts unstructured paperwork into structured, schema aligned outputs. These outputs might be programmatically exported into JSONL datasets appropriate with Amazon Bedrock fine-tuning necessities for textual content and imaginative and prescient fashions.This basically lets Pulse deal with the heavy lifting of extraction and information high quality, whereas making it easy to generate the coaching datasets required for mannequin customization on Amazon Bedrock.
Conclusion
By combining Pulse AI’s superior doc understanding with the ML capabilities of AWS, you possibly can construct monetary information processing techniques which can be sooner, extra correct, and extra scalable than conventional approaches.This structure demonstrates a production-ready method to monetary doc processing utilizing Amazon Bedrock and Pulse AI. Getting began with Pulse AI is easy.
Join a Pulse AI Standard account to start utilizing fine-tuned fashions on your monetary workflows. For those who’re new to the system, the Pulse AI Quickstart Documentation gives step-by-step steering that will help you configure your first fine-tuning job and deploy {custom} fashions tailor-made to your group’s wants. For personalised help or questions on implementing fine-tuning at scale, attain out to the group at hey@runpulse.com—they’re prepared that will help you unlock the total potential of domain-specific AI.
The actual energy of fine-tuning emerges while you complement basis fashions (FMs) along with your group’s distinctive monetary datasets. By coaching fashions in your proprietary paperwork, terminology, and enterprise processes, you create specialised capabilities that generic fashions sometimes can not match. This method transforms AI from a general-purpose device right into a strategic asset that understands the nuances of your particular monetary area.
Extra assets
To deepen your understanding of supervised fine-tuning and discover superior implementation methods, seek the advice of the AWS Nova Fantastic-tuning Information and the documentation on customizing Amazon Nova Fashions. These assets present technical particulars on hyperparameter enhancements, information preparation finest practices, and deployment patterns. The Pulse API Documentation gives complete steering for integrating production-grade doc extraction capabilities into your present workflows.
Concerning the authors

{kind=link}