


Synthetic intelligence (AI) reasoning capabilities decide whether or not fashions can deal with advanced, real-world duties past easy sample matching. With robust reasoning, fashions can establish issues from ambiguous descriptions, apply insurance policies beneath competing constraints, adapt tone to delicate conditions, and supply full options that deal with root causes. With out sturdy reasoning, AI programs fail when confronted with nuanced situations requiring judgment, context consciousness, and multi-step problem-solving.
This put up evaluates the reasoning capabilities of our newest providing within the Nova household, Amazon Nova Lite 2.0, utilizing sensible situations that take a look at these essential dimensions. We examine its efficiency towards different fashions within the Nova household—Lite 1.0, Micro, Professional 1.0, and Premier—to elucidate how the newest model advances reasoning high quality and consistency.
Answer overview
We consider 5 Amazon Nova fashions throughout 5 buyer help situations, measuring efficiency on eight dimensions:
- Downside identification
- Answer completeness
- Coverage adherence
- Factual accuracy
- Empathy and tone
- Communication readability
- Logical coherence
- Sensible utility
An impartial evaluator mannequin (gpt-oss-20b) offers automated, unbiased scoring.
The analysis structure makes use of the identical Area: us-east-1 and robotically handles totally different API codecs: Converse API for Nova, OpenAI Chat Completions for gpt-oss-20b.
The pattern pocket book is accessible within the GitHub repository.
Check situations
To generate the situations analysis dataset, we use Claude Sonnet 4.5 by Anthropic on Amazon Bedrock to generate a pattern of 100 situations that pertain to widespread buyer help interactions. We don’t use any of the Nova fashions to generate the situations to keep away from any bias. We then randomly choose 5 situations for our testing functions that consider widespread real-world reasoning challenges:
- Indignant buyer grievance – Checks de-escalation, empathy, and downside decision when a buyer threatens to depart after delayed supply and poor service.
- Software program technical downside – Evaluates technical troubleshooting when an app crashes throughout photograph uploads regardless of primary troubleshooting makes an attempt.
- Billing dispute – Assesses investigation abilities and safety consciousness for unrecognized costs doubtlessly indicating unauthorized entry.
- Product defect report – Measures guarantee coverage utility and customer support for a two-month-old faulty product.
- Account safety concern – Checks urgency response and safety protocols for unauthorized password adjustments and fraudulent purchases.
Every state of affairs consists of key points to establish, required options, and related insurance policies—offering goal standards for analysis. Relying in your trade/area/use case, the situations and related context could also be totally different.
Implementation particulars
The analysis framework establishes a complete methodology for assessing mannequin efficiency throughout a number of dimensions concurrently. This systematic strategy ensures that every mannequin undergoes similar testing circumstances, enabling honest comparability of reasoning capabilities throughout the Nova household. The technical implementation handles the complexity of managing totally different API codecs whereas sustaining analysis consistency. The framework assumes an lively AWS account, entry to Nova fashions and gpt-oss-20b, together with the provision of the boto3 SDK, and pandas, matplotlib, seaborn, scipy and numpy packages.
Mannequin invocation
The system robotically detects which API format every mannequin requires and routes requests accordingly. Nova fashions (Lite, Micro, Professional, Premier) use Amazon Bedrock Converse API, which offers a unified interface for conversational interactions. gpt-oss fashions use the OpenAI Chat Completions format, requiring a special request construction with the InvokeModel API. The invocation operate checks the mannequin identifier to find out the suitable format. For gpt-oss fashions, it constructs a JSON request physique with messages, token limits, and temperature settings, then parses the response to extract the generated content material. For Nova fashions, it makes use of the Converse API with structured message objects and inference configuration parameters, extracting the response from the output message content material. This dual-API strategy helps seamless analysis throughout totally different mannequin households with out requiring separate code paths or handbook configuration adjustments. The identical analysis logic works for all fashions no matter their underlying API necessities, with the system dealing with format variations transparently. The structure additionally permits us to make use of fashions from totally different Areas whereas sustaining a single analysis workflow.
The analysis framework makes use of optimized prompts generated by the Amazon Bedrock Immediate Optimizer API. The optimizer analyzes and rewrites uncooked prompts to enhance mannequin efficiency with higher construction, readability, and group, creating model-specific optimizations for every Nova mannequin.
A state of affairs with the optimized immediate is proven within the following instance:
Analysis Framework
The evaluator receives the state of affairs, mannequin response, and analysis standards. We make use of a two-step scoring course of: first, the evaluator assigns a class label that finest characterizes the response; then, the evaluator assigns a predetermined rating equivalent to that class label. This strategy ensures a constant and uniform scoring methodology throughout all mannequin responses.
The analysis immediate construction:
The evaluator should justify scores, offering transparency into the evaluation. To handle transparency issues in AI analysis, the evaluator offers detailed reasoning for every of the eight dimensions, plus an general justification. This ensures that scores usually are not simply numerical however backed by particular explanations of why every rating was assigned.
Giant language mannequin (LLM)-as-a-judge analysis
Machine translation-based analysis strategies like ROUGE and BLEU fall brief on the subject of open ended conversations. LLM-as-a-judge offers scalability, flexibility and evaluations that intently match human preferences as much as 80%.
Check with the comparison table in the README for additional particulars.
Analysis course of
For every mannequin and state of affairs mixture, we carry out 10 runs to measure consistency. This produces 250 evaluations (5 fashions × 5 situations × 10 runs) offering a statistical unfold by a number of measurements. The variety of runs and situations may be elevated in line with the precise use case. The framework consists of diagnostic checks to confirm analysis high quality and reliability. Failed evaluations (the place the evaluator returns a rating of 0 resulting from technical points resembling JSON parsing errors, or when fashions don’t reply owing to blocked responses adhering to Accountable AI standards) are excluded from imply and customary deviation calculations to make sure correct efficiency metrics. This prevents technical failures from artificially decreasing mannequin scores.
Outcomes
The chosen situations and strategy described right here allow deep statistical evaluation of mannequin efficiency patterns. By inspecting each particular person state of affairs outcomes and combination metrics, we are able to establish strengths and potential areas for enchancment throughout the Nova mannequin household. This multi-dimensional evaluation strategy offers confidence within the reliability of efficiency rankings.
Statistical evaluation
The statistical analysis we use comply with the strategies outlined in Miller, 2024. To quantify uncertainty in mannequin efficiency estimates, we calculate customary error (SE) as:
SE = √(σ^2/n),
the place σ^2 is the pattern variance, and n is the pattern measurement. SE measures how exact our estimate of the imply is and tells us how a lot the pattern imply would range if we repeated the analysis many occasions. The usual error permits us to assemble 95% confidence intervals (CI = μ± 1.96×SE), the place μ is the pattern imply. This offers believable ranges for true mannequin efficiency, facilitating statistical significance testing by interval overlap evaluation. As well as, we introduce a coefficient of variation (CV) primarily based consistency rating calculated as (100 – CV%), the place CV% = (σ/μ)×100, and σ is the usual deviation. This normalizes reliability measurement on a 0-100 scale, thereby offering an intuitive metric for response stability. Lastly, zero-exclusion averaging prevents failed evaluations from artificially deflating scores, whereas error bars on visualizations transparently talk uncertainty. For the sake of completeness, the code within the GitHub repository calculates different statistics such at least detectable impact that demonstrates the power to reliably detect significant efficiency variations, a pairwise mannequin comparability metric that identifies correlations between mannequin responses, and an influence evaluation that validates the chosen pattern measurement. These methodologies remodel the analysis from easy rating comparability into rigorous experimental science with quantified uncertainty, enabling assured conclusions about mannequin efficiency variations.
Determine 1 Efficiency of fashions throughout the size thought-about within the research with 95% confidence intervals
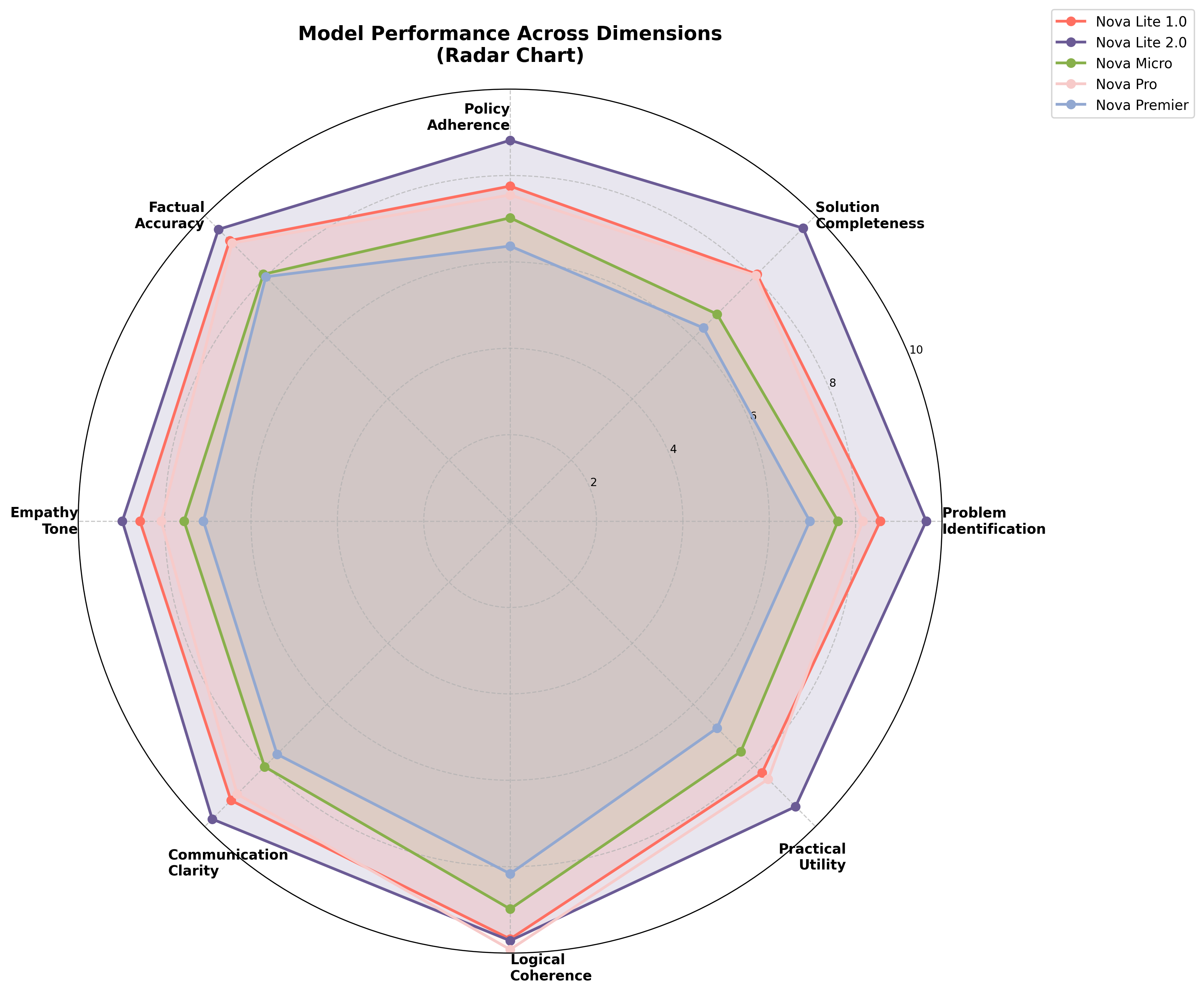
Determine 2 General efficiency of Nova Lite 2.0 in comparison with different fashions within the Nova household
Determine 1 exhibits the efficiency of fashions with scores averaged throughout all of the runs for every dimension thought-about within the research; that is additionally depicted on the radar chart in Determine 2. Desk 1 exhibits the scores throughout all dimensions thought-about within the research. Nova Lite 2.0 achieved the best general rating (9.42/10) with a normal error of 0.08 and a coefficient of variation of 5.55%, demonstrating high-quality reasoning.
| Metric | Nova Lite 2.0 | Nova Lite 1.0 | Nova Professional 1.0 | Nova Micro | Nova Premier |
| General Rating | 9.42 | 8.65 | 8.53 | 7.70 | 7.16 |
| Customary Error (SE) | 0.08 | 0.09 | 0.12 | 0.32 | 0.38 |
| 95% Confidence Interval | [9.28, 9.57] | [8.48, 8.82] | [8.30, 8.76] | [7.08, 8.32] | [6.41, 7.91] |
| Consistency Rating (CV-based) | 94.45 | 93.05 | 90.46 | 71.37 | 62.96 |
| Coefficient of Variation | 5.55% | 6.95% | 9.54% | 28.63% | 37.04% |
Desk 1: General Mannequin Efficiency Abstract
| Metric | Nova Lite 2.0 | Nova Lite 1.0 | Nova Professional 1.0 | Nova Micro | Nova Premier |
| Downside Identification | 9.63 ± 0.27 | 8.57 ± 0.46 | 8.16 ± 0.44 | 7.59 ± 0.74 | 6.94 ± 0.82 |
| Answer Completeness | 9.59 ± 0.23 | 8.08 ± 0.32 | 8.04 ± 0.42 | 6.78 ± 0.65 | 6.33 ± 0.69 |
| Coverage Adherence | 8.82 ± 0.54 | 7.76 ± 0.59 | 7.55 ± 0.64 | 7.02 ± 0.69 | 6.37 ± 0.81 |
| Factual Accuracy | 9.55 ± 0.26 | 9.18 ± 0.30 | 9.10 ± 0.28 | 8.08 ± 0.74 | 8.00 ± 0.89 |
| Empathy Tone | 8.98 ± 0.33 | 8.57 ± 0.34 | 8.08 ± 0.36 | 7.55 ± 0.65 | 7.10 ± 0.79 |
| Communication Readability | 9.76 ± 0.19 | 9.14 ± 0.28 | 8.94 ± 0.28 | 8.04 ± 0.69 | 7.63 ± 0.85 |
| Logical Coherence | 9.71 ± 0.35 | 9.67 ± 0.29 | 9.92 ± 0.11 | 8.98 ± 0.74 | 8.16 ± 0.91 |
| Sensible Utility | 9.35 ± 0.27 | 8.24 ± 0.22 | 8.45 ± 0.24 | 7.55 ± 0.62 | 6.78 ± 0.70 |
Desk 2: Dimension-Degree Efficiency of the Nova fashions (Imply Scores with 95% Confidence Intervals)
Desk 2 exhibits the efficiency throughout the eight dimensions thought-about within the research. Nova Lite 2.0 achieved persistently excessive scores throughout all dimensions.
| Situation | Nova Lite 2.0 | Nova Lite 1.0 | Nova Micro | Nova Professional 1.0 | Nova Premier |
| Account Safety Concern | 9.25 | 7.95 | 7.65 | 6.90 | 2.00 |
| Indignant Buyer Criticism | 9.95 | 9.50 | 9.30 | 8.35 | 8.20 |
| Billing Dispute | 9.15 | 8.75 | 8.60 | 8.85 | 8.20 |
| Product Defect Report | 9.25 | 8.90 | 7.70 | 8.00 | 8.75 |
| Software program Technical Downside | 10.00 | 8.20 | 8.55 | 8.75 | 8.60 |
Desk 3 Abstract of scores (on a scale of 1-10) throughout fashions and situations thought-about. A rating of two for Nova Premier for Account Safety Concern is because of Guardrails being invoked for nearly all the responses.
Desk 3 summarizes the imply scores corresponding to every state of affairs thought-about within the research. Once more, Nova Lite 2.0 achieves excessive scores throughout all dimensions.
Dimension evaluation
The dimensional strengths of Nova Lite 2.0 show balanced capabilities throughout essential analysis standards. Excessive scores in downside identification, communication, and logical reasoning point out mature efficiency that interprets successfully to real-world functions, distinguishing it from fashions that excel in particular person dimensions however lack consistency.
Downside Identification: Nova Lite 2.0 excelled at figuring out all key points—essential the place lacking issues result in incomplete options.
Communication Readability: The mannequin achieved the best rating on this dimension, producing well-structured, actionable responses clients might comply with simply.
Logical Coherence: Robust efficiency signifies the mannequin maintains sound reasoning with out contradictions throughout advanced situations.
Empathy and Tone: Excessive scores show acceptable emotional intelligence, essential for de-escalation and delicate conditions.
Desk 4 exhibits pattern evaluator explanations for high-scoring and low-scoring fashions, illustrating efficient scoring methodology.
| Nova Lite 2.0 – Rating: 10 – Class: “Wonderful” The response explicitly acknowledges the 4 key points: it mentions the delayed supply (“delay in receiving your laptop computer”), the poor customer support expertise (“unhelpful interplay with our help group”), the client’s loyalty (“a valued buyer of 5 years”), and the refund request (“cancel your order and obtain a full refund”). All points are acknowledged with acceptable language. Nova Premier – Rating: 6 – Class: “Satisfactory” |
Desk 4 Pattern explanations supplied by the evaluator for Nova Lite 2.0 and Nova Premier for the Indignant Buyer state of affairs alongside the Downside Identification dimension
Key findings
The analysis outcomes reveal essential insights for mannequin choice and deployment methods. These findings emphasize contemplating a number of efficiency components quite than focusing solely on combination scores, as optimum decisions rely on particular utility necessities and operational constraints.
- Multi-dimensional reasoning issues: Fashions scoring nicely on accuracy however poorly on empathy or readability are unsuitable for customer-facing functions. The balanced efficiency of Nova Lite 2 throughout all dimensions makes it production-ready.
- Consistency predicts manufacturing success: The low variability of Nova Lite 2.0 versus different fashions signifies dependable efficiency throughout numerous situations—essential the place inconsistent responses harm person belief.
- Actual-world analysis reveals sensible capabilities: Artificial benchmarks miss essential dimensions like empathy, coverage adherence, and sensible utility. This framework surfaces production-relevant capabilities.
Implementation issues
Efficiently implementing this analysis framework requires consideration to operational components that considerably impression evaluation high quality and cost-effectiveness. The selection of analysis methodology, scoring mechanisms, and technical infrastructure straight influences end result reliability and scalability.
- Evaluator choice: We chosen gpt-oss-20b to make sure independence from the Nova household, lowering potential bias. Amazon Bedrock gives built-in LLM-as-a-judge capabilities with customary metrics like correctness, completeness, and harmfulness. The framework offered on this put up offers the flexibleness to outline specialised analysis standards and multi-dimensional assessments that may be custom-made to the precise use case of curiosity.
- Situation design: Efficient situations stability realism with measurability. Every consists of particular particulars grounding analysis in real looking contexts. Goal standards—key points to establish, required options, related insurance policies—allow constant scoring. Practical complexity combining a number of issues (billing dispute + safety breach) and competing priorities (urgency vs protocols) reveals how fashions deal with real-world ambiguity and surfaces functionality gaps.
- Statistical validation: A number of runs per state of affairs present confidence intervals and detect inconsistency, making certain efficiency variations are statistically vital.
Key takeaways
Amazon Nova Lite 2.0 demonstrates spectacular reasoning capabilities in examined real-world situations, attaining constant excessive efficiency throughout numerous problem-solving duties. Balanced scores throughout analysis dimensions—from technical downside identification to empathetic communication—point out sturdy reasoning doubtlessly relevant to different domains after complete testing. Multi-dimensional analysis reveals nuanced mannequin capabilities that single-metric benchmarks miss. Understanding efficiency throughout downside identification, answer completeness, coverage adherence, empathy, readability, and logical coherence offers actionable deployment insights. This sensible testing methodology offers actionable insights for organizations evaluating AI programs. The framework’s give attention to goal standards, impartial analysis, and statistical validation creates reproducible assessments adaptable to domains requiring contextual judgment and problem-solving. As fashions advance, evaluation methodologies should evolve to seize more and more subtle reasoning capabilities—multi-turn conversations, advanced decision-making beneath uncertainty, and nuanced judgment in ambiguous conditions.
Conclusion
This complete analysis demonstrates that Amazon Nova Lite 2.0 delivers production-ready AI reasoning capabilities with measurable reliability throughout numerous enterprise functions. The multi-dimensional evaluation framework offers organizations with quantitative proof wanted to confidently deploy AI programs in essential operational environments.
Subsequent steps
Consider Nova Lite 2.0 to your use case:
- Bedrock Mannequin Analysis: Begin with mannequin analysis instruments of Amazon Bedrock, together with the built-in LLM-as-a-judge capabilities for traditional metrics, or adapt the customized framework mentioned on this put up for specialised analysis standards.
- Implement multi-dimensional testing: Adapt the analysis framework to your particular area necessities.
- Pilot deployment: Start with low-risk situations to validate efficiency in your atmosphere.
- Scale systematically: Use the statistical validation strategy to develop to extra use circumstances.
Extra assets
In regards to the authors
 Madhu Pai, Ph.D., is a Principal Specialist Options Architect for Generative AI and Machine Studying at AWS. He leads strategic AI/ML initiatives that ship scalable impression throughout numerous industries by figuring out buyer wants and constructing impactful options. Beforehand at AWS, Madhu served because the WW Accomplice Tech Lead for Manufacturing the place he delivered compelling accomplice options that drove strategic outcomes for industrial manufacturing clients. He brings over 18 years of expertise throughout a number of industries, leveraging information, AI, and ML to ship measurable enterprise outcomes.
Madhu Pai, Ph.D., is a Principal Specialist Options Architect for Generative AI and Machine Studying at AWS. He leads strategic AI/ML initiatives that ship scalable impression throughout numerous industries by figuring out buyer wants and constructing impactful options. Beforehand at AWS, Madhu served because the WW Accomplice Tech Lead for Manufacturing the place he delivered compelling accomplice options that drove strategic outcomes for industrial manufacturing clients. He brings over 18 years of expertise throughout a number of industries, leveraging information, AI, and ML to ship measurable enterprise outcomes.
 Sunita Koppar is a Senior Specialist Options Architect in Generative AI and Machine Studying at AWS, the place she companions with clients throughout numerous industries to design options, construct proof-of-concepts, and drive measurable enterprise outcomes. Past her skilled position, she is deeply captivated with studying and instructing Sanskrit, actively partaking with scholar communities to assist them upskill and develop.
Sunita Koppar is a Senior Specialist Options Architect in Generative AI and Machine Studying at AWS, the place she companions with clients throughout numerous industries to design options, construct proof-of-concepts, and drive measurable enterprise outcomes. Past her skilled position, she is deeply captivated with studying and instructing Sanskrit, actively partaking with scholar communities to assist them upskill and develop.
 Satyanarayana Adimula is a Senior Builder within the AWS GenAI Invocation Middle. With over 20 years of expertise in information and analytics and deep experience in generative AI, he helps organizations obtain measurable enterprise outcomes. He builds agentic AI programs that automate workflows, speed up decision-making, scale back prices, enhance productiveness, and create new income alternatives. His work spans massive enterprise clients throughout numerous industries, together with retail, banking, monetary providers, insurance coverage, healthcare, media and leisure, {and professional} providers.
Satyanarayana Adimula is a Senior Builder within the AWS GenAI Invocation Middle. With over 20 years of expertise in information and analytics and deep experience in generative AI, he helps organizations obtain measurable enterprise outcomes. He builds agentic AI programs that automate workflows, speed up decision-making, scale back prices, enhance productiveness, and create new income alternatives. His work spans massive enterprise clients throughout numerous industries, together with retail, banking, monetary providers, insurance coverage, healthcare, media and leisure, {and professional} providers.

{kind=link}