


Coaching and serving giant transformer fashions is basically a reminiscence administration downside. All GPUs in a cluster have a set quantity of VRAM, and as mannequin measurement and context size develop, engineers should continuously make tradeoffs on the way to distribute work throughout the {hardware}. a new expertise from Zifrareferred to as tensor and sequence parallelism (TSP), presents a option to rethink that tradeoff. Moreover, in benchmark exams with as much as 1,024 AMD MI300X GPUs, peak reminiscence per GPU is constantly decrease than normal parallelism schemes in use right now for each coaching and inference workloads.
The issue TSP is fixing
To know why TSP is essential, you first want to grasp the 2 parallelization methods that TSP is mixed with.
Tensor parallelism (TP) Break up mannequin weights between GPUs. If the eye layer or MLP layer has a weight matrix, every GPU within the TP group solely maintains a portion of that matrix. This instantly reduces the per-GPU reminiscence occupied by parameters, gradients, and optimizer state (“mannequin state” reminiscence). The tradeoff is that TP requires a collective communication operation (normally an all-reduce or reduce-scatter/all-gather pair) each time a layer is computed. This communication is proportional to the scale of the activation, so the fee will increase because the size of the sequence will increase.
Sequence parallelism (SP) takes a unique method. As a substitute of splitting the weights, we break up the enter token sequence between GPUs. Every GPU processes solely a portion of the token, lowering the quadratic prices of activation reminiscence and a focus computation. Nevertheless, with SP, the mannequin weights stay totally replicated throughout all GPUs. Which means the mannequin state reminiscence stays precisely the identical irrespective of what number of GPUs you add to the SP group.
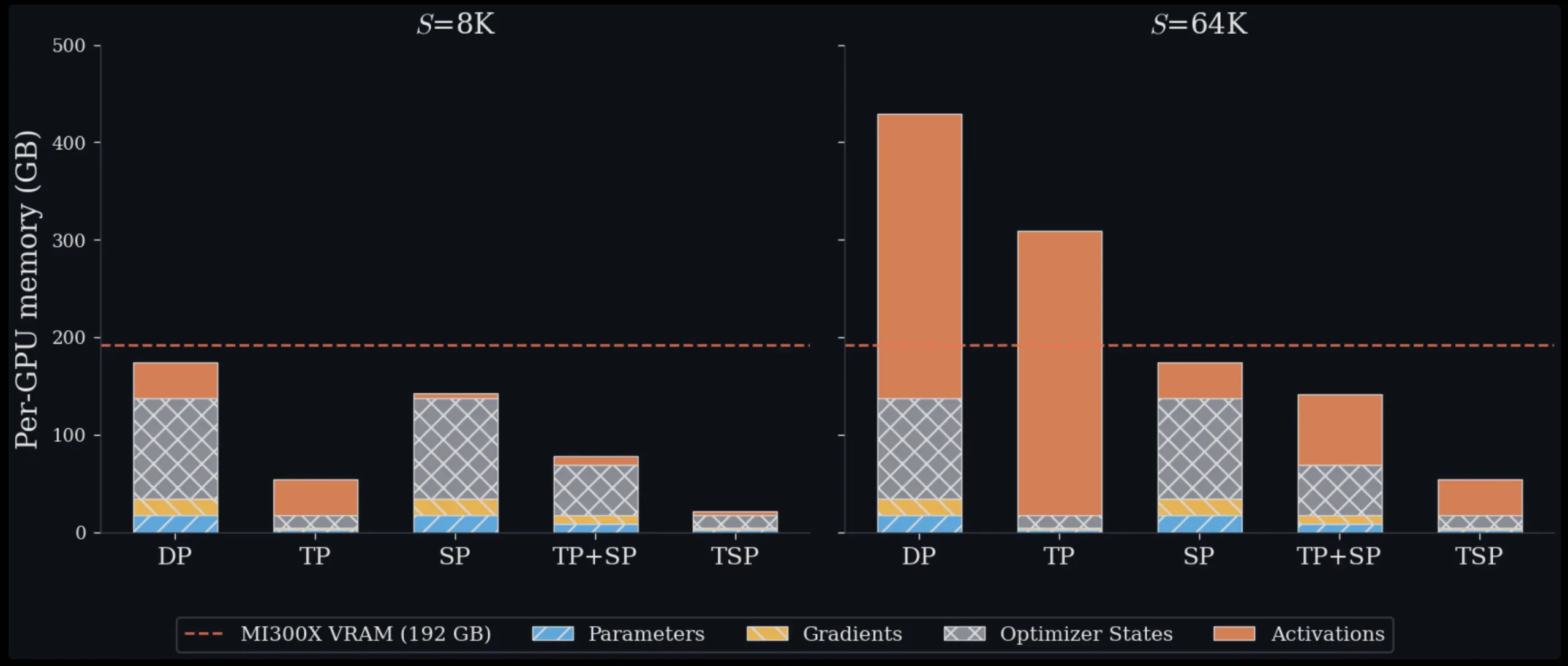
In normal multidimensional parallelism, engineers mix TPs and SPs by putting them on orthogonal axes of the machine mesh. If you need TP diploma T and SP diploma Σ, a mannequin reproduction will eat T.Σ GPUs. That is costly in two methods. First, extra GPUs are used for mannequin parallel teams, leaving fewer GPUs obtainable for information parallel replicas. Second, if T.Σ is giant sufficient to span a number of nodes, some collective communications should undergo slower inter-node interconnects comparable to InfiniBand or Ethernet reasonably than high-bandwidth intra-node materials comparable to AMD Infinity Cloth or NVIDIA NVLink. One other frequent baseline, information parallelism (DP), fully avoids these mannequin parallelism prices, nevertheless it replicates all mannequin state to all gadgets, making it impractical for big fashions or lengthy contexts alone.
What folding really means
The core thought of TSP is collapsing parallelism. As a substitute of putting TP and SP in separate orthogonal mesh dimensions, we collapse them each right into a single machine mesh axis of measurement D. All GPUs in a TSP group concurrently maintain 1/D of mannequin weights and 1/D of token sequences. Since each are sharded with the identical D GPU, the reminiscence footprint per machine is lowered by 1/D for each parameter reminiscence and activation reminiscence. This can’t be achieved with only a single normal parallelism scheme. Due to this fact, TSP is the one scheme that concurrently reduces weight-proportional reminiscence (parameters, gradients, optimizer states) and activation reminiscence by the identical 1/D issue on a single axis with out requiring a two-dimensional T.Σ machine structure.
The problem is that if every GPU has solely a part of the weights and a part of the sequence, it should coordinate with different GPUs to finish the ahead go of every layer. TSP makes use of two completely different communication schedules to deal with this. One for consideration and one for gate MLP.
To concentrate, TSP iterates over the burden shards. At every step, one GPU broadcasts its packed consideration weight shards (WQ, WK, WV, and WO) to all different GPUs within the group. All GPUs then apply these weights to native sequence tokens to compute native Q, Okay, and V projections. As a result of causal consideration requires entry to the whole key/worth context, native Okay and V tensors are all collected throughout TSP teams and sorted utilizing a zigzag partitioning scheme earlier than FlashAttendant is utilized. Zigzag partitions permit the causal consideration workload to be balanced throughout ranks. It’s because subsequent tokens correspond to bigger prefixes, making a load imbalance.
For gated MLP, TSP makes use of ring scheduling. Every GPU begins with a neighborhood shard of gates, upward and downward projections. These weight shards flow into inside the TSP group through point-to-point ship/obtain operations, and every GPU accumulates partial output regionally because the shards arrive. Importantly, this eliminates the all-reduce that normal TP requires for MLP output. The sequence stays native, solely the weights are moved. This ring is designed to overlap weight switch and GEMM computation, so the communication occurs within the background throughout GPU computation.
Reminiscence and throughput outcomes
When examined over sequence lengths of 16K to 128K tokens on a single 8 GPU MI300X node, TSP achieved the bottom peak reminiscence throughout the board. At 16K tokens, mannequin state reminiscence dominates briefly contexts, so TSP and TP are roughly equal, at 31.0 GB and 31.5 GB per GPU. With 128K tokens, the state of affairs modifications dramatically. TSP makes use of 38.8 GB per GPU, whereas TP makes use of 70.0 GB and two completely different TP+SP factorizations on the identical node use 85.0 GB and 140.0 GB. The theoretical numbers all through this examine are primarily based on a 7B dense decoder-only transformer reference mannequin (hidden dimension h=4096, 32 layers, 32 question heads, 32 KV heads, FFN enlargement issue F=4, bf16 precision), offering a reproducible baseline for evaluating schemes.
Throughput outcomes on 128 full nodes (1,024 MI300X GPUs) present that TSP constantly outperforms the matched TP+SP baseline. With a folded diploma of D=8 and a sequence size of 128K tokens, TSP achieves 173 million tokens/second (about 2.6x speedup) in comparison with 66.3 million tokens per second for the matched TP+SP baseline. The upper the diploma of parallelism and the longer the sequence size, the better the profit.

Sensible trade-offs to grasp
TSP will increase whole communication in comparison with TP alone. We add a per-layer weight switch time period on prime of the identical activation-proportional Okay/V allgather that SP makes use of. Nevertheless, the analysis workforce reveals that when the batch measurement B and sequence size S fulfill BS > 8h (h is the embedding dimension of the mannequin), the transmission site visitors of TSP can compete with TP. This situation is met in most long-context coaching and inference eventualities.
A key perception highlighted by the Zyphra workforce is that communication quantity and communication value aren’t the identical factor. Whether or not the additional site visitors results in a lower in measured pace is dependent upon whether or not the collective is latency-bound or bandwidth-bound, and the way a lot of that site visitors can overlap with matrix multiplication. These implementation pipelines carry out weight transfers behind the dominant GEMM operations, so weight communication consumes bandwidth with out rising essential path time.
TSP shouldn’t be designed to exchange TP, SP, or TP+SP in all settings. It’s meant as an extra axis within the multidimensional parallelism design area. Assemble pipeline parallelism, knowledgeable parallelism, and information parallelism orthogonally. Which means groups can incorporate TSP into present parallelism configurations, even when the usual structure forces mannequin parallelism teams over gradual internode hyperlinks.
Necessary factors
- Zyphra’s tensor and sequence parallelism (TSP) collapses tensor and sequence parallelism right into a single machine mesh axis, so every GPU concurrently holds 1/D of mannequin weights and 1/D of token sequences, lowering reminiscence overhead for each coaching and inference.
- TSP is the one parallel processing scheme that reduces each weight-proportional reminiscence (parameters, gradients, optimizer states) and activation reminiscence by the identical 1/D issue on a single axis, with out requiring a two-dimensional T.Σ machine mesh.
- Experimental outcomes on a single 8-GPU MI300X node present that TSP makes use of 38.8 GB per GPU at 128K sequence size, whereas TP makes use of 70.0 GB and TP+SP configurations use 85.0 to 140.0 GB.
- At giant scale (1,024 MI300X GPUs, 128K contexts, D=8), TSP achieves 173 million tokens/second. This compares to 66.3 million tokens/second for the matched TP+SP baseline (~2.6x throughput benefit).
- TSP organizes pipelines, specialists, and information parallelism orthogonally and is right for long-context, memory-constrained coaching and inference workloads the place eradicating weights and activation replication is extra essential than further communication.
Please examine paper and technical details. Please be at liberty to observe us too Twitter Do not forget to affix us 130,000+ ML subreddits and subscribe our newsletter. cling on! Are you on telegram? You can now also participate by telegram.
Must companion with us to advertise your GitHub repository, Hug Face Web page, product launch, webinar, and many others.?connect with us
The publish Zyphra Introduces Tensor and Sequence Parallelism (TSP): {Hardware}-Conscious Coaching and Inference Methods to Obtain 2.6x Throughput on Matched TP+SP Baselines appeared first on MarkTechPost.

{kind=link}