


How can we construct a language mannequin that will increase capability however barely adjustments the computation of every token? Ant Group’s Inclusion AI team By releasing , we’re selling sparse large-scale fashions in a scientific means. Lin 2.0. Lin 2.0 is Inference-based language model family It’s based mostly on the concept every activation ought to immediately translate right into a extra highly effective inferential habits. That is achieved whereas maintaining activations small. 16B → 1T without rewriting the recipe. This sequence has three variations: Lin Mini 2.0 1.4B energetic for a complete of 16B; phosphorus flash 2.0 100B class with 6.1B activated, and Lin 1T A complete of 1T, roughly 50B per token will likely be energetic.
Sparse MoE as a core design
each Rin 2.0 model use the identical sparse Mix of expert tiers. Every layer has 256 routed consultants and 1 shared knowledgeable. The router selects 8 routed consultants for every token, and shared consultants are at all times on, so every token makes use of about 9 out of 257 consultants. This corresponds to roughly 3.5 % activation, which corresponds to an activation charge of 1/32. The analysis crew experiences about seven instances extra effectivity in comparison with equal dense fashions as a result of it trains and serves solely a small portion of the community for every token whereas sustaining a really massive parameter pool.
Ling 2.0 brings coordinated advances throughout 4 layers: stack, mannequin structure, pre-training, post-training, and the underlying FP8 infrastructure.
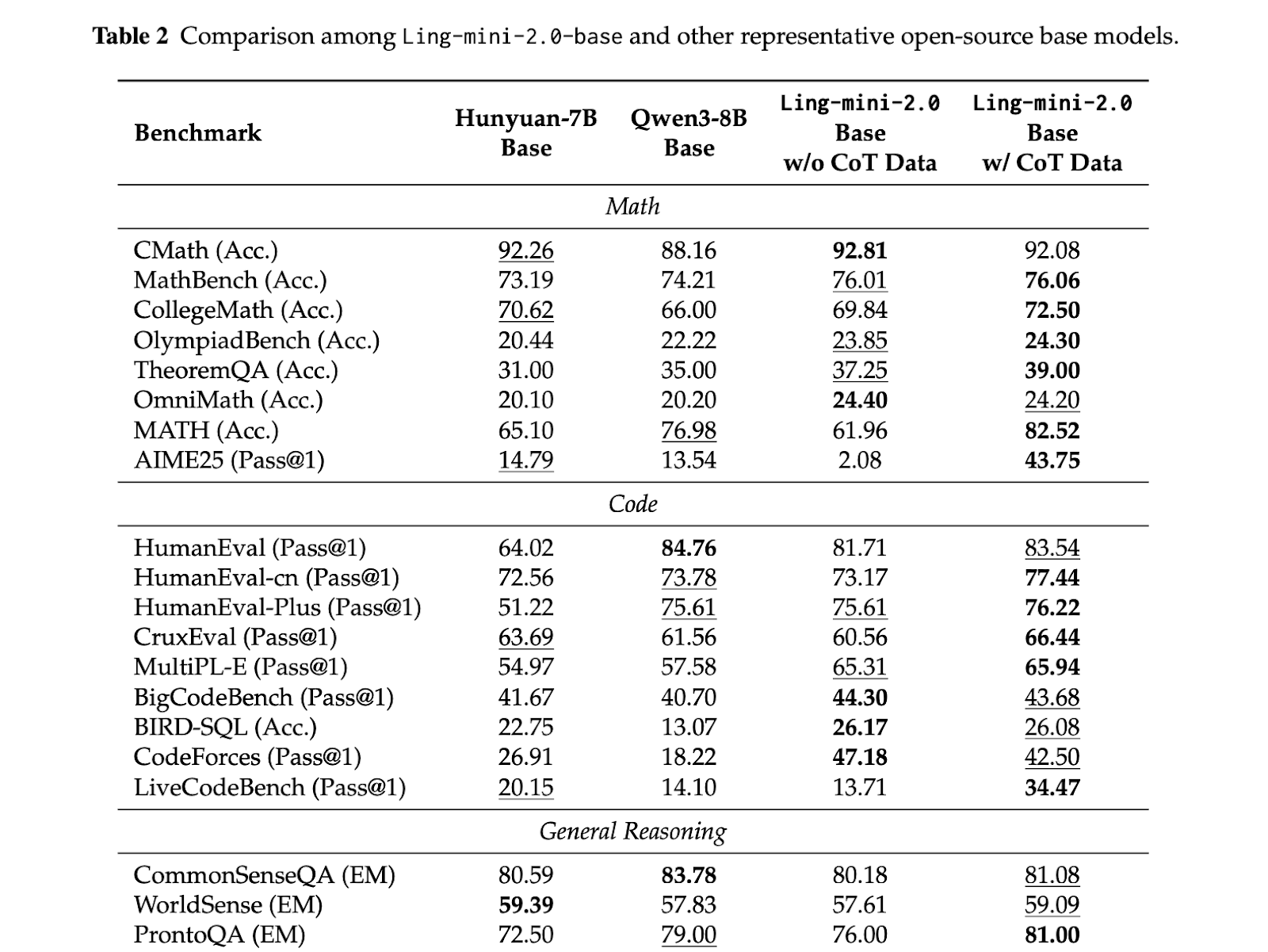
Mannequin structure: of The architecture is selected using Ling Scaling Laws rather than trial and error.. To assist Ling Scaling Legal guidelines, the crew will run one thing known as Ling Wind Tunnel. It is a fastened set of small MoE runs educated underneath the identical information and routing guidelines, after which fitted with an influence regulation to foretell loss, activation, and knowledgeable steadiness at a lot bigger sizes. This lets you select at a decrease value 1/32 activations, 256 routed experts and 1 shared expert before committing the GPU to 1T scale. The routing has no auxiliary loss as a consequence of sigmoid scoring, and the stack makes use of QK norm, MTP loss, and partial RoPE to maintain the depth secure. The Ling mini 2.0, Ling flash 2.0, and Ling 1T all share consistency throughout measurement as a result of the identical legal guidelines decided their shapes.
Pre-training: The sequence is educated on over 20T tokens, beginning with a mix of 4K context and necessary sources of inference equivalent to math and code steadily growing to virtually half of the corpus. In a later intermediate coaching part, we lengthen the context to roughly 32K with chosen 150B token slices, then inject one other 600B tokens of high-quality thought chains, and eventually lengthen to 128K with YaRN whereas sustaining the standard of the quick context. This pipeline ensures that lengthy context and inferences usually are not solely added within the SFT step, however are launched early.
After coaching: Alignment is split into practical path and most popular path. First, decoupled fine-tuning teaches the mannequin to change between fast responses and deep reasoning by varied system prompts, then an evolutionary CoT stage extends and diversifies the chain, and eventually sentence-level coverage optimization with group area rewards fine-grainedly adjusts the output to human judgment. this gradual alignment It will allow you to obtain superior efficiency in math, code, and educating with out mindlessly inflating your solutions.
Infrastructure: Lin 2.0 trains natively on FP8 with safeguards and obtains round 15% utilization on reported {hardware} whereas maintaining the loss curve inside a small hole of BF16. The numerous speedup of roughly 40% is just not solely as a consequence of precision, but in addition as a consequence of parallel processing of heterogeneous pipelines, interleaving of ahead and backward execution, and MTP block-aware partitioning. Mixed with Warmup Steady Merge, which replaces LR decay by merging checkpoints, this method stack makes 1T-scale execution sensible on present clusters.
perceive the outcomes
The sample of analysis is constant; Small Activation MoE Model It gives aggressive high quality whereas maintaining compute per token low. Lin mini 2.0 It reportedly has a complete of 16B parameters, prompts 1.4B per token, and runs in a dense band of 7-8B. Ling flash 2.0 maintains the identical 1/32 activation recipe, has 100B and prompts 6.1B per token. Lin 1T is the flagship non-thinking mannequin, with complete parameters of 1T and roughly 50B actives per token, sustaining 1/32 sparsity and scaling the identical Ling Scaling Legal guidelines to trillion scale.
Vital factors
- Lin 2.0 is constructed round a particular 1/32 activation MoE structure utilizing Ling Scaling Legal guidelines to permit 256 routed consultants and 1 shared knowledgeable to remain optimum from 16B to 1T.
- Lin Mini 2.0 has a complete of 16B parameters, with 1.4B activated per token, and is reported to match a 7B-8B dense mannequin whereas producing over 300 tokens per second with easy QA on H20.
- phosphorus flash 2.0 Holding the identical recipe, with an energetic parameter of 6.1B and throughout the 100B vary, it offers larger capability choices with out growing compute per token.
- Lin 1T We expose the entire design, roughly 50B energetic 1T complete parameters per token, 128K contexts, and an Evo CoT and LPO-style post-training stack to drive environment friendly inference.
- Elevated effectivity in all sizes Comes with a 7x denser baseline The mixture of sparse activation, FP8 coaching, and a shared coaching schedule predictably scales high quality with out retuning compute.
this release signifies full sparsity MoE stack. Ling Scaling Legal guidelines identifies 1/32 activation as optimum, the structure locks in 256 routing consultants and 1 shared knowledgeable, and the identical geometry is used from 16B to 1T. Coaching, context enlargement, and desire optimization are all tailor-made to that selection, so small activations do not block math, code, or lengthy contexts, and FP8 and heterogeneous pipelines hold prices inside sensible limits. It is a clear sign that trillions of inferences will be organized round fastened sparsity quite than growing dense computing.
Please verify HF weight, lipo and paper. Please be happy to test it out GitHub page for tutorials, code, and notebooks. Please be happy to comply with us too Twitter Remember to affix us 100,000+ ML subreddits and subscribe our newsletter. hold on! Are you on telegram? You can now also participate by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a synthetic intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information, which is technically sound and simply understood by a large viewers. The platform boasts over 2 million views per thirty days, demonstrating its recognition amongst viewers.

{kind=link}