


Understanding audio has all the time been a multimodal frontier that has lagged behind imaginative and prescient. Though picture language fashions are quickly increasing towards real-world deployment, constructing open fashions that robustly infer speech, environmental sounds, and music, particularly over lengthy durations of time, stays extraordinarily troublesome. Researchers at NVIDIA and the College of Maryland at the moment are immediately addressing that hole.
The analysis workforce introduced that Audio Flamingo Subsequent (AF-Subsequent)probably the most succesful mannequin within the Audio Flamingo collection, is a completely open massive audio language mannequin (LALM) skilled on internet-scale audio knowledge.
Audio Flamingo Subsequent (AF-Subsequent) coming in Three variants specialised for various use instances. Launch contains: AF-Subsequent directions For solutions to normal questions, AF-Subsequent-Suppose for superior multilevel reasoning, and AF-NEXT-Captioner View detailed audio captions.
What’s a Massive-Scale Audio Language Mannequin (LALM)?
a Massive-scale spoken language mannequin (LALM) It combines an audio encoder and a decoder-specific language mannequin to allow query answering, captioning, transcription, and inference immediately on audio enter. Consider this because the audio equal of imaginative and prescient language fashions like LLaVA and GPT-4V. Nevertheless, it’s designed to course of speech, environmental sounds, and music concurrently inside one built-in mannequin.
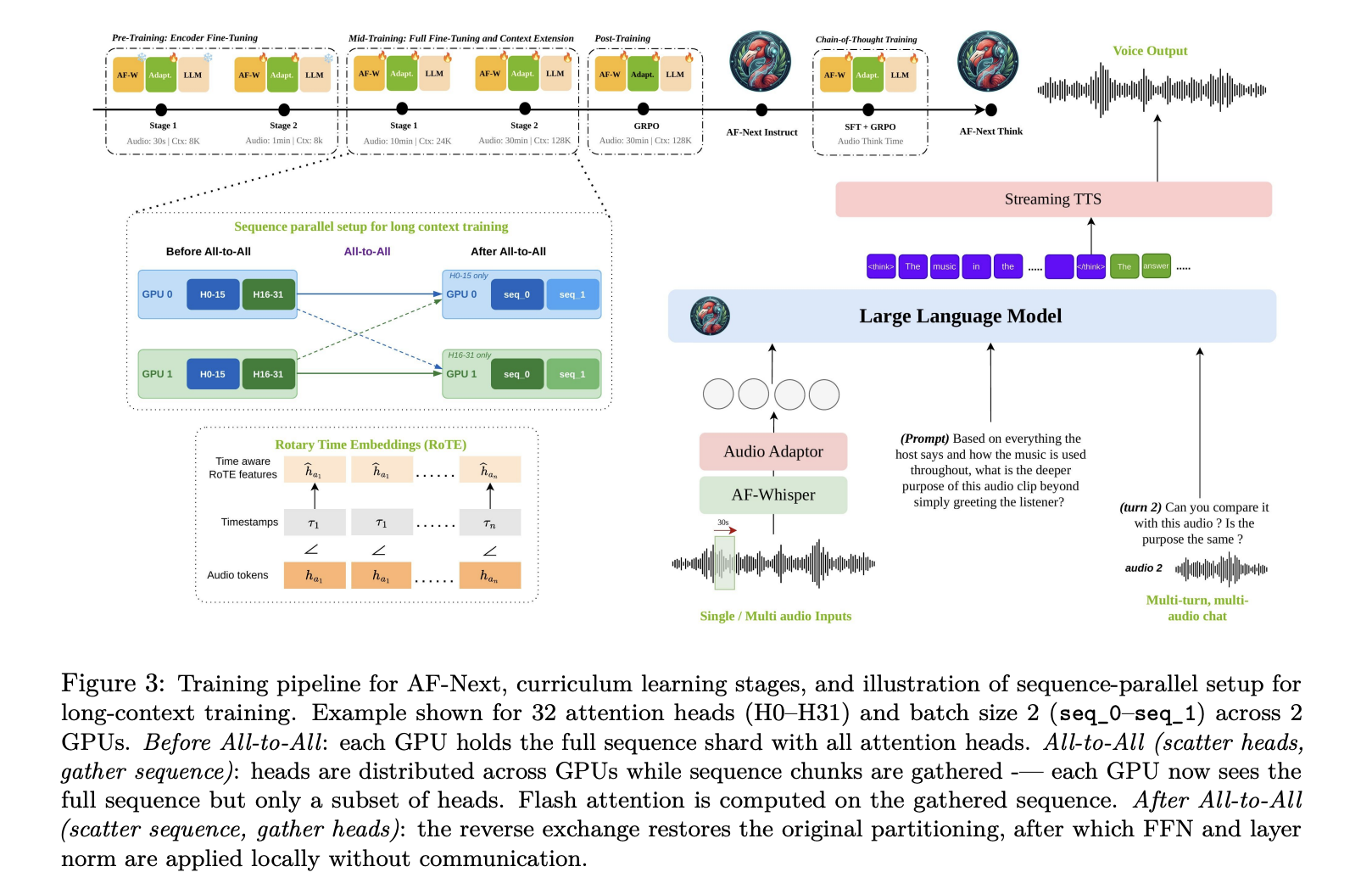
Structure: 4 elements working in a pipeline
AF-Subsequent is constructed round 4 most important elements. AF-Whisper Audio Encodera customized Whisper-based encoder additional pre-trained on a bigger and extra numerous corpus, together with multilingual speech and multi-speaker ASR knowledge. Given an audio enter, the mannequin resamples it to 16 kHz mono and converts the waveform to a 128-channel log-mel spectrogram utilizing a 25-ms window and a 10-ms hop dimension. Spectrograms are processed in non-overlapping 30 second chunks by AF-Whisper, outputting options at 50 Hz, after which a stride 2 pooling layer is utilized. Hidden dimensions are 1280.
The second is audio adaptera two-layer MLP that maps the audio illustration of AF-Whisper to the embedding house of the language mannequin. The third is LLM spine: Qwen-2.5-7B, a decoder-only causal mannequin with 7B parameters, 36 transformer layers, and 16 consideration heads. Further lengthy context coaching prolonged the context size from 32k tokens to 128k tokens.
Refined however vital architectural particulars embody: Rotation time embedding (RoTE). Normal positional encoding of transformers indexes tokens by their place in a discrete sequence. i. As a substitute of the usual RoPE rotation angle, RoTE replaces this. θ ← −i · 2πRoTE makes use of θ ← −τi · 2πRight here, τi is absolutely the timestamp of every token. For audio tokens generated with a set 40 ms stride, discrete time positions are interpolated earlier than being fed to the RoTE module. This offers a place illustration based mostly on precise time slightly than sequence order. This can be a core design selection that enables the mannequin to make temporal inferences, particularly for lengthy audio. lastly, Streaming TTS module It permits for dialogue between voices.
Temporal Audio Thought Chains: Crucial Reasoning Recipes
Chain of Thought (CoT) prompts improved inference throughout textual content and imaginative and prescient fashions, however earlier audio CoT work confirmed solely modest enhancements as a result of the coaching dataset was restricted to quick clips containing easy questions. AF-Subsequent addresses this Temporal Audio Thought ChainRight here, the mannequin explicitly anchors every intermediate inference step to the timestamp of the audio earlier than producing the reply, facilitating devoted proof aggregation and mitigating hallucinations attributable to lengthy recordings.
To coach this means, the analysis workforce AF-thinking timea dataset of query, reply, and thought chain triplets culled from difficult audio sources reminiscent of trailers, film summaries, thriller tales, and lengthy multiparty conversations. AF-Suppose-Time consists of roughly 43,000 coaching samples, with a mean of 446.3 phrases per thought chain.
Huge coaching: 1 million hours, 4 levels
The ultimate coaching dataset consists of roughly 108 million samples and roughly 1 million hours of audio. These are extracted from each present public datasets and uncooked audio that’s collected from the open web after which synthetically labeled. New knowledge classes launched embody greater than 200,000 lengthy movies starting from 5 to half-hour for long-form captioning and QA, multi-speaker speech understanding knowledge masking speaker identification, interruption identification, and goal speaker ASR, roughly 1 million samples for multi-speech inference throughout a number of simultaneous audio inputs, and roughly 386,000 samples for security and following directions.
The coaching is as follows 4 stage curriculumevery with totally different knowledge combine and context size. Pre-training There are two substages. In stage 1, we maintain each AF-Whisper and LLM frozen and prepare solely the audio adapter (30 seconds max audio, 8K token context). Stage 2 additional fine-tunes the audio encoder whereas conserving the LLM frozen (1 minute max audio, 8K token context). mid-term coaching There are additionally two substages. Stage 1 performs an entire fine-tuning of the complete mannequin, including AudioSkills-XL and new curated knowledge (10 minutes max audio, 24K token context). Stage 2 introduces lengthy audio captions and QA, downsampling the Stage 1 combine to half its unique mix weight whereas increasing context to 128,000 tokens and audio to half-hour. The mannequin ensuing from intermediate coaching is launched particularly as follows: AF-NEXT-Captioner. after coaching Apply GRPO-based reinforcement studying targeted on multi-turn chat, security, directions, and chosen skill-specific datasets, AF-Subsequent directions. Lastly, CoT coaching Begin with AF-Subsequent-Instruct, apply SFT on AF-Suppose-Time, then apply GRPO with post-training knowledge combination, AF-Subsequent-Suppose.
One of many notable contributions by the analysis workforce is: Hybrid sequence parallel processingwhich permits 128K context coaching on lengthy audio. With out this, the enlargement of audio tokens would exceed the usual context window, making the second-order reminiscence price of self-attention infeasible. This answer combines Ulysses consideration, which makes use of all-to-all collectives to distribute sequence and head dimensions amongst nodes the place high-bandwidth interconnects can be found, and ring consideration, which circulates blocks of keys and values between nodes through point-to-point switch. Ulysses handles intra-node communication effectively. Rings are scaled throughout nodes.
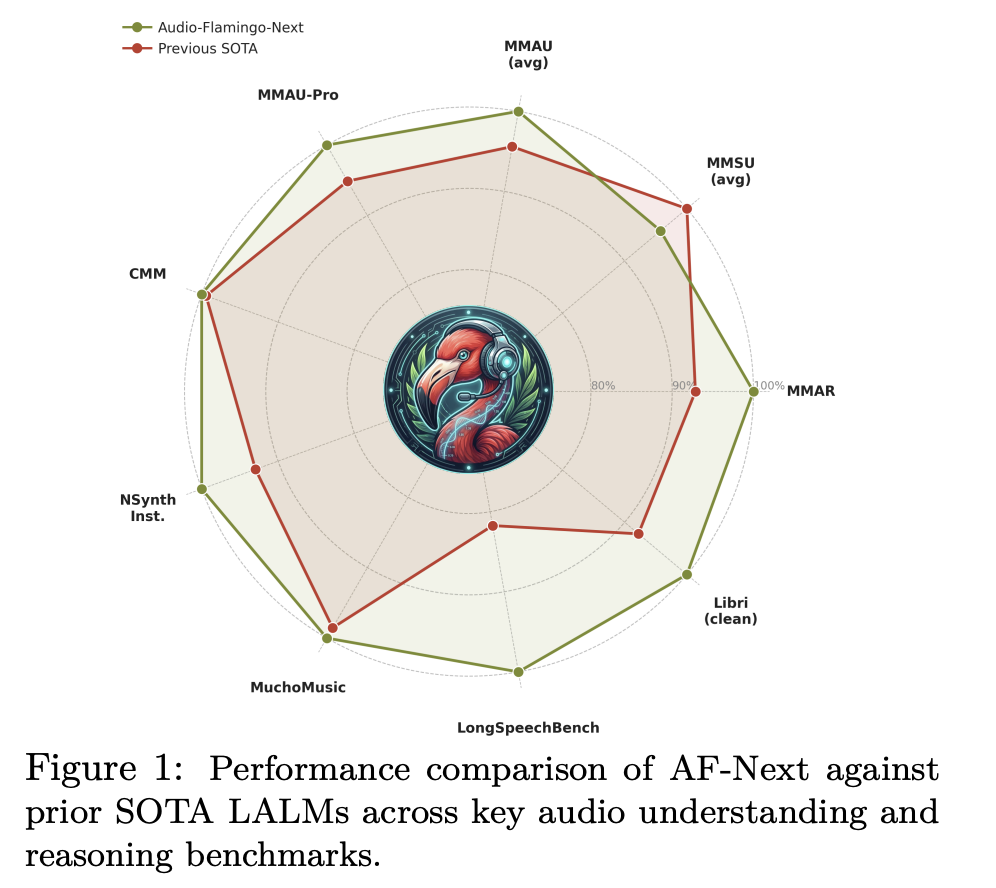
Benchmark outcomes: total good
On MMAU-v05.15.25, probably the most extensively used audio inference benchmark, AF-Subsequent-Instruct achieves a mean accuracy of 74.20 in comparison with 72.42 for Audio Flamingo 3, AF-Subsequent-Suppose reaches 75.01, and AF-Subsequent-Captioner reaches 75.76. Sound (79.87), improved in all three music subcategories. (75.3), and speech (72.13). Within the tougher MMAU-Professional benchmark, AF-Subsequent-Suppose (58.7) outperforms the closed-source Gemini-2.5-Professional (57.4).
Music comprehension is especially markedly improved. For Medley-Solos-DB instrument recognition, AF-Subsequent reached 92.13, whereas Audio Flamingo 2 got here in at 85.80. For SongCaps music captions, GPT5’s protection and accuracy scores jumped from 6.7 and 6.2 (AF3) to eight.8 and eight.9, respectively.
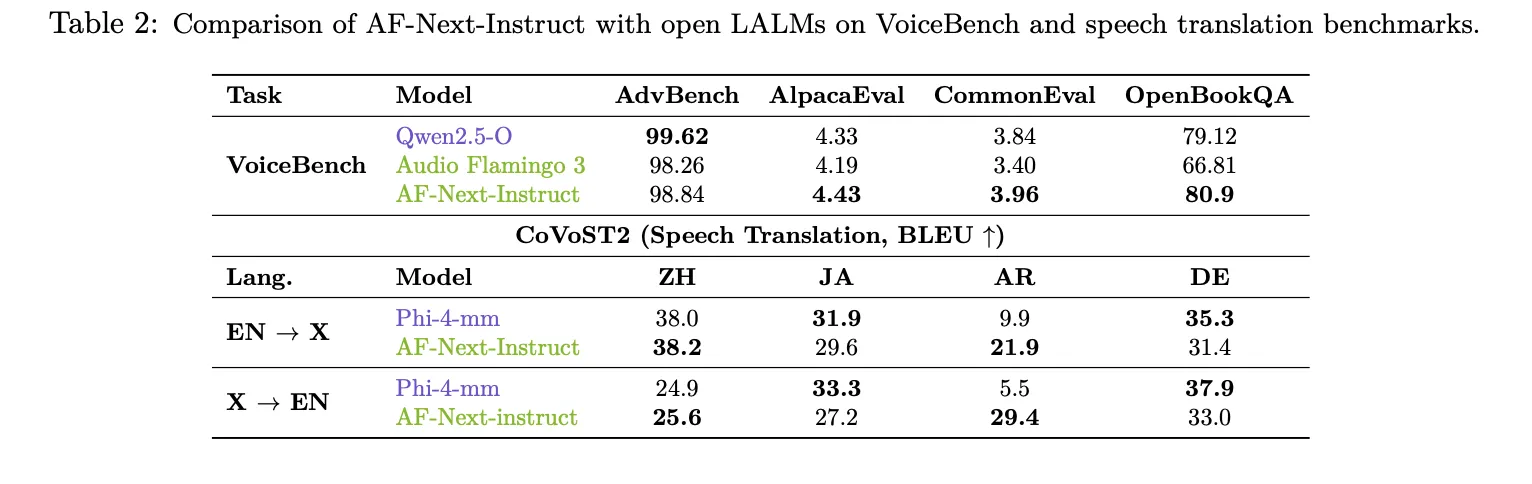
The place AF-Subsequent most clearly distinguishes itself is in its understanding of long-duration speech. On LongAudioBench, AF-Subsequent-Instruct achieved a rating of 73.9, outperforming each Audio Flamingo 3 (68.6) and the closed-source Gemini 2.5 Professional (60.4). Within the variant with voice (+Speech), AF-Subsequent reaches 81.2, in comparison with 66.2 for Gemini 2.5 Professional. In ASR, AF-Subsequent-Instruct set new lowest values amongst LALMs with phrase error charges of 1.54 for LibriSpeech test-clean and a couple of.76 for test-other. On VoiceBench, AF-Subsequent-Instruct achieved the best scores in AlpacaEval (4.43), CommonEval (3.96), and OpenBookQA (80.9), beating Audio Flamingo 3 by greater than 14 factors in OpenBookQA. For CoVoST2 speech translation, AF-Subsequent confirmed a very notable 12-point enchancment over Phi-4-mm in Arabic EN→X translation (21.9 vs. 9.9).
Essential factors
Listed below are 5 key takeaways.
- A totally open speech language mannequin at web scale: AF-Subsequent is taken into account the primary LALM to increase speech understanding to Web-scale knowledge (roughly 108 million samples and 1 million hours of audio).
- Temporal phonetic thought chain solves lengthy phonetic reasoning: Quite than inferring as in earlier CoT approaches, AF-Subsequent explicitly anchors every intermediate inference step to a timestamp within the audio earlier than producing the reply. This makes the mannequin considerably extra devoted and interpretable for lengthy recordings of as much as half-hour. This can be a downside that was largely averted in earlier fashions.
- Three variants specialised for various use instances: This launch contains AF-Subsequent-Instruct for answering frequent questions, AF-Subsequent-Suppose for superior multi-step inference, and AF-Subsequent-Captioner for detailed audio captioning, permitting practitioners to decide on the suitable mannequin based mostly on their job slightly than utilizing one-size-fits-all checkpoints.
- Regardless of its small dimension, it outperforms closed fashions when it comes to long-lasting audio. On LongAudioBench, AF-Subsequent-Instruct has a rating of 73.9, increased than the closed-source Gemini 2.5 Professional (60.4) and Audio Flamingo 3 (68.6). For variants with tougher speech, the distinction widened even additional, reaching 81.2 for the AF-Subsequent versus 66.2 for the Gemini 2.5 Professional.
Please examine paper, Project page and model weights. Please be happy to comply with us too Twitter Do not forget to hitch us 130,000+ ML subreddits and subscribe our newsletter. hold on! Are you on telegram? You can now also participate by telegram.
Must companion with us to advertise your GitHub repository, Hug Face Web page, product launch, webinar, and so on.? connect with us

{kind=link}