


We’ve all obtained used to the little numbered blue hyperlinks in ChatGPT’s responses. They’re the citations that again up ChatGPT’s responses with exterior data.
However, though ChatGPT crawls dozens of pages to reply a single question, in response to our analysis, it solely finally ends up citing ~50% of them.
Why does one web page get the credit score whereas one other, which the AI clearly retrieved, will get nothing?
In response to studies by AI professional Dan Petrovic, when ChatGPT retrieves outcomes, every one comes again with the web page title, a short snippet or abstract, the URL, and an ID quantity.

ChatGPT makes use of this information to determine which pages are value opening and finally citing in its response.
Meaning there’s a gatekeeping layer earlier than ChatGPT opens and reads any of your precise web page content material. The title, snippet, and URL are doing the heavy lifting in that preliminary choice.
So we needed to know: what really influences that call? Does greater semantic similarity between a web page’s retrieval information and the consumer question improve quotation chance? Which fields matter most? Do human-readable URLs outperform opaque ones?
To seek out out, we analyzed 1.4 million ChatGPT 5.2 prompts from February 2025 (desktop) with the assistance of Ahrefs information scientist Xibeijia Guan.
However earlier than we get into the findings, you have to perceive how ChatGPT really gathers its sources—as a result of not all URLs enter the system the identical manner.
When ChatGPT retrieves outcomes, it categorizes sources utilizing an inner discipline referred to as ref_type—basically a label for the retrieval channel the URL got here via.
We found 5 classes: search, information, reddit, youtube, and academia.
The quotation charges between them are wildly uneven:
| ref_type | Quotation % | Whole information factors |
|---|---|---|
| search | 88.46% | 25,563,589 |
| information | 12.01% | 3,940,537 |
| 1.93% | 16,182,976 | |
| youtube | 0.51% | 953,693 |
| academia | 0.40% | 185,337 |
The overall “search” index dominates—each in quantity and quotation charge—and 88% of the URLs that find yourself being cited by ChatGPT are taken instantly from search.
If you wish to be cited by ChatGPT, you have to be in that search choice pool—which implies your content material must rank.
This isn’t new data. By now, most individuals are already conscious that rating performs an element, but it surely’s good to have some extra information to again it up.
Specialised verticals like YouTube (e.g. youtube.com) and Academia (e.g. arXiv.org), however, are pulled in at scale however barely ever get surfaced as precise citations.
Sidenote.
The “search” ref_type does embody Reddit and YouTube outcomes too—any Reddit or YouTube web page that comes again via a typical internet search will present up there.
The separate “Reddit” and “YouTube” ref_types possible characterize further outcomes—i.e. these pulled in by way of devoted API integrations—on high of regardless of the internet search already returned.
That’s why the quantity on these channels is so excessive; ChatGPT is supplementing its search outcomes with a separate feed of Reddit and YouTube content material.
This issues loads for decoding the remainder of the evaluation.
On common, ChatGPT pulls ~16.57 cited URLs and ~16.58 non-cited URLs per immediate.
However as a result of Reddit makes up 67.8% of the non-cited pool, any combination comparability of “cited vs. non-cited” is admittedly evaluating search outcomes to Reddit API output. Not apples to apples.
So all through this analysis, we’ve remoted the evaluation by ref_type wherever potential to keep away from that distortion.
That is in all probability essentially the most hanging discovering within the dataset.
Reddit has its personal devoted ref_type in ChatGPT’s retrieval system, with over 16 million information factors in our dataset.
But it’s cited at a charge of simply 1.93%.
In the meantime, 67.8% of all non-cited URLs come from Reddit.
In different phrases: ChatGPT is utilizing Reddit extensively to know subjects, gauge consensus, and construct context—but it surely nearly by no means provides Reddit the credit score.
It learns from the group, then cites one other establishment.
As we’ve briefly lined, when ChatGPT retrieves search outcomes, every one comes again with a set of fields together with a title, URL, and generally a snippet—a brief extract of web page content material saved in ChatGPT’s retrieval information.
We anticipated that having extra of those fields populated would correlate with greater quotation charges.
At first look, the combination information appeared to inform a distinct story: non-cited pages even have extra populated fields in ChatGPT’s retrieval information than cited ones.
Non-cited URLs had snippets 14.81% of the time versus 4.36% for cited URLs, and have been much more more likely to carry a publication date (92.72% vs. 35.98%).
We nearly ran with that as a discovering, however I’m glad we didn’t.
After we dug into it, the discrepancy turned out to be nearly completely a compositional artifact—pushed by Reddit and the mechanics of ChatGPT’s retrieval pipeline.
As a result of the non-cited pool is overwhelmingly Reddit (67.8%), and Reddit content material pulled by way of API naturally carries pub_date metadata, the 92.72% determine is a Reddit artifact—not a sign about how ChatGPT evaluates internet pages normally.
The snippet hole is defined in another way. In response to David McSweeney’s research on ChatGPT’s retrieval course of, the mannequin really abandons the snippet discipline (the quick content material extract) as soon as it’s determined to quote a URL, and opens the total web page as an alternative.
So, it’s not a matter of ChatGPT preferring pages with no snippets. The low snippet share for cited pages is probably going a byproduct of how the pipeline works.
After we remoted the information to only the “search” ref_type—stripping out Reddit, information, YouTube, and the remainder—the image turned loads clearer:
| Search ref_type | Has snippet | Has pub_date | Whole URLs |
|---|---|---|---|
| Cited | 2.52% | 33.79% | 22,612,529 |
| Not cited | 0.09% | 49.00% | 2,951,060 |
Snippet information is mainly non-existent for each teams throughout the search vertical—it’s not a usable sign. And the publication date percentages are nearer, however non-cited search pages are nonetheless barely extra more likely to carry a pub_date (49%) than cited ones (33.79%).
The variations we initially noticed between cited and non-cited URLs appear to have been distorted by the information composition and retrieval mechanics. Any sign—if there may be one—is buried underneath the noise.
The sincere takeaway: we are able to’t draw sturdy conclusions about whether or not the snippet or publication date fields play a significant function in quotation from this information.
It’s value flagging that this downside possible applies to different quotation research too. Any analysis evaluating “cited vs. non-cited” URLs with out accounting for the place these URLs got here from dangers mistaking quirks of the information for actual patterns.
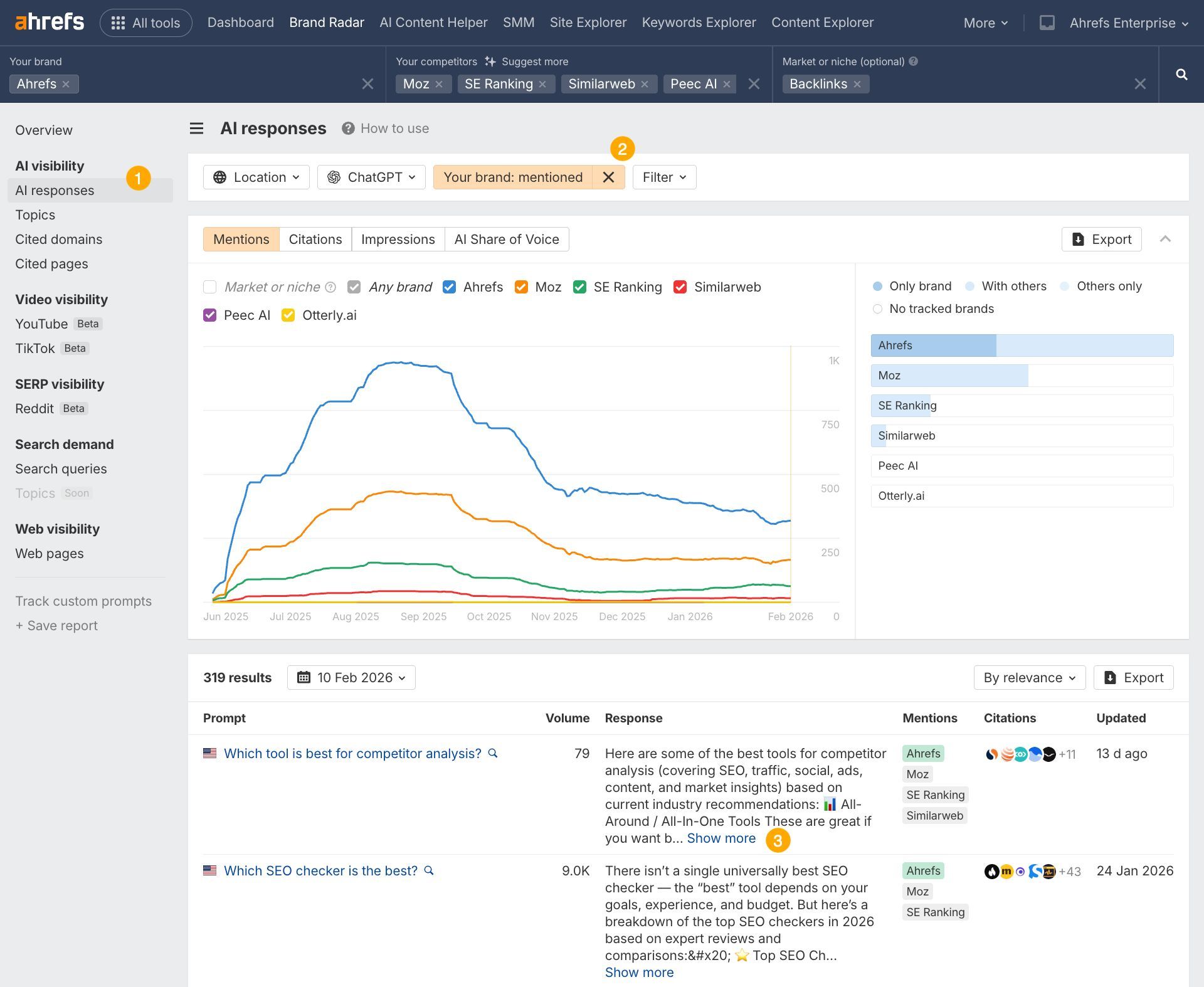
Discover your individual quotation gaps in Model Radar
The information on this research tells you what ChatGPT values. Model Radar tells you the place you’re falling quick.
Open Model Radar, arrange your model and rivals, and head straight to the Cited Pages report.
Then, filter for responses the place rivals are cited and also you aren’t.
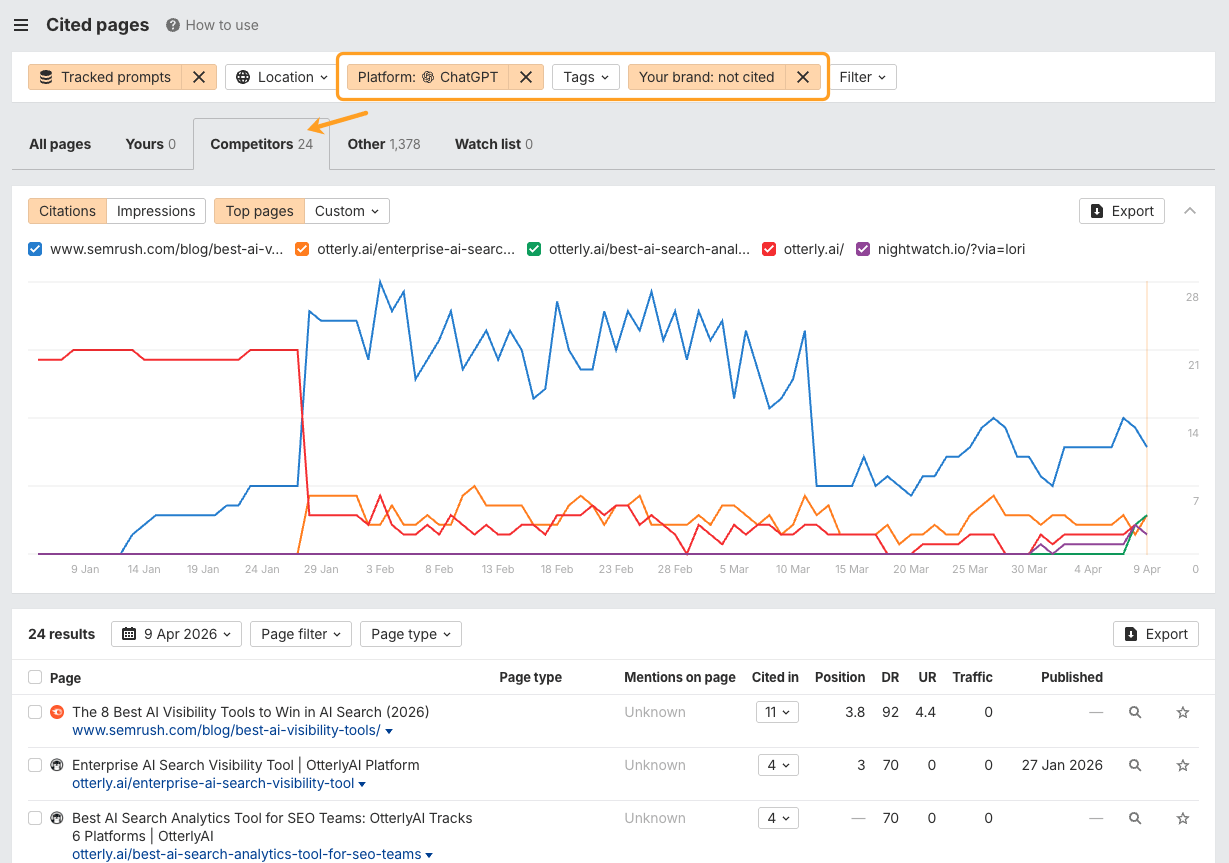
That hole evaluation provides you a concrete checklist of content material to create, refresh, or restructure.
To determine what’s “citable,” ChatGPT estimates relevance, in a course of generally described as “semantic scoring”, to guage whether or not an article and a question are associated.
Since ChatGPT is a closed-source mannequin, we don’t have visibility into precisely how it determines relevance internally.
So, on this research, we used cosine similarity computed from embeddings generated by open-source fashions, to quantify and approximate how ChatGPT could work.
ChatGPT matches URLs in opposition to its personal “fanout queries”—the sub-questions it generates internally (from a consumer’s seed immediate) to hunt for particular details.
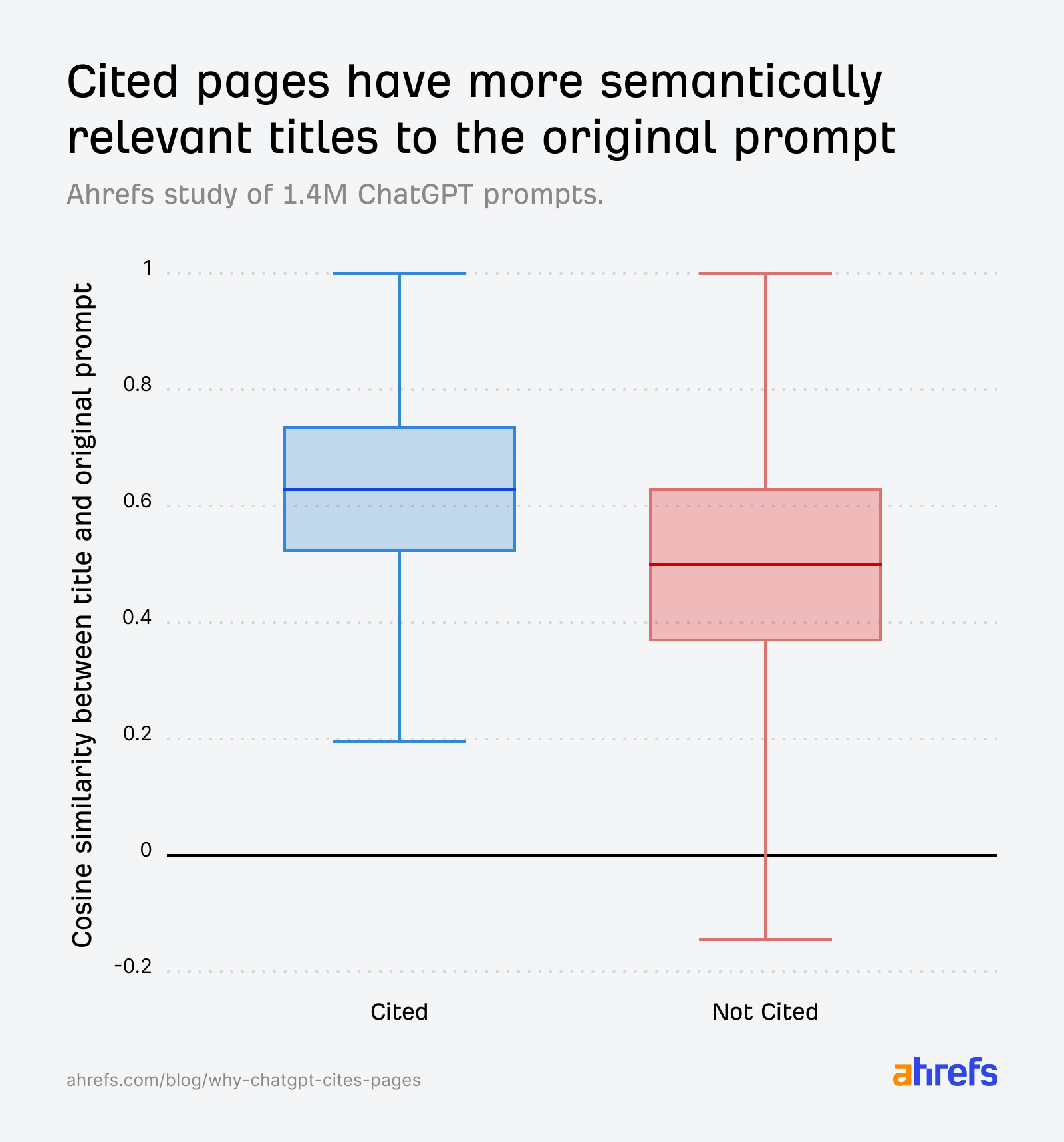
The information confirms that title relevance to fanout queries is a crucial consider quotation:
- Immediate vs. cited URL title: 0.602
- Immediate vs. non-cited URL title: 0.484
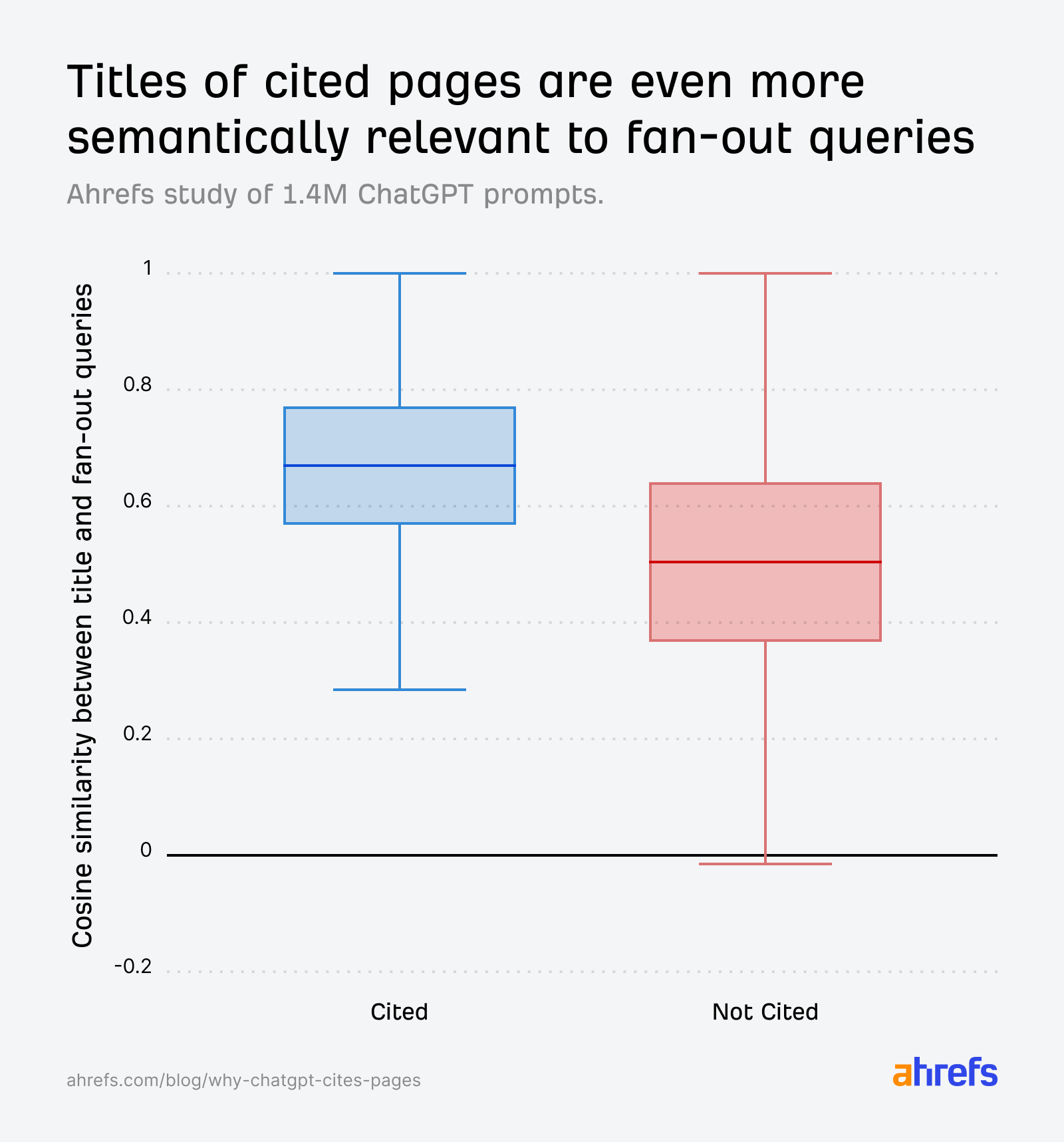
- Fanout question vs. cited URL title (max match*): 0.656
Sidenote.
For every of those fanout queries, we compute its cosine similarity with the article title. The “max match” rating is the best similarity amongst them—for instance, if scores are 0.45, 0.71, and 0.38, the max match is 0.71. This captures the best-aligned sub-question moderately than averaging throughout all interpretations, which might dilute the sign.
The field plots inform the story clearly. Throughout all ref_types, cited URLs have constantly greater similarity between their title and the unique immediate:
The hole widens additional once we evaluate in opposition to fanout queries as an alternative of the unique immediate—reinforcing that creating content material related to ChatGPT’s inner sub-questions are what actually drive choice:
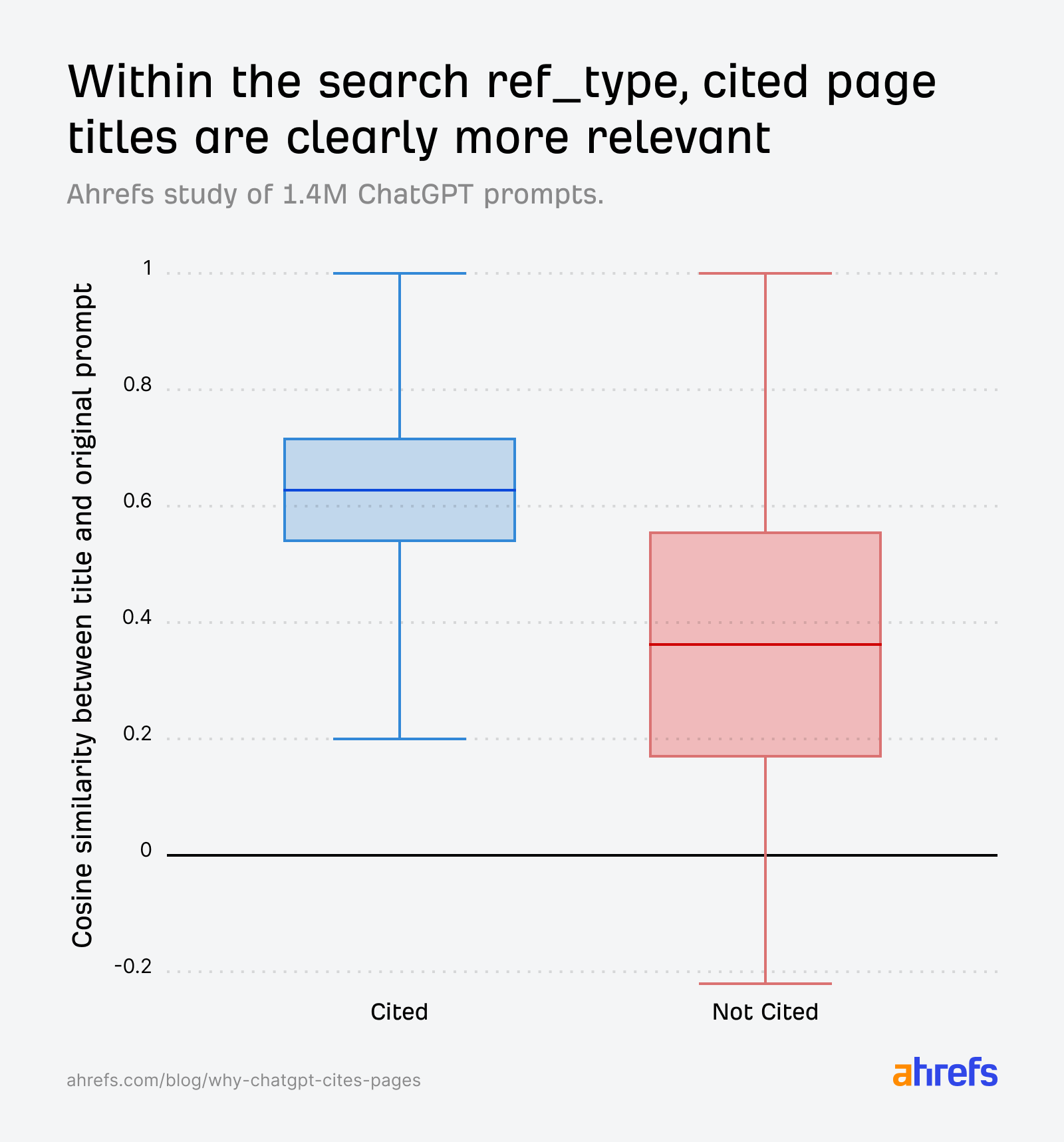
After we isolate the search ref_type particularly, the sample will get even sharper. Cited pages are clearly extra related, and the non-cited distribution drops considerably:
We additionally discovered that search outcomes with pure language URL slugs had an 89.78% quotation charge, in comparison with 81.11% for these with out.
In the end, in case your URL and title don’t semantically align with the AI’s inner fanout queries, you’re much less more likely to get cited.
Optimize for fan-out queries utilizing Model Radar
You’ll be able to research fanout queries instantly inside Model Radar. Head to the AI Responses report, decide any immediate, and also you’ll see the fanout queries ChatGPT generated alongside the cited URLs.
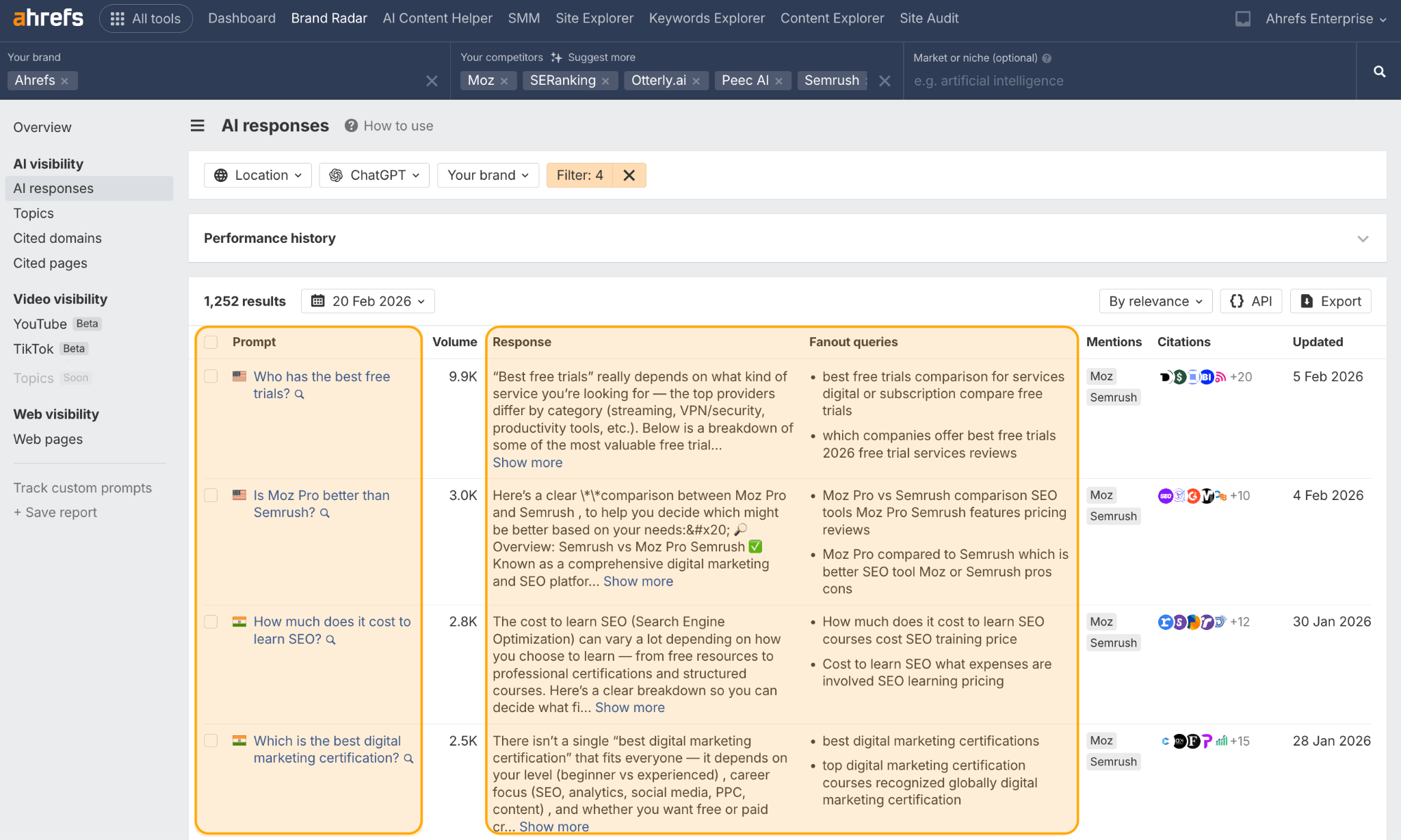
That is the precise set of sub-questions your content material must reply.
From there, use the AI Content material Helper to test how properly your web page covers the subjects these fanout queries handle. It measures the cosine similarity between your content material and the subjects the SERP or AI response is making an attempt to cowl—and provides you a coloured spotlight as you write, displaying which gaps stay.

If a competitor’s web page is getting cited for a question the place yours isn’t, this is without doubt one of the quickest methods to diagnose why.
It’s frequent data that more energizing content material will get cited extra by AI—and, in truth, our personal research of 17 million citations helps that. We discovered that ChatGPT cited URLs that have been 458 days newer than Google’s natural outcomes—the strongest freshness desire of any platform we examined.
This research doesn’t contradict that narrative, but it surely does add an additional layer of nuance.
As an example, once we take a look at the search index, cited pages span a variety of ages—the median is round 500 days (~1.3 years previous), with some cited pages over 2,700 days previous (~7.4 years previous).
The median age is definitely far decrease than our preliminary freshness research linked above (958 days again in July vs 500 days on this dataset), suggesting that ChatGPT is skewing even youthful in its quotation preferences.
That mentioned, we additionally discovered that non-cited pages are overwhelmingly very younger.
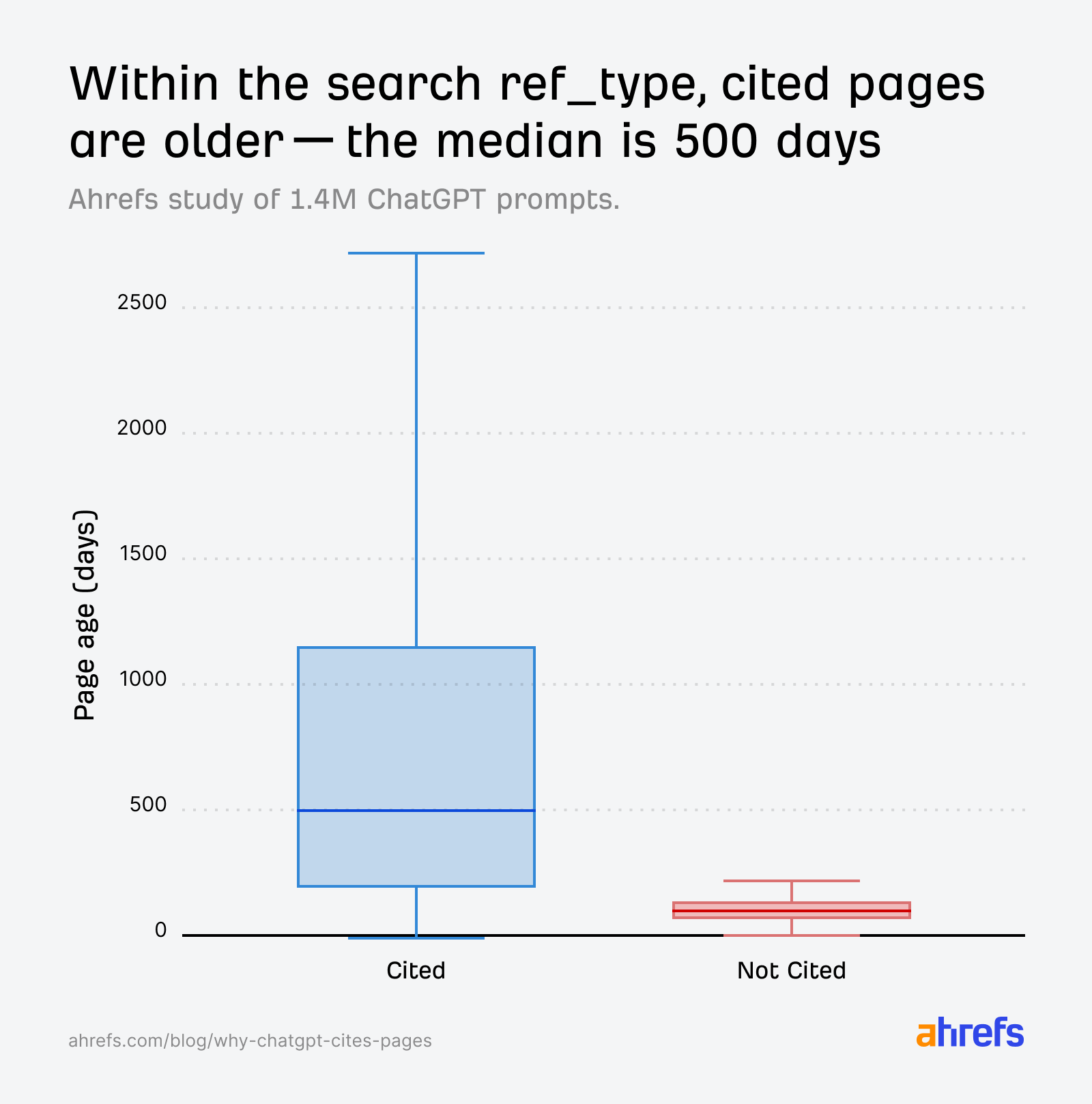
So inside a single immediate’s retrieval set, it’s the older, extra established pages that are inclined to get cited, and the freshest content material that tends to get discarded.
In different phrases, ChatGPT prefers recent content material, however tends to quote comparatively “older” content material extra typically. That sounds counterintuitive, however each issues might be true on the identical time.
Throughout the broader inhabitants of AI citations, ChatGPT does skew more energizing in comparison in opposition to Google outcomes, and even in opposition to it’s personal quotation preferences from solely final 12 months.
However inside a given retrieval set, freshness alone isn’t sufficient. Relevance nonetheless does the heavy lifting.
A brand new web page that matches fanout queries properly will get cited. A brand new web page that doesn’t might be retrieved, but ignored.
It’s additionally value declaring that the pool of non-cited pages (~3M) throughout the search ref_type is much smaller than the cited group (~23M), which limits how confidently we are able to interpret the age hole.
The place freshness issues most is in “information”.
On this class, title relevance scores for cited and non-cited pages are practically similar:
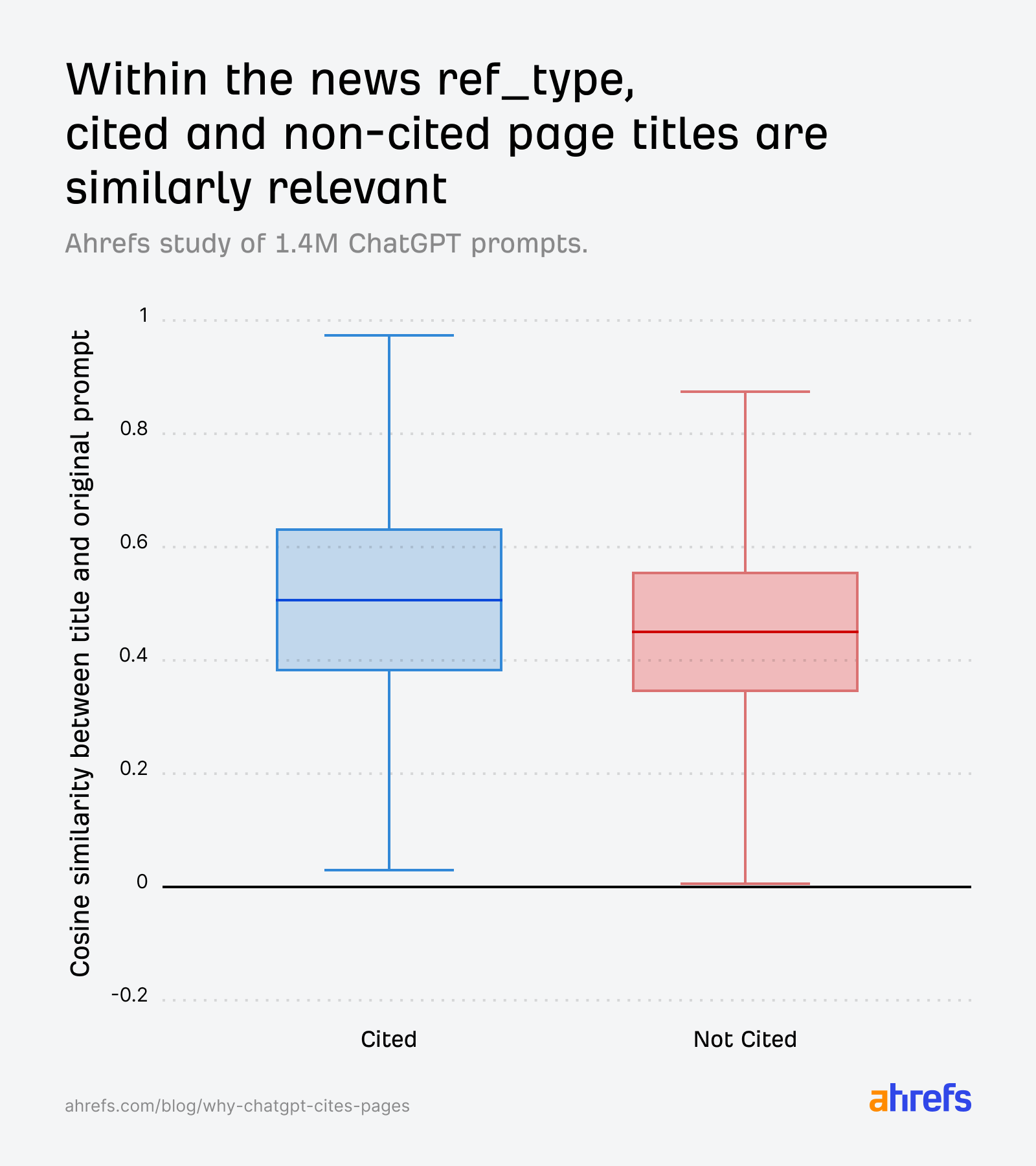
The AI can’t determine based mostly on relevance alone, so it defaults to a temporal tie-breaker: web page age. Cited information pages skew youthful:
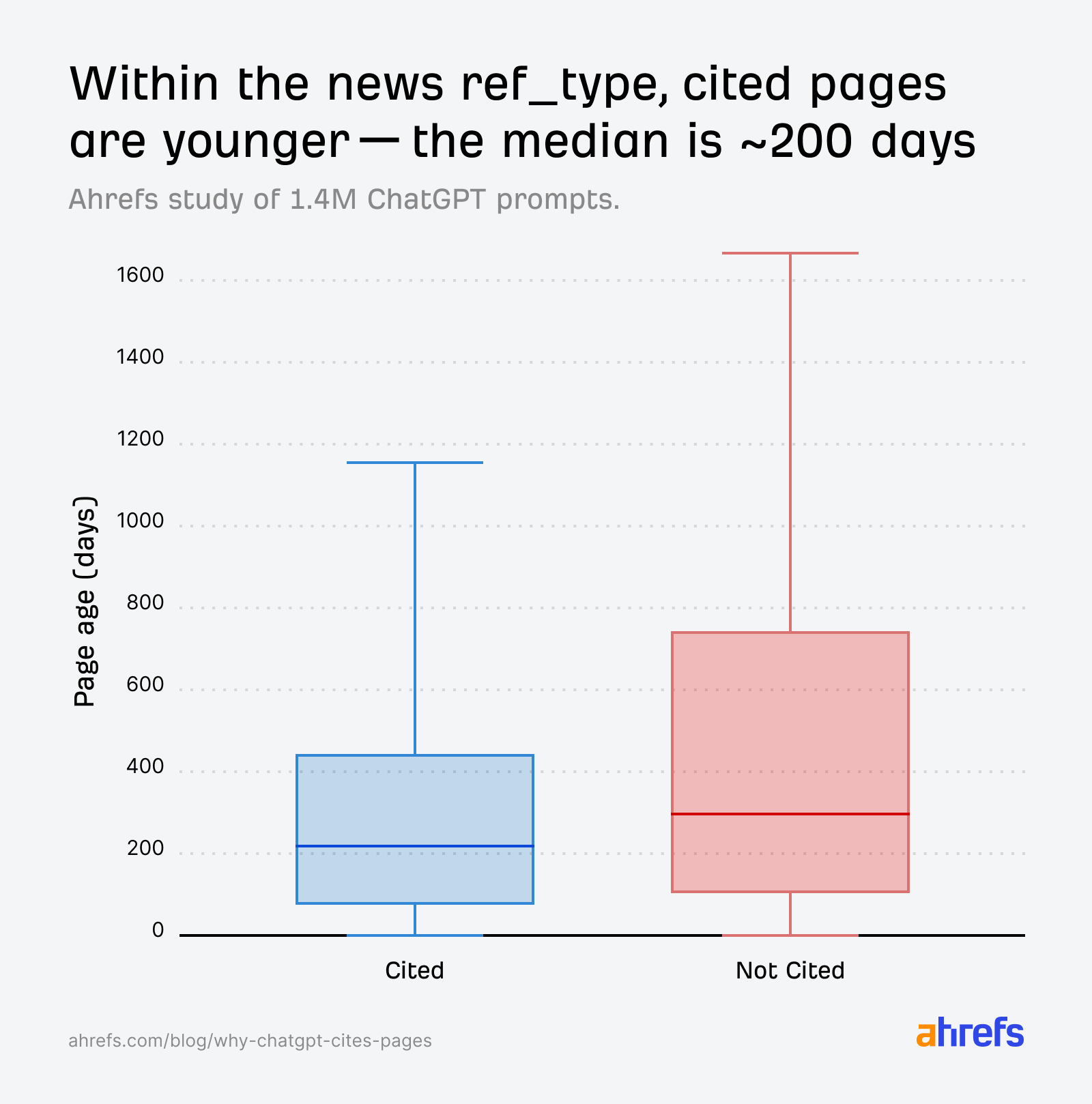
For information queries, youthful pages have a transparent benefit, even when relevance scores between cited and non-cited pages are comparable.
Create the freshest information content material utilizing Firehose
If you happen to publish information or time-sensitive content material, freshness is non-negotiable.
Be the primary to interrupt information on sure tales utilizing Ahrefs Firehose—our real-time internet monitoring API that offers you a streaming feed of information from our enormous crawler infrastructure.
For instance, when you work in SaaS journalism, you’ll be able to monitor content material modifications on pages like Google’s official weblog, so that you might be the primary one to cowl a brand new Google replace as quickly because it goes stay.
Then, use Model Radar’s Mentions historical past within the AI Responses report to trace whether or not your ChatGPT visibility spikes after publication.
The 1.4 million prompts paint a fairly clear image. ChatGPT is an aggressive editor. It favors its basic search index, makes use of semantic similarity to pick and cite sources, and treats Reddit as a textbook it’s embarrassed to confess it learn.
However the information additionally taught us a lesson in analytical warning.
Mixture comparisons between “cited” and “non-cited” URLs might be deceptive if the non-cited pool is dominated by a single supply sort with its personal retrieval mechanics.
What initially appeared like a paradox—less-optimized pages getting cited extra—turned out to be a matter of dataset composition.
We might have gotten that one very improper if we hadn’t remoted by ref_type.
In the end, the pages that get cited are those whose titles and content material match the questions ChatGPT is asking behind the scenes, and that floor via the correct retrieval channel.

{kind=link}