


How a lot skill can Sparse display? 8.3B parameters and moe ~1.5B energetic path Can it’s streamed on a smartphone with out lag or consuming reminiscence? Liquid AI has been launched LFM2-8B-A1B, A small-scale mixed-of-experts (MoE) mannequin constructed for on-device execution in conditions the place reminiscence, latency, and vitality budgets are tight. In contrast to most MoE works which might be optimized for cloud batch companies, the LFM2-8B-A1B is focused at telephones, laptops, and embedded techniques. I’ll exhibit Complete variety of parameters 8.3 billion Nonetheless, simply activate As much as 1.5 billion parameters per tokenmakes use of sparse professional routing to keep up small compute paths whereas enhancing expressive energy. This mannequin is launched beneath the next situations: LFM Open License v1.0 (lfm1.0)
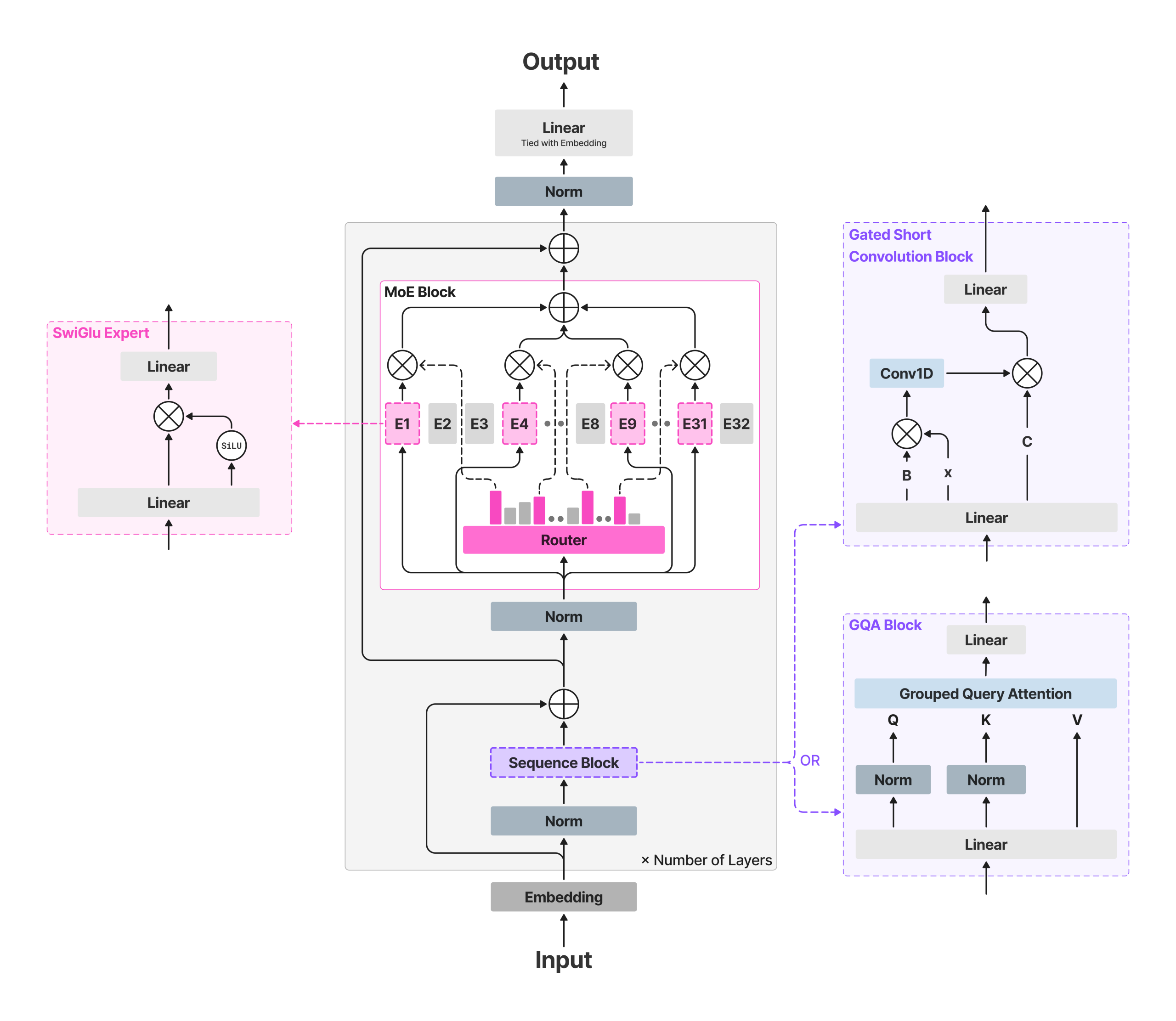
perceive the structure
LFM2-8B-A1B retains the “high-speed spine” of LFM2 and inserts a sparse MoE feedforward block to extend capability with out considerably growing energetic computing. The spine makes use of 18 gated brief convolution blocks and Six grouped question consideration (GQA) blocks. all layers apart from the primary two Embody MoE block. The primary two stay dense for stability. Every MoE block is outlined as follows: 32 consultants;Router chooses High 4 consultants by token and Normalized sigmoid gate and adaptive routing bias Steadiness the load and stabilize your coaching. The size of the context is 32,768 tokens;vocabulary dimension 65,536;Reported pre-training price range ~12T tokens.
This strategy permits per-token FLOP and cache progress to be restricted by the energetic path (consideration + 4 professional MLPs), whereas the entire capability permits for specialization throughout domains corresponding to multilingual information, arithmetic, and code. It is a use case that usually entails regression with very small dense fashions.
efficiency sign
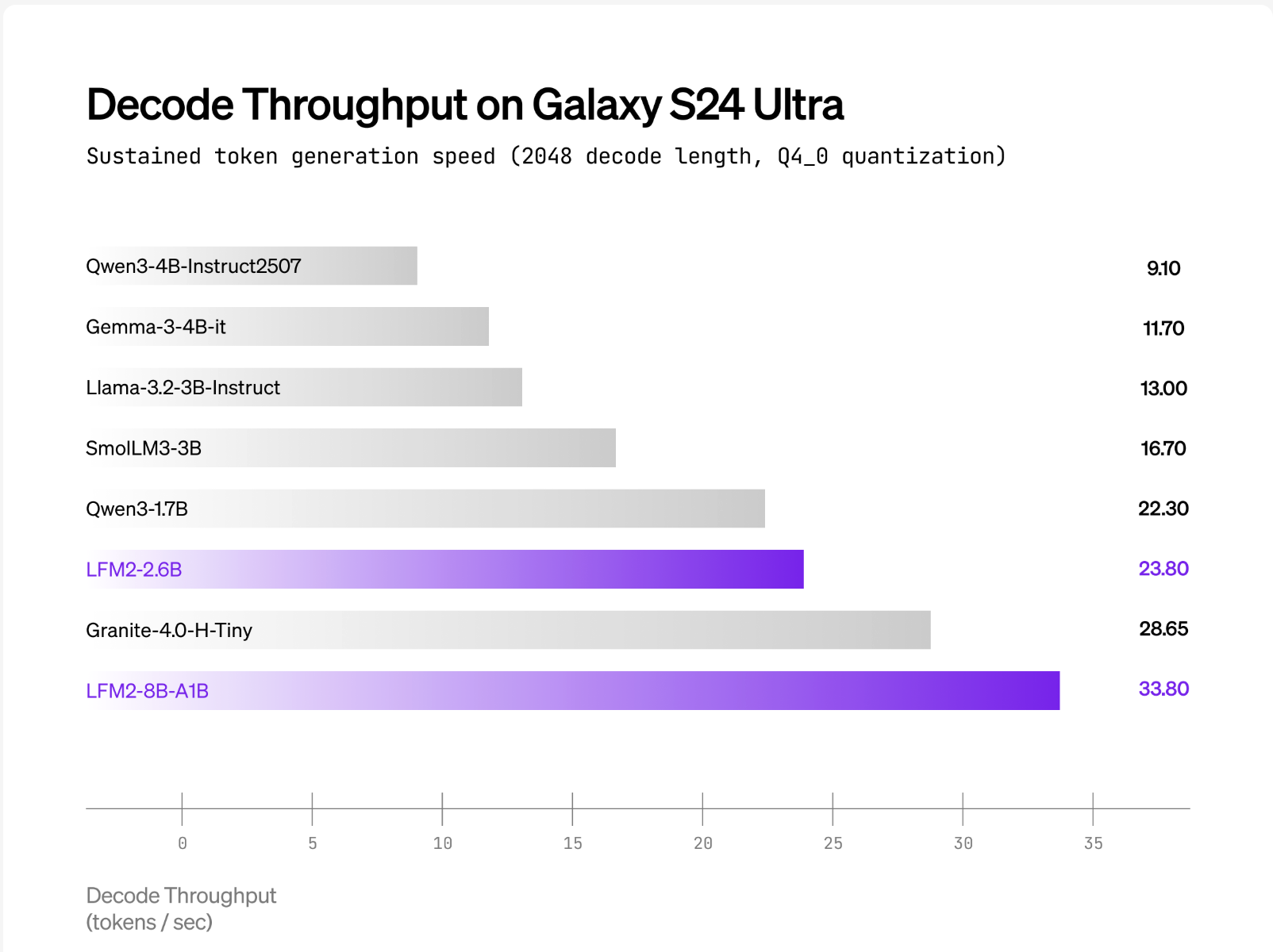
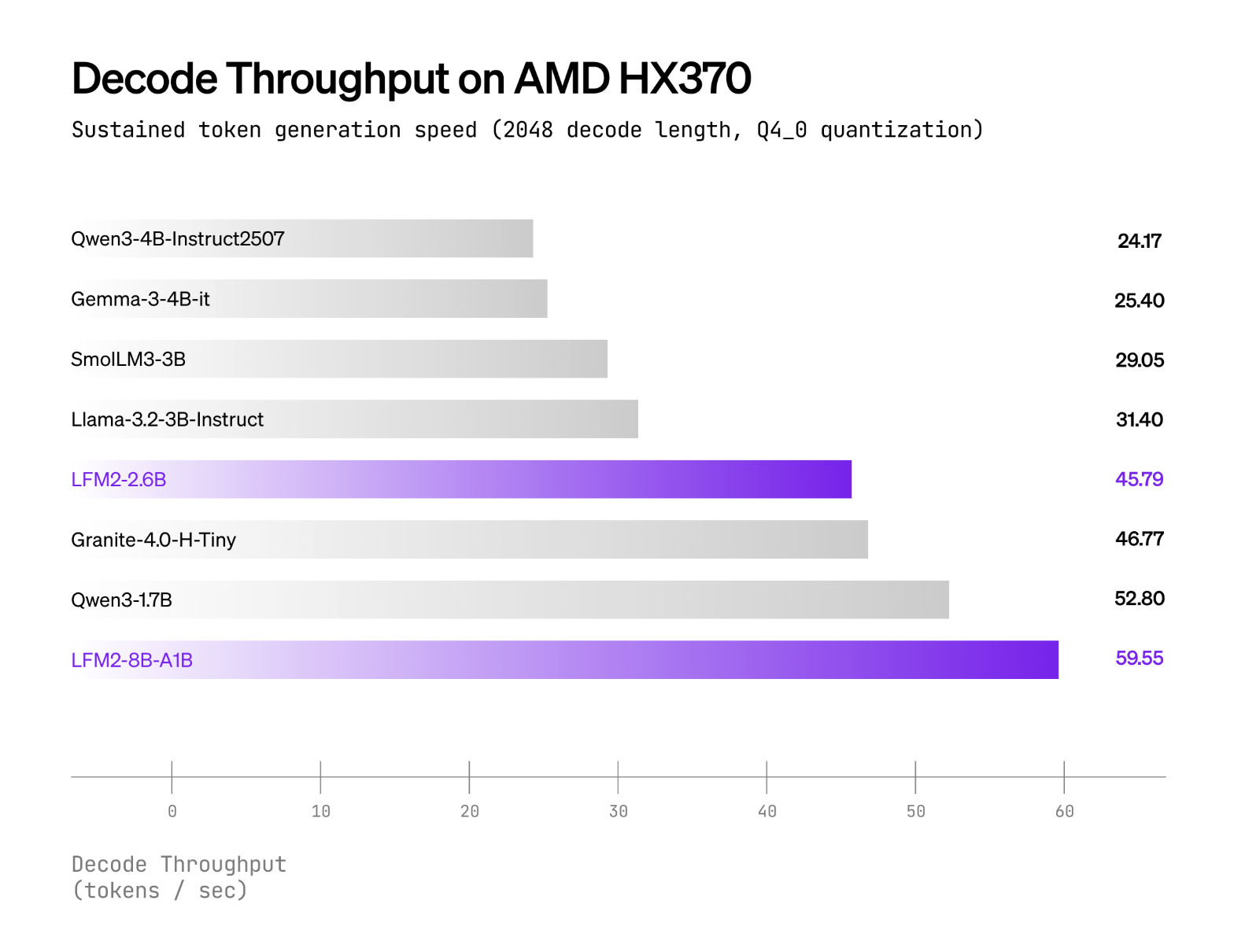
Liquid AI stories LFM2-8B-A1B. Runs considerably sooner than Qwen3-1.7B CPU assessments use an inner XNNPACK-based stack and a customized CPU MoE kernel. Scope of public land int4 quantization with int8 dynamic activation above AMD Ryzen AI 9 HX370 and samsung galaxy s24 extremely. The Liquid AI group equates high quality with: 3-4B excessive density mannequinWhereas protecting energetic computing shut by, 1.5B. The “x Sooner” headline multiplier between distributors just isn’t publicly accessible. Claims are structured as energetic fashions in addition to device-by-device comparisons.
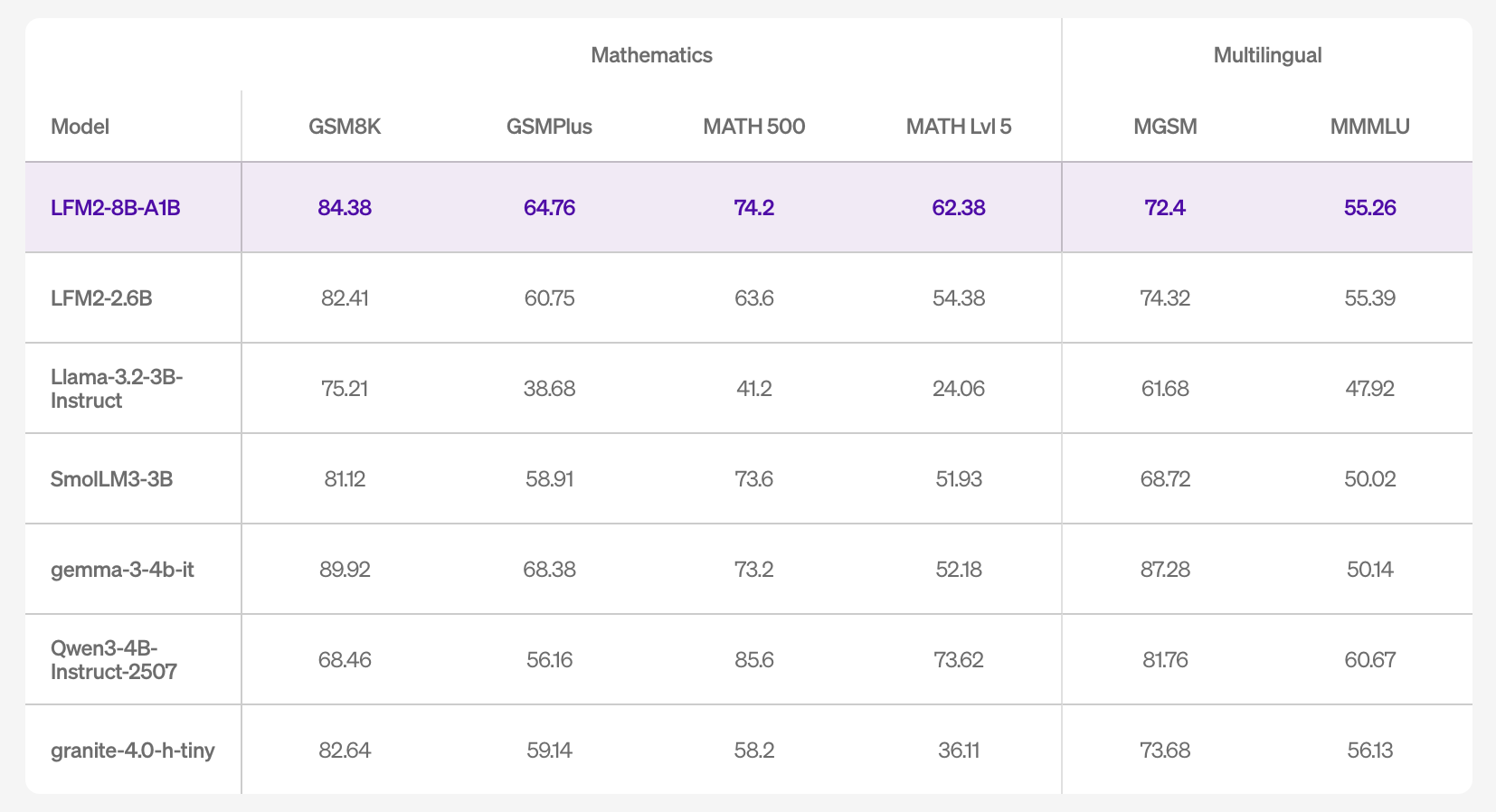
By way of accuracy, the mannequin card lists outcomes throughout 16 benchmarks, together with MMLU/MMLU-Professional/GPQA (information), IFEval/IFBench/Multi-IF (subsequent directions), GSM8K/GSMPlus/MATH500/MATH-Lvl-5 (math), and MGSM/MMMLU (multilingual). This determine demonstrates improved in-band competing instruction-following and mathematical efficiency for the small-scale mannequin, in addition to improved information capability in comparison with LFM2-2.6B, according to a bigger whole parameter price range.

Introduction and instruments
LFM2-8B-A1B ships with Transformers/vLLM for GPU inference and a GGUF construct for llama.cpp. The official GGUF repository lists the next widespread quants: Q4_0 ≈4.7 GB to F16 ≈16.7GB For native runs, llama.cpp Requires latest construct lfm2moe help (b6709+) to keep away from “Unknown mannequin structure” errors. What’s utilized in Liquid CPU verification? Q4_0 and int8 dynamic activation above AMD Ryzen AI 9 HX370 and samsung galaxy s24 extremelyRight here, LFM2-8B-A1B exhibits increased decoding throughput than LFM2-8B-A1B. Quen 3-1.7B Comparable energetic parameter class. operating torch Referenced for cell/embedded CPU deployment.
Essential factors
- Structure and routing: LFM2-8B-A1B combines an LFM2 high-speed spine (18 gate short-conv blocks + 6 GQA blocks) with per-layer sparse MoE FFNs (all layers besides the primary two) and makes use of 32 consultants with regularized sigmoid gates and top-4 routing by way of adaptive bias. Complete parameters 8.3 billion, as much as 1.5 billion energetic per token.
- Goal on system: Designed for cell phones, laptops, and embedded CPUs/GPUs. The quantized variant “matches comfortably” into high-end client {hardware} for personal, low-latency use.
- Efficiency positioning. Liquid report LFM2-8B-A1B is Considerably sooner than Qwen3-1.7B Targets and targets in CPU testing 3-4B excessive density class high quality Whereas sustaining an energetic path of roughly 1.5B.
LFM2-8B-A1B exhibits that sparse MoE is extra sensible than common server-scale regimes. This mannequin combines an LFM2 conv-attention spine with per-layer professional MLP (apart from the primary two layers) to maintain token complexity near 1.5B whereas elevating high quality to the 3-4B dense class. With normal and GGUF weights, llama.cpp/ExecuTorch/vLLM paths, and permissive on-device posture, the LFM2-8B-A1B is a concrete choice for constructing low-latency non-public assistants and application-embedded copilots on client and edge {hardware}.
Please test Models with hugging faces and technical details. Please be at liberty to test it out GitHub page for tutorials, code, and notebooks. Please be at liberty to observe us too Twitter Remember to affix us 100,000+ ML subreddits and subscribe our newsletter. hold on! Are you on telegram? You can now also participate by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a man-made intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information, which is technically sound and simply understood by a large viewers. The platform boasts over 2 million views monthly, demonstrating its reputation amongst viewers.

{kind=link}