


Lengthy-context large-scale language fashions (LLMs) face reminiscence bottlenecks which are unrelated to mannequin weights. Throughout decoding, the transformer caches the key-value (KV) vectors for all tokens in all layers, so there isn’t a have to recompute consideration. This cache grows linearly with sequence size and batch measurement, and the mannequin itself can have a smaller footprint in lengthy contexts with excessive concurrency.
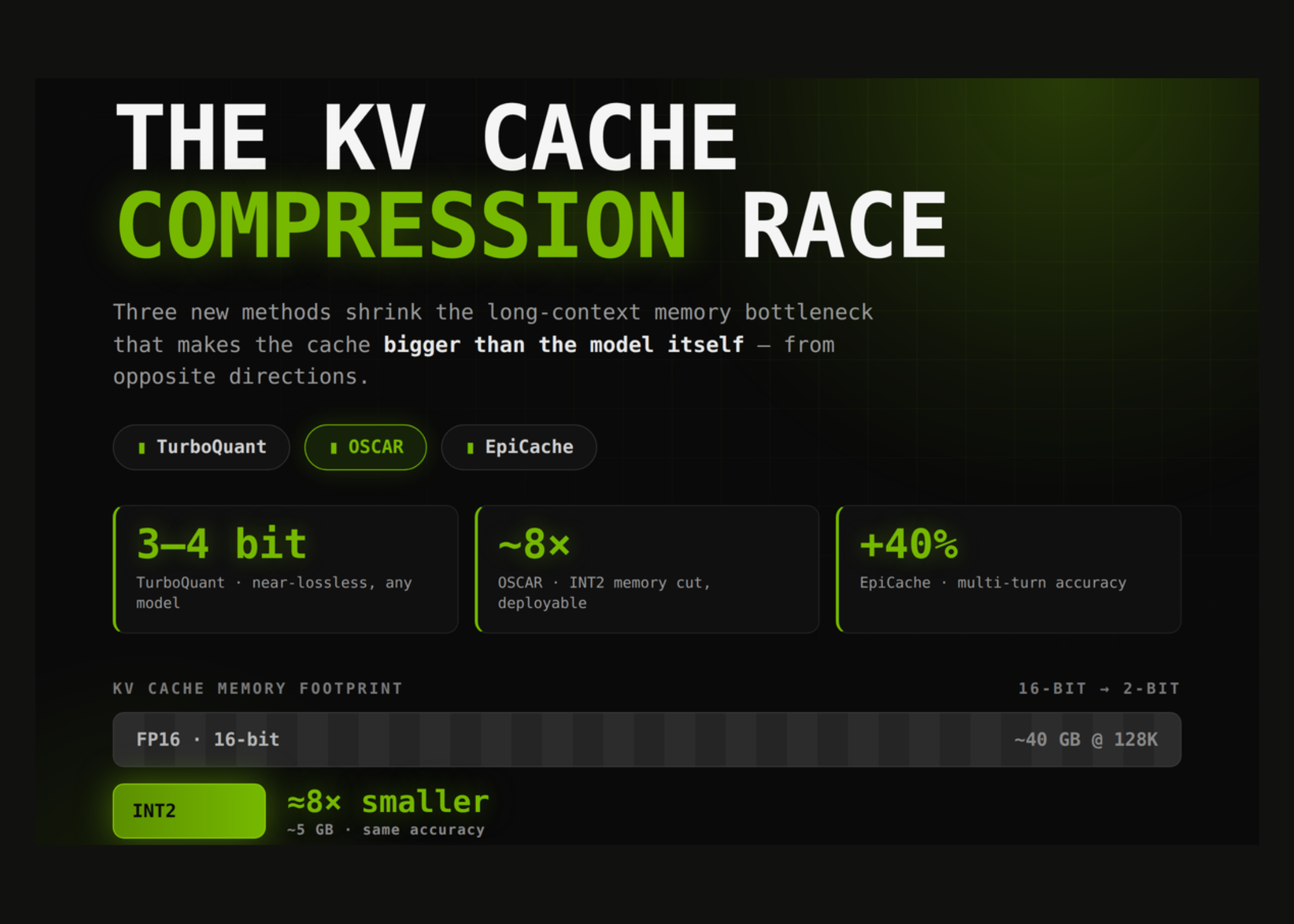
Take into account Llama-3.1-70B in BF16. The price of that KV cache is roughly 0.31 MB per token (80 layers × 8 KV heads × 128 head dims × 2 tensors × 2 bytes). With 128K tokens, that is about 40 GB. That is over 300 GB for 1M tokens and over 140 GB for the load itself. To make issues worse, each newly decoded token requires streaming your complete cache from high-bandwidth reminiscence (HBM), pushing decoding to the reminiscence bandwidth restrict slightly than the compute restrict. Due to this fact, shrinking the KV cache is probably the most direct means to scale back each price and decoding delay.
Present approaches fall into roughly 5 teams. Token eviction (H2O, SnapKV), Quantization (millet, gear), low rank projection (pal), mix (KVMerger), and Sharing structure (MLA). Current analysis in 2026 focuses on the frontier of ultra-low bit quantization. Google and New York College turbo quanto (ICLR 2026) and Collectively AI oscar Whereas attacking the identical downside from the wrong way, Apple epicash Deal with issues that nobody else is addressing.
Most KV quantizers are preventing the identical basic enemy. Outlier channel — A small variety of channels with disproportionately massive magnitudes that dominate the quantization vary and push the remainder of the sign into a number of representable ranges. Because of this easy INT2 quantization (solely 4 ranges) collapses to close zero precision.
millet We have now established an ordinary baseline right here. We have now proven that the important thing vector has a hard and fast outlier channel throughout tokens, however the worth vector doesn’t, so we quantize the important thing per channel and values per token. This tuning-free 2-bit recipe reduces end-to-end peak reminiscence (together with weights) by an element of roughly 2.6, and serves as a reference level for constructing new strategies.
TurboQuant: Theoretically optimum with out being conscious of information
TurboQuant handles outliers in two steps with out reviewing the info:
- Stage 1: Every vector is randomly rotated so its coordinates are practically unbiased and roughly Gaussian distributed. This is applicable a precomputed optimum scalar (Lloyd–Max) quantizer to every coordinate.
- Stage 2: A 1-bit quantized Johnson-Lindenstrauss (QJL) rework is utilized to the residuals to acquire an unbiased estimate of the eye logit with out the overhead of a normalization fixed.
The promoting level is theoretical. TurboQuant’s distortion has been confirmed to be inside a small fixed issue (roughly 2.7 instances) of the decrease certain of knowledge principle. In apply, Needle-in-a-Haystack with 4x compression reaches just about good recall, with papers exhibiting absolute high quality neutrality at 3.5 bits and solely a small degradation at 2.5 bits per channel. It really works out-of-the-box with any mannequin because it requires no calibration and may operate as a quick vector database quantizer.
There’s one caveat price flagging. The extensively repeated statistic that “H100 improves your consideration span by 8 instances” comes from the next outcomes: Google’s blogrefers to a slim attention-logit microbenchmark, not a paper. TurboQuant’s documented candy spot is the near-lossless area of 3-4 bits.
OSCAR: Acknowledge alerts and deploy instantly
OSCAR bets on the alternative. The premise is that on the 4 ranges of INT2, data-aware rotation is the unsuitable instrument. Blindly smoothing the vary shouldn’t be sufficient when there may be little precision margin. Due to this fact, OSCAR is pay attention to warning Rotation from a one-time offline calibration move: keys are rotated to the distinctive foundation of the question covariance, and values are rotated to the score-weighted worth covariance. The Hadamard rework and bit-reversal permutation distribute the channel significance evenly throughout the quantization teams.
What makes OSCAR completely different is that it ships as an entire system, not simply an algorithm.
- Combined-precision web page cache: The sink and up to date tokens stay in BF16, however the historical past is compressed to INT2. In a 128K context, solely ~0.24% of the tokens stay in BF16.
- Fused Triton kernel Full SGLang integration (web page consideration and prefix cache appropriate).
- precomputed rotation (“RotationZoo”) for Qwen3-4B/8B/32B, GLM-4.7-FP8, and MiniMax-M2.7 — No recalibration required.
At efficient 2.28 bits, OSCAR lies inside 1.42 factors of Qwen3-8B’s BF16 and is successfully equal to Qwen3-32B (0.02 factors distinction). For GLM-4.7-FP8, the naive INT2 collapses to zero and the data-unaware baseline reaches solely low single digits. OSCAR matches BF16 and barely outperforms (inside noise) on the reported benchmarks. Collectively, AI stories ~7.83x job-level throughput and ~8x KV cache reminiscence discount in 100K contexts with ~3x quicker decoding.
So, who wins?
Neither — that is the trustworthy reply. for INT2 deployable with 128K tokens on supported fashionsOSCAR is presently the one confirmed possibility that will not break and comes with production-ready SGLang assist. for Coaching-free, model-independent quantization within the 3-4 bit areaTurboQuant presents far more versatility.
The OSCAR paper stories that TurboQuant is down greater than 40 factors on comparable budgets. Nonetheless, that analysis is carried out inside OSCAR’s proprietary framework, all layers are quantized, a single random seed is used, and it operates effectively beneath TurboQuant’s supposed bitwidth, offering a weak foundation for making a direct judgment. A extra fascinating chance is that the 2 are: complementary: The mix of calibration-aware rotation and an optimum scalar quantizer is a promising mixture that nobody has shipped but. (Each groups have publicly famous the identical concept.)
Third axis: EpiCache
Each TurboQuant and OSCAR are constructed for a single lengthy context. Neither deal with is lacking Prolonged multi-turn conversationsmany exchanges have a wealthy historical past. apple’s epicash is a no-training KV cache administration framework aimed toward precisely that hole.
- Prefill per block Course of historical past in blocks to restrict peak reminiscence.
- episodic clustering It divides the dialog into coherent semantic “episodes”, every with its personal compression cache.
- Episode match search Route every question to probably the most related episode throughout inference.
- Adaptive layer-by-layer funds allocation Measure every layer’s sensitivity to eviction and distribute the reminiscence funds accordingly.
Throughout LongMemEval, RealTalk, and LoCoMo, EpiCache stories as much as 40% increased accuracy than eviction baselines, near-full cache accuracy with 4-6x compression, and as much as 3.5x decrease peak reminiscence (and as much as 2.4x decrease latency). As a result of that decides which one Token to carry how precisely To save lots of them, immediately synthesize them utilizing OSCAR or TurboQuant to additional improve the financial savings.
Necessary factors
- turbo quanto Pushing the frontier with out counting on theoretical fashions. That is the go-to for attaining 3-4 bit near-lossless compression on any mannequin.
- oscar Leads the deployable INT2 with as much as 7.83x throughput and as much as 8x reminiscence financial savings in 100K contexts on supported fashions.
- epicash It solves conversational reminiscence throughout turns, attaining as much as 40% increased accuracy and three.5x decrease peak reminiscence than eviction, and synthesizes with both quantizer.
- Choice by constraints: Mix orthogonal methods to swimsuit, contemplating bit-width funds, mannequin portability, or dialog size. These approaches are complementary slightly than aggressive.
supply of knowledge
Arnav is presently a pupil at Rochester Institute of Expertise, incomes a bachelor’s diploma in laptop science and a minor in economics with hands-on backend improvement expertise. He’s additionally a contributor to Marktechpost, the place he writes about AI/ML analysis.

{kind=link}