


Amazon Q Enterprise is a generative AI-powered assistant that may reply questions, present summaries, generate content material, and extract insights straight from the content material of digital and scanned PDF paperwork in your enterprise knowledge sources, with out the necessity to pre-extract textual content.
Clients in industries corresponding to finance, insurance coverage, and healthcare life sciences have to derive insights from many sorts of paperwork which can be usually in scanned PDF format, corresponding to receipts, healthcare plans, tax statements, and so on. These doc sorts are sometimes in semi-structured or unstructured codecs and require processing to extract textual content earlier than they are often listed by Amazon Q Enterprise.
With the launch of help for scanned PDF paperwork in Amazon Q Enterprise, now you can seamlessly course of quite a lot of multimodal doc sorts by means of the AWS Administration Console and APIs in all supported Amazon Q Enterprise AWS Areas. Utilizing supported connectors, you may ingest and index paperwork corresponding to scanned PDFs out of your knowledge sources, after which use the paperwork to reply questions, present summaries, and generate content material out of your enterprise techniques securely and precisely. This characteristic eliminates the event effort required to extract textual content from scanned PDF paperwork outdoors of Amazon Q Enterprise and improves doc processing pipelines for constructing generative synthetic intelligence (AI) assistants utilizing Amazon Q Enterprise.
On this publish, I present you tips on how to use Amazon Q Enterprise to asynchronously index scanned PDF paperwork and carry out real-time queries.
Answer overview
You need to use Amazon Q Enterprise with scanned PDF paperwork from the console, AWS SDK, or AWS Command Line Interface (AWS CLI).
Amazon Q Enterprise gives a flexible suite of information connectors that may combine with a variety of enterprise knowledge sources, enabling you to develop generative AI options with minimal setup and configuration. To study extra, see Amazon Q Enterprise, which is usually out there now. Bettering workforce productiveness with generative AI.
As soon as you’re prepared to make use of the Amazon Q Enterprise utility, you may add scanned PDFs on to your Amazon Q Enterprise index utilizing the console or API. Amazon Q Enterprise provides a number of knowledge supply connectors that let you consolidate and sync knowledge from a number of knowledge repositories right into a single index. This publish presents two eventualities for working with paperwork: one utilizing the direct doc add possibility and one utilizing the Amazon Easy Storage Service (Amazon S3) connector. If it’s essential ingest paperwork from different knowledge sources, see Supported Connectors for extra data on connecting to further knowledge sources.
Indexing paperwork
On this publish, I’ll use three scanned PDF paperwork as examples (a billing bill, a medical insurance abstract, and an employment verification kind) and a few textual content paperwork.
Step one is to index these paperwork. To index paperwork utilizing Amazon Q Enterprise’s direct add characteristic, comply with these steps: On this instance, we’ll add a scanned PDF.
- Within the Amazon Q Enterprise console, utility Within the navigation pane, open the applying.
- select addition Data supply.
- select Add a file.
- Add your scanned PDF file.
The uploaded file is Knowledge Supply tab. Add Standing Modifications from obtained To course of To index or Has been up to dateAt this level, your file has been efficiently listed into the Amazon Q Enterprise knowledge retailer. The next screenshot reveals a efficiently listed PDF.
The next steps present tips on how to combine and sync paperwork with Amazon Q Enterprise utilizing the Amazon S3 connector. On this instance, we index textual content paperwork.
- Within the Amazon Q Enterprise console, utility Within the navigation pane, open the applying.
- select Add a Knowledge Supply.
- select Amazon S3 For connectors.
- Enter your data Identify, VPC and Safety group settings, IAM roles, and Synchronous Mode.
- To attach your knowledge supply to Amazon Q Enterprise, Add a Knowledge Supply.
- In Knowledge supply particulars Within the Connector particulars web page part: Sync now Permits Amazon Q Enterprise to start synchronizing (crawling and ingesting) knowledge out of your knowledge sources.
As soon as the sync job is full, the info supply can be out there. The next screenshot reveals that each one 5 paperwork (scanned and digital PDFs, and a textual content file) have been efficiently listed.

The next screenshot reveals a complete view of two knowledge sources: paperwork uploaded straight and paperwork ingested by way of the Amazon S3 connector.

Now let’s run some queries in opposition to the info supply utilizing Amazon Q Enterprise.
Querying dense, unstructured, scanned PDF paperwork
Your paperwork might be dense, unstructured, scanned PDF doc sorts from which Amazon Q Enterprise can establish and extract probably the most salient information-dense textual content. On this instance, we use a multi-page medical insurance plan abstract PDF that we listed earlier. The next screenshot reveals a pattern web page.

That is an instance of a well being plan abstract doc.
The Amazon Q Enterprise internet UI asks, “What are the annual out-of-pocket limits listed on my medical insurance plan abstract?”
Amazon Q Enterprise searches listed paperwork, retrieves related data, and generates solutions whereas citing sources of that data. The next screenshot reveals a pattern output.

Querying structured, tabular, scanned PDF paperwork
Your paperwork might also include structured knowledge components in a tabular format. Amazon Q Enterprise can mechanically establish, extract, and linearize structured knowledge from scanned PDFs to precisely resolve person queries. Within the following instance, we use the bill PDF that we listed earlier. The next screenshot reveals an instance.
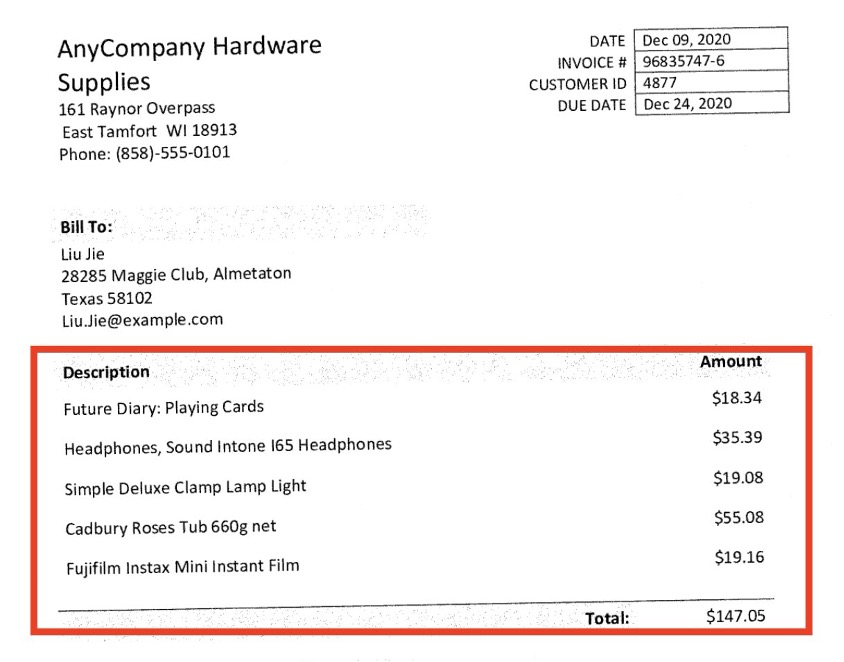
That is an instance of an bill.
The Amazon Q Enterprise internet UI asks, “How a lot are the headphones charged on my bill?”
Amazon Q Enterprise searches the listed paperwork and references the supply doc to get the reply. The next screenshot reveals that Amazon Q Enterprise can extract billing data from an bill.

Semi-structured type of queries
Paperwork might also include semi-structured knowledge components of their kind, corresponding to key-value pairs. Amazon Q Enterprise can exactly fulfill queries associated to those knowledge components by extracting particular fields or attributes which can be significant to the question. On this instance, we use an employment verification PDF. The next screenshot reveals an instance.

That is an instance of an employment verification doc.
Within the Amazon Q Enterprise internet UI, once you ask, “What are the applicant’s employment dates as acknowledged on the employment certificates?”, Amazon Q Enterprise will search the listed employment certificates and reference the supply doc to get the reply.

Indexing paperwork utilizing the AWS CLI
This part reveals you tips on how to use the AWS CLI to ingest structured and unstructured paperwork saved in an S3 bucket into an Amazon Q Enterprise index. You may shortly get detailed details about your paperwork, corresponding to their standing and any errors that occurred throughout indexing. If you’re an present Amazon Q Enterprise person and have listed paperwork in numerous codecs, corresponding to scanned PDFs or different supported sorts, and also you wish to reindex your scanned paperwork, comply with these steps:
- Test the standing of every doc and filter failed paperwork in keeping with their standing.
"DOCUMENT_FAILED_TO_INDEX"You may filter paperwork primarily based on the next error messages:
"errorMessage": "Doc can't be listed because it accommodates no textual content to index and search on. Doc should include some textual content."
If you’re a brand new person and haven’t listed any paperwork, you may skip this step.
Under is an instance of utilizing the ListDocuments API to filter paperwork with a selected standing and their error message.
The next screenshot reveals the AWS CLI output, together with a listing of failed paperwork with error messages.

Subsequent, course of the paperwork in batches. Amazon Q Enterprise helps including a number of paperwork to an Amazon Q Enterprise index.
- Use the BatchPutDocument API to ingest a number of scanned paperwork saved in an S3 bucket into an index.
The next screenshot reveals the output from the AWS CLI, with the failed paperwork displayed as an empty record.

- Lastly, we use the ListDocuments API once more to examine if all of the paperwork have been listed correctly.
The next screenshot reveals that the paperwork are listed within the knowledge supply.

cleansing
If you happen to create a brand new Amazon Q Enterprise utility and not wish to use it, unsubscribe from the applying, take away any assigned customers, and delete it to keep away from accumulating prices in your AWS account. Additionally, for those who not wish to use an listed knowledge supply, see Managing Amazon Q Enterprise Knowledge Sources for directions on deleting the listed knowledge supply.
Conclusion
On this publish, I mentioned Amazon Q Enterprise help for scanned PDF doc sorts. I highlighted the steps to sync, index, and question supported doc sorts, which now embrace scanned PDF paperwork, utilizing Amazon Q Enterprise generative AI. I additionally offered examples of queries in opposition to structured, unstructured, and semi-structured multi-modal scanned paperwork utilizing the Amazon Q Enterprise Internet UI and AWS CLI.
To study extra about this characteristic, see Supported Doc Codecs for Amazon Q Enterprise. Strive it out immediately within the Amazon Q Enterprise console. To study extra, see Amazon Q Enterprise and the Amazon Q Enterprise Person Information. Please ship us your suggestions under. AWS re:Post for Amazon Q Or contact us by means of your typical AWS help contacts.
Concerning the Creator
 Sonali Sahu She leads the Generative AI Specialist Options Structure workforce at AWS. She is an writer, thought chief, and passionate technologist. Her major focus is AI and ML and he or she is a frequent speaker at AI and ML conferences and meetups world wide. She has broad and deep expertise in expertise and the expertise trade with trade experience in healthcare, monetary sector, and insurance coverage.
Sonali Sahu She leads the Generative AI Specialist Options Structure workforce at AWS. She is an writer, thought chief, and passionate technologist. Her major focus is AI and ML and he or she is a frequent speaker at AI and ML conferences and meetups world wide. She has broad and deep expertise in expertise and the expertise trade with trade experience in healthcare, monetary sector, and insurance coverage.
 Chinmayi Lane I am a Generative AI Specialist Options Architect at AWS. I am keen about utilized arithmetic and machine studying. I give attention to designing clever doc processing and generative AI options for AWS clients. Outdoors of labor, I get pleasure from dancing salsa and bachata.
Chinmayi Lane I am a Generative AI Specialist Options Architect at AWS. I am keen about utilized arithmetic and machine studying. I give attention to designing clever doc processing and generative AI options for AWS clients. Outdoors of labor, I get pleasure from dancing salsa and bachata.
 Himesh Kumar is an skilled Senior Software program Engineer presently working in Amazon Q Enterprise at AWS. He’s keen about constructing distributed techniques within the generative AI/ML house. His experience extends to growing scalable and environment friendly techniques making certain excessive availability, efficiency and reliability. Past his technical abilities, he’s devoted to steady studying and retains himself on the forefront of technological developments in AI and Machine Studying.
Himesh Kumar is an skilled Senior Software program Engineer presently working in Amazon Q Enterprise at AWS. He’s keen about constructing distributed techniques within the generative AI/ML house. His experience extends to growing scalable and environment friendly techniques making certain excessive availability, efficiency and reliability. Past his technical abilities, he’s devoted to steady studying and retains himself on the forefront of technological developments in AI and Machine Studying.
 Chin Wei He’s a Senior Software program Developer within the Amazon Q enterprise workforce at AWS and is keen about constructing trendy functions utilizing AWS applied sciences. He loves community-driven studying and expertise sharing, particularly on machine studying internet hosting and inference associated subjects. At present, his major focus is constructing a serverless and event-driven structure for RAG knowledge ingestion.
Chin Wei He’s a Senior Software program Developer within the Amazon Q enterprise workforce at AWS and is keen about constructing trendy functions utilizing AWS applied sciences. He loves community-driven studying and expertise sharing, particularly on machine studying internet hosting and inference associated subjects. At present, his major focus is constructing a serverless and event-driven structure for RAG knowledge ingestion.

{kind=link}