


This submit was written in Mohamed Hossam at Brightskies.
Analysis universities engaged in giant scale AI and excessive efficiency computing (HPC) usually face vital infrastructure challenges that hinder innovation and gradual analysis findings. Conventional on-premises HPC clusters include lengthy GPU procurement cycles, strict scaling restrictions and sophisticated upkeep necessities. These obstacles restrict the power of researchers to shortly iterate AI workloads reminiscent of pure language processing (NLP), laptop imaginative and prescient, and primary mannequin (FM) coaching. Amazon Sagemaker HyperPod eases the heavy lifting concerned in constructing AI fashions. It helps you shortly scale mannequin growth duties reminiscent of coaching, fine-tuning, or inference throughout clusters of pre-configured HPC instruments and tons of or hundreds of AI accelerators (reminiscent of NVIDIA GPUS H100, A100) which might be built-in with autoscaling.
On this submit, we present how analysis universities can implement Sagemaker HyperPod to speed up AI analysis utilizing dynamic SluRM partitioning, fine-tuned GPU useful resource administration, budget-aware computational value monitoring, and multirosin node load balancing.
Answer overview
The Amazon Sagemaker HyperPod is designed to assist large-scale machine studying operations for researchers and ML scientists. The service is totally managed by AWS and removes operational overhead whereas sustaining enterprise-grade safety and efficiency.
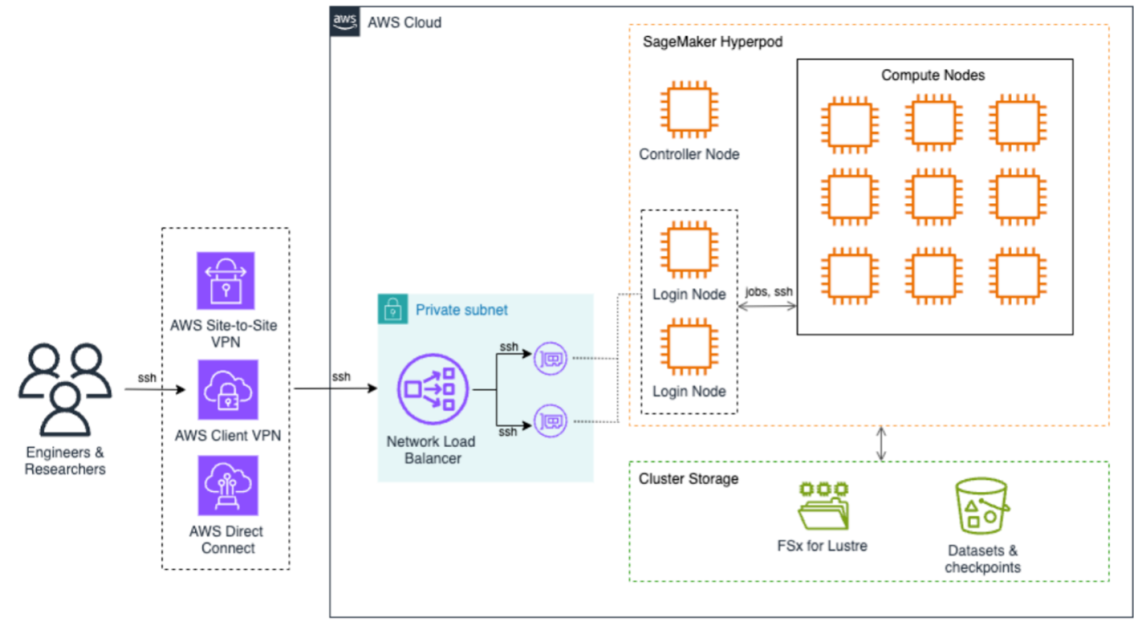
The next structure diagram reveals how you can entry the Sagemaker HyperPod and submit a job: Finish customers can securely entry Sagemaker HyperPod clusters utilizing AWS Web site-to-site VPN, AWS Consumer VPN, or AWS Direct Join. These connections finish on a community load balancer that effectively distributes SSH visitors to the login node. That is the principle entry level for job submission and cluster interplay. On the core of the structure is the Sege maker HyperPod Compute, controller nodes that coordinate cluster operations, and a number of compute nodes positioned within the grid configuration. This setup helps environment friendly distributed coaching workloads with excessive velocity interconnections between nodes. All of those are included inside a personal subnet for added safety.
The storage infrastructure is constructed round two essential parts: AmazonFSXfor Luster presents high-performance file system capabilities, whereas Amazon S3 gives devoted storage for datasets and checkpoints. This twin storage method gives each excessive velocity information entry for coaching workloads and guaranteeing worthwhile coaching artifacts.
The implementation consisted of a number of levels. The next steps present you how you can deploy and configure an answer.
Stipulations
Earlier than deploying Amazon Sagemaker HyperPod, be sure that the next stipulations are in place:
- AWS Configuration:
- AWS Command Line Interface (AWS CLI) with Acceptable Permissions
- Ready cluster configuration file:
cluster-config.jsonandprovisioning-parameters.json
- Community setup:
- AWS Identification and Administration (IAM) position with the next permissions:
Launch the CloudFormation stack
I launched the AWS CloudFormation stack to provision the mandatory infrastructure parts, together with VPCs and subnets, FSX for Luster file programs, S3 buckets for lifecycle scripts and coaching information, and IAM roles with scope transparency for cluster operations. Please see Amazon Sagemaker HyperPod Workshop For CloudFormation templates and automation scripts.
Customise the SluRM cluster configuration
To tailor the computing assets to the analysis wants of the division, we created SluRM partitions that replicate the organizational construction, together with NLP, laptop imaginative and prescient, and deep studying groups. I used it Slurm Partition Configuration Outline slurm.conf Comes with a customized partition. SLURM Accounting is now enabled by configuring slurmdbd Hyperlink utilization to division accounts and supervisors.
Generic Useful resource (GRES) configuration has been enabled to assist fractional GPU sharing and environment friendly use. GPU stripping permits a number of customers to entry the GPU on the identical node. GRES setup adopted tips from Amazon Sagemaker HyperPod Workshop.
Present and validate clusters
I’ve verified cluster-config.json and provisioning-parameters.json Information utilizing AWS CLI and Sagemaker HyperPod verification script:
Subsequent, I created a cluster.
Implement value monitoring and funds enforcement
To observe utilization and management prices, every sage maker’s hyperpod assets (e.g. Amazon EC2, FSX for Luster, and so forth.) have been tagged uniquely ClusterName tag. AWS Budgets and AWS Price Explorer Stories had been configured to trace month-to-month bills per cluster. Moreover, alerts had been set as much as notify researchers once they approached quota or funds thresholds.
This integration helped to advertise environment friendly use and predictable analysis spending.
Allow load balancing for the login node
Because the variety of concurrent customers elevated, the college adopted a multirosin node structure. Two login nodes have been deployed within the EC2 autoscaling group. The community load balancer consisted of goal teams for routing SSH and system supervisor visitors. Lastly, AWS Lambda enforces per-user session limits Run-As Tags with Session Supervisor, a function of Programs Supervisor.
For extra details about the total implementation, see Implementing Login Node Load Balancing in Sagemaker HyperPod to reinforce the multi-user expertise.
Configure federated entry and consumer mappings
To facilitate safe and seamless entry for researchers, Establishment has built-in on-premises Lively Listing (AD) utilizing AWS Listing Companies. This enables for uniform and administration of consumer identification, in addition to entry permissions throughout your Sagemaker HyperPod account. The implementation consisted of the next vital parts:
- Federation Consumer Integration – I used Session Supervisor to map advert customers to POSIX usernames
run-asNice management over tags and compute node entry - Safe session administration – I configured the System Supervisor to permit customers to entry utilizing my account as a substitute of the default
ssm-user - ID-based tagging – Federation usernames have been robotically mapped to consumer listing, workload, and funds through useful resource tags
For full step-by-step steering, see Amazon Sagemaker HyperPod Workshop.
This method streamlined consumer provisioning and entry management whereas sustaining robust consistency between company insurance policies and compliance necessities.
Put up-Deployment Optimization
To forestall pointless consumption of computing assets resulting from idle periods, the college has configured Slurm Pluggable Authentication Module (PAM). This setup will robotically sign off customers after a slam job has been accomplished or cancelled, supporting speedy availability of the computing nodes for queued jobs.
The configuration improved throughput job scheduling by shortly releasing idle nodes and decreasing administrative overhead in managing inactive periods.
furthermore, QoS Policy It was configured to regulate useful resource consumption, restrict work durations, and guarantee truthful GPU entry throughout customers and departments. for instance:
- Maxtresperuser – Ensure that per consumer GPU or CPU utilization stays inside outlined limits
- maxwalldurationperjob – Helps stop excessively lengthy jobs from monopolizing nodes
- Precedence weight – Modify precedence scheduling primarily based on analysis teams or initiatives
These extensions promoted an optimized, balanced HPC setting that was in keeping with the tutorial analysis institute’s shared infrastructure mannequin.
cleansing
To delete assets and forestall ongoing prices, full the next steps:
- Delete the Sagemaker HyperPod cluster.
- Removes the CloudFormation stack used for the Sagemaker HyperPod infrastructure.
This robotically removes associated assets, reminiscent of VPCs and subnets, Luster File System FSX, S3 buckets, and IAM roles. When you create these assets exterior of CloudFormation, you’ll need to manually delete them.
Conclusion
Sagemaker HyperPod presents analysis universities a strong, totally managed HPC answer tailor-made to the distinctive necessities of AI workloads. Automating infrastructure provisioning, scaling and useful resource optimization permits companies to speed up innovation whereas sustaining budgetary management and operational effectivity. By custom-made SluRM configurations, GPU sharing with GRE, federated entry and strong login node balancing, the answer highlights the potential to rework Sagemaker HyperPod analysis computing in order that researchers can give attention to science moderately than infrastructure.
For extra info on how you can benefit from your Sagemaker HyperPod, click on Sagemaker HyperPod Workshop Discover out extra weblog posts about Sagemaker HyperPod.
In regards to the creator
 Tasneem Fathima I’m a senior answer architect at AWS. She helps UAE’s increased schooling and analysis purchasers to undertake cloud know-how, enhance time to science, and innovate on AWS.
Tasneem Fathima I’m a senior answer architect at AWS. She helps UAE’s increased schooling and analysis purchasers to undertake cloud know-how, enhance time to science, and innovate on AWS.
 Mohamed Hotham Specializing in AWS’ high-performance computing (HPC) and AI infrastructure at Brightskies’ Senior HPC Cloud Options Architect. He helps universities and analysis institutes within the Gulf and Center East as he leverages GPU clusters, accelerates AI adoption, and migrates HPC/AI/ML workloads to the AWS cloud. Throughout his free time, Mohamed enjoys enjoying video video games.
Mohamed Hotham Specializing in AWS’ high-performance computing (HPC) and AI infrastructure at Brightskies’ Senior HPC Cloud Options Architect. He helps universities and analysis institutes within the Gulf and Center East as he leverages GPU clusters, accelerates AI adoption, and migrates HPC/AI/ML workloads to the AWS cloud. Throughout his free time, Mohamed enjoys enjoying video video games.

{kind=link}