


Image this: Your group simply obtained 10,000 buyer suggestions responses. The standard strategy? Weeks of handbook evaluation. However what if AI couldn’t solely analyze this suggestions but additionally validate its personal work? Welcome to the world of huge language mannequin (LLM) jury techniques deployed utilizing Amazon Bedrock.
As extra organizations embrace generative AI, notably LLMs for varied purposes, a brand new problem has emerged: guaranteeing that the output from these AI fashions aligns with human views and is correct and related to the enterprise context. Handbook evaluation of huge datasets could be time consuming, useful resource intensive, and thus impractical. For instance, manually reviewing 2,000 feedback can take over 80 hours, relying on remark size, complexity, and researcher analyses. LLMs supply a scalable strategy to function qualitative textual content annotators, summarizers, and even judges evaluating textual content outputs from different AI techniques.
This prompts the query, “However how can we deploy such LLM-as-a-judge techniques successfully after which use different LLMs to judge efficiency?”
On this submit, we spotlight how one can deploy a number of generative AI fashions in Amazon Bedrock to instruct an LLM mannequin to create thematic summaries of textual content responses (similar to from open-ended survey inquiries to your clients) after which use a number of LLM fashions as a jury to overview these LLM generated summaries and assign a ranking to evaluate the content material alignment between the abstract title and abstract description. This setup is also known as an LLM jury system. Consider the LLM jury as a panel of AI judges, every bringing their very own perspective to judge content material. As an alternative of counting on a single mannequin’s probably biased view, a number of fashions work collectively to offer a extra balanced evaluation.
Drawback: Analyzing textual content suggestions
Your group receives 1000’s of buyer suggestions responses. Conventional handbook evaluation of responses would possibly painstakingly and resource-intensively take days or perhaps weeks, relying on the quantity of free textual content feedback you obtain. Various pure language processing strategies, although seemingly quicker, additionally require intensive knowledge cleanup and coding know-how to research the info successfully. Pre-trained LLMs supply a promising, comparatively low-code answer for rapidly producing thematic summaries from text-based knowledge as a result of these fashions have been proven to scale knowledge evaluation and cut back handbook overview time. Nevertheless, when counting on a single pre-trained LLM for each evaluation and analysis, considerations come up relating to biases, similar to mannequin hallucinations (that’s, producing inaccurate info) or affirmation bias (that’s, favoring anticipated outcomes). With out cross-validation mechanisms, similar to evaluating outputs from a number of fashions or benchmarking in opposition to human-reviewed knowledge, the danger of unchecked errors will increase. Utilizing a number of pre-trained LLMs can deal with this concern by offering sturdy and complete analyses, even permitting for enabling human-in-the-loop oversight, and enhancing reliability over a single-model analysis. The idea of utilizing LLMs as a jury means deploying a number of generative AI fashions to independently consider or validate one another’s outputs.
Resolution: Deploy LLM as judges on Amazon Bedrock
You need to use Amazon Bedrock to match the varied frontier basis fashions (FMs) similar to Anthropic’s Claude 3 Sonnet, Amazon Nova Professional, and Meta’s Llama 3. The unified Amazon Internet Providers (AWS) atmosphere and standardized API calls simplify deploying a number of fashions for thematic evaluation and judging mannequin outputs. Amazon Bedrock additionally solves for operational wants via a unified safety and compliance managed system and a constant mannequin deployment atmosphere throughout all fashions.
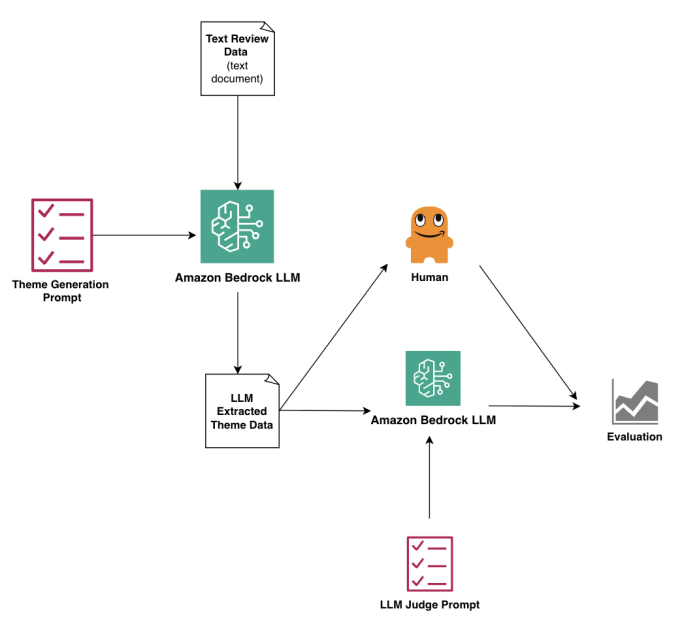
Our proposed workflow, illustrated within the following diagram, contains these steps:
- The preprocessed uncooked knowledge is ready in a .txt file and uploaded into Amazon Bedrock. A thematic era immediate is crafted and examined, then the info and immediate are run in Amazon SageMaker Studio utilizing a pre-trained LLM of selection.
- The LLM-generated summaries are transformed right into a .txt file, and the abstract knowledge is uploaded into SageMaker Studio.
- Subsequent, an LLM-as-a-judge immediate is crafted and examined, and the abstract knowledge and immediate are run in SageMaker Studio utilizing totally different pre-trained LLMs.
- Human-as-judge scores are then statistically in contrast in opposition to the mannequin efficiency. We use proportion settlement, Cohen’s kappa, Krippendorff’s alpha, and Spearman’s rho.
Conditions
To finish the steps, it is advisable have the next conditions:
- An AWS account with entry to:
- Primary understanding of Python and Jupyter notebooks
- Preprocessed textual content knowledge for evaluation
Implementation particulars
On this part, we stroll you thru the step-by-step implementation.
Do this out for your self by downloading the Jupyter notebook from GitHub.
- Create a SageMaker pocket book occasion to run the evaluation, after which initialize Amazon Bedrock and configure the enter and output file places on Amazon S3. Save the textual content suggestions you’d like to research as a .txt file in an S3 bucket. Use the next code:
- Use Amazon Nova Professional in Amazon Bedrock to generate LLM-based thematic summaries for the suggestions you need to analyze. Relying in your use case, you need to use any or a number of fashions provided by Amazon Bedrock for this step. The immediate offered right here can be generic and can should be tuned in your particular use case to present the LLM mannequin of selection sufficient context in your knowledge to allow applicable thematic categorization:
- Now you can use a number of LLMs as jury to judge the themes generated by the LLM within the earlier step. In our instance, we use Amazon Nova Professional and Anthropic’s Claude 3.5 Sonnet fashions to every analyze the themes per suggestions and supply an alignment rating. Right here, our alignment rating is on a scale of 1–3, the place 1 signifies poor alignment through which themes don’t seize the details, 2 signifies partial alignment through which themes seize some however not all key factors, and three signifies sturdy alignment through which themes precisely seize the details:
- When you’ve got the alignment scores from the LLMs, right here’s how one can implement the next settlement metrics to match and distinction the scores. Right here, if in case you have scores from human judges, you’ll be able to rapidly add these as one other set of scores to find how intently the human scores (gold commonplace) aligns with that of the fashions:
We used the next well-liked settlement metrics to match alignment and subsequently efficiency throughout and amongst fashions:
- Share settlement – Share settlement tells us what number of instances two raters present the identical ranking (for instance, 1–5) of the identical factor, similar to two folks offering the identical 5-star ranking of a film. The extra instances they agree, the higher. That is expressed as a proportion of the whole variety of instances rated and calculated by dividing the whole agreements by the whole variety of scores and multiplying by 100.
- Cohen’s kappa – Cohen’s kappa is actually a wiser model of proportion settlement. It’s like when two folks guess what number of of their 5 coworkers will put on blue within the workplace every day. Typically each folks guess the identical quantity (for instance, 1–5) by likelihood. Cohen’s kappa considers how effectively the 2 folks agree, past any fortunate guesses. The coefficients vary from −1 to +1, the place 1 represents excellent settlement, 0 represents settlement equal to likelihood, and unfavourable values point out settlement lower than likelihood.
- Spearman’s rho – Spearman’s rho is sort of a friendship meter for numbers. It exhibits how effectively two units of numbers “get alongside” or transfer collectively. If one set of numbers goes up and the opposite set additionally goes up, they’ve a constructive relationship. If one goes up whereas the opposite goes down, they’ve a unfavourable relationship. Coefficients vary from 1 to +1, with values nearer to ±1 indicating stronger correlations.
- Krippendorff’s alpha – Krippendorff’s alpha is a take a look at used to find out how a lot all raters agree on one thing. Think about two folks taste-testing totally different meals at a restaurant and ranking the meals on a scale of 1–5. Krippendorff’s alpha supplies a rating to indicate how a lot the 2 folks agree on their meals scores, even when they didn’t style each dish within the restaurant. The alpha coefficient ranges from 0–1, the place values nearer to 1 point out increased settlement amongst raters. Usually, an alpha above 0.80 signifies sturdy settlement, an alpha between 0.67 and 0.80 signifies acceptable settlement, and an alpha beneath 0.67 suggests low settlement. If calculated with the rationale that the degrees (1, 2, and three) are ordinal, Krippendorff’s alpha considers not solely settlement but additionally the magnitude of disagreement. It’s much less affected by marginal distributions in comparison with kappa and supplies a extra nuanced evaluation when scores are ranked (ordinal). That’s, though proportion settlement and kappa deal with all disagreements equally, alpha acknowledges the distinction between minor (for instance, “1” in comparison with “2”) and main disagreements (for instance, “1” in comparison with “3”).
Success! When you adopted alongside, you’ve got now efficiently deployed a number of LLMs to evaluate thematic evaluation output from an LLM.
Extra issues
To assist handle prices when working this answer, take into account the next choices:
For delicate knowledge, take into account the next choices:
Outcomes
On this submit, we demonstrated how you need to use Amazon Bedrock to seamlessly use a number of LLMs to generate and choose thematic summaries of qualitative knowledge, similar to from buyer suggestions. We additionally confirmed how we are able to evaluate human evaluator scores of text-based summaries from survey response knowledge in opposition to scores from a number of LLMs similar to Anthropic’s Claude 3 Sonnet, Amazon Nova Professional, and Meta’s Llama 3. In recently published research, Amazon scientists confirmed LLMs confirmed inter-model settlement as much as 91% in contrast with human-to-model settlement as much as 79%. Our findings counsel that though LLMs can present dependable thematic evaluations at scale, human oversight continues to stay essential for figuring out delicate contextual nuances that LLMs would possibly miss.
The very best half? By way of Amazon Bedrock mannequin internet hosting, you’ll be able to evaluate the varied fashions utilizing the identical preprocessed knowledge throughout all fashions, so you’ll be able to select the one which works greatest in your context and want.
Conclusion
With organizations turning to generative AI for analyzing unstructured knowledge, this submit supplies perception into the worth of utilizing a number of LLMs to validate LLM-generated analyses. The sturdy efficiency of LLM-as-a-judge fashions opens alternatives to scale textual content knowledge analyses at scale, and Amazon Bedrock might help organizations work together with and use a number of fashions to make use of an LLM-as-a-judge framework.
In regards to the Authors
 Dr. Sreyoshi Bhaduri is a Senior Analysis Scientist at Amazon. At the moment, she spearheads modern analysis in making use of generative AI at scale to resolve complicated provide chain logistics and operations challenges. Her experience spans utilized statistics and pure language processing, with a PhD from Virginia Tech and specialised coaching in accountable AI from MILA. Sreyoshi is dedicated to demystifying and democratizing generative AI options and bridging the hole between theoretical analysis and sensible purposes utilizing AWS applied sciences.
Dr. Sreyoshi Bhaduri is a Senior Analysis Scientist at Amazon. At the moment, she spearheads modern analysis in making use of generative AI at scale to resolve complicated provide chain logistics and operations challenges. Her experience spans utilized statistics and pure language processing, with a PhD from Virginia Tech and specialised coaching in accountable AI from MILA. Sreyoshi is dedicated to demystifying and democratizing generative AI options and bridging the hole between theoretical analysis and sensible purposes utilizing AWS applied sciences.
 Dr. Natalie Perez focuses on transformative approaches to buyer insights and modern options utilizing generative AI. Beforehand at AWS, Natalie pioneered large-scale voice of worker analysis, driving product and programmatic enhancements. Natalie is devoted to revolutionizing how organizations scale, perceive, and act on buyer wants via the strategic integration of generative AI and human-in-the-loop methods, driving innovation that places clients on the coronary heart of product, program, and repair improvement.
Dr. Natalie Perez focuses on transformative approaches to buyer insights and modern options utilizing generative AI. Beforehand at AWS, Natalie pioneered large-scale voice of worker analysis, driving product and programmatic enhancements. Natalie is devoted to revolutionizing how organizations scale, perceive, and act on buyer wants via the strategic integration of generative AI and human-in-the-loop methods, driving innovation that places clients on the coronary heart of product, program, and repair improvement.
 John Kitaoka is a Options Architect at Amazon Internet Providers (AWS) and works with authorities entities, universities, nonprofits, and different public sector organizations to design and scale AI options. His work covers a broad vary of machine studying (ML) use instances, with a major curiosity in inference, accountable AI, and safety. In his spare time, he loves woodworking and snowboarding.
John Kitaoka is a Options Architect at Amazon Internet Providers (AWS) and works with authorities entities, universities, nonprofits, and different public sector organizations to design and scale AI options. His work covers a broad vary of machine studying (ML) use instances, with a major curiosity in inference, accountable AI, and safety. In his spare time, he loves woodworking and snowboarding.
 Dr. Elizabeth (Liz) Conjar is a Principal Analysis Scientist at Amazon, the place she pioneers on the intersection of HR analysis, organizational transformation, and AI/ML. Specializing in folks analytics, she helps reimagine staff’ work experiences, drive high-velocity organizational change, and develop the subsequent era of Amazon leaders. All through her profession, Elizabeth has established herself as a thought chief in translating complicated folks analytics into actionable methods. Her work focuses on optimizing worker experiences and accelerating organizational success via data-driven insights and modern technological options.
Dr. Elizabeth (Liz) Conjar is a Principal Analysis Scientist at Amazon, the place she pioneers on the intersection of HR analysis, organizational transformation, and AI/ML. Specializing in folks analytics, she helps reimagine staff’ work experiences, drive high-velocity organizational change, and develop the subsequent era of Amazon leaders. All through her profession, Elizabeth has established herself as a thought chief in translating complicated folks analytics into actionable methods. Her work focuses on optimizing worker experiences and accelerating organizational success via data-driven insights and modern technological options.

{kind=link}