


Researchers at Toyota Laboratory have revealed Multiview Geometric Diffusion (MVGD). It unveils a groundbreaking diffusion-based structure that instantly combines the depth maps of recent high-fidelity RGB and sparse pose photographs. This innovation guarantees to redefine the frontier of 3D synthesis by offering a streamlined, strong and scalable resolution for producing reasonable 3D content material.
The core problem for MVGD addresses is to realize multiview consistency. Makes the generated new views seamlessly built-in into 3D area. Conventional strategies typically depend on the development of complicated 3D fashions which can be troubled by reminiscence constraints, gradual coaching, and restricted generalization. Nonetheless, MVGD instantly integrates implicit 3D inference right into a single diffusion mannequin, producing enter photographs with out intermediate 3D mannequin constructions and pictures and depth maps that keep scale alignment and geometric coherence.
MVGD makes use of the ability of diffusion fashions recognized for high-fidelity picture era to concurrently encode look and depth info.
Vital progressive elements embody:
- Pixel-level diffusion: Not like potential diffusion fashions, MVGD makes use of a token-based structure to work on the authentic picture decision and preserves particulars.
- Embed collaborative duties: Multitasking design permits fashions to collaborate RGB photographs and depth maps to make the most of unified geometric and visible advances.
- Scene scale normalization: MVGD routinely normalizes the scene scale based mostly on the pose of the enter digicam, making certain geometric consistency throughout a various dataset.
With coaching on an unprecedented scale with over 60 million multiview picture samples from real-world and artificial datasets, MVGD has distinctive generalization capabilities. Allow this massive dataset:
- Zero Shot Generalization: MVGD provides strong efficiency in invisible domains with out specific tweaks.
- Robustness to dynamics: Regardless of not explicitly modeling movement, MVGD makes use of transferring objects to successfully deal with the scene.
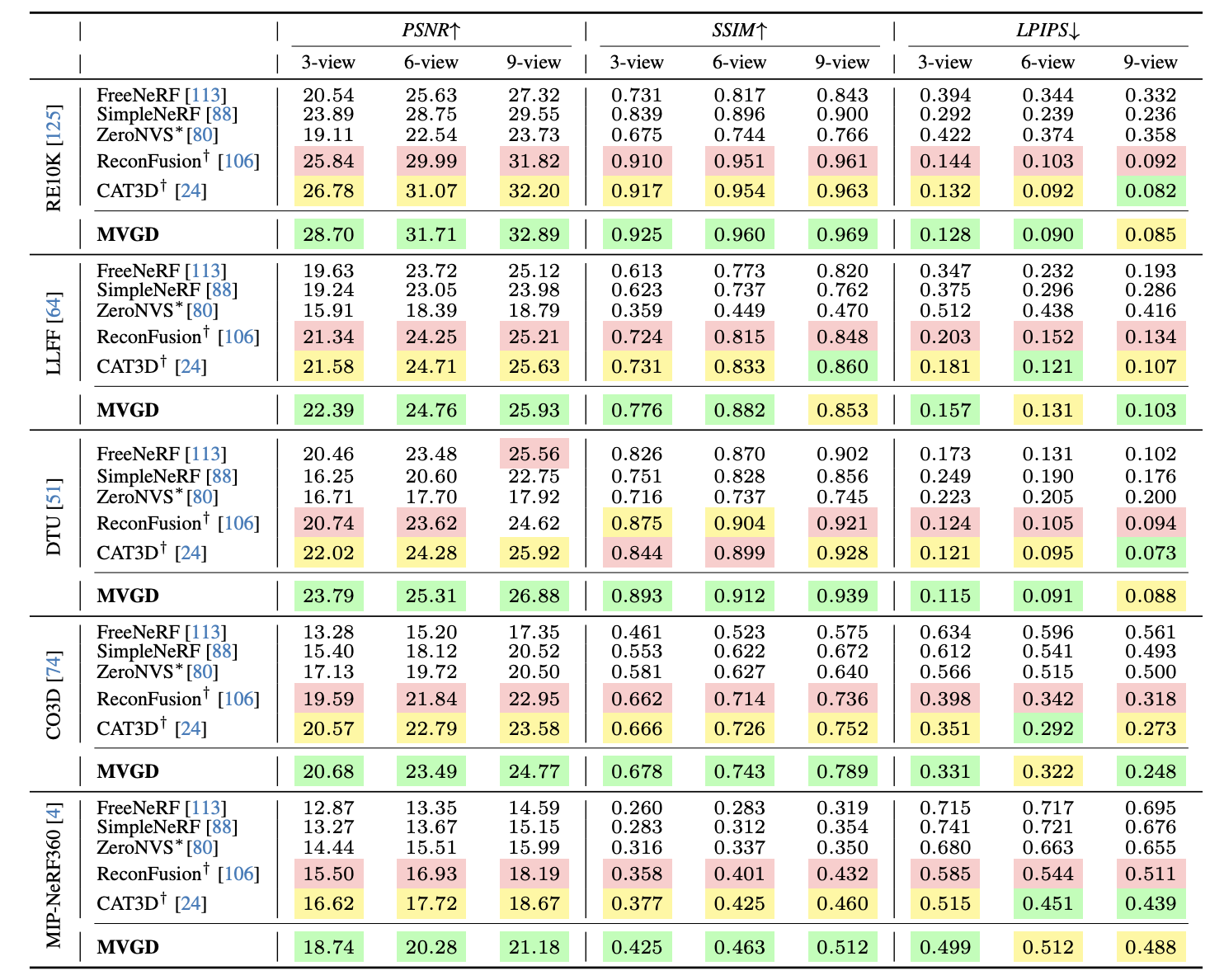
MVGD achieves cutting-edge efficiency with benchmarks resembling Realestate10K, Co3DV2, and Scannet, surpassing or matching present strategies in each new view synthesis and multiview depth estimation.
MVGD introduces incremental conditioning and scalable fine-tuning to enhance its versatility and effectivity.
- Incremental conditioning permits you to refine the generated new view by returning the generated new view to the mannequin.
- Scalable fine-tuning permits for scaling incremental fashions, bettering efficiency with out in depth retraining.
The which means of MVGD is necessary.
- Simplified 3D pipeline: Eliminating specific 3D representations streamline the combination and depth estimates of recent views.
- Enhanced realism: Joint RGB and depth energy era supply a brand new perspective that’s reasonable, 3D meaningless.
- Scalability and flexibility: MVGD handles all kinds of enter views. It’s important for large-scale 3D captures.
- Fast iteration: Nice tuning encourages adaptation to new duties and complexity.
MVGD represents a significant advance in 3D synthesis, combining subtle class with strong geometric cues to offer optically reasonable photographs and depth of scale recognition. This breakthrough illustrates the emergence of a “geometry-first” diffusion mannequin poised to revolutionize immersive content material creation, autonomous navigation, and spatial AI.
Check out paper. All credit for this examine will likely be despatched to researchers on this undertaking. Additionally, please be happy to observe us Twitter And do not forget to hitch us 80k+ ml subreddit.
🚨 Really useful Reads – LG AI Analysis releases NEXUS: Superior Programs that combine Agent AI Programs and Information Compliance Requirements to deal with authorized issues in AI datasets

Jean-Marc is a profitable AI govt. He led and accelerated the expansion of AI energy options and based a pc imaginative and prescient firm in 2006. He’s an AI Convention speaker and holds an MBA from Stanford.

{kind=link}