


Impressed by the mind neural community Important for picture recognition and language processing. These networks depend on activation features that may be taught complicated patterns. Nonetheless, many activation features face challenges. Some individuals wrestle with disappearing gradationstudying on deep networks is sluggish, whereas others undergo from “.died neuron”, sure elements of the community cease studying. Fashionable options intention to resolve these issues, however usually have drawbacks comparable to inefficiency and inconsistent efficiency.
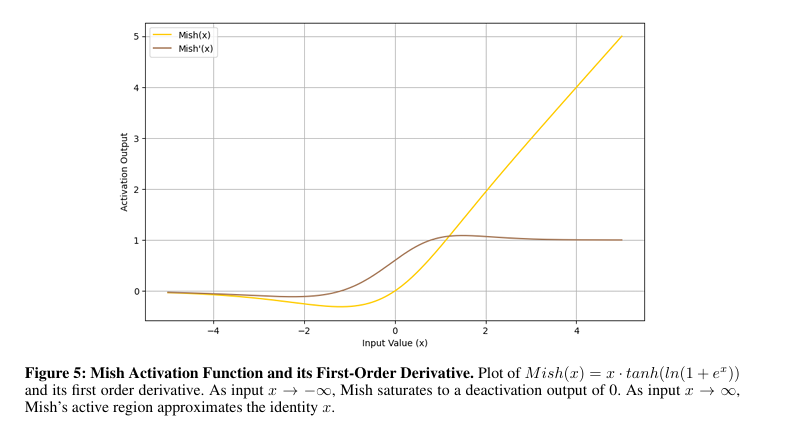
the present, activation operate Neural networks are going through critical issues. Options like step and sigmoid It suffers from vanishing gradients, limiting its effectiveness in deep networks. Tan This was a slight enchancment, however it turns on the market are different points. ReLU It does deal with some gradient points, however ‘die ReLU” downside happens, and neurons change into inactive. variations like Leaky ReLU and Prell I attempt to repair it, however it creates inconsistencies and challenges with regularization. Superior options comparable to Elle, Shiruand gel Enhance nonlinearity. Nonetheless, with added complexity and bias, new designs comparable to Mish and Smish confirmed stability solely in sure instances and didn’t work within the general case.
With the intention to clear up these issues, College of South Florida We proposed a brand new activation operate. TeLU(x) = x · Tanh(ex)It combines studying effectivity. ReLU It has clean operate stability and generalization capabilities. This operate introduces clean transitions the place the output of the operate modifications step by step in response to modifications within the enter, near-zero common activation, and sturdy gradient dynamics that overcome among the issues with current activation features. Masu. The aim of this design is to supply constant efficiency throughout completely different duties, enhance convergence, and improve stability by generalizing higher throughout shallow and deep architectures.
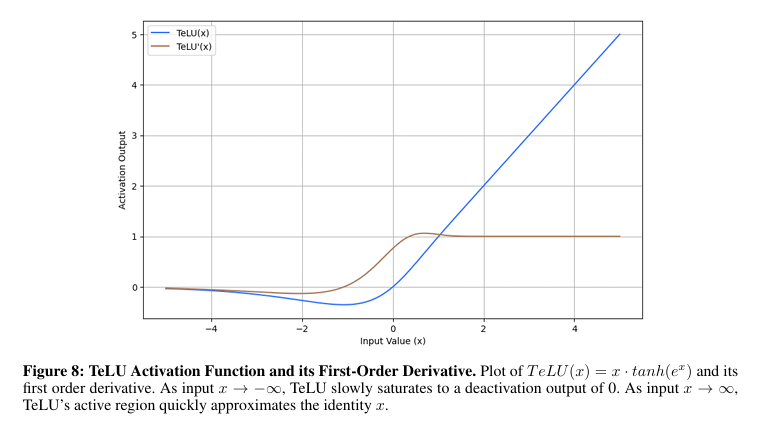
The researchers centered on enhancing neural networks whereas sustaining computational effectivity. The researchers aimed to make the algorithm converge shortly, preserve it steady throughout coaching, and make it sturdy to generalization to unseen information. This operate is non-polynomial and exists analytically. Subsequently, any steady goal operate could be approximated. This method centered on bettering studying stability and self-regularization whereas minimizing numerical instability. By combining linear and nonlinear properties, the framework can assist environment friendly studying and keep away from issues comparable to gradient explosion.

Rated by researchers Mr. TeLU We evaluated its efficiency via experiments and in contrast it with different activation features. The outcomes confirmed that Inform This helped forestall the vanishing gradient downside, which is vital for successfully coaching deep networks. Examined on giant datasets together with: picture internet and Text8 dynamic pooling transformerIt exhibits sooner convergence and higher accuracy than conventional features like . ReLU. Experiments additionally confirmed that Inform It’s computationally environment friendly and works effectively with ReLU-based configurations, usually resulting in improved outcomes. The experiment confirmed that Inform is steady and performs effectively throughout a wide range of neural community architectures and coaching strategies.

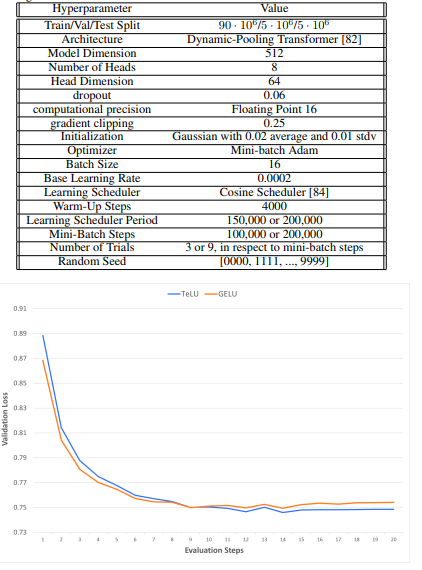
In the end, the activation operate proposed by the researchers outperforms current activation features by stopping the vanishing gradient downside, rising computational effectivity, and exhibiting higher efficiency throughout numerous datasets and architectures. Main challenges have been addressed. Efficiently utilized on benchmarks comparable to ImageNet, Text8, and Penn Treebank, demonstrating sooner convergence, improved accuracy, and stability for deep studying fashions, positioning TeLU as a promising software for deep neural networks. can. Moreover, TeLU’s efficiency can function a baseline for future analysis and encourage additional improvement of activation features to realize even greater effectivity and reliability in machine studying developments.
check out of paper. All credit score for this examine goes to the researchers of this challenge. Do not forget to observe us Twitter and please be part of us telegram channel and LinkedIn groupsHmm. Do not forget to hitch us 60,000+ ML subreddits.
🚨 Upcoming free AI webinars (January 15, 2025): Improve LLM accuracy with synthetic data and evaluation intelligence–Attend this webinar to gain actionable insights to improve the performance and accuracy of your LLM models while protecting your data privacy.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a bachelor’s diploma in agricultural and meals engineering from the Indian Institute of Know-how, Kharagpur. He’s a knowledge science and machine studying fanatic who desires to combine these cutting-edge applied sciences into the agricultural sector to resolve challenges.

{kind=link}