


I not too long ago tried out fashions from the Hugging Face catalog and am actually having fun with my every day work. I assumed this is perhaps a great alternative to share what I’ve discovered and provides readers some tips about how one can apply these fashions. With minimal stress.
My particular duties lately embrace going by means of chunks of unstructured textual content knowledge (notes, emails, free textual content remark fields, and so on.) and classifying them in response to classes which might be related to enterprise use circumstances. . There are lots of methods to do that. I have been exploring as some ways as doable, together with easy issues like sample matching and lexical search, in addition to utilizing pre-built neural community fashions for a wide range of functions. It has numerous options and I am moderately proud of the outcomes.
I believe the perfect technique is to include a number of methods in some sort of ensemble format to maximise your choices. I do not imagine that utilizing these fashions on their very own typically (and never persistently sufficient) essentially will get issues proper, however when mixed with extra primary methods they’ll enhance the sign additional. It may be strengthened.
As already talked about, the duty for me was to take a piece of textual content, often written by a human, with none constant format or schema, and attempt to perceive what classes apply to that textual content. Simply do it. To do that, we adopted a number of completely different approaches along with the analytical strategies described above. These approaches vary from very low effort to considerably extra concerned. These are the three methods I’ve examined to this point.
- Ask the mannequin to decide on a class (zero-shot classification — we’ll use this for instance later on this article)
- Use named entity recognition fashions to seek out key objects referenced in textual content and make classifications based mostly on them.
- Ask the mannequin to summarize the textual content and apply different methods to make a classification based mostly on the abstract.
This is likely one of the most enjoyable issues to do. Discover fashions within the Hugging Face catalog. in https://huggingface.co/models You may see an enormous assortment of accessible fashions added to the catalog by customers. Listed below are some suggestions and recommendation that can assist you select correctly.
- Do not take a look at downloads or likes and select one thing that hasn’t been tried and examined by a major variety of different customers. on every mannequin web page.[コミュニティ]It’s also possible to test the tabs to see if customers are discussing points or reporting bugs.
- If doable, examine who uploaded the mannequin to find out if it may be trusted. The one who skilled or tuned the mannequin might or might not know what she or he is doing, and the standard of the outcomes is determined by that particular person.
- Learn the documentation rigorously and skip fashions with little or no documentation. In any case, it is going to be tough to make use of them successfully.
- Use the filters on the aspect of the web page to slender down the precise mannequin to your job. The quantity of selection could also be enormous, but it surely’s effectively categorized that can assist you discover what you want.
- Most mannequin playing cards have a easy check that you may run to see how the mannequin works, however that is simply an instance, and the mannequin might be good at that, making this case very simple. Be aware that it was chosen as a result of it turned out to be .
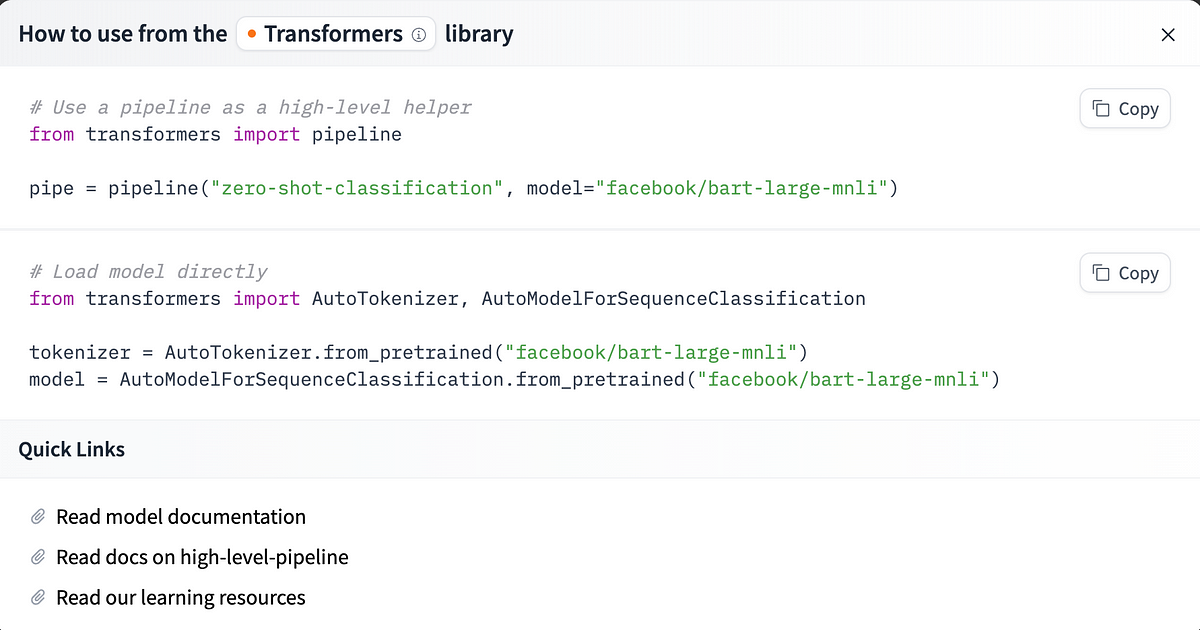
When you discover a mannequin you wish to strive, it is easy to get began. on the high proper of the mannequin card web page.[このモデルを使用する]Click on the button to see implementation choices.[Transformers]As soon as you choose an choice, you’ll be offered with the next steps:

If the mannequin you select just isn’t supported by the Transformers library, there could also be different methods listed reminiscent of TF-Keras, scikit-learn, and so on., however clicking that button will take you thru all of them with easy-to-use directions. Pattern code is displayed. .
In my experiments, all fashions had been supported by Transformers, so I might run them nearly simply by following these steps: You probably have any questions, you may as well discuss with our detailed documentation for full API particulars for the Transformers library and the varied courses it offers. I’ve frolicked checking these docs for particular courses when optimizing, however you do not really want to try this to get the fundamentals up and working.
Now, you might have selected the mannequin you wish to strive. Do you have already got knowledge? If not, this experiment used a number of publicly obtainable datasets, primarily from Kaggle. You will discover many helpful datasets there as effectively. Moreover, Hugging Face additionally has a dataset catalog that you may try, however in my expertise it isn’t that simple to seek out or perceive what’s in there (there’s simply not numerous documentation) .
After getting chosen a dataset of unstructured textual content knowledge, it isn’t tough to load it and use it in these fashions. Load the mannequin and tokenizer (from the documentation supplied by Hugging Face as above) and set all these to pipeline Features from the transformer library. Loop by means of a blob of textual content in a listing or pandas collection and move it to a mannequin perform. That is mainly the identical for no matter sort of job you’re doing, however for zero-shot classification you additionally want to supply a candidate label or checklist of labels, as proven under.
So, let’s take a more in-depth take a look at zero-shot classification. As talked about above, this includes utilizing a pre-trained mannequin to measure the similarity between the textual content and the label utilizing a discovered semantic embedding, particularly for untrained classes. It includes classifying textual content in response to. Clause.
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizer
from transformers import pipelinenli_model = AutoModelForSequenceClassification.from_pretrained("fb/bart-large-mnli", model_max_length=512)
tokenizer = AutoTokenizer.from_pretrained("fb/bart-large-mnli")
classifier = pipeline("zero-shot-classification", gadget="cpu", mannequin=nli_model, tokenizer=tokenizer)
label_list = ['News', 'Science', 'Art']
all_results = []
for textual content in list_of_texts:
prob = self.classifier(textual content, label_list, multi_label=True, use_fast=True)
results_dict = {x: y for x, y in zip(prob["labels"], prob["scores"])}
all_results.append(results_dict)
It will return a listing of dictionaries. Every of those dictionaries accommodates keys for doable labels, and the values are the possibilities for every label. You do not have to make use of a pipeline as we have finished right here, but it surely makes multi-label zero-shot a lot simpler than writing the code by hand, and it is easy to interpret and manipulate. Outcomes are returned.
For those who do not wish to use a pipeline, you are able to do one thing like this as an alternative, however you may need to do it as soon as for every label. Discover how we have to specify the processing of the logits ensuing from the mannequin run to acquire human-interpretable output. Additionally, you will have to load the tokenizer and mannequin as described above.
def run_zero_shot_classifier(textual content, label):
speculation = f"This instance is said to {label}."x = tokenizer.encode(
textual content,
speculation,
return_tensors="pt",
truncation_strategy="only_first"
)
logits = nli_model(x.to("cpu"))[0]
entail_contradiction_logits = logits[:, [0, 2]]
probs = entail_contradiction_logits.softmax(dim=1)
prob_label_is_true = probs[:, 1]
return prob_label_is_true.merchandise()
label_list = ['News', 'Science', 'Art']
all_results = []
for textual content in list_of_texts:
for label in label_list:
consequence = run_zero_shot_classifier(textual content, label)
all_results.append(consequence)
You’ve got most likely seen that I am not speaking about tweaking the mannequin myself for this undertaking – that is true. We might do that sooner or later, however we’re at the moment restricted by the truth that now we have minimal labeled coaching knowledge to work with. Whilst you might use semi-supervised methods or bootstrap a labeled coaching set, this entire experiment was about seeing how far you will get with a direct, off-the-shelf mannequin. I’ve some small labeled knowledge samples to make use of to check the mannequin’s efficiency, however they don’t seem to be almost as a lot as I would wish to tune the mannequin.
You probably have good coaching knowledge and wish to tune the bottom mannequin, Hugging Face has some useful documentation. https://huggingface.co/docs/transformers/en/training
Efficiency is an fascinating problem since I have been working all my experiments domestically on my laptop computer to this point. Naturally, utilizing these fashions for Hugging Face requires rather more computation and is slower than primary methods reminiscent of common expressions or dictionary lookups, however different strategies It is value discovering a method to optimize it, since you may get a sign that may’t be achieved in follow. All of those fashions are GPU-enabled and really simple to push to run on the GPU. (If you wish to strive it out on a GPU instantly, try the code proven above. Additionally, in case your programming atmosphere has a GPU obtainable, test the place “cpu” is changed in “cuda”. ) Nevertheless, costs from cloud suppliers aren’t low-cost, so prioritize accordingly and determine if sooner speeds are well worth the value.
Generally, GPU utilization is rather more vital for coaching (which you must remember when fine-tuning), however much less vital for inference. I will not delve into optimization right here, but when that is vital to you, you must also contemplate parallelism, each knowledge parallelism and precise coaching/compute parallelism.
I ran the mannequin! Listed below are the outcomes. I will offer you some suggestions on the finish on how one can overview the output and truly apply it to your enterprise questions.
- Do not blindly belief a mannequin’s output; run rigorous assessments to guage its efficiency. Simply because a transformer mannequin works effectively with a specific textual content blob, or can often accurately match textual content to a specific label, doesn’t imply that this can be a generalizable consequence. Use completely different examples and various kinds of textual content to show that your efficiency is adequate.
- In case you are assured in your mannequin and wish to use it in manufacturing, observe and report the mannequin’s habits. That is good follow for any mannequin in manufacturing, however you must preserve the generated outcomes along with the inputs you gave them so you may regularly test them to ensure efficiency is not degraded. That is much more vital with the sort of deep studying mannequin, as there may be much less interpretability as to why and the way the mannequin makes the inferences it makes. It is harmful to make too many assumptions concerning the internal workings of your mannequin.
As I discussed earlier than, I choose to make use of this type of mannequin output as half of a bigger pool of methods and mix them in an ensemble technique. By doing so, we will get hold of the indicators that these inferences can present, moderately than relying solely on one method. .
I hope this overview is beneficial for anybody seeking to get began with pretrained fashions for textual content (or different modes) evaluation. I want you the perfect.

{kind=link}