


Lots of my purchasers ask me for recommendation on which LLMs (massive language fashions) to make use of to construct merchandise tailor-made for Dutch-speaking customers. Nonetheless, many of the accessible benchmarks are multilingual and never particularly targeted on the Dutch language. As a Machine Studying Engineer and Postdoctoral Researcher in Machine Studying on the College of Amsterdam, I understand how essential benchmarks have been to the development of AI, however I additionally perceive the dangers of blindly trusting benchmarks. That is why I made a decision to experiment and run my very own Dutch-specific benchmark.
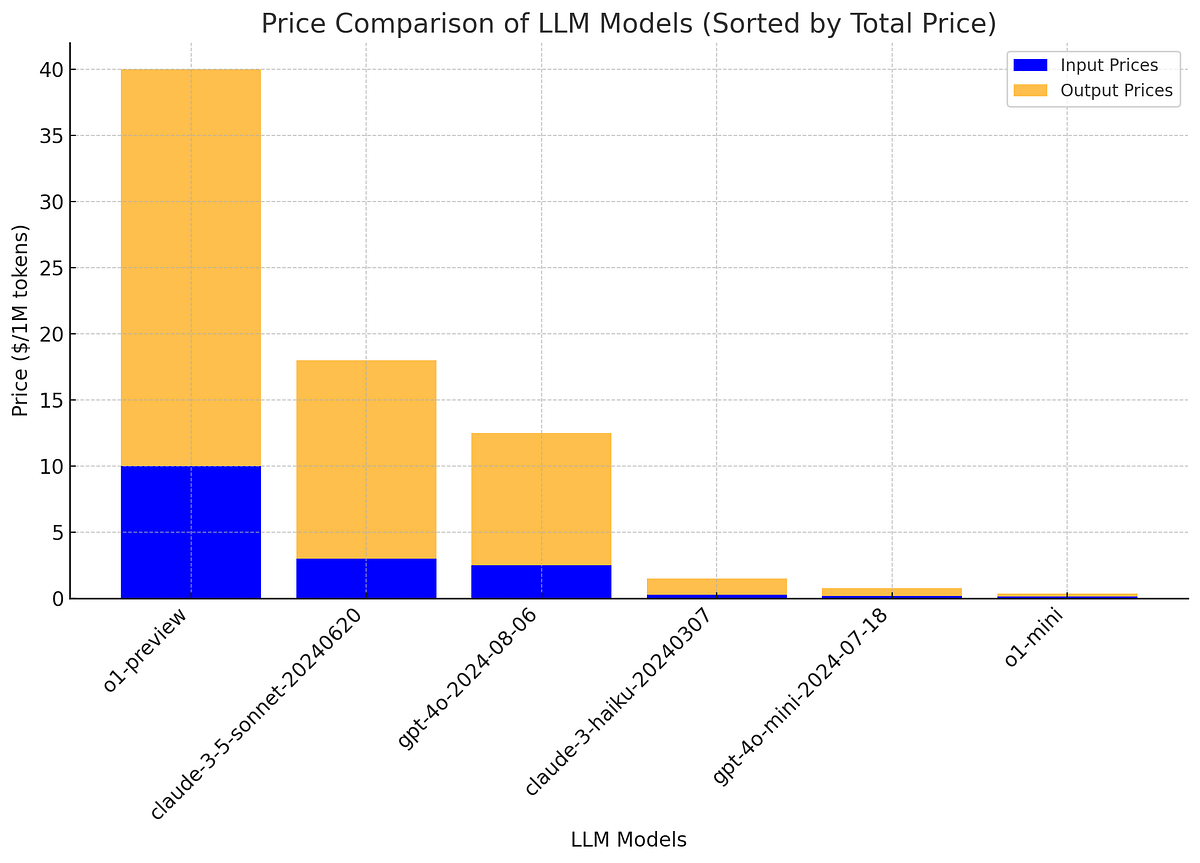
On this put up, I take a better have a look at my first try and benchmark a number of Massive Scale Language Fashions (LLMs) on actual Dutch examination questions. I information you thru the complete course of, from accumulating over 12,000 examination PDFs, to extracting question-answer pairs, to utilizing LLMs to mechanically rating the mannequin efficiency. You will note how fashions reminiscent of o1-preview, o1-mini, GPT-4o, GPT-4o-mini, and Claude-3 carried out on completely different Dutch training ranges, from VMBO to VWO, and whether or not greater prices for sure fashions result in higher outcomes. That is solely my first try on the downside, and sooner or later I could do extra such posts to discover different fashions and duties. I additionally focus on the challenges and prices concerned, and share my insights on the very best fashions for Dutch duties. In case you are constructing or extending an LLM-based product for the Dutch market, this put up will give you priceless insights to information your selections as of September 2024.
It is changing into increasingly more widespread for corporations like OpenAI to make daring, nearly hyperbolic, claims in regards to the capabilities of their fashions, typically with out ample real-world validation to again them up. That is why benchmarking these fashions is so essential – particularly once they’re touted as having the ability to remedy every little thing from advanced reasoning to nuanced language understanding. With such grandiose claims, it is important to run goal checks to see how properly they carry out in follow, and extra particularly, how they deal with the distinctive challenges of the Dutch language.
I used to be shocked to seek out that no in depth analysis on benchmarking Dutch LLMs has been executed to this point. That is what prompted me to sort out the issue myself on a wet afternoon. I felt that now was the fitting time to dive in and begin validating these fashions, as many establishments and corporations depend on them increasingly more. So right here is my first try and fill this hole. I hope it is going to present priceless insights for everybody working with Dutch.
Lots of my purchasers work with merchandise in Dutch and wish AI fashions which are cost-effective and carry out properly at understanding and processing Dutch. Whereas massive language fashions (LLMs) have made spectacular progress, many of the accessible benchmarks deal with English or multilingual options, typically ignoring the nuances of smaller languages reminiscent of Dutch. The dearth of deal with Dutch is essential as a result of when the mannequin is requested to grasp non-English textual content, linguistic variations can create vital gaps in efficiency.
5 years in the past, NLP (deep studying) fashions for Dutch had been removed from mature (like the primary variations of BERT). On the time, conventional methods reminiscent of TF-IDF mixed with logistic regression typically outperformed early deep studying fashions on the Dutch duties I labored on. Since then, fashions (and datasets) have improved considerably, particularly with the arrival of Transformers and multilingual pre-trained LLMs, however it’s nonetheless essential to look at how properly these advances translate to a selected language reminiscent of Dutch. The belief that efficiency beneficial properties in English will carry over to different languages will not be at all times legitimate, particularly for advanced duties reminiscent of studying comprehension.
That is why I targeted on making a customized benchmark for the Dutch language utilizing actual examination knowledge from the Dutch “Nederlands” exams (these exams are within the public area as soon as revealed). These exams transcend easy language processing; they check “begrijpend lezen” (studying comprehension), requiring college students to grasp the intent behind completely different texts and reply nuanced questions on them. This sort of activity is especially essential because it displays real-world functions, reminiscent of authorized paperwork, information articles, or processing and summarizing buyer inquiries written in Dutch.
By benchmarking LLM on this particular activity, I hoped to realize deeper perception into how the mannequin offers with the complexities of the Dutch language, particularly when requested to interpret intent, derive conclusions, and reply with correct solutions. That is essential for corporations constructing merchandise personalized for Dutch-speaking customers. Somewhat than counting on normal multilingual benchmarks that do not totally seize the complexities of the language, my aim was to create a extra focused and related benchmark that might assist us determine fashions that carry out greatest in Dutch.

{kind=link}