


Combination of Specialists (MoE) fashions have emerged as a key innovation in machine studying, notably in scaling giant language fashions (LLMs). These fashions are designed to handle the rising computational calls for of processing huge quantities of knowledge. By leveraging a number of specialised specialists inside a single mannequin, MoE architectures can effectively route particular duties to probably the most acceptable skilled, optimizing efficiency. This strategy has confirmed helpful in pure language processing (NLP), the place processing various and sophisticated duties concurrently is crucial to reaching accuracy and effectivity.
Probably the most important challenges that MoE fashions face is load imbalance amongst specialists. Some specialists bear a heavy activity load in such fashions, whereas others change into inefficient as they must be extra closely utilized. This imbalance can result in routing collapse, the place the mannequin repeatedly selects a number of specialists, hindering the general coaching course of. Moreover, uneven distribution of duties will increase computational overhead because the mannequin wants help to successfully handle the workload. Addressing this imbalance is essential because it instantly impacts the mannequin’s capability to carry out optimally, particularly when scaling as much as deal with giant datasets and sophisticated language processing duties.
Conventional strategies make use of auxiliary loss capabilities to mitigate the load imbalance drawback. These capabilities penalize the mannequin when duties are inconsistently distributed amongst specialists, encouraging a extra balanced load. Though this strategy helps obtain higher stability, it additionally introduces new challenges. Particularly, auxiliary losses introduce interfering gradients throughout coaching, that are in battle with the mannequin’s fundamental objective: language modeling. These undesirable gradients degrade the mannequin’s efficiency, making it troublesome to stability, preserve load stability, and obtain excessive accuracy in language processing duties. This trade-off has been a persistent difficulty within the improvement of MoE fashions.
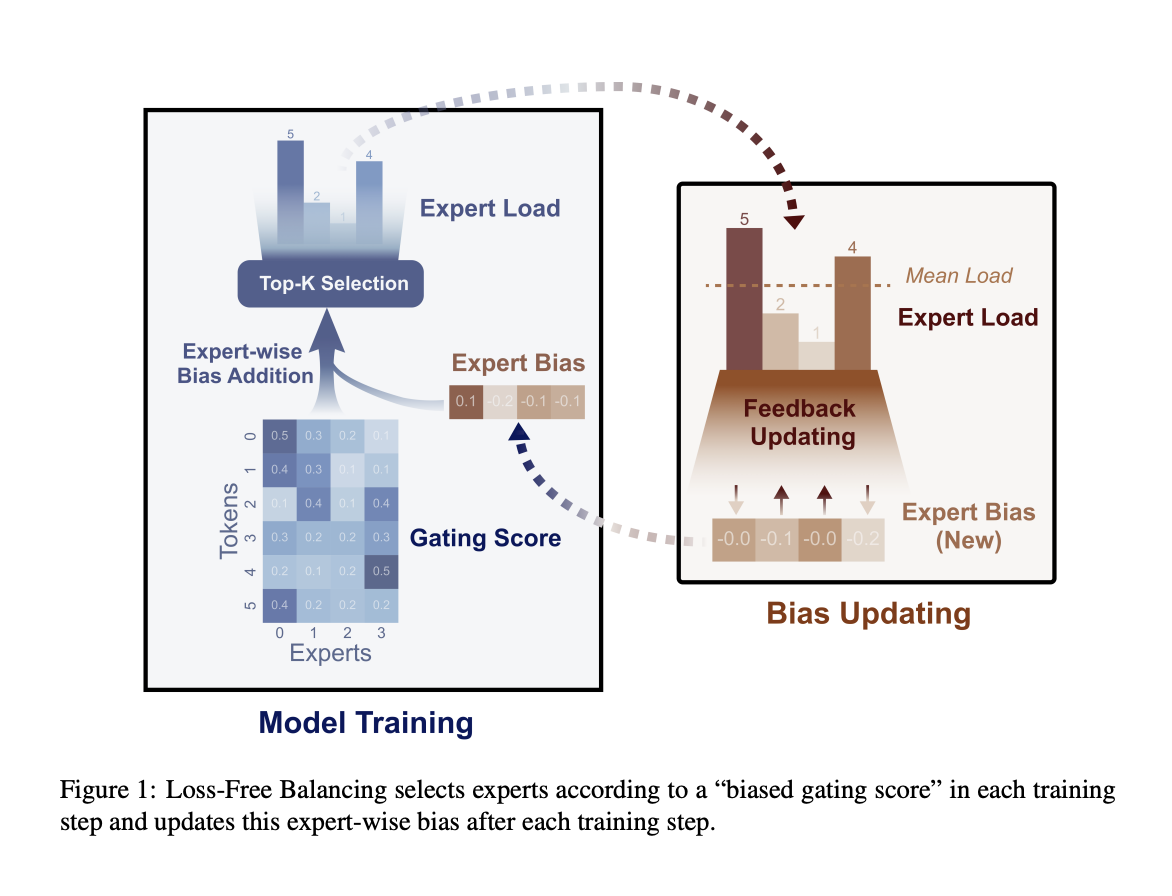
Researchers from DeepSeek-AI and Peking College Lossless balancingOur methodology eliminates the necessity for auxiliary loss capabilities by dynamically adjusting the routing of duties to specialists primarily based on their present load. Not like earlier strategies that launched dangerous gradients, loss-free balancing focuses on sustaining a balanced distribution of duties with out interfering with the mannequin’s major coaching objective. This strategy permits the mannequin to function extra effectively and ensures that each one specialists are successfully utilized with out compromising efficiency.
The loss-free balancing methodology works by means of a dynamic means of per-expert bias adjustment. Earlier than making a routing choice, the mannequin applies biases to every skilled’s routing rating. These biases are repeatedly up to date primarily based on every skilled’s latest load. For instance, if an skilled has been used regularly in latest coaching steps, its bias is adjusted downwards, lowering its load. Conversely, if an skilled is underused, its bias is elevated, encouraging the mannequin to route extra duties to that skilled. This iterative course of permits the mannequin to take care of a constant stability of options throughout all specialists, bettering effectivity and efficiency.
When it comes to experimental outcomes, the loss-free balancing methodology offers important enhancements over conventional auxiliary loss-based methods. In experiments performed on an MoE mannequin with one billion (1B) parameters and skilled with 100 billion (100B) tokens, and a bigger mannequin with three billion (3B) parameters and skilled with 200 billion (200B) tokens, the researchers noticed notable enhancements in each load stability and general mannequin efficiency. For instance, validation perplexity, a key indicator of mannequin efficiency, was lowered to 9.50 for the 1B parameter mannequin and seven.92 for the 3B parameter mannequin when loss-free balancing was used. The strategy lowered the utmost violation of world load stability (MaxVio) to 0.04, a major enchancment over the outcomes obtained with auxiliary loss-control strategies. These outcomes spotlight the effectiveness of the loss-free balancing strategy in sustaining balanced load distribution whereas bettering the language processing capabilities of the mannequin.

The analysis workforce additionally explored numerous configurations and tweaks to additional optimize the loss-free balancing methodology. They tried totally different bias replace charges and guidelines to find out the best strategy. For instance, an replace price of 0.001 supplied a great stability between convergence velocity and cargo stability. Whereas exploring various strategies corresponding to multiplicative bias, the researchers concluded that additive bias supplied higher efficiency and cargo stability. These enhancements highlighted the adaptability of the strategy and its potential for additional optimization in future purposes.

In conclusion, our loss-free balancing methodology allows extra environment friendly and efficient coaching of large-scale language fashions by addressing load imbalance with out introducing interfering gradients. Experimental outcomes, together with lowered validation perplexity and improved load stability metrics, reveal the potential of this strategy to enhance the efficiency of MoE fashions in quite a lot of purposes.
Test it out paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, do not forget to observe us. Twitter And our Telegram Channel and LinkedIn GroupsUp. For those who like our work, you’ll love our Newsletter..
Be part of us! 50k+ ML Subreddits
Listed below are some advisable webinars from our sponsors: “Building High-Performance AI Applications with NVIDIA NIM and Haystack”
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His newest endeavor is the launch of Marktechpost, an Synthetic Intelligence media platform. The platform stands out for its in-depth protection of Machine Studying and Deep Studying information in a fashion that’s technically correct but simply comprehensible to a large viewers. The platform has gained reputation amongst its viewers with over 2 million views each month.

{kind=link}