


This put up is co-written with HyeKyung Yang, Jieun Lim, and SeungBum Shim from LotteON.
LotteON goals to be a platform that not solely sells merchandise, but additionally supplies a customized suggestion expertise tailor-made to your most popular way of life. LotteON operates numerous specialty shops, together with style, magnificence, luxurious, and children, and strives to offer a customized buying expertise throughout all features of consumers’ life.
To boost the buying expertise of LotteON’s prospects, the advice service improvement group is repeatedly enhancing the advice service to offer prospects with the merchandise they’re in search of or could also be considering on the proper time.
On this put up, we share how LotteON improved their suggestion service utilizing Amazon SageMaker and machine studying operations (MLOps).
Downside definition
Historically, the advice service was primarily offered by figuring out the connection between merchandise and offering merchandise that have been extremely related to the product chosen by the shopper. Nevertheless, it was essential to improve the advice service to research every buyer’s style and meet their wants. Subsequently, we determined to introduce a deep learning-based suggestion algorithm that may establish not solely linear relationships within the information, but additionally extra complicated relationships. For that reason, we constructed the MLOps structure to handle the created fashions and supply real-time providers.
One other requirement was to construct a steady integration and steady supply (CI/CD) pipeline that may be built-in with GitLab, a code repository utilized by current suggestion platforms, so as to add newly developed suggestion fashions and create a construction that may repeatedly enhance the standard of advice providers via periodic retraining and redistribution of fashions.
Within the following sections, we introduce the MLOps platform that we constructed to offer high-quality suggestions to our prospects and the general technique of inferring a deep learning-based suggestion algorithm (Neural Collaborative Filtering) in actual time and introducing it to LotteON.
Resolution structure
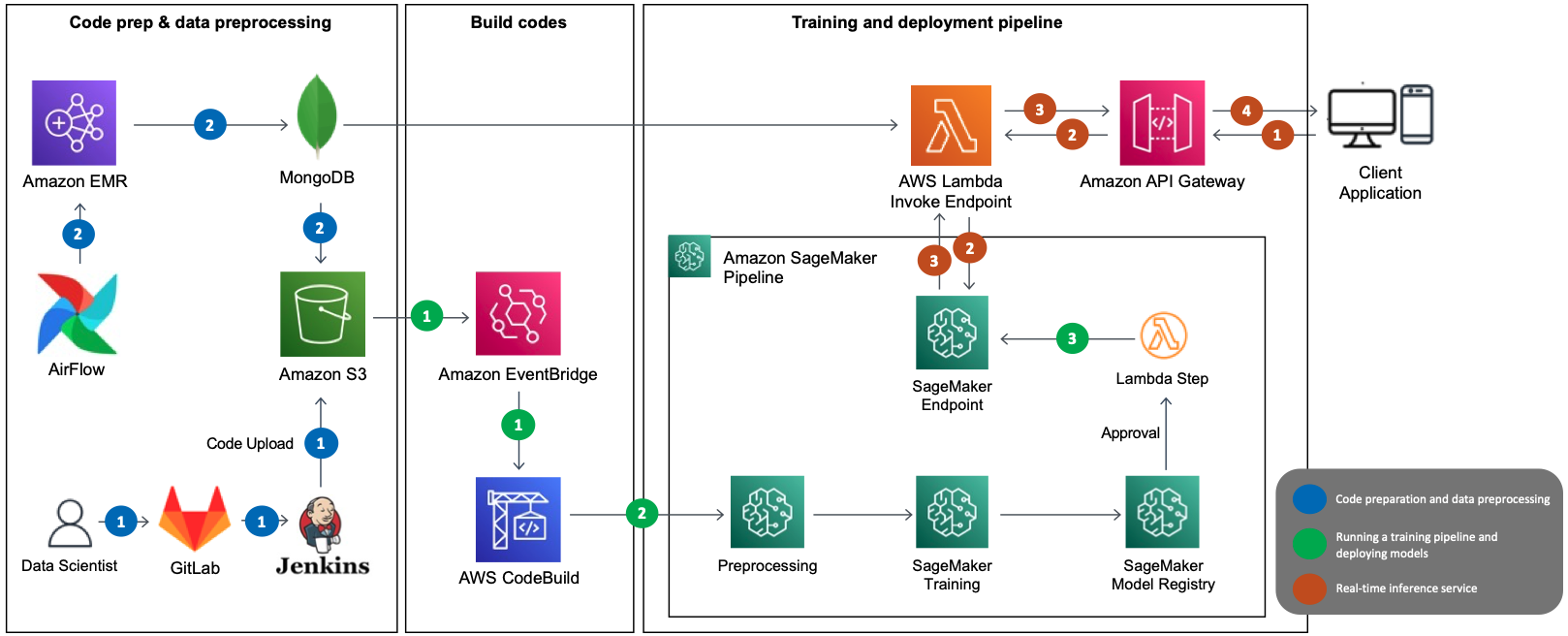
The next diagram illustrates the answer structure for serving Neural Collaborative Filtering (NCF) algorithm-based suggestion fashions as MLOps. The primary AWS providers used are SageMaker, Amazon EMR, AWS CodeBuild, Amazon Easy Storage Service (Amazon S3), Amazon EventBridge, AWS Lambda, and Amazon API Gateway. We’ve mixed a number of AWS providers utilizing Amazon SageMaker Pipelines and designed the structure with the next elements in thoughts:
- Information preprocessing
- Automated mannequin coaching and deployment
- Actual-time inference via mannequin serving
- CI/CD construction
The previous structure exhibits the MLOps information movement, which consists of three decoupled passes:
- Code preparation and information preprocessing (blue)
- Coaching pipeline and mannequin deployment (inexperienced)
- Actual-time suggestion inference (brown)
Code preparation and information preprocessing
The preparation and preprocessing part consists of the next steps:
- The info scientist publishes the deployment code containing the mannequin and the coaching pipeline to GitLab, which is utilized by LotteON, and Jenkins uploads the code to Amazon S3.
- The EMR preprocessing batch runs via Airflow in keeping with the required schedule. The preprocessing information is loaded into MongoDB, which is used as a function retailer together with Amazon S3.
Coaching pipeline and mannequin deployment
The mannequin coaching and deployment part consists of the next steps:
- After the coaching information is uploaded to Amazon S3, CodeBuild runs based mostly on the principles laid out in EventBridge.
- The SageMaker pipeline predefined in CodeBuild runs, and sequentially runs steps resembling preprocessing together with provisioning, mannequin coaching, and mannequin registration.
- When coaching is full (via the Lambda step), the deployed mannequin is up to date to the SageMaker endpoint.
Actual-time suggestion inference
The inference part consists of the next steps:
- The consumer utility makes an inference request to the API gateway.
- The API gateway sends the request to Lambda, which makes an inference request to the mannequin within the SageMaker endpoint to request an inventory of suggestions.
- Lambda receives the checklist of suggestions and supplies them to the API gateway.
- The API gateway supplies the checklist of suggestions to the consumer utility utilizing the Suggestion API.
Suggestion mannequin utilizing NCF
NCF is an algorithm based mostly on a paper offered on the Worldwide World Extensive Internet Convention in 2017. It’s an algorithm that covers the restrictions of linear matrix factorization, which is commonly utilized in current suggestion techniques, with collaborative filtering based on the neural net. By including non-linearity via the neural internet, the authors have been capable of mannequin a extra complicated relationship between customers and objects. The info for NCF is interplay information the place customers react to objects, and the general construction of the mannequin is proven within the following determine (supply: https://arxiv.org/abs/1708.05031).
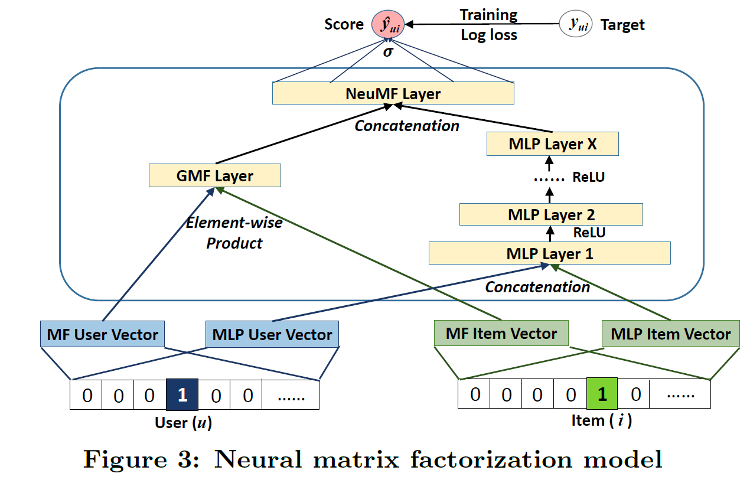
Though NCF has a easy mannequin structure, it has proven efficiency, which is why we selected it to be the prototype for our MLOps platform. For extra details about the mannequin, discuss with the paper Neural Collaborative Filtering.
Within the following sections, we talk about how this resolution helped us construct the aforementioned MLOps elements:
- Information preprocessing
- Automating mannequin coaching and deployment
- Actual-time inference via mannequin serving
- CI/CD construction
MLOps element 1: Information preprocessing
For NCF, we used user-item interplay information, which requires important sources to course of the uncooked information collected on the utility and rework it right into a type appropriate for studying. With Amazon EMR, which supplies totally managed environments like Apache Hadoop and Spark, we have been capable of course of information sooner.
The info preprocessing batches have been created by writing a shell script to run Amazon EMR via AWS Command Line Interface (AWS CLI) instructions, which we registered to Airflow to run at particular intervals. When the preprocessing batch was full, the coaching/take a look at information wanted for coaching was partitioned based mostly on runtime and saved in Amazon S3. The next is an instance of the AWS CLI command to run Amazon EMR:
MLOps element 2: Automated coaching and deployment of fashions
On this part, we talk about the elements of the mannequin coaching and deployment pipeline.
Occasion-based pipeline automation
After the preprocessing batch was full and the coaching/take a look at information was saved in Amazon S3, this occasion invoked CodeBuild and ran the coaching pipeline in SageMaker. Within the course of, the model of the end result file of the preprocessing batch was recorded, enabling dynamic management of the model and administration of the pipeline run historical past. We used EventBridge, Lambda, and CodeBuild to attach the information preprocessing steps run by Amazon EMR and the SageMaker studying pipeline on an event-based foundation.
EventBridge is a serverless service that implements guidelines to obtain occasions and direct them to locations, based mostly on the occasion patterns and locations you determine. The preliminary function of EventBridge in our configuration was to invoke a Lambda perform on the S3 object creation occasion when the preprocessing batch saved the coaching dataset in Amazon S3. The Lambda perform dynamically modified the buildspec.yml file, which is indispensable when CodeBuild runs. These modifications encompassed the trail, model, and partition data of the information that wanted coaching, which is essential for finishing up the coaching pipeline. The next function of EventBridge was to dispatch occasions, instigated by the alteration of the buildspec.yml file, resulting in working CodeBuild.
CodeBuild was liable for constructing the supply code the place the SageMaker pipeline was outlined. All through this course of, it referred to the buildspec.yml file and ran processes resembling cloning the supply code and putting in the libraries wanted to construct from the trail outlined within the file. The Venture Construct tab on the CodeBuild console allowed us to evaluate the construct’s success and failure historical past, together with a real-time log of the SageMaker pipeline’s efficiency.
SageMaker pipeline for coaching
SageMaker Pipelines helps you outline the steps required for ML providers, resembling preprocessing, coaching, and deployment, utilizing the SDK. Every step is visualized inside SageMaker Studio, which could be very useful for managing fashions, and you too can handle the historical past of skilled fashions and endpoints that may serve the fashions. You may also arrange steps by attaching conditional statements to the outcomes of the steps, so you may undertake solely fashions with good retraining outcomes or put together for studying failures. Our pipeline contained the next high-level steps:
- Mannequin coaching
- Mannequin registration
- Mannequin creation
- Mannequin deployment
Every step is visualized within the pipeline in Amazon SageMaker Studio, and you too can see the outcomes or progress of every step in actual time, as proven within the following screenshot.
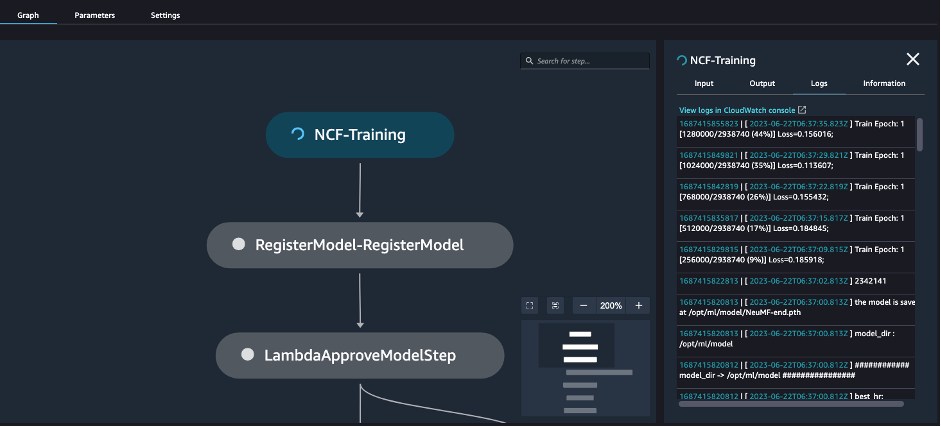
Let’s stroll via the steps from mannequin coaching to deployment, utilizing some code examples.
Prepare the mannequin
First, you outline a PyTorch Estimator to make use of for coaching and a coaching step. This requires you to have the coaching code (for instance, prepare.py) prepared prematurely and go the placement of the code as an argument of the source_dir. The coaching step runs the coaching code you go as an argument of the entry_point. By default, the coaching is completed by launching the container within the occasion you specify, so that you’ll have to go within the path to the coaching Docker picture for the coaching surroundings you’ve developed. Nevertheless, when you specify the framework on your estimator right here, you may go within the model of the framework and Python model to make use of, and it’ll mechanically fetch the version-appropriate container picture from Amazon ECR.
Whenever you’re finished defining your PyTorch Estimator, you’ll want to outline the steps concerned in coaching it. You are able to do this by passing the PyTorch Estimator you outlined earlier as an argument and the placement of the enter information. Whenever you go within the location of the enter information, the SageMaker coaching job will obtain the prepare and take a look at information to a particular path within the container utilizing the format /choose/ml/enter/information/<channel_name> (for instance, /choose/ml/enter/information/prepare).
As well as, when defining a PyTorch Estimator, you should utilize metric definitions to watch the training metrics generated whereas the mannequin is being skilled with Amazon CloudWatch. You may also specify the trail the place the outcomes of the mannequin artifacts after coaching are saved by specifying estimator_output_path, and you should utilize the parameters required for mannequin coaching by specifying model_hyperparameters. See the next code:
Create a mannequin bundle group
The following step is to create a mannequin bundle group to handle your skilled fashions. By registering skilled fashions in mannequin packages, you may handle them by model, as proven within the following screenshot. This data lets you reference earlier variations of your fashions at any time. This course of solely must be finished one time while you first prepare a mannequin, and you’ll proceed so as to add and replace fashions so long as they declare the identical group title.
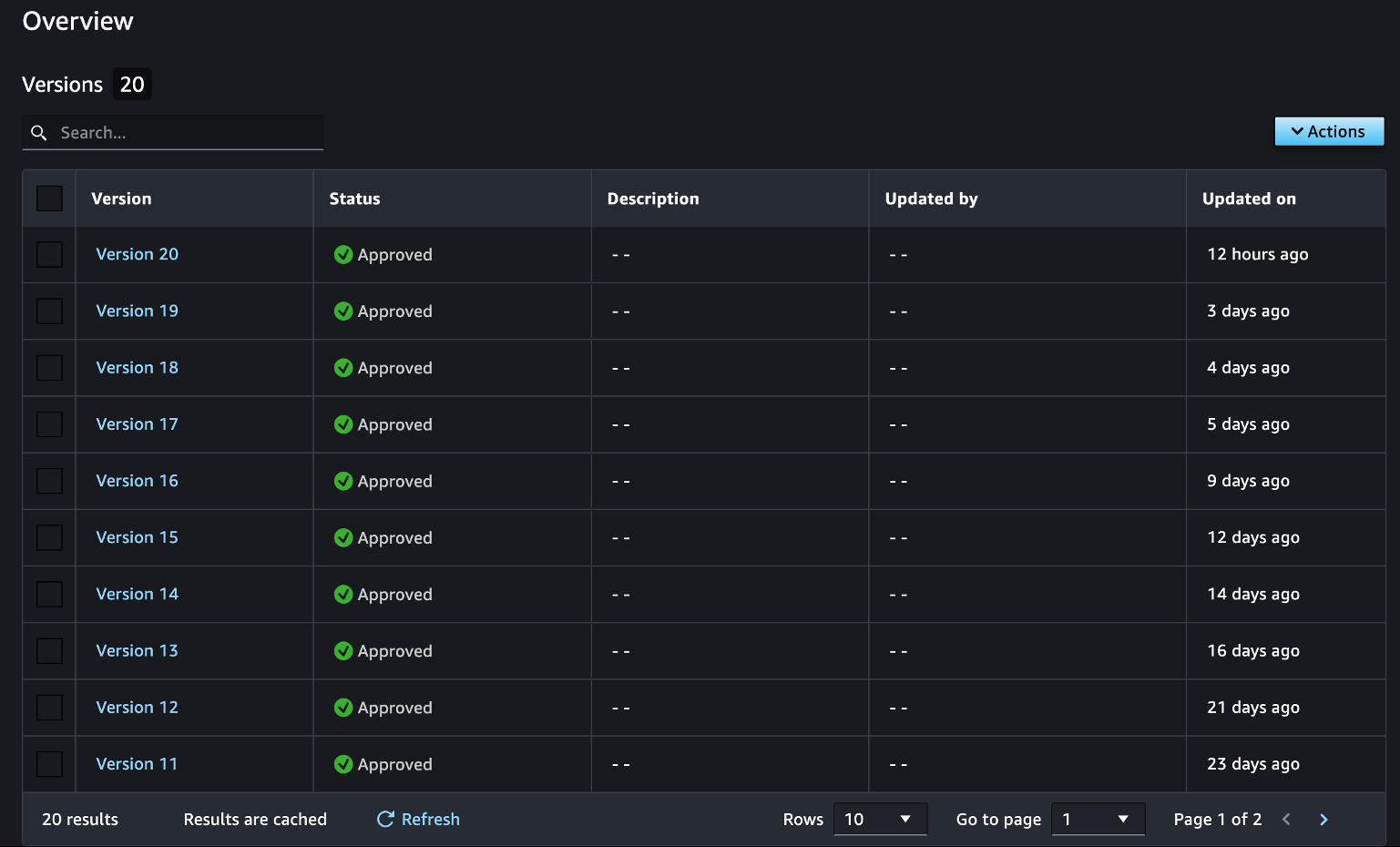
See the next code:
Add a skilled mannequin to a mannequin bundle group
The following step is so as to add a skilled mannequin to the mannequin bundle group you created. Within the following code, while you declare the Mannequin class, you get the results of the earlier mannequin coaching step, which creates a dependency between the steps. A step with a declared dependency can solely be run if the earlier step succeeds. Nevertheless, you should utilize the DependsOn choice to declare a dependency between steps even when the information is just not causally associated.
After the skilled mannequin is registered within the mannequin bundle group, you should utilize this data to handle and observe future mannequin variations, create a real-time SageMaker endpoint, run a batch rework job, and extra.
Create a SageMaker mannequin
To create a real-time endpoint, an endpoint configuration and model is required. To create a mannequin, you want two primary components: an S3 tackle the place the mannequin’s artifacts are saved, and the trail to the inference Docker picture that can run the mannequin’s artifacts.
When making a SageMaker mannequin, you will need to take note of the next steps:
- Present the results of the mannequin coaching step, step_train.properties.ModelArtifacts.S3ModelArtifacts, which might be transformed to the S3 path the place the mannequin artifact is saved, as an argument of the
model_data. - Since you specified the PyTorchModel class,
framework_version, andpy_version, you utilize this data to get the trail to the inference Docker picture via Amazon ECR. That is the inference Docker picture that’s used for mannequin deployment. Make certain to enter the identical PyTorch framework, Python model, and different particulars that you simply used to coach the mannequin. This implies preserving the identical PyTorch and Python variations for coaching and inference. - Present the inference.py because the entry level script to deal with invocations.
This step will set a dependency on the mannequin bundle registration step you outlined through the DependsOn choice.
Create a SageMaker endpoint
Now you’ll want to outline an endpoint configuration based mostly on the created mannequin, which is able to create an endpoint when deployed. As a result of the SageMaker Python SDK doesn’t help the step associated to deployment (as of this writing), you should utilize Lambda to register that step. Cross the required arguments to Lambda, resembling instance_type, and use that data to create the endpoint configuration first. Since you’re calling the endpoint based mostly on endpoint_name, you’ll want to guarantee that variable is outlined with a novel title. Within the following Lambda perform code, based mostly on the endpoint_name, you replace the mannequin if the endpoint exists, and deploy a brand new one if it doesn’t:
To get the Lambda perform right into a step within the SageMaker pipeline, you should utilize the SDK related to the Lambda perform. By passing the placement of the Lambda perform supply as an argument of the perform, you may mechanically register and use the perform. At the side of this, you may outline LambdaStep and go it the required arguments. See the next code:
Create a SageMaker pipeline
Now you may create a pipeline utilizing the steps you outlined. You are able to do this by defining a reputation for the pipeline and passing within the steps for use within the pipeline as arguments. After that, you may run the outlined pipeline via the beginning perform. See the next code:
After this course of is full, an endpoint is created with the skilled mannequin and is prepared to be used based mostly on the deep learning-based mannequin.
MLOps element 3: Actual-time inference with mannequin serving
Now let’s see easy methods to invoke the mannequin in actual time from the created endpoint, which will also be accessed utilizing the SageMaker SDK. The next code is an instance of getting real-time inference values for enter values from an endpoint deployed through the invoke_endpoint perform. The options you go as arguments to the physique are handed as enter to the endpoint, which returns the inference ends in actual time.
After we configured the inference perform, we had it return the objects within the order that the person is almost certainly to love among the many objects handed in. The previous instance returns objects from 1–25 so as of probability of being favored by the person at index 0.
We added enterprise logic to the function, configured it in Lambda, and linked it with an API gateway to implement the API’s capability to return beneficial objects in actual time. We then performed efficiency testing of the web service. We load examined it with Locust utilizing 5 g4dn.2xlarge situations and located that it might be reliably served in an surroundings with 1,000 TPS.
MLOps element 4: CI/CD construction
A CI/CD construction is a elementary a part of DevOps, and can also be an essential a part of organizing an MLOps surroundings. AWS CodeCommit, AWS CodeBuild, AWS CodeDeploy, and AWS CodePipeline collectively present all of the performance you want for CI/CD, from code shaping to deployment, construct, and batch administration. The providers are usually not solely linked to the identical code collection, but additionally to different providers resembling GitHub and Jenkins, so you probably have an current CI/CD construction, you should utilize them individually to fill within the gaps. Subsequently, we expanded our CI/CD construction by linking solely the CodeBuild configuration described earlier to our current CI/CD pipeline.
We linked our SageMaker notebooks with GitLab for code administration, and once we have been finished, we replicated them to Amazon S3 through Jenkins. After that, we set the S3 path to the default repository path of the NCF CodeBuild venture as described earlier, in order that we might construct the venture with CodeBuild.
Conclusion
Thus far, we’ve seen the end-to-end technique of configuring an MLOps surroundings utilizing AWS providers and offering real-time inference providers based mostly on deep studying fashions. By configuring an MLOps surroundings, we’ve created a basis for offering high-quality providers based mostly on numerous algorithms to our prospects. We’ve additionally created an surroundings the place we will shortly proceed with prototype improvement and deployment. The NCF we developed with the prototyping algorithm was additionally capable of obtain good outcomes when it was put into service. Sooner or later, the MLOps platform might help us shortly develop and experiment with fashions that match LotteON information to offer our prospects with a progressively higher-quality suggestion expertise.
Utilizing SageMaker together with numerous AWS providers has given us many benefits in creating and working our providers. As mannequin builders, we didn’t have to fret about configuring the surroundings settings for continuously used packages and deep learning-related frameworks as a result of the surroundings settings have been configured for every library, and we felt that the connectivity and scalability between AWS providers utilizing AWS CLI instructions and associated SDKs have been nice. Moreover, as a service operator, it was good to trace and monitor the providers we have been working as a result of CloudWatch linked the logging and monitoring of every service.
You may also take a look at the NCF and MLOps configuration for hands-on observe on our GitHub repo (Korean).
We hope this put up will allow you to configure your MLOps surroundings and supply real-time providers utilizing AWS providers.
In regards to the Authors
![]() SeungBum Shim is an information engineer within the Lotte E-commerce Suggestion Platform Growth Staff, liable for discovering methods to make use of and enhance recommendation-related merchandise via LotteON information evaluation, and creating MLOps pipelines and ML/DL suggestion fashions.
SeungBum Shim is an information engineer within the Lotte E-commerce Suggestion Platform Growth Staff, liable for discovering methods to make use of and enhance recommendation-related merchandise via LotteON information evaluation, and creating MLOps pipelines and ML/DL suggestion fashions.
 HyeKyung Yang is a analysis engineer within the Lotte E-commerce Suggestion Platform Growth Staff and is answerable for creating ML/DL suggestion fashions by analyzing and using numerous information and creating a dynamic A/B take a look at surroundings.
HyeKyung Yang is a analysis engineer within the Lotte E-commerce Suggestion Platform Growth Staff and is answerable for creating ML/DL suggestion fashions by analyzing and using numerous information and creating a dynamic A/B take a look at surroundings.
 Jieun Lim is an information engineer within the Lotte E-commerce Suggestion Platform Growth Staff and is answerable for working LotteON’s customized suggestion system and creating customized suggestion fashions and dynamic A/B take a look at environments.
Jieun Lim is an information engineer within the Lotte E-commerce Suggestion Platform Growth Staff and is answerable for working LotteON’s customized suggestion system and creating customized suggestion fashions and dynamic A/B take a look at environments.
 Jesam Kim is an AWS Options Architect and helps enterprise prospects undertake and troubleshoot cloud applied sciences and supplies architectural design and technical help to deal with their enterprise wants and challenges, particularly in AIML areas resembling suggestion providers and generative AI.
Jesam Kim is an AWS Options Architect and helps enterprise prospects undertake and troubleshoot cloud applied sciences and supplies architectural design and technical help to deal with their enterprise wants and challenges, particularly in AIML areas resembling suggestion providers and generative AI.
 Gonsoo Moon is an AWS AI/ML Specialist Options Architect and supplies AI/ML technical help. His primary function is to collaborate with prospects to unravel their AI/ML issues based mostly on numerous use circumstances and manufacturing expertise in AI/ML.
Gonsoo Moon is an AWS AI/ML Specialist Options Architect and supplies AI/ML technical help. His primary function is to collaborate with prospects to unravel their AI/ML issues based mostly on numerous use circumstances and manufacturing expertise in AI/ML.

{kind=link}
{kind=link}