


Massive-scale language fashions (LLMs) have demonstrated nice capability in producing human-like textual content, answering questions, and coding. Nevertheless, they face hurdles that require excessive reliability, security, and moral compliance. Reinforcement studying from human suggestions (RLHF), or preference-based reinforcement studying (PbRL), has emerged as a promising answer. This framework has been extremely profitable in fine-tuning his LLM to human preferences and growing its usefulness.
Current RLHF approaches like InstructGPT depend on express or implicit reward fashions such because the Bradley-Terry mannequin. Latest research have investigated direct desire possibilities to raised signify human preferences. Some researchers have formulated RLHF as discovering a Nash equilibrium in a continuing sum recreation and have proposed Miller descent and self-play-first optimization (SPO) strategies. Direct Nash Optimization (DNO) was additionally launched based mostly on win chance hole, however its precise implementation nonetheless depends on the iterative his DPO framework.
Researchers from the College of California, Los Angeles and Carnegie Mellon College have launched Self-Play Desire Optimization (SPPO), a sturdy self-play framework for tuning language fashions to handle the challenges of RLHF. We offer provable ensures for fixing two-player fixed sum video games and scalability for giant language fashions. In formulating RLHF as such a recreation, the aim is to determine a Nash equilibrium coverage that ensures a persistently most well-liked response. They suggest an adaptive algorithm based mostly on multiplicative weights that employs a self-play mechanism through which the coverage fine-tunes itself based mostly on artificial information annotated by a most well-liked mannequin.
The self-play framework goals to unravel two-player constant-sum video games effectively and at scale for giant language fashions. It employs an iterative framework based mostly on multiplicative weight updates and self-play mechanisms. The algorithm asymptotically converges to the optimum coverage and identifies a Nash equilibrium. Theoretical evaluation ensures convergence and gives provable ensures. In contrast with present strategies similar to DPO and IPO, SPPO has improved convergence and effectively addresses the information sparsity downside.
The researchers consider the mannequin utilizing GPT-4 for automated analysis and current outcomes with AlpacaEval 2.0 and MT-Bench. The SPPO mannequin persistently improves via iterations, with SPPO Iter3 exhibiting the very best win price. In contrast with DPO and IPO, SPPO achieves higher efficiency and successfully controls output size. Check time reranking utilizing the PainRM reward mannequin persistently improves mannequin efficiency with out over-optimizing. SPPO outperforms many state-of-the-art chatbots on AlpacaEval 2.0 and stays aggressive along with his GPT-4 on MT-Bench.
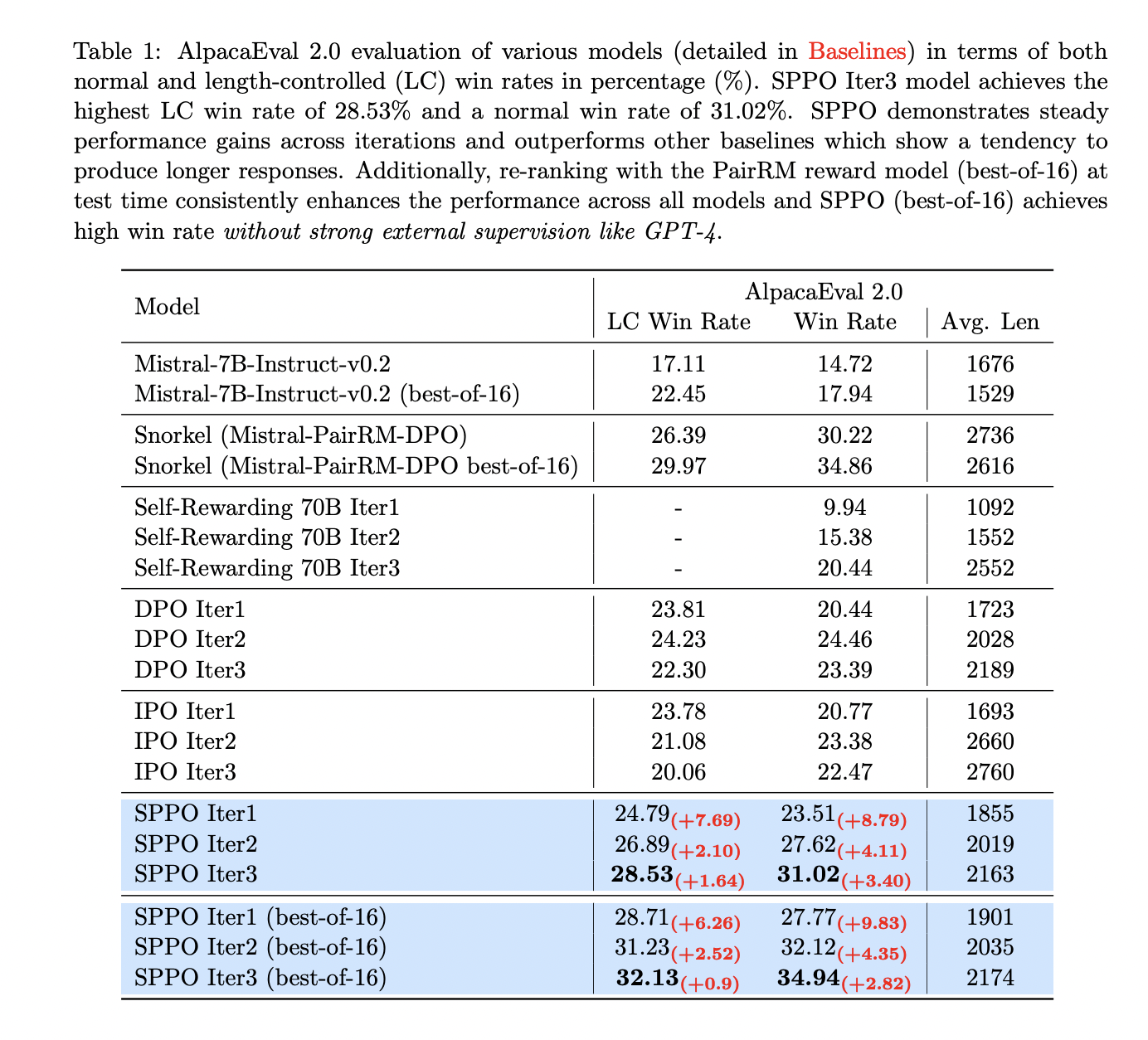
In conclusion, this paper presents Self-Play Desire Optimization (SPPO), a sturdy methodology for fine-tuning LLM utilizing human/AI suggestions. SPPO considerably improves over present strategies similar to His DPO and His IPO throughout quite a lot of benchmarks by using self-play in a two-player recreation and preference-based studying targets. By integrating desire fashions and batch estimation, SPPO carefully aligns LLM with human preferences and addresses points similar to “size bias” reward hacking. These findings counsel the potential of his SPPO to reinforce the coordination of generative AI programs and advocate the widespread adoption of his SPPO in LLM and different fields.
Please examine paper. All credit score for this research goes to the researchers of this venture.Do not forget to observe us twitter.Please be a part of us telegram channel, Discord channeland linkedin groupsHmm.
For those who like what we do, you will love Newsletter..
Do not forget to hitch us 41,000+ ML subreddits
![]()
Asjad is an intern advisor at Marktechpost. He’s pursuing a level in mechanical engineering from the Indian Institute of Know-how, Kharagpur. Asjad is a machine studying and deep studying fanatic and is continually researching the functions of machine studying in healthcare.

{kind=link}