


On this article, you’ll discover ways to construct a textual content clustering pipeline by combining giant language mannequin embeddings with HDBSCAN, a density-based clustering algorithm, to robotically uncover subjects in unlabeled textual content knowledge.
Subjects we are going to cowl embrace:
- Learn how to generate textual content embeddings for uncooked paperwork utilizing a pre-trained sentence-transformers mannequin.
- Learn how to cut back the dimensionality of these embeddings with UMAP to organize them for clustering.
- Learn how to apply HDBSCAN to robotically uncover matter clusters and visualize the outcomes.
Clustering Unstructured Textual content with LLM Embeddings and HDBSCAN
Introduction
The present period of Generative AI appears to primarily concentrate on chat interfaces and prompts, however the vary of purposes of giant language fashions, or LLMs for brief, is just not restricted to simply that. Certainly, one among their strongest downstream skills consists of turning uncooked, messy, unstructured textual content into semantically wealthy mathematical representations known as embeddings. As soon as that’s executed, we will use these textual content representations for quite a lot of machine studying use circumstances, with clustering being no exception.
Particularly, embeddings will be mixed with superior, density-based clustering strategies like HDBSCAN, permitting because of this for the invention of hidden subjects, patterns, or classes in your assortment of textual content paperwork: all with out the necessity for prior labeling.
This text exhibits the right way to assemble a text-based clustering pipeline from scratch. We are going to use a freely accessible dataset containing textual content situations, in addition to an open-source LLM that has been educated for producing embeddings — i.e. a so-called embedding mannequin. The icing on the cake: we’ll use free and helpful, fashionable Python libraries offering implementations of clustering algorithms like HDBSCAN.
Step-by-Step Walkthrough
First, let’s begin by putting in the important thing Python libraries we are going to want:
- Sentence transformers, to load a pre-trained LLM for embedding era from Hugging Face — you’ll want a Hugging Face API key, additionally known as an access token, to have the ability to load the mannequin.
- Umap-learn, to use an algorithm to cut back the dimensionality of embeddings.
Likewise, in case you are engaged on a neighborhood IDE as a substitute of a cloud pocket book atmosphere and don’t have scikit-learn and pandas, you might want to put in them too.
|
!pip set up sentence–transformers umap–be taught |
Now we begin the coding half by getting some contemporary knowledge. The fetch_20newsgroups perform, which fetches a dataset containing texts from categorized information articles, will do. Notice that although the dataset comprises labels, we are going to omit them, as we’re pretending to not know this data for the sake of clustering these knowledge situations into teams primarily based on similarity. Additionally, we pattern down the dataset to 150 situations, which shall be consultant sufficient for our instance.
|
import pandas as pd from sklearn.datasets import fetch_20newsgroups
# Fetching a extremely focused subset of knowledge (~150-200 docs) classes = [‘sci.space’, ‘sci.med’, ‘rec.autos’] newsgroups = fetch_20newsgroups(subset=‘prepare’, classes=classes, take away=(‘headers’, ‘footers’, ‘quotes’))
# Sampling down right into a consultant, illustrative subset df = pd.DataFrame({‘textual content’: newsgroups.knowledge, ‘true_label’: newsgroups.goal}) df = df[df[‘text’].str.strip().str.len() > 100].pattern(150, random_state=42).reset_index(drop=True)
print(f“Loaded {len(df)} textual content paperwork.”) print(“nSample doc:”) print(df[‘text’].iloc[0][:150] + “…”) |
Output:
|
Loaded 150 textual content paperwork.
Pattern doc:
Okay Mr. Dyer, we‘re correctly impressed along with your philosophical expertise and capability to insult individuals. You’re a great speaker and an adept politic... |
The following step is to acquire the embeddings from uncooked texts. To do that, we load all-MiniLM-L6-v2 from Hugging Face’s sentence-transformers library. This can be a light-weight but efficient mannequin to acquire embeddings rapidly.
|
from sentence_transformers import SentenceTransformer
# Loading the free, open-source mannequin mannequin = SentenceTransformer(‘all-MiniLM-L6-v2’)
# Encoding textual content paperwork into dense vector embeddings print(“Producing embeddings…”) embeddings = mannequin.encode(df[‘text’].tolist(), show_progress_bar=True)
print(f“Embedding matrix form: {embeddings.form}”) |
For the reason that embedding dimension is initially too excessive for clustering functions, we now apply a dimensionality discount method through the use of the UMAP algorithm from the namesake library put in earlier:
|
import umap
# Lowering embedding dimensions to five, to retain sufficient density data for clustering reducer = umap.UMAP(n_neighbors=15, n_components=5, min_dist=0.0, random_state=42) reduced_embeddings = reducer.fit_transform(embeddings)
print(f“Decreased matrix form: {reduced_embeddings.form}”) |
Now our numerical embedding vectors related to information articles consist of 5 dimensions (attributes) solely. Let’s see if this compact illustration is significant sufficient to acquire insightful clustering by making use of the HDBSCAN algorithm, which is a density-based clustering method:
|
from sklearn.cluster import HDBSCAN
# Initializing HDBSCAN # min_cluster_size=8: we specified that every cluster should have no less than 8 paperwork clusterer = HDBSCAN(min_cluster_size=8, min_samples=3, store_centers=‘centroid’) df[‘cluster’] = clusterer.fit_predict(reduced_embeddings)
# Counting situations per cluster cluster_counts = df[‘cluster’].value_counts() print(“nCluster Distribution:”) print(cluster_counts) |
Vital: the clustering outcomes are partly influenced by the hyperparameter settings we outlined for HDBSCAN. I like to recommend you check out different configurations for the minimal cluster measurement and different hyperparameters to discover how this impacts outcomes.
End result:
|
Cluster Distribution: cluster 0 101 1 49 Title: depend, dtype: int64 |
It appears like HDBSCAN detected two clusters related to high-density areas within the knowledge area. Would there even be noisy factors that weren’t allotted to both of those two clusters? Let’s test:
|
for cluster_id in sorted(df[‘cluster’].distinctive()): if cluster_id == –1: print(“n=== CLUSTER: NOISE / UNCLASSIFIED ===”) else: print(f“n=== CLUSTER: Found Matter #{cluster_id} ===”)
# Getting as much as 3 pattern texts from this cluster samples = df[df[‘cluster’] == cluster_id][‘text’].head(3).tolist() for i, pattern in enumerate(samples, 1): clean_sample = ” “.be a part of(pattern.break up())[:120] print(f” {i}. {clean_sample}…”) |
Output:
|
=== CLUSTER: Found Matter #0 === 1. Okay Mr. Dyer, we‘re correctly impressed along with your philosophical expertise and skill to insult individuals. You’re a great ... 2. I was at an fascinating seminar at work (UK‘s R.A.L. Area Science Dept.) on this topic, particularly on a small-scale… 3. That is the second submit which appears to be blurring the excellence between actual illness brought on by Candida albicans and t…
=== CLUSTER: Found Matter #1 === 1. It’s nice that all these different automobiles can out–deal with, out–nook, and out– speed up an Integra. However, you‘ve received to ask ... 2. l diamond star automobiles (Talon/Eclipse/Laser) put out 190 hp in the turbo fashions, and 195 hp in the AWD turbo fashions, These ... 3. Sorry for the mis–spelling, however I forgot how to spell it after my collection of exams and NO–on hand reference right here. Is it s... |
Looks as if all knowledge factors within the pattern of 150 had been allotted to both one of many two clusters recognized, thus hinting on the clue that the information articles would possibly simply separable in line with matter.
For additional perception, we will present some cluster visualizations with assistance from the supplementary code supplied under, which exhibits a scatterplot for each pairwise mixture of the 5 present parts that describe every knowledge level:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import matplotlib.pyplot as plt import seaborn as sns import itertools
# Making a DataFrame for the 5 diminished embeddings and cluster labels reduced_df = pd.DataFrame(reduced_embeddings, columns=[f‘UMAP_D{i+1}’ for i in range(reduced_embeddings.shape[1])]) reduced_df[‘cluster’] = df[‘cluster’]
# Getting all distinctive pairwise combos of the 5 dimensions dim_pairs = record(itertools.combos(reduced_df.columns[:–1], 2))
num_plots = len(dim_pairs) num_cols = 3 num_rows = (num_plots + num_cols – 1) // num_cols
plt.determine(figsize=(num_cols * 5, num_rows * 4))
for i, (dim1, dim2) in enumerate(dim_pairs): plt.subplot(num_rows, num_cols, i + 1) sns.scatterplot( x=dim1, y=dim2, hue=‘cluster’, knowledge=reduced_df, palette=‘viridis’, s=70, alpha=0.7, legend=‘full’ ) plt.title(f‘{dim1} vs {dim2}’) plt.xlabel(dim1) plt.ylabel(dim2) plt.grid(True, linestyle=‘–‘, alpha=0.6)
plt.tight_layout() plt.present() |
End result:
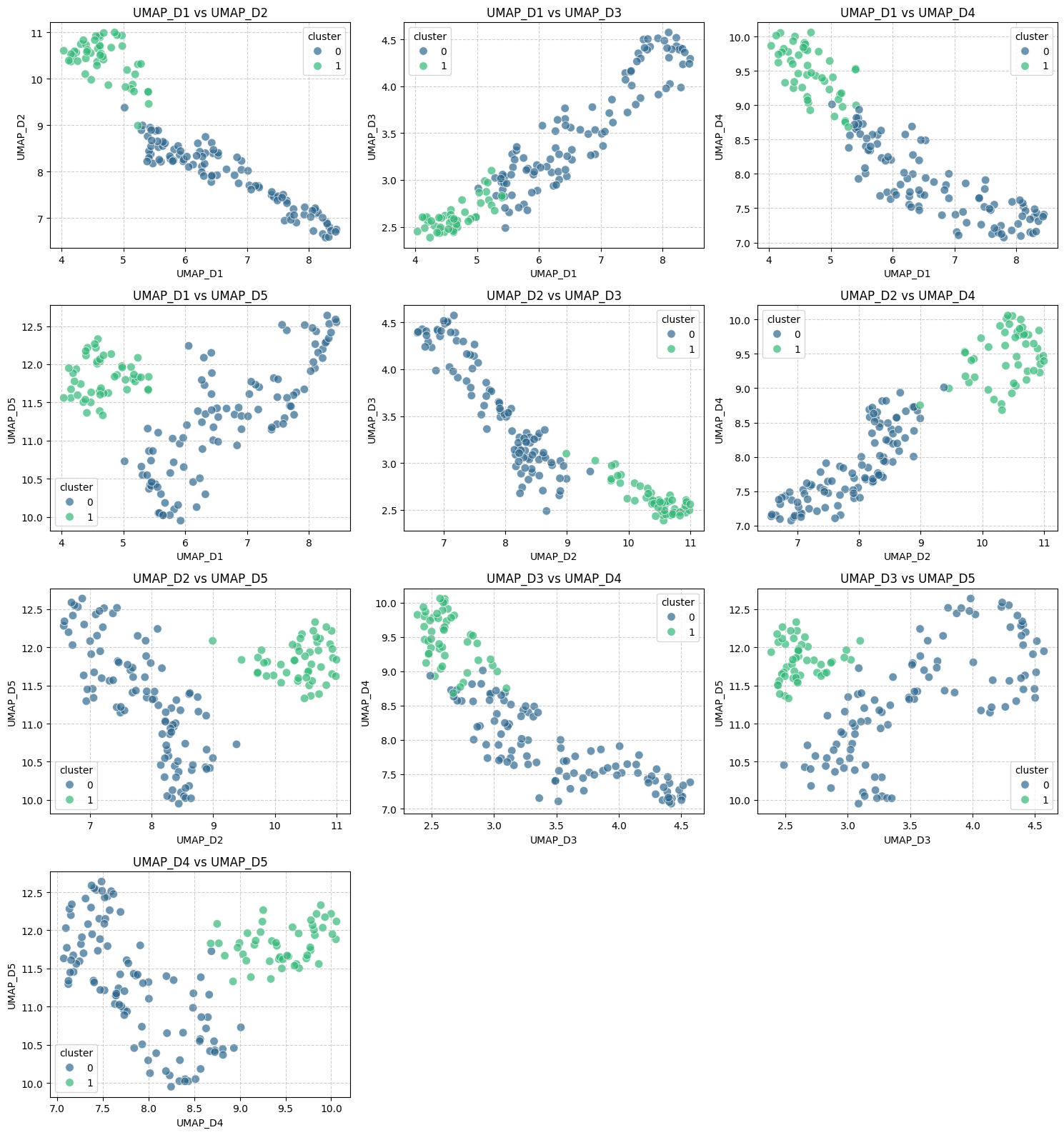
By making an attempt completely different configurations for HDBSCAN, you might come throughout outcomes by which the variety of recognized clusters could possibly be completely different from two. Simply give it a strive!
Wrapping Up
As soon as we’ve gone by way of the method of constructing the text-based clustering pipeline, it’s price concluding by stating the important thing the explanation why placing collectively LLM embeddings with HDBSCAN is price it. These embrace the flexibility to retain and seize, to some extent, the true semantic which means and linguistic nuances of the unique textual content, because of the properties inherent to embeddings obtained by way of sentence-transformers. Furthermore, HDBSCAN robotically determines an optimum variety of clusters and is ready to detect outlying factors that is perhaps noise or outliers that might distort group-level statistics.

{kind=link}