


In case your doc repository accommodates tons of of hundreds of thousands of recordsdata amassed over practically a decade, how will you systematically discover and edit delicate buyer knowledge with out spending years?This was the problem we confronted. huntington national bank (Huntington), a high 10 financial institution in the US.
Edit delicate data at scale
Since 2015, Huntington doc administration techniques have safely saved tons of of hundreds of thousands of paperwork on-premises. In 2025, as a part of its proactive compliance efforts, Huntington started processing paperwork and redacting delicate knowledge inside this technique. These paperwork are available in quite a lot of codecs, so the answer wanted to be versatile sufficient to deal with quite a lot of file sorts whereas offering the throughput wanted to quickly course of hundreds of thousands of paperwork.
Preliminary estimates indicated the hassle would take years. Nevertheless, by designing a scalable modifying workflow utilizing Amazon Textract, Amazon SageMaker, AWS Step Capabilities, and AWS Lambda, Huntington lowered this timeline to a couple months.
Answer overview
Earlier than wanting on the technical implementation, let’s check out the core necessities that Huntington established for this challenge. If you’re dealing with related large-scale doc processing challenges, you should use the next necessities as a place to begin for designing your personal answer.
- Information have to be encrypted at relaxation and in transit.
- The place knowledge is saved or accessed should meet strict entry necessities.
- Companies used have to be inside PCI DSS compliance.
- The output have to be replicated again to an on-premises knowledge retailer.
- Redaction accuracy have to be at the very least 95% to satisfy compliance necessities.
The next diagram reveals the high-level answer structure.
Transfer your knowledge securely and with confidence
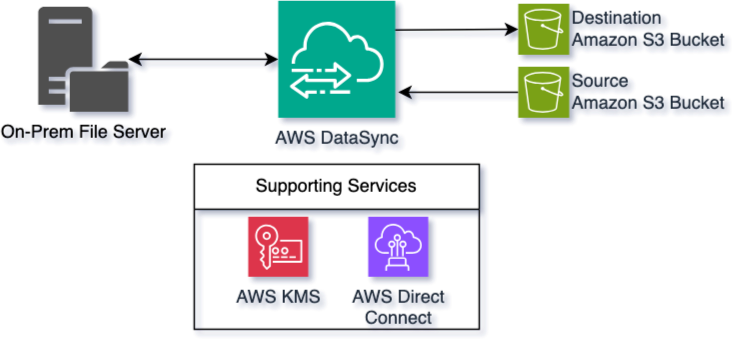
Huntington’s first purpose was to maneuver paperwork from an on-premises file share to an Amazon Easy Storage Service (Amazon S3) bucket. Shifting paperwork is straightforward, however this activity required over 400 million paperwork to be encrypted in transit and at relaxation. To perform this, Huntington used AWS DataSync, AWS Direct Join, Amazon S3, and AWS Key Administration Service (AWS KMS).
You possibly can deploy AWS DataSync as an agent in your on-premises datacenter to watch configured sources equivalent to SMB file shares. Getting paperwork into AWS was essential for processing, however AWS DataSync additionally helps synchronizing knowledge to on-premises. This was one other essential requirement for this challenge.
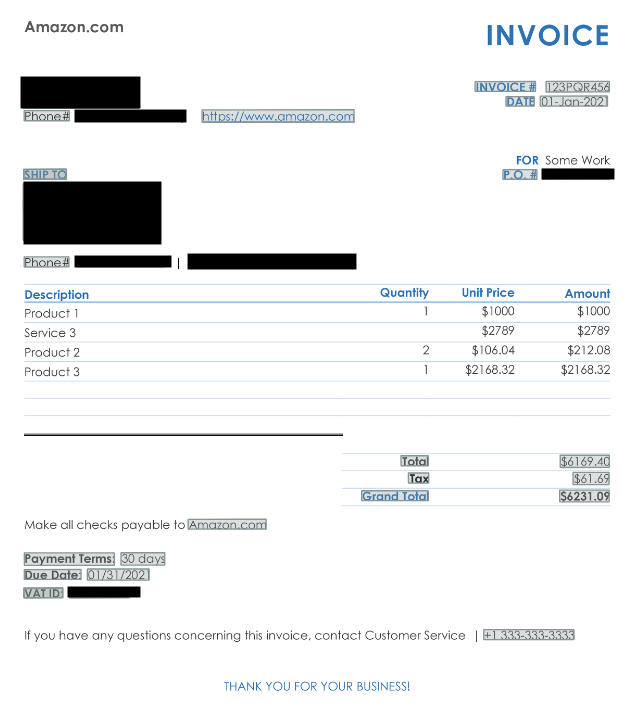
Amazon Textract is an AWS machine studying service that extracts textual content, tables, and types from scanned paperwork. Monetary establishments use it to robotically course of paperwork equivalent to account statements and mortgage purposes to determine delicate knowledge equivalent to social safety numbers, account numbers, and private addresses. The next pattern bill demonstrates this performance.

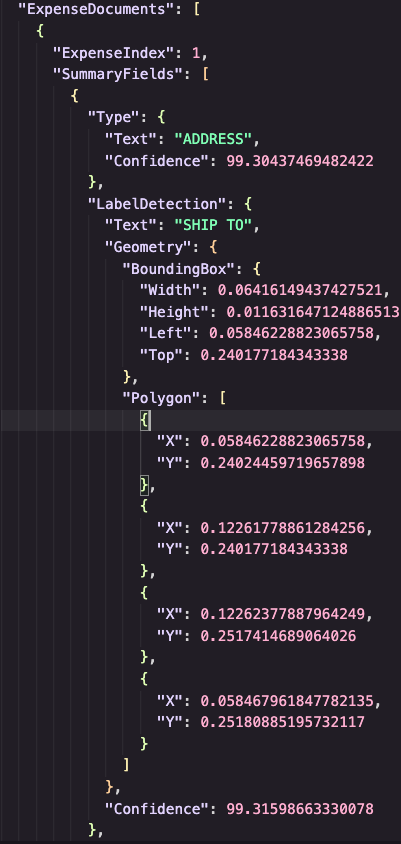
Amazon Textract detects numerous fields out of your doc and offers the coordinates of the detected fields and different metadata within the JSON output.
Huntington used Amazon Textract in an orchestrated course of utilizing AWS Step Capabilities. This method lowered guide assessment time and improved the accuracy of detecting delicate data throughout massive volumes of paperwork.
Scaling detection throughput
Automated pipelines for doc processing are helpful, however processing paperwork sequentially can prolong challenge timelines by a number of years. To fulfill its targets, Huntington wanted to course of hundreds of thousands of paperwork daily.
To scale to this stage, we would have liked to deal with two most important issues: maximizing concurrent Amazon Textract jobs inside our service quotas and controlling request charges to keep away from throttling.
AWS companies have quotas that may be adjusted by means of tender and arduous limits. You possibly can enhance your Amazon Textract jobs per second quota by submitting a request from the AWS Service Quotas console.
To maximise throughput towards service quotas, Huntington used AWS Step Capabilities’ built-in map state. It processes a set of enter in JSON, CSV, or different codecs. The workforce organized paperwork in Amazon S3 into JSON collections and ran map states in distributed mode to extend concurrency. To trace pipeline progress, we used AWS Step Capabilities map execution summaries in parallel with the Amazon CloudWatch dashboard to watch response occasions, throttle counts, success, and error charges.
To deal with potential throttling, Huntington monitored the CloudWatch dashboard to see what number of Amazon Textract requests have been profitable and what number of have been throttled. Adjusted concurrency limits for little one workflow runs as wanted to make sure excessive throughput and staying inside Amazon Textract service quotas. As soon as the job completes efficiently, the found fields and metadata are written to your bucket for later assessment. The next diagram illustrates this method.
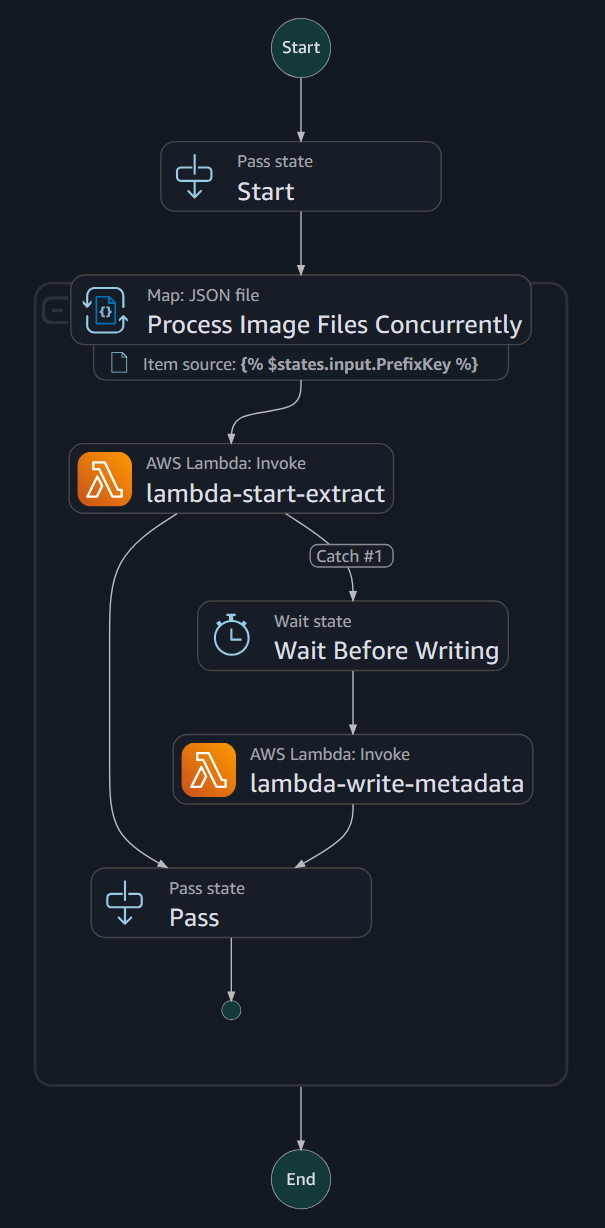
A wait block inside the step operate ensures that the method is able to proceed writing job metadata and proceed with the following Amazon Textract name. If there are not any failures, the state machine exits in a passing state. When a failure happens, AWS Step Capabilities writes to logs for human assessment and reprocessing.
Edit detected delicate data
The method up so far has centered on discovering delicate knowledge and cataloging it in metadata recordsdata written to Amazon S3. The ultimate step is to edit the doc and ship it again to on-premises storage.
Picture and PDF modifying is supported by a number of open supply and proprietary instruments. Common open supply Python libraries embody picture drawing libraries equivalent to PyMuPDF and PIL. The next picture reveals the bill modifying pattern proven earlier. Amazon Textract helps detection of assorted fields, and you too can create customized classifications utilizing common expression patterns. When mixed with redaction software program, detected fields might be reliably redacted. When creating thresholds for human intervention, Amazon Textract offers a confidence rating that may set off a validation workflow.
Huntington once more confronted the identical architectural problem. The query is tips on how to broaden this. AWS Step Capabilities offered an answer for processing hundreds of thousands of paperwork whereas offering hooks for error dealing with and retry logic. As soon as the doc processing pipeline cataloged objects that wanted modifying, Huntington ran a easy circulate on them.
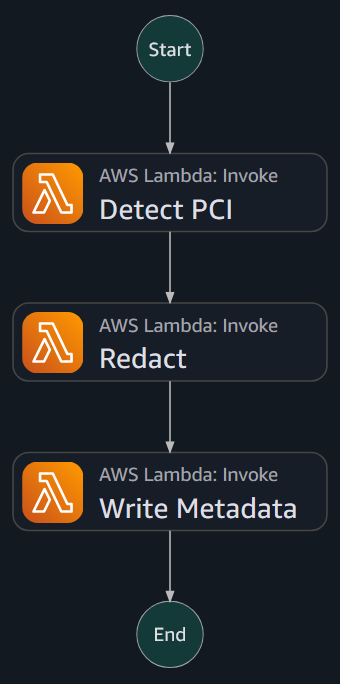
To confirm accuracy and thoroughness, Huntington double-checked that the detected fields matched anticipated patterns earlier than modifying, after which up to date every file’s metadata. The edited recordsdata have been positioned in an Amazon S3 location monitored by AWS DataSync for sending to on-premises file storage.
conclusion
Huntington makes use of AWS to course of paperwork at a fee of roughly 10 million paperwork per day, decreasing estimated processing occasions from years to simply months. Processing prices for your complete doc repository have been roughly 5% of the unique estimate. Redemption accuracy was over 95%, assembly compliance necessities and supporting knowledge safety aims.
This challenge reveals how AWS companies can assist large-scale knowledge processing and compliance efforts. Huntington plans to proceed utilizing the framework for large-scale editorial wants equivalent to mergers and acquisitions.
For extra details about the companies used on this answer, go to the Amazon Textract particulars web page or see the AWS Step Capabilities documentation.
Acknowledgment
Particular due to the next people and groups for his or her contributions: Xuelei Yuan, Robert Carnell, Jeanne Keith, Debbie Montgomery, Invoice Gross, Jodi Pettiford, Jon Glazer, Marshall Doss, Bob Wojasinski, Tami Wolf, Marijane Eldridge, Pradeep Kumar Tata, Michael Burkhardt, Nirmal Antony, Trevor Pease, Bryan Griffith, Angus Ferguson (AWS) Randy Patrick (AWS), Stephanie Brenneman (AWS), Artwork Steele, Kevin Owen.
In regards to the writer

{kind=link}