


Coaching giant language fashions requires correct suggestions alerts, however conventional reinforcement studying (RL) usually struggles with reward sign reliability. The standard of those alerts instantly influences how fashions be taught and make choices. Nonetheless, creating sturdy suggestions mechanisms will be advanced and error inclined. Actual-world coaching eventualities usually introduce hidden biases, unintended incentives, and ambiguous success standards that may derail the educational course of, resulting in fashions that behave unpredictably or fail to fulfill desired aims.
On this put up, you’ll discover ways to implement reinforcement studying with verifiable rewards (RLVR) to introduce verification and transparency into reward alerts to enhance coaching efficiency. This method works finest when outputs will be objectively verified for correctness, corresponding to in mathematical reasoning, code technology, or symbolic manipulation duties. Additionally, you will discover ways to layer methods like Group Relative Coverage Optimization (GRPO) and few-shot examples to additional enhance outcomes. You’ll use the GSM8K dataset (Grade College Math 8K: a group of grade college math issues) to enhance math drawback fixing accuracy, however the methods used right here will be tailored to all kinds of different use circumstances.
Technical overview
Earlier than diving into implementation, it’s useful to grasp the RL ideas that underpin this method. RL addresses challenges in mannequin coaching by establishing a structured suggestions system by reward alerts. This paradigm permits fashions to be taught by interplay, receiving suggestions that guides them towards optimum conduct. RL gives a framework for fashions to iteratively enhance their responses primarily based on clearly outlined alerts concerning the high quality of their outputs, making it extremely efficient for coaching fashions that work together with customers and should adapt their conduct primarily based on outcomes. Conventional RL has highlighted an necessary consideration: the standard of the reward sign issues considerably. When reward capabilities are imprecise or incomplete, fashions can have interaction in “reward hacking,” discovering unintended methods to maximise scores with out reaching the specified conduct. Recognizing this limitation has led to the event of extra rigorous approaches that target creating dependable, well-defined reward capabilities.
RLVR addresses reward hacking by rule-based suggestions outlined by the mannequin tuner. It makes use of programmatic reward capabilities that mechanically rating outputs towards particular standards, enabling fast iteration with out the bottleneck of amassing human scores. These “verifiable” rewards come from goal, reproducible guidelines, making RLVR perfect for evolving necessities as a result of it learns normal optimization methods and adapts shortly to new eventualities. GRPO is a reinforcement studying algorithm that improves AI mannequin studying by evaluating efficiency inside teams somewhat than throughout all information without delay. It organizes coaching information into significant teams and optimizes efficiency relative to every group’s baseline, giving acceptable consideration to every class. This group-aware optimization reduces coaching variance, accelerates convergence, and may produce fashions that carry out persistently throughout numerous classes. Combining RLVR with GRPO creates a framework the place automated rewards information studying whereas group-relative optimization helps drive balanced efficiency.
You outline reward capabilities for various process points, and GRPO treats these as distinct teams throughout coaching, facilitating simultaneous enchancment throughout dimensions. This mix delivers fast adaptation and sturdy efficiency, perfect for dynamic environments requiring generalization past coaching distribution. Including few-shot studying enhances this framework in 3 ways. First, few-shot examples present templates that present the mannequin what good outputs seem like, narrowing the search area for exploration. Second, GRPO leverages these examples by producing a number of candidate responses per immediate and studying from their relative efficiency inside every group. Third, verifiable rewards instantly affirm which approaches succeed. This mix accelerates studying: the mannequin begins with concrete examples of the specified format, explores variations effectively by group-based comparability, and receives definitive suggestions on correctness.
Resolution overview
On this part, you’ll stroll by the right way to fine-tune a Qwen2.5-0.5B mannequin on SageMaker AI utilizing Amazon Amazon SageMaker Coaching Jobs. Amazon SageMaker Coaching jobs help distributed multi-GPU and multi-node configurations, so you may spin up high-performance clusters on demand, prepare billion-parameter fashions sooner, and mechanically shut down assets when the job finishes.
Observe: Whereas Qwen2.5-0.5B was chosen for this use case, others like code technology would require a bigger mannequin (e.g. Qwen2.5-Coder-7B) and subsequently bigger coaching situations.
Conditions
To run the instance from this put up on Amazon SageMaker AI, you will need to fulfill the next stipulations:
Setting arrange
You should use your most well-liked IDE, corresponding to VS Code or PyCharm, however be sure that your native setting is configured to work with AWS, as mentioned within the stipulations.
To make use of SageMaker Studio JupyterLab areas full the next steps:
- On the Amazon SageMaker AI console, select Domains within the navigation pane, then open your area.
- Within the navigation pane below Functions and IDEs, select Studio.
- On the Person profiles tab, find your person profile, then select Launch and Studio.
- In Amazon SageMaker Studio, launch an
ml.t3.mediumJupyterLab pocket book occasion with at the least 50 GB of storage.
A big pocket book occasion isn’t required, as a result of the fine-tuning job will run on a separate ephemeral coaching occasion with GPU acceleration.
- To start fine-tuning, begin by cloning the GitHub repo and navigating to
3_distributed_training/reinforcement-learning/grpo-with-verifiable-rewardlisting, then launch the model-finetuning-grpo-rlvr.ipynb - Pocket book with a Python 3.12 or increased model kernel
Put together the dataset for fine-tuning
Working GRPO with RLVR requires you to have the ultimate reply to every query to calculate reward. First, put together the info by extracting the ultimate reply for every query.
As well as, this instance makes use of few-shot examples (8 pictures) to enhance mannequin coaching efficiency. For extra info on few-shot examples in reinforcement studying, consult with the paper “Reinforcement Learning for Reasoning in Large Language Models with One Training Example”. Whereas the analysis paper focuses on single-shot examples, this put up will present you each single and multi-shot efficiency.
Every enter will include 8 examples, adopted by the issue to be solved:
After the info has been ready, maintain 10 % of the info as a validation set and push each coaching and validation set to S3.
The Verifiable Reward Perform
This GRPO implementation for mathematical reasoning employs a dual-reward system that gives goal, verifiable suggestions throughout coaching. This method leverages the inherent verifiability of mathematical issues to create dependable coaching alerts with out requiring human annotation or subjective analysis.You’ll implement two complementary reward capabilities that work collectively to information the mannequin towards each right response formatting and mathematical accuracy of the consequence:
Format Reward Perform
This operate helps confirm the mannequin learns to construction its responses appropriately by:
- Sample Matching: Searches for the precise format
#### The ultimate reply is [number] - Constant Scoring: Awards 0.5 factors for correct formatting, 0.0 for incorrect format
- Coaching Sign: Encourages the mannequin to observe the anticipated reply construction
Correctness Reward Perform
This operate gives the core mathematical verification by:
- Reply Extraction: Makes use of regex to extract numerical solutions from formatted responses
- Normalization: Removes frequent formatting characters (commas, forex symbols, items)
- Precision Comparability: Makes use of a tolerance of 1e-3 to deal with floating-point precision
- Binary Scoring: Awards 1.0 for proper solutions, 0.0 for incorrect ones
Integrating RLVR with GRPO
The reward capabilities are built-in into the GRPO coaching pipeline by the GRPOTrainer:
Throughout coaching, GRPO makes use of these reward capabilities to compute coverage gradients. First the mannequin generates a number of completions for every mathematical drawback. Subsequent, the reward for every response is computed for each reward capabilities. The format reward operate will grant as much as 0.5 for correct response construction, and the correctness reward operate will grant as much as 1.0 for the mathematical accuracy of the reply for a most mixed reward of 1.5 per completion. Then GRPO compares the completions inside teams to establish the very best responses. Lastly, within the coverage replace step, the loss operate makes use of reward variations to replace mannequin parameters. Greater-rewarded completions enhance their chance, whereas lower-rewarded completions lower their chance. This relative rating drives the optimization course of.The next instance demonstrates the right way to fine-tune Qwen2.5-0.5B. The recipe is supplied within the scripts folder, permitting you to customise it or change the bottom mannequin. Right here you’ll use GRPO with verifiable rewards utilizing Quantized Low-Rank Adaptation (QLoRA). QLoRA is used right here as a way to cut back coaching useful resource necessities and pace up the coaching course of, with a small commerce off in accuracy.
Recipe overview
This recipe implements Group Relative Coverage Optimization (GRPO) with verifiable rewards for fine-tuning the Qwen2.5-0.5B mannequin on mathematical reasoning duties. The recipe makes use of a dual-reward system that objectively evaluates each reply formatting and mathematical correctness with out requiring human annotation.
Vital Hyperparameters:
learning_rate: 1.84e-4 – Studying charge optimized for GRPO coachingnum_train_epochs: 2 – Coaching epochs to keep away from overfittingper_device_train_batch_size: 16 with gradient_accumulation_steps: 2 – Efficient batch measurement of 32max_seq_length: 2048 – Context window for 8-shot promptinglora_r: 16 andlora_alpha: 16 – LoRA rank and scaling parameterswarmup_ratio: 0.1 with cosine scheduler – Studying charge schedulinglora_target_modules– Targets consideration and MLP layers for adaptation
As a subsequent step, you’ll use a SageMaker AI coaching job to spin up a coaching cluster and run the mannequin fine-tuning. The SageMaker AI Model Trainer. ModelTrainer runs coaching jobs on totally managed infrastructure; dealing with setting setup, scaling, and artifact administration. It additionally lets you specify coaching scripts, enter information, and compute assets with out manually provisioning servers. Library dependencies will be managed by the necessities.txt file in scripts folder. ModelTrainer will mechanically detect this file and set up the listed dependencies at runtime.
First, arrange your setting. Right here you’ll specify the occasion sort and variety of situations for coaching and the situation of the coaching container.
Subsequent, configure the setting variables, code areas, and information paths:
Arrange the channels for coaching and validation information:
Then start coaching:model_trainer.prepare(input_data_config=information)The next is the listing construction for supply code of this instance:
To fine-tune throughout a number of GPUs, the instance coaching script makes use of Huggingface Speed up and DeepSpeed ZeRO-3, which work collectively to coach giant fashions extra effectively. Huggingface Speed up simplifies launching distributed coaching by mechanically dealing with gadget placement, course of administration, and combined precision settings. DeepSpeed ZeRO-3 reduces reminiscence utilization by partitioning optimizer states, gradients, and parameters throughout GPUs—permitting billion-parameter fashions to suit and prepare sooner.You possibly can run your GRPO coach script with Huggingface Speed up utilizing a easy command like the next:
Outcomes
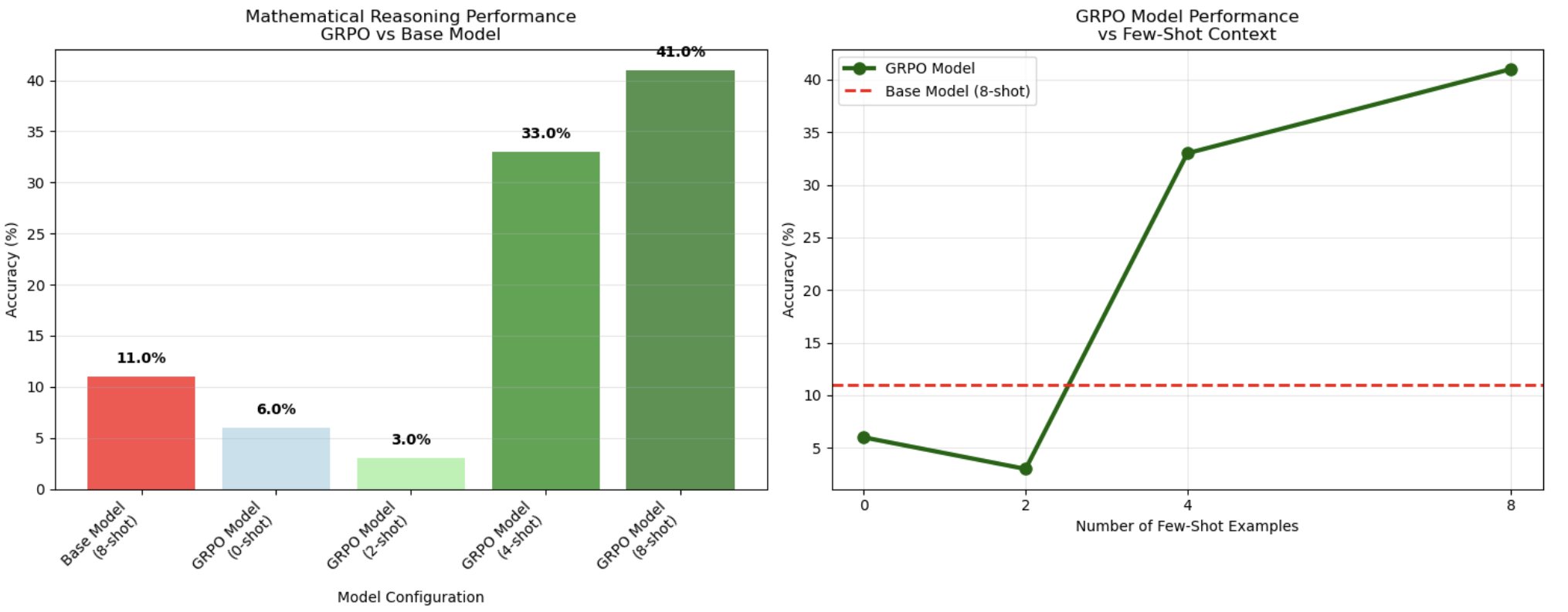
After evaluating the fashions on 100 take a look at samples, the 8-shot GRPO-trained mannequin achieved 41% accuracy in comparison with the bottom mannequin’s 11%, demonstrating a 3.7x enchancment in chain-of-thought mathematical reasoning.

The next chart exhibits a definite threshold associated to context size, revealing an optimum vary of samples for reasoning activation. Whereas 0-shot (6%) and 2-shot (3%) configurations carried out poorly – even worse than the bottom mannequin – efficiency dramatically improved at 4-shot prompting (33%), then peaked at 8-shot context (41%). This non-linear scaling sample means that GRPO coaching creates reasoning patterns that require a sure variety of examples to activate successfully. The mannequin seems to have realized to leverage group comparisons from a number of examples, in line with GRPO’s group-based coverage optimization method the place the mannequin learns to match and choose optimum reasoning paths from a number of generated options.
Extending RLVR to different domains
Whereas this put up targeted on mathematical reasoning with GSM8K, the RLVR method generalizes to domains with objectively verifiable outputs. Two promising instructions show this versatility:
Code technology with execution-based rewards
Code technology gives pure verification by execution. Partial rewards will be awarded when code compiles and runs with out errors, whereas full rewards are achieved when outputs move complete unit checks. Area specialists specify necessities utilizing pure language prompts, whereas the reward mannequin mechanically evaluates correctness by code execution—assuaging subjective human analysis.
Area-specific textual content technology with semantic validation
For specialised domains like medical or technical writing, keyword-based rewards can information fashions towards acceptable terminology. Partial rewards encourage inclusion of required phrases, whereas full rewards require full key phrase units in semantically acceptable contexts. For example, medical textual content technology can reward outputs that mix diagnostic key phrases (“signs,” “analysis”) with remedy key phrases (“remedy,” “remedy”) in clinically legitimate patterns, educating area vocabulary by measurable targets. These examples illustrate how verifiable rewards prolong past mathematical reasoning to duties the place correctness will be programmatically validated, establishing the muse for broader functions of this coaching method.
Cleansing Up
To scrub up your assets to keep away from incurring extra costs, observe these steps:
- Delete any unused SageMaker Studio assets.
- Optionally, delete the SageMaker Studio area.
- Delete any S3 buckets created
- Confirm that your coaching job isn’t operating anymore! To take action, in your SageMaker console, select Coaching and test Coaching jobs.

To be taught extra about cleansing up your assets provisioned, try Clear up.
Conclusion
On this instance you educated a Qwen2.5-0.5B mannequin utilizing GRPO (Group Relative Coverage Optimization) on GSM8K: a dataset of 8,500 grade college math phrase issues that require multi-step arithmetic reasoning and pure language understanding. Every drawback features a query like “Janet’s geese lay 16 eggs per day…” with step-by-step options ending in numerical solutions, making it perfect for verifiable reward coaching.
This implementation demonstrates the effectiveness of Reinforcement Studying with Verifiable Rewards (RLVR) for mathematical reasoning duties. The GRPO-trained Qwen2.5-0.5B mannequin achieved a 3.7x enchancment over the bottom mannequin, reaching 41% accuracy on GSM8K in comparison with the baseline 11%.The analysis outcomes validate RLVR as a promising method for domains with objectively verifiable outcomes, providing an alternative choice to preference-based coaching strategies. The brink conduct suggests GRPO learns to leverage group comparisons from a number of examples, in line with its group-based optimization method. This work establishes a basis for making use of verifiable reward methods to different domains requiring logical rigor and mathematical accuracy.
For extra info on Amazon SageMaker AI totally managed coaching, consult with the coaching part of the SageMaker AI documentation. The supporting code for this put up will be present in GitHub.
In regards to the authors

{kind=link}