


Sustaining mannequin agility is essential for organizations to adapt to technological developments and optimize their synthetic intelligence (AI) options. Whether or not transitioning between completely different giant language mannequin (LLM) households or upgrading to newer variations throughout the identical household, a structured migration method and a standardized course of are important for facilitating steady efficiency enchancment whereas minimizing operational disruptions. Nonetheless, creating such an answer is difficult in each technical and non-technical facets as a result of the answer must:
- Be generic to cowl a wide range of use instances
- Be particular so {that a} new person can apply it to the goal use case
- Present complete and truthful comparability between LLMs
- Be automated and scalable
- Incorporate domain- and task-specific information and inputs
- Have a well-defined, end-to-end course of from knowledge preparation steering to last success standards
On this submit, we introduce a scientific framework for LLM migration or improve in generative AI manufacturing, encompassing important instruments, methodologies, and finest practices. The framework facilitates transitions between completely different LLMs by offering sturdy protocols for immediate conversion and optimization. It contains analysis mechanisms that assess a number of efficiency dimensions, enabling data-driven decision-making by means of detailed and comparative evaluation of supply and vacation spot fashions. The proposed method affords a complete resolution that features the technical facets of mannequin migration and supplies quantifiable metrics to validate profitable migration and establish areas for additional optimization, facilitating a seamless transition and steady enchancment. Listed here are just a few highlights of the answer:
- Gives a wide range of reporting choices with varied LLM analysis frameworks and complete steering for metrics choice for goal use instances.
- Gives automated immediate optimization and migration with Amazon Bedrock Immediate Optimization and the Anthropic Metaprompt tool, along with finest practices for additional immediate optimization.
- Gives complete steering for mannequin choice and an end-to-end resolution for mannequin comparability concerning price, latency, accuracy, and high quality.
- Gives function examples and use case examples for customers to shortly apply the answer to the goal use case.
- The entire time required for an LLM migration or improve by following this framework is from two days as much as two weeks relying on the complexity of the use case.
Resolution overview
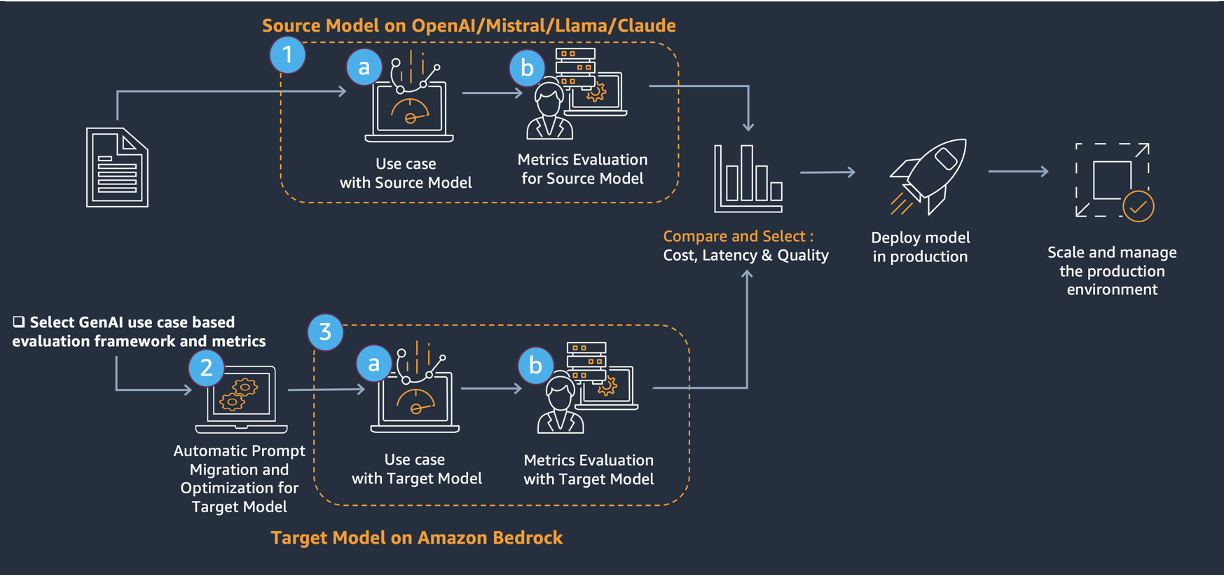
The core of the migration includes a three-step method, proven within the previous diagram.
- Consider the supply mannequin.
- Immediate migration to and optimization of the goal mannequin with Amazon Bedrock immediate optimization and the Anthropic Metaprompt instrument.
- Consider the goal mannequin.
This resolution supplies a complete method to improve current generative AI options (supply mannequin) to LLMs on Amazon Bedrock (goal mannequin). This resolution addresses technical challenges by means of:
- Analysis metrics choice with a framework that makes use of varied LLMs
- Immediate enchancment and migration with Amazon Bedrock Immediate Optimization and the Anthropic Metaprompt instrument
- Mannequin comparability throughout price, latency, and efficiency
This structured method supplies a sturdy framework for evaluating, migrating, and optimizing LLMs. By following these steps, we are able to transition between fashions, probably unlocking improved efficiency, cost-efficiency, and capabilities in your AI functions. The method emphasizes thorough preparation, systematic analysis, and steady enchancment; setting the stage for long-term success in utilizing superior language fashions.
Resolution implementation
Dataset preparation
An analysis dataset with high-quality samples is important to the migration course of. For many use instances, samples with floor fact solutions are required; whereas for different use instances, metrics that don’t require floor fact—akin to reply relevancy, faithfulness, toxicity, and bias (see Analysis of frameworks and metrics choice part)—can be utilized because the willpower metrics. Use the next steering and knowledge format to organize the pattern knowledge for the goal use instances.
Prompt fields for pattern knowledge embrace:
- Immediate used for the supply mannequin
- Immediate enter (if any), for instance: Questions and context for Retrieval-Augmented Technology (RAG)-based reply era
- Configurations used for supply mannequin invocation, for instance, temperature, top_p, top_k, and so forth.
- Floor truths
- Output from the supply mannequin
- Latency of the supply mannequin
- Enter and output tokens from the supply mannequin, which can be utilized for price calculation
It’s essential to keep in mind that top quality floor truths are important to profitable migration for many use instances. Floor truths shouldn’t solely be validated concerning correctness, but in addition to confirm that they match the subject material knowledgeable’s (SME’s) steering and analysis standards. See Error Evaluation part for an instance of a SME’s steering and analysis standards.
As well as, if any current analysis metrics can be found, akin to a human analysis rating or thumbs up/thumbs down from a SME, embrace these metrics and corresponding reasoning or feedback for every knowledge pattern. If any automated evaluations have been carried out, embrace the automated analysis scores, strategies, and configurations. The next part supplies extra detailed steering on choosing analysis frameworks and defining the metrics. Nonetheless, it’s nonetheless beneficial to gather the prevailing or most popular analysis metrics from stakeholders for reference.
Embrace the next fields if relevant:
- Present human analysis metrics for the supply mannequin, for instance, the SME rating for supply mannequin.
- Present automated analysis metrics for the supply mannequin, for instance, the LLM-as-a-judge rating for the supply mannequin.
The next desk is an instance format of the info samples:
| sample_id | … |
| query | |
| content material | |
| prompt_source_llm | |
| answer_ground_truth | |
| answer_ source_llm | |
| latency_ source_llm | |
| input_token_source_llm | |
| output_token_source_llm | |
| llm_judge_score_source_llm | |
| human_score_source_llm | |
| human_score_reasoning_source_llm |
Analysis of frameworks and metrics choice
After accumulating info and knowledge samples, the subsequent step is to decide on the right analysis metrics for the generative AI use case. Apart from human analysis by a SME, automated analysis metrics are advisable as a result of they’re extra scalable and goal and help the long-term well being and sustainability of the product. The next desk reveals the automated metrics which are accessible for every use case.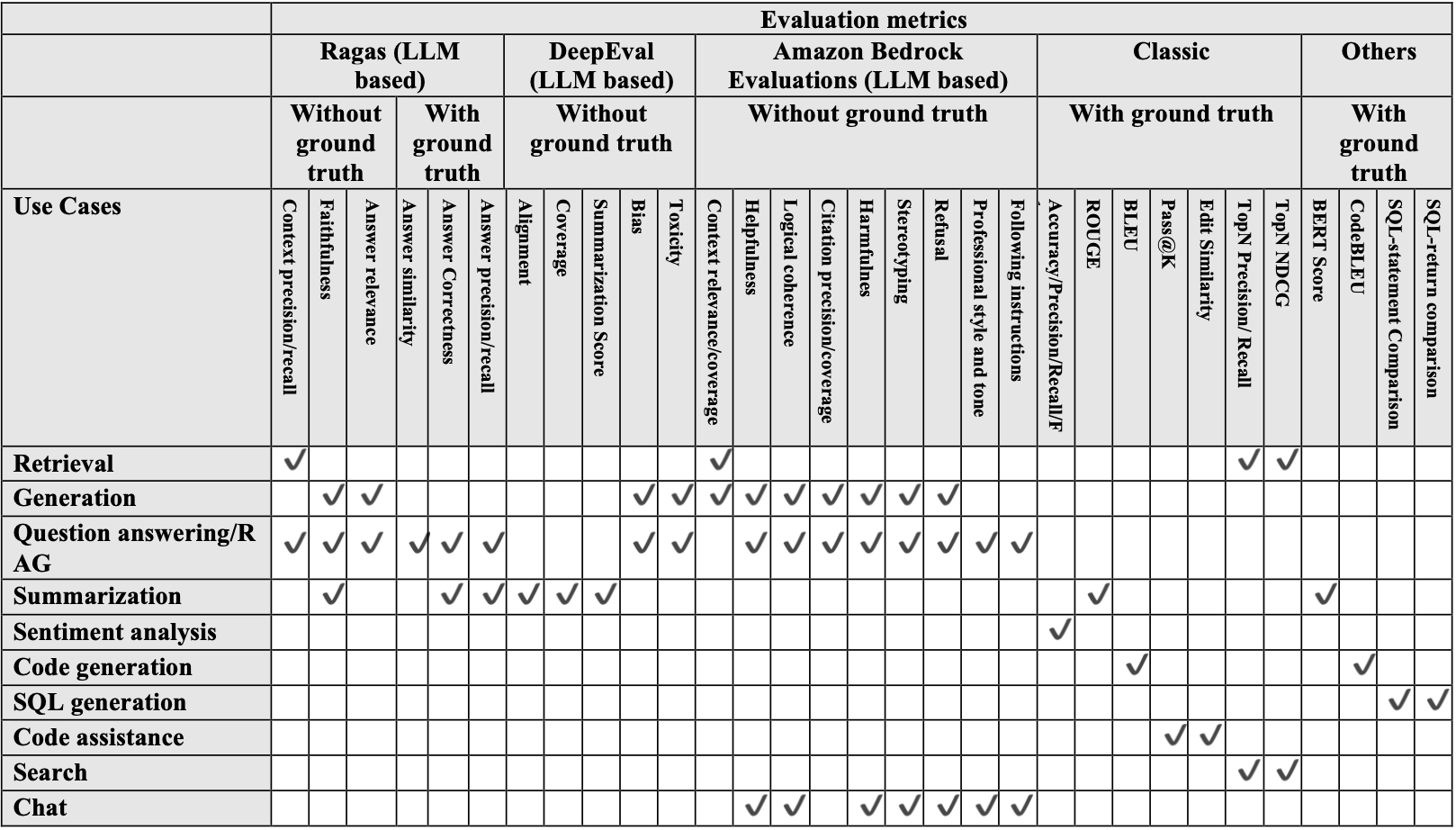
Mannequin choice
The number of an acceptable LLM requires cautious consideration of a number of components. Whether or not migrating to an LLM throughout the identical LLM household or to a distinct LLM household, understanding the important thing traits of every mannequin and the analysis standards is essential for achievement. When planning emigrate between LLMs, fastidiously evaluate and consider varied accessible choices and take a look at the mannequin card and respective prompting guides launched by every mannequin supplier. When evaluating LLM choices, think about a number of key standards:
- Enter and output modalities: Textual content, code, and multi-modal capabilities
- Context window dimension: Most enter tokens the mannequin can course of
- Price per inference or token
- Efficiency metrics: Latency and throughput
- Output high quality and accuracy
- Area specialization and particular use case compatibility
- Internet hosting choices: Cloud, on-premises, and hybrid
- Information privateness and safety necessities
After preliminary filtering based mostly on these traits, benchmarking assessments must be carried out by evaluating efficiency on particular duties to check shortlisted fashions. Amazon Bedrock affords a complete resolution with entry to varied LLMs by means of a unified API. This permits us to experiment with completely different fashions, evaluate their efficiency, and even use a number of fashions in parallel, all whereas sustaining a single integration level. This method not solely simplifies the technical implementation but in addition helps keep away from vendor lock-in by enabling a diversified AI mannequin technique.
Immediate migration
Two automated immediate migration and optimization instruments are launched right here: the Amazon Bedrock Immediate Optimization and the Anthropic Metaprompt instrument.
Amazon Bedrock Immediate Optimization
Amazon Bedrock Immediate Optimization is a instrument accessible in Amazon Bedrock to mechanically optimize prompts written by customers. This helps customers construct top quality generative AI functions on Amazon Bedrock and reduces friction when shifting workloads from different suppliers to Amazon Bedrock. Amazon Bedrock Immediate Optimization can allow migration of current workloads from a supply mannequin to LLMs on Amazon Bedrock with minimal immediate engineering. With this instrument, we are able to select the mannequin to optimize the immediate for after which generate an optimized immediate for the goal mannequin. The primary benefit of utilizing Amazon Bedrock Immediate Optimization is the flexibility to make use of it from the AWS Administration Console for Amazon Bedrock. Utilizing the console, we are able to shortly generate a brand new immediate for the goal mannequin. We will additionally use the Bedrock API to generate a migrated immediate, please see the detailed implementation under.
Choice A) Optimize a immediate from the Amazon Bedrock Console
- Within the Amazon Bedrock console, go to Immediate administration.
- Select Create immediate, enter a reputation for the immediate template, and select Create.
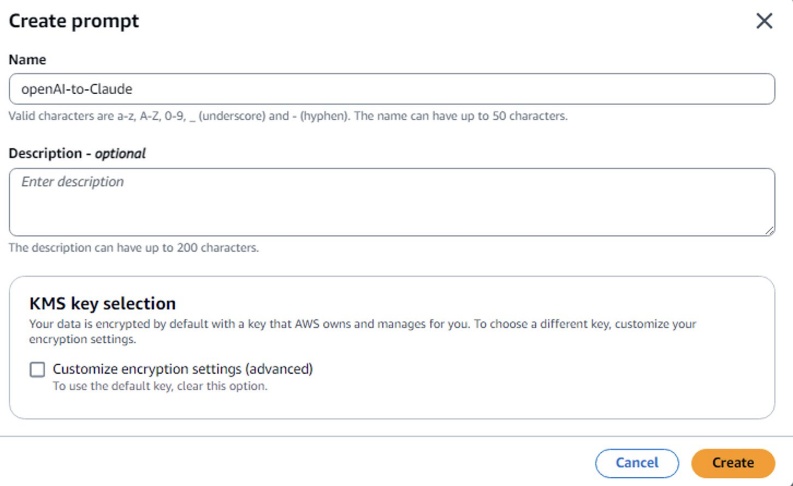
- Enter the supply mannequin immediate. Create variables by enclosing a reputation with double curly braces:
{{variable}}. Within the Take a look at variables part, enter values to exchange the variables with when testing. - Choose a Goal Mannequin in your optimized immediate. For instance, Anthropic’s Claude Sonnet 4.
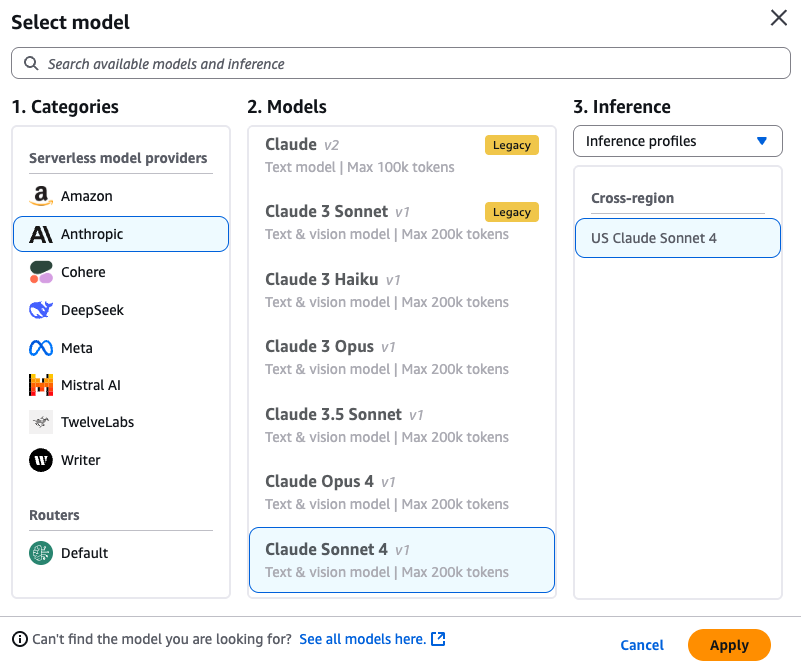
- Select the Optimize button to generate an optimized immediate for the goal mannequin.

6. After the immediate is generated, the comparability window of the optimized immediate for the goal mannequin is proven together with your authentic immediate from supply mannequin.
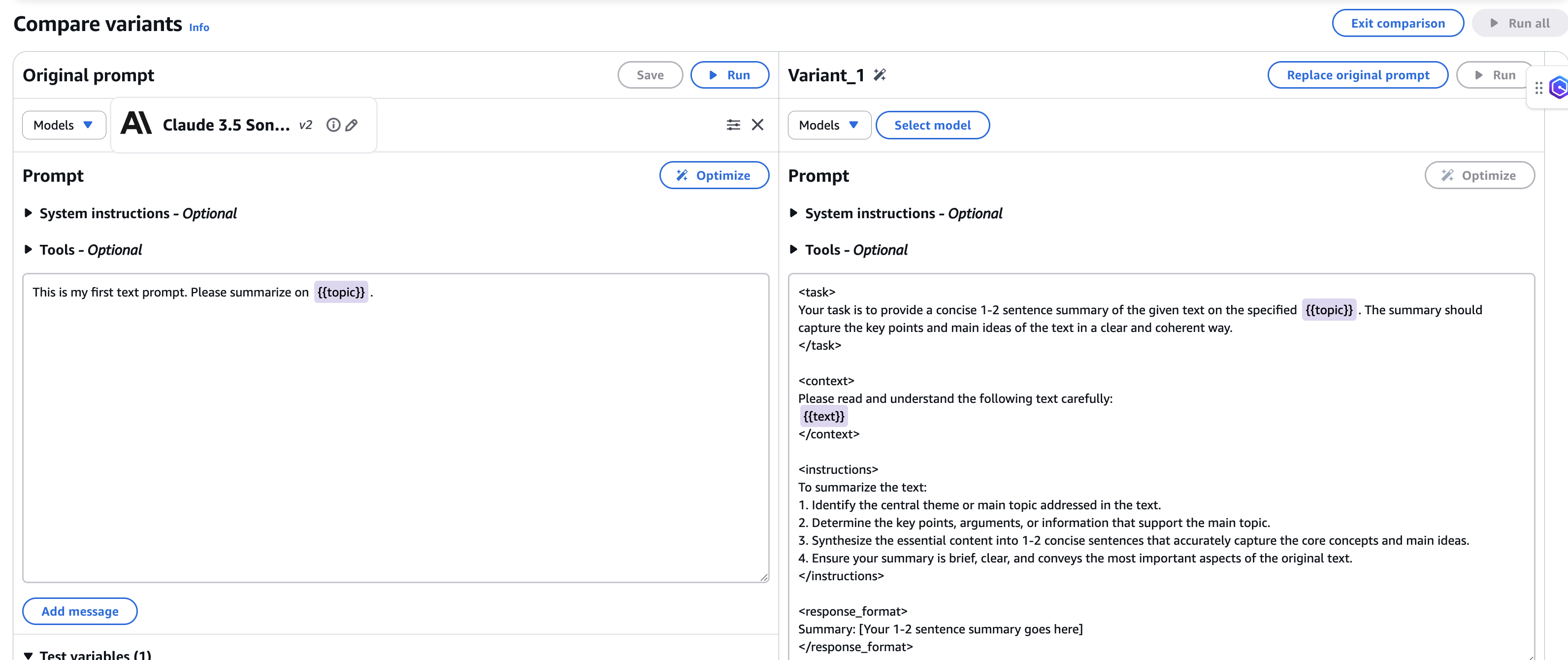
7. Save the brand new optimized immediate earlier than exiting evaluating mode.
Choice B) Optimize a immediate utilizing Amazon Bedrock API
We will additionally use the Bedrock API to generate a migrated immediate, by sending an OptimizePrompt request with an Brokers for Amazon Bedrock runtime endpoint. Present the immediate to optimize within the enter object and specify the mannequin to optimize for within the targetModelId discipline.
The response stream returns the next occasions:
- analyzePromptEvent – Seems when the immediate is completed being analyzed. Incorporates a message describing the evaluation of the immediate.
- optimizedPromptEvent – Seems when the immediate has completed being rewritten. Incorporates the optimized immediate.
Run the next code pattern to optimize a immediate:
Anthropic Metaprompt instrument
The Metaprompt is a immediate optimization instrument provided by Anthropic the place Claude is prompted to write down immediate templates on the person’s behalf based mostly on a subject or activity. We will use it to instruct Claude on finest assemble a immediate to attain a given goal constantly and precisely.
The important thing steps are:
- Specify the uncooked immediate template, clarify the duty, and specify the enter variables and the anticipated output.
- Run Metaprompt with a Claude LLM akin to Claude-3-Sonnet by inputting the uncooked immediate from the supply mannequin.
- The brand new immediate template is generated with an optimized set of directions and format following Claude LLM’s finest practices.
Advantages of utilizing metaprompts:
- Prompts are way more detailed and complete in comparison with human-created prompts
- Helps improve the probability that finest practices are adopted for prompting the Anthropic fashions
- Permits specifying that key particulars such most popular tone
- Improves high quality and consistency of the mannequin’s outputs
The Metaprompt instrument is especially helpful for studying Claude’s most popular immediate fashion or as a technique to generate a number of immediate variations for a given activity, simplifying testing a wide range of preliminary immediate variations for the goal use case.
To implement this course of, observe the steps within the Prompt Migration Jupyter Notebook emigrate supply mannequin prompts to focus on mannequin prompts. This pocket book requires Claude-3-Sonnet to be enabled because the LLM in Amazon Bedrock utilizing Mannequin Entry to generate the transformed prompts.
The next is one instance of a supply mannequin immediate in a monetary Q&A use case:
After finishing the steps within the pocket book, we are able to mechanically get the optimized immediate for the goal mannequin. The next instance generates a immediate optimized for Anthropic’s Claude LLMs.
As proven within the previous instance, the immediate fashion and format are mechanically transformed to observe the very best practices of the goal mannequin, akin to utilizing XML tags and regrouping the directions to be clearer and extra direct.
Generate outcomes
Reply era throughout migration is an iterative course of. The final move contains passing migrated prompts and context to the LLM and producing a solution. A number of iterations are wanted to check completely different immediate variations, a number of LLMs, and completely different configurations of every LLM to assist us choose the very best mixture. Usually, your complete pipeline of a generative AI system (akin to a RAG-based chatbot) isn’t migrated. As a substitute, solely a portion of the pipeline is migrated. Thus, it’s essential {that a} fastened model of the remaining elements within the pipeline is obtainable. For instance, in a RAG-based query and reply (Q&A) system, we’d migrate solely the reply era part of the pipeline. Because of this, we are able to proceed to make use of the already generated context of the prevailing manufacturing mannequin.
As a finest observe, use the Amazon Bedrock fashions commonplace invocation technique (within the Migration code repository) to generate metadata akin to latency, time to first token, enter token, and output token along with the ultimate response. These metadata fields are added as a brand new column on the finish of the outcomes desk and used for analysis. The output format and column title must be aligned with the analysis metric necessities. The next desk reveals an instance of the pattern knowledge earlier than feeding it into the analysis pipeline for a RAG use case.
Instance of a pattern knowledge earlier than analysis:
| financebench_id | financebench_id_03029 |
| doc_name | 3M_2018_10K |
| doc_link | https://traders.3m.com/financials/sec-filings/content material/0001558370-19-000470/0001558370-19-000470.pdf |
| doc_period | 2018 |
| question_type | metrics-generated |
| query | What’s the FY2018 capital expenditure quantity (in USD hundreds of thousands) for 3M? Give a response to the query by counting on the small print proven within the money move assertion. |
| ground_truths | [‘$1577.00’] |
| evidence_text | … |
| page_number | 60 |
| llm_answer | In accordance with the money move assertion within the 3M 2018 10-Okay report, the capital expenditure (purchases of property, plant and gear) for fiscal yr |
| llm_contexts | … |
| latency_meta_time | 0.92706 |
| latency_meta_kwd | 0.60666 |
| latency_meta_comb | 1.44876 |
| latency_meta_ans_gen | 2.48371 |
| input_tokens | 21147 |
| output_tokens | 401 |
Analysis
Analysis is likely one of the most essential components of the migration course of as a result of it straight connects to the sign-off standards and determines the success of the migration. For many instances, analysis focuses on metrics in three main classes: accuracy and high quality, latency, and price. Both automated analysis or human analysis can be utilized to evaluate the accuracy and high quality of the mannequin response.
Automated analysis
The combination of LLMs within the high quality analysis course of represents a major development in evaluation methodology. These fashions excel at conducting complete evaluations throughout a number of dimensions, together with contextual relevance, coherence, and factual accuracy, whereas sustaining consistency and scalability. Two major classes of the automated analysis metrics are launched right here:
- Predefined metrics: Metrics predefined in LLM-based analysis frameworks akin to Ragas, DeepEval, and Amazon Bedrock Evaluations, or straight based mostly on non-LLM algorithms, like these launched in Evaluation of frameworks.
- Customized metrics: Personalized metrics with person offered definitions, analysis standards, or prompts to make use of LLM as an neutral decide.
Predefined metrics
These metrics are both utilizing some LLM-based analysis frameworks akin to Ragas and DeepEval or are straight based mostly on non-LLM algorithms. These metrics are broadly adopted, predefined, and have restricted choices for personalization. Ragas and DeepEval are two LLM-based analysis frameworks and metrics that we used as examples within the Migration code repository.
- Ragas: Ragas is an open supply framework that helps to judge RAG pipelines. RAG denotes a category of LLM functions that use exterior knowledge to enhance the LLM’s context. It supplies a wide range of LLM-powered automated analysis metrics. The next metrics are launched within the Ragas evaluation notebook within the Migration code repository.
- Reply precision: Measures how precisely the mannequin’s generated reply accommodates related and proper claims in comparison with the bottom fact reply.
- Reply recall: Evaluates the completeness of the reply; that’s, the mannequin’s means to retrieve the appropriate claims and evaluate them to the bottom fact reply. Excessive recall signifies that the reply totally covers the required particulars in step with the bottom fact.
- Reply correctness: The evaluation of reply correctness includes gauging the accuracy of the generated reply when in comparison with the bottom fact. This analysis depends on the
floor factand thereply, with scores starting from 0 to 1. A better rating signifies a better alignment between the generated reply and the bottom fact, signifying higher correctness. - Reply similarity: The evaluation of the semantic resemblance between the generated reply and the bottom fact. This analysis relies on the
floor factand thereply, with values falling throughout the vary of 0 to 1. A better rating signifies a greater alignment between the generated reply and the bottom fact.
The next desk is a pattern knowledge output after Ragas analysis.
| financebench_id | financebench_id_03029 |
| doc_name | 3M_2018_10K |
| doc_link | https://investors.3m.com/financials/sec-filings/content/0001558370-19-000470/0001558370-19-000470.pdf |
| doc_period | 2018 |
| question_type | metrics-generated |
| query | What’s the FY2018 capital expenditure quantity (in USD hundreds of thousands) for 3M?. |
| ground_truths | [‘$1577.00’] |
| evidence_text | … |
| page_number | 60 |
| llm_answer | In accordance with the money move assertion within the 3M 2018 10-Okay report, the capital expenditure (purchases of property, plant and gear) for fiscal yr 2018 was $1,577 million. … |
| llm_contexts | … |
| latency_meta_time | 0.92706 |
| latency_meta_kwd | 0.60666 |
| latency_meta_comb | 1.44876 |
| latency_meta_ans_gen | 2.48371 |
| input_tokens | 21147 |
| output_tokens | 401 |
| answer_precision | 0 |
| answer_recall | 1 |
| answer_correctness | 0.16818 |
| answer_similarity | 0.33635 |
- DeepEval: DeepEval is an open supply LLM analysis framework. It’s much like Pytest however specialised for unit testing LLM outputs. DeepEval incorporates the most recent analysis to judge LLM outputs based mostly on metrics such because the G-Eval, hallucination, reply relevancy, Ragas, and so forth. It makes use of LLMs and varied different pure language processing (NLP) fashions that run domestically in your machine for analysis. In DeepEval, a metric serves as a regular of measurement for evaluating the efficiency of an LLM output based mostly on particular standards. DeepEval affords a spread of default metrics to shortly get began. The next metrics are launched within the DeepEval evaluation notebook within the Migration code repository.|
- Reply relevancy: The reply relevancy metric measures the standard of your RAG pipeline’s generator by evaluating how related the
actual_outputof your LLM software is in comparison with the offered enter. - Faithfulness: The faithfulness metric measures the standard of your RAG pipeline’s generator by evaluating whether or not the
actual_outputfactually aligns with the contents of yourretrieval_context. - Toxicity: The toxicity metric is one other referenceless metric that evaluates toxicity in your LLM outputs.
- Bias: The bias metric determines whether or not your LLM output accommodates gender, racial, or political bias.
- Reply relevancy: The reply relevancy metric measures the standard of your RAG pipeline’s generator by evaluating how related the
- Amazon Bedrock Evaluations: Amazon Bedrock Evaluations is a set of instruments for evaluating, evaluating, and choosing basis fashions – together with customized or third-party fashions – in your particular use instances. It helps each model-only and RAG pipelines analysis. We will use Bedrock Evaluations both through AWS console or API. Amazon Bedrock Evaluations affords an in depth checklist of built-in metrics for each standalone LLMs and full RAG pipelines, together with however not restricted to:
- Accuracy: Measures the correctness of mannequin outputs.
- Faithfulness: Checks for factual accuracy and avoids hallucinations.
- Helpfulness: Measures holistically how helpful responses are in answering questions.
- Logical coherence: Measures whether or not the responses are free from logical gaps, inconsistencies or contradictions.
- Harmfulness: Measures dangerous content material within the responses, together with hate, insults, violence, or sexual content material.
- Stereotyping: Measures generalized statements about people or teams of individuals in responses.
- Refusal: Measures how evasive the responses are in answering questions.
- Following directions: Measures how effectively the mannequin’s response respects the precise instructions discovered within the immediate.
- Skilled fashion and tone: Measures how acceptable the response’s fashion, formatting, and tone is for an expert setting.
Customized metrics
These metrics are person outlined and are usually tailor-made to particular duties or domains. One well-liked technique is to make use of customized LLM as a decide to supply an analysis rating for a solution utilizing a user-provided immediate. In distinction to utilizing predefined metrics, this technique is very customizable as a result of we are able to present the immediate with task-specific analysis necessities. For instance, we are able to ask the LLM to generate a 10-point scoring system and comprehensively consider the reply towards floor fact throughout completely different dimensions, akin to correctness of data, contextual relevance, depth and comprehensiveness of element, and general utility and helpfulness.
The next is an instance of a personalized immediate for LLM as a decide:
Human analysis
Whereas quantitative metrics present beneficial knowledge factors, a complete qualitative analysis based mostly on skilled tips and SME suggestions can also be essential to validate mannequin efficiency. Efficient qualitative evaluation usually covers a number of key areas together with response theme and tone consistency, detection of inappropriate or undesirable content material, domain-specific accuracy, date and time associated points, and so forth. By utilizing SME experience, we are able to establish refined nuances and potential points which may escape quantitative evaluation. Error analysis supplies some potential facets that the SME can use for analysis standards, which might additionally function the steering for validating and making ready floor truths. We will use instruments akin to Amazon Bedrock Evaluations for human analysis.
Although human analysis or person suggestions collected from a UI can straight replicate the SME’s analysis standards, it’s not as environment friendly, scalable, and goal because the automated analysis strategies. Thus, a generative AI system improvement life cycle would possibly begin with human analysis however finally strikes towards automated analysis. Human analysis can be utilized if automated analysis isn’t assembly baseline targets or pre-defined analysis standards.
Latency metrics
When migrating language fashions, runtime efficiency metrics are essential indicators of operational success. Whole latency and Time to first token (TTFT) are the most typical metrics for latency measurement.
- Whole latency is an end-to-end metric that measures the full length required for full response era, from preliminary immediate to last output. It encompasses processing the enter, producing the response, and delivering it to the person. Whole latency impacts person satisfaction, system throughput, and useful resource utilization.
- Time to first token (TTFT) quantifies the preliminary response pace—particularly, the length till the mannequin generates its first output token. This metric considerably impacts perceived responsiveness and person expertise, particularly in interactive functions. TTFT is especially essential in conversational AI and real-time techniques (functions akin to chatbots, digital assistants, and interactive search techniques) the place customers anticipate speedy suggestions. A low TTFT creates an impression of system responsiveness and might tremendously improve person engagement.
If the outcomes era step requires a number of LLM calls, the breakdown latency metrics must be offered as a result of solely the submodule latency akin to LLM migration must be in contrast within the following mannequin comparability step.
Price calculation
For LLM invocation, the fee may be calculated based mostly on the variety of enter and output tokens and the corresponding worth per token:
The associated fee calculations desk for worth per enter and output token may be present in Amazon Bedrock Pricing .
Mannequin comparability report: Efficiency, latency, and price
We will use the Generate Comparison Report notebook within the code repository to mechanically generate a last comparability report for the supply and goal mannequin in a holistic view.
We will additionally use analysis studies generated from Ragas and DeepEval with corresponding metrics to check the fashions from the 2 analysis frameworks. We will receive a side-by-side comparability of the typical enter and output tokens and common price and latency for the chosen fashions. As proven within the following determine, after operating this pocket book, there are two comparability tables for the supply and goal fashions from the 2 chosen analysis frameworks.
Ragas
DeepEval
Additional optimization
When enhancing and optimizing a generative AI manufacturing pipeline throughout an LLM migration or improve, customers usually deal with two key areas:
- High quality of generated solutions
- Latency of response era
Immediate optimization
To optimize the standard of the generated solutions, we have to get an excellent understanding of the errors by conducting error evaluation and figuring out the objects for immediate optimization.
Error evaluation
Getting the absolute best response from a candidate LLM is unlikely with none optimization. Thus, conducting error evaluation and specializing in doable facets for error patterns helps us consider generated reply high quality and establish the alternatives for enchancment. Error evaluation additionally supplies a path to guide immediate engineering to enhance the standard. After gathering error evaluation insights and suggestions from SMEs, an iterative immediate optimization course of may be carried out. To start out, formulate the error evaluation insights and suggestions from SMEs into clear steering or standards. Ideally, these standards must be clarified earlier than beginning the immediate migration. These standards function the core issues for additional immediate optimization to assist present constant, high-quality responses to fulfill the SME’s bar. The next is an instance of doable steering and standards we’d obtain from a SME.
Instance of a solution formatting fashion information from a SME in a monetary Q&A use case:
- Correctness
- Be sure pulled numbers are appropriate. All numbers must be matched to floor fact.
- Be sure all claims from floor fact can be found within the LLM reply.
- Generated responses shouldn’t add irrelevant sentences.
- Time
- Generated solutions should acknowledge the fiscal yr and all wanted quarters from the query accurately.
- Within the reply, quarter orders from most up-to-date to the earliest is most popular.
- When the query asks about year-over-year, the reply ought to specify general yr or the final quarter, not quarter-by-quarter.
- When the reply comes from a single information doc, embrace the date of publication within the reply.
- Theme and tone
- Use skilled language mirroring the fashion of a newspaper.
- Format and excerpts
- When the person question asks for a listing, current the checklist in bullet level format.
- When the person question asks for excerpts, present a abstract assertion adopted by a bulleted checklist of unedited excerpts straight from the doc.
- Queries that ask for a complete checklist ideally embrace bullet factors.
- Queries that ask for subjects or themes with subjective classes ideally embrace a bulleted checklist.
- Don’t begin the reply by referencing the context (in keeping with context).
- Size
- Most responses must be between 30–150 phrases. Longer solutions are acceptable when the query includes a number of entities or responding to queries that require sub-categories throughout the response.
Optimization strategies
After acquiring clear standards, a number of optimization strategies can be utilized to handle these standards, akin to:
- Immediate engineering to specify sure standards within the instruction of the immediate
- Few-shot studying to specify the reply format and generated reply examples
- Incorporating meta-information that would assist the LLM to know the context of the duty and query
- Pre- or post-processing to implement the output format or resolve some frequent error patterns
Latency optimization
There are just a few doable options to optimize the latency:
Optimizing prompts to generate shorter solutions
The latency of an LLM mannequin is straight impacted by the variety of output tokens as a result of every extra token requires a separate ahead cross by means of the mannequin, rising processing time. As extra tokens are generated, latency grows, particularly in bigger fashions akin to Opus 4. To cut back the latency, we are able to add directions to immediate to keep away from offering prolonged solutions, unrelated explanations, or filler phrases.
Utilizing provisioned throughput
Throughput refers back to the quantity and charge of inputs and outputs {that a} mannequin processes and returns. Buying provisioned throughput to supply a better degree of throughput for a devoted hosted mannequin can probably cut back the latency in comparison with utilizing on-demand fashions. Although it can’t assure the development of latency, it constantly helps to forestall throttled requests.
Enchancment lifecycle
It’s unlikely {that a} candidate LLM can obtain the absolute best efficiency with none optimization. It’s additionally typical for the previous optimization processes to be carried out iteratively. Thus, the development (optimization) lifecycle is important to enhance the efficiency and establish the gaps or defects within the pipeline or knowledge. The advance lifecycle usually contains:
- Immediate optimization
- Reply era
- Analysis metrics era
- Error evaluation
- Pattern label verification
- Dataset updates concerning pattern defects and improper labels
Process or area information identificationThe migration course of described on this submit can be utilized in two phases in a generative AI resolution manufacturing lifecycle.
Finish-to-end LLM migration and mannequin agility
New LLMs are launched steadily. No LLM can constantly preserve peak efficiency for a given use case. It’s frequent for a manufacturing generative AI resolution emigrate to a different household of LLMs or improve to a brand new model of an LLM. Thus, having a regular and reusable end-to-end LLM migration or improve course of is important to the long-term success of any generative AI resolution.
Monitoring and high quality assurance
When migration or updates are stabilized, there must be a regular monitoring and high quality assurance course of utilizing a routinely refreshed golden analysis dataset with floor fact and automatic or human analysis metrics, in addition to analysis of precise person traces. As a part of this resolution, the established analysis and knowledge or floor fact assortment processes may be reused for monitoring and high quality assurance.
Suggestions and recommendations (classes discovered)
The next are some suggestions and recommendations for the success of an LLM migration or improve course of.
- Signal-off situation: The information, analysis standards and success standards outlined at first must be adequate for stakeholders to confidently log off on the method. Ideally, there must be no adjustments within the knowledge, floor truths, or SME analysis and success standards throughout the course of.
- Pattern knowledge and high quality: The information must be of adequate high quality and amount for assured analysis. The bottom fact solutions and labels must be totally aligned with the SME’s analysis standards and expectations. Ideally, there must be no adjustments within the knowledge, floor truths, or SME analysis standards throughout the course of.
- Enchancment lifecycle: Be sure to plan and implement an enchancment lifecycle to get probably the most out of your chosen LLM.
- Mannequin choice: When choosing competing goal fashions towards a supply mannequin, use assets such because the Artificial Analysis benchmarking web site to acquire a holistic comparability of fashions. These comparisons usually cowl high quality, efficiency, and worth evaluation, offering beneficial insights earlier than beginning the experiment. This preliminary analysis may also help slender down probably the most promising candidates and inform the experimental design.
- Efficiency towards price trade-offs: When evaluating completely different fashions or options, it’s essential to contemplate the stability between efficiency and price. In some instances, a mannequin would possibly supply barely decrease efficiency however at a sufficiently diminished price to make it a less expensive choice general. That is significantly true in situations the place the efficiency distinction is minimal, however the fee financial savings are substantial.
- Optimization strategies: Exploring varied optimization strategies, akin to immediate engineering or provisioned throughput, can result in important enhancements in efficiency metrics like accuracy and latency. These optimizations may also help bridge the hole between completely different fashions and must be thought of as a part of the analysis course of.
Conclusion
On this submit, we launched the AWS Generative AI Mannequin Agility Resolution, an end-to-end resolution for LLM migrations and upgrades of current generative AI functions that maintains and improves mannequin agility. The answer defines a standardized course of and supplies a complete toolkit for LLM migration or improve with a wide range of ready-to-use instruments and superior strategies that may can be utilized emigrate generative AI functions to new LLMs. This can be utilized as a regular course of within the lifecycle of your generative AI functions. After an software is stabilized with a particular LLM and configuration, the analysis and knowledge and floor fact assortment processes on this resolution may be reused for manufacturing monitoring and high quality assurance.
To study extra about this resolution, please take a look at our AWS Generative AI Model Agility Code Repo.
In regards to the authors

{kind=link}