


Massive language fashions (LLMs) now drive probably the most superior conversational brokers, artistic instruments, and decision-support techniques. Nonetheless, their uncooked output usually accommodates inaccuracies, coverage misalignments, or unhelpful phrasing—points that undermine belief and restrict real-world utility. Reinforcement Advantageous‑Tuning (RFT) has emerged as the popular technique to align these fashions effectively, utilizing automated reward alerts to exchange expensive handbook labeling.
On the coronary heart of recent RFT is reward features. They’re constructed for every area by way of verifiable reward features that may rating LLM generations by way of a bit of code (Reinforcement Studying with Verifiable Rewards or RLVR) or with LLM-as-a-judge, the place a separate language mannequin evaluates candidate responses to information alignment (Reinforcement Studying with AI Suggestions or RLAIF). Each these strategies present scores to the RL algorithm to nudge the mannequin to unravel the issue at hand. On this submit, we take a deeper take a look at how RLAIF or RL with LLM-as-a-judge works with Amazon Nova fashions successfully.
Why RFT with LLM‑as‑a-judge in comparison with generic RFT?
Reinforcement Advantageous-Tuning can use any reward sign, simple hand‑crafted guidelines (RLVR), or an LLM that evaluates mannequin outputs (LLM-as-a-judge or RLAIF). RLAIF makes alignment way more versatile and highly effective, particularly when reward alerts are obscure and arduous to craft manually. In contrast to generic RFT rewards that depend on blunt numeric scoring like substring matching, an LLM decide causes throughout a number of dimensions—correctness, tone, security, relevance—offering context-aware suggestions that captures subtleties and domain-specific nuances with out task-specific retraining. Moreover, LLM judges supply built-in explainability by way of rationales (for instance, “Response A cites peer-reviewed research”), offering diagnostics that speed up iteration, pinpoint failure modes instantly, and scale back hidden misalignments, one thing static reward features can’t do.
Implementing LLM-as-a-judge: Six crucial steps
This part covers the important thing steps concerned in designing and deploying LLM-as-a-judge reward features.
Choose the decide structure
The primary crucial resolution is choosing your decide structure. LLM-as-a-judge provides two major analysis modes: Rubric-based (point- based mostly) judging and Desire-based judging, every suited to totally different alignment situations.
| Standards | Rubric-based judging | Desire-based judging |
| Analysis technique | Assigns a numeric rating to a single response utilizing predefined standards | Compares two candidate responses side-by-side and selects the superior one |
| High quality measurement | Absolute high quality measurements | Relative high quality by way of direct comparability |
| Most well-liked used when | Clear, quantifiable analysis dimensions exist (accuracy, completeness, security compliance) | Coverage mannequin ought to discover freely with out reference knowledge restrictions |
| Knowledge necessities | Solely requires cautious immediate engineering to align the mannequin to reward specs | Requires a minimum of one response pattern for choice comparability |
| Generalizability | Higher for out-of-distribution knowledge, avoids knowledge bias | Depends upon high quality of reference responses |
| Analysis type | Mirrors absolute scoring techniques | Mirrors pure human analysis by way of comparability |
| Really helpful start line | Begin right here if choice knowledge is unavailable and RLVR unsuitable | Use when comparative knowledge is out there |
Outline your analysis standards
After you’ve chosen your decide sort, articulate the particular dimensions that you simply wish to enhance. Clear analysis standards are the inspiration of efficient RLAIF coaching.
For Desire-based judges:
Write clear prompts explaining what makes one response higher than one other. Be express about high quality preferences with concrete examples. Instance: “Desire responses that cite authoritative sources, use accessible language, and instantly handle the person’s query.”
For Rubric-based judges:
We suggest utilizing Boolean (go/fail) scoring for rubric-based judges. Boolean scoring is extra dependable and reduces decide variability in comparison with fine-grained 1–10 scales. Outline clear go/fail standards for every analysis dimension with particular, observable traits.
Choose and configure your decide mannequin
Select an LLM with adequate reasoning functionality to guage your goal area, configured by way of Amazon Bedrock and referred to as utilizing a reward AWS Lambda operate. For widespread domains like math, coding, and conversational capabilities, smaller fashions can work effectively with cautious immediate engineering.
| Mannequin tier | Most well-liked for | Price | Reliability | Amazon Bedrock mannequin |
| Massive/Heavyweight | Complicated reasoning, nuanced analysis, multi-dimensional scoring | Excessive | Very Excessive | Amazon Nova Professional, Claude Opus, Claude Sonnet |
| Medium/Light-weight | Common domains like math or coding, balanced cost-performance | Low-Medium | Reasonable-Excessive | Amazon Nova 2 Lite, Claude Haiku |
Refine your decide mannequin immediate
Your decide immediate is the inspiration of alignment high quality. Design it to supply structured, parseable outputs with clear scoring dimensions:
- Structured output format – Specify JSON or parseable format for simple extraction
- Clear scoring guidelines – Outline precisely how every dimension ought to be calculated
- Edge case dealing with – Tackle ambiguous situations (for instance, “If response is empty, assign rating 0”)
- Desired behaviors – Explicitly state behaviors to encourage or discourage
Align decide standards with manufacturing analysis metrics
Your reward operate ought to mirror the metrics that you’ll use to guage the ultimate mannequin in manufacturing. Align your reward operate with manufacturing success standards to allow fashions designed for the right aims.
Alignment workflow:
- Outline manufacturing success standards (for instance, accuracy, security) with acceptable thresholds
- Map every criterion to particular decide scoring dimensions
- Validate that decide scores correlate along with your analysis metrics
- Check the decide on consultant samples and edge instances
Constructing a sturdy reward Lambda operate
Manufacturing RFT techniques course of hundreds of reward evaluations per coaching step. Construct a resilient reward Lambda operate to assist present coaching stability, environment friendly compute utilization, and dependable mannequin conduct. This part covers methods to construct a reward Lambda operate that’s resilient, environment friendly, and manufacturing prepared.
Composite reward rating structuring
Don’t rely solely on LLM judges. Mix them with quick, deterministic reward parts that catch apparent failures earlier than costly decide evals:
Core parts
| Part | Goal | When to make use of |
| Format correctness | Confirm JSON construction, required fields, schema compliance | All the time – catches malformed outputs instantly. Low-cost and instantaneous suggestions. |
| Size penalties | Discourage overly verbose or terse responses | When output size issues (for instance, summaries) |
| Language consistency | Confirm responses match enter language | Vital for multilingual functions |
| Security filters | Rule-based checks for prohibited content material | All the time – prevents unsafe content material from reaching manufacturing |
Infrastructure readiness
- Implement exponential backoff: Handles Amazon Bedrock API fee limits and transient failures gracefully
- Parallelization technique: Use ThreadPoolExecutor or async patterns to parallelize decide calls throughout rollouts to scale back latency
- Keep away from Lambda chilly begin delays: Set an acceptable Lambda timeout (quarter-hour really helpful) and provisioned concurrency (~100 for typical setups)
- Error dealing with: Add complete error dealing with that returns impartial/noisy rewards (0.5) relatively than failing all the coaching step
Check your reward Lambda operate for resilience
Validate decide consistency and calibration:
- Consistency: Check decide on the identical samples a number of instances to measure rating variance (ought to be low for deterministic analysis)
- Cross-judge comparability: Evaluate scores throughout totally different decide fashions to establish analysis blind spots
- Human calibration: Periodically pattern rollouts for human assessment to catch decide drift or systematic errors
- Regression testing: Create a “decide check suite” with recognized good/unhealthy examples to regression check decide conduct
RFT with LLM-as-a-judge – Coaching workflow
The next diagram illustrates the whole end-to-end coaching course of, from baseline analysis by way of decide validation to manufacturing deployment. Every step builds upon the earlier one, making a resilient pipeline that balances alignment high quality with computational effectivity whereas actively stopping reward hacking and supporting production-ready mannequin conduct.
Actual-world case research: Automating authorized contract assessment
On this part, we consult with a real-world use case with a number one authorized trade companion. The duty is to generate feedback on dangers, assessments, and actions on authorized documentation with respect to the insurance policies and former contracts as reference paperwork.
Problem
Associate was occupied with fixing the issue of automating the method of reviewing, assessing, and flagging dangers in authorized contract paperwork. Particularly, they needed to guage potential new contracts in opposition to inside tips and rules, previous contracts, and legal guidelines of the nation pertaining to the contract.
Resolution
We formulated this downside as one the place we’re offering a goal doc (the “contract” that wants analysis), and a reference doc (the grounding doc and context) and count on the LLM to generate a JSON with a number of feedback, remark sorts, and really helpful actions to take based mostly on the evaluation. The unique dataset out there for this use case was comparatively small that included full contracts together with annotations and feedback from authorized consultants. We used LLM as a decide utilizing GPT OSS 120b mannequin because the decide and a customized system immediate throughout RFT.
RFT workflow
Within the following part we cowl particulars of the important thing elements within the RFT workflow for this use case.
Reward Lambda operate for LLM-as-a-judge
The next code snippets current the important thing parts of the reward Lambda operate.
Be aware: title of Lambda operate ought to have “SageMaker”, for instance, "arn:aws:lambda:us-east-1:123456789012:operate:MyRewardFunctionSageMaker"
a) Begin with defining a high-level goal
b) Outline the analysis method
c) Describe the scoring dimensions with clear specs on how a specific rating ought to be calculated
d) Clearly outline the ultimate output format to parse
e) Create a high-level Lambda handler, offering adequate multithreading for quicker inference
Deployment of the Lambda operate
We used the next AWS Id and Entry Administration (IAM) permissions and settings within the Lambda operate. The next configurations are required for reward Lambda features. RFT coaching can fail if any of them are lacking.
a) Permissions for Amazon SageMaker AI execution function
Your Amazon SageMaker AI execution function should have permission to invoke your Lambda operate. Add this coverage to your Amazon SageMaker AI execution function:
b) Permissions for Lambda operate execution function
Your Lambda operate’s execution function wants primary Lambda execution permissions and the permissions to Invoke the decide Amazon Bedrock mannequin.
Be aware: This resolution follows the AWS shared accountability mannequin. AWS is answerable for securing the infrastructure that runs AWS providers within the cloud. You might be answerable for securing your Lambda operate code, configuring IAM permissions, implementing encryption and entry controls, managing knowledge safety and privateness, configuring monitoring and logging, and verifying compliance with relevant rules. Observe the precept of least privilege by scoping permissions to particular useful resource ARNs. For extra info, see Safety in AWS Lambda and Amazon SageMaker AI Safety within the AWS documentation.
c) Add provisioned concurrency
Publish a model of the Lambda and to allow the operate to scale with out fluctuations in latency, we added some provisioned concurrency. 100 was adequate on this case, nevertheless, there’s extra room for value enhancements right here.

d) Set Lambda timeout to fifteen minutes

Customizing the coaching configuration
We launched Nova Forge SDK that can be utilized for all the mannequin customization lifecycle—from knowledge preparation to deployment and monitoring. Nova Forge SDK removes the necessity to seek for the suitable recipes or container URI for particular methods.
You should utilize the Nova Forge SDK to customise coaching parameters in two methods: present a full recipe YAML utilizing recipe_path or go particular fields utilizing overrides for selective modifications. For this use case, we use overrides to tune the rollout and coach settings as proven within the following part.
Outcomes
RFT with Amazon Nova 2 Lite achieved a 4.33 mixture rating—the very best efficiency throughout all evaluated fashions—whereas sustaining good JSON schema validation. This represents a big enchancment, demonstrating that RFT can produce production-ready, specialised fashions that outperform bigger general-purpose alternate options.
We evaluated fashions utilizing a “better of ok” single-comment setting, the place every mannequin generated a number of feedback per pattern and we scored the highest-quality output. This method establishes an higher sure on efficiency and allows a good comparability between fashions that produce single versus a number of outputs.
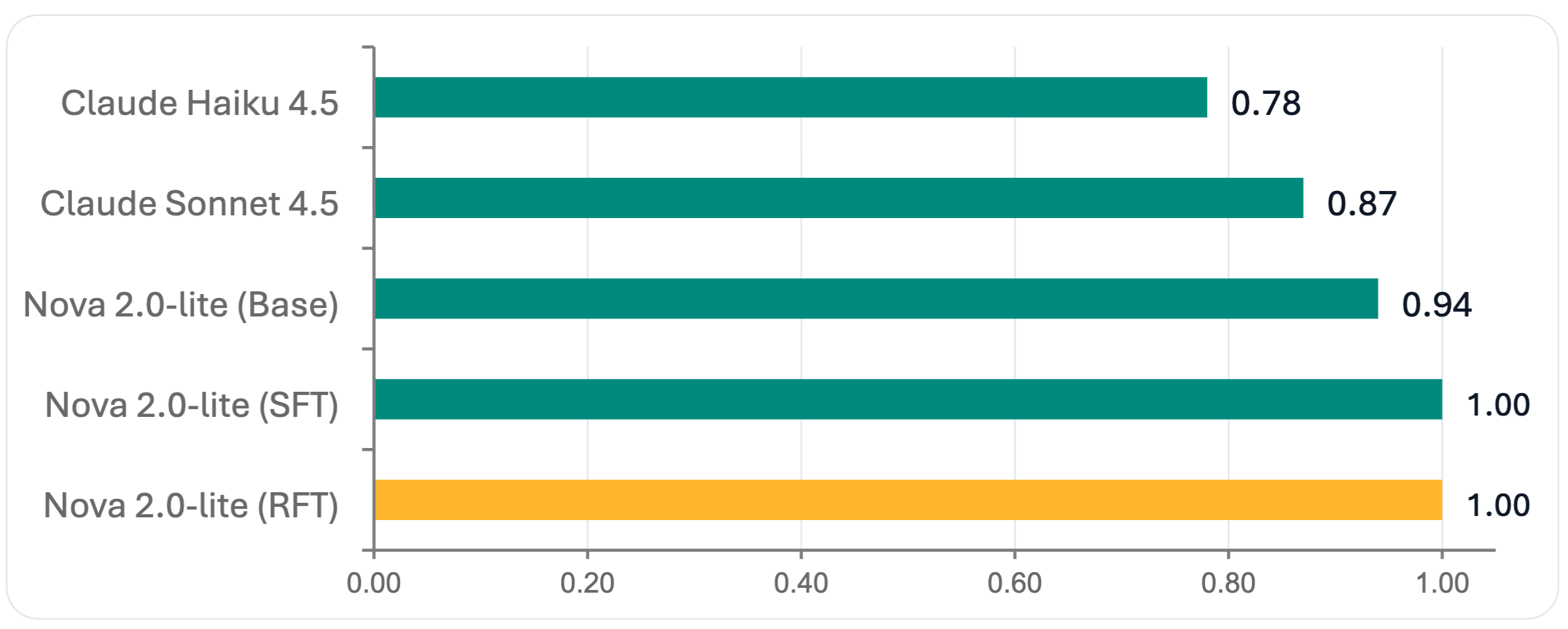
Determine 1 — JSON Schema Validation Scores (0–1 scale, greater is healthier)
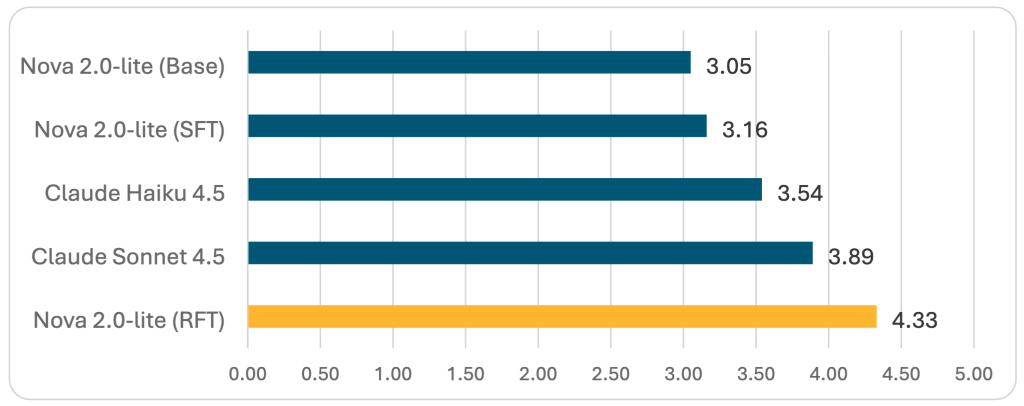
Determine 2 — Combination LLM decide scores (1–5 scale, greater is healthier)
Key takeaways:
- RFT achieved the very best efficiency amongst evaluated fashions on this research.
Amazon Nova 2 Lite with RFT achieved a 4.33 mixture rating, outperforming each Claude Sonnet 4.5 and Claude Haiku 4.5, whereas additionally reaching good JSON schema validation.
- Removes pointless coaching artifacts
Throughout SFT iterations, we noticed problematic behaviors together with repetitive remark technology and unnatural Unicode character predictions. These points, seemingly attributable to overfitting or dataset imbalances, didn’t seem in RFT checkpoints. RFT’s reward-based enhancements naturally discourages such artifacts, producing extra sturdy and dependable outputs.
- Sturdy generalization to new decide standards
Once we evaluated RFT fashions utilizing a modified decide immediate (aligned however not equivalent to the coaching reward operate), efficiency remained sturdy. This demonstrates that RFT learns generalizable high quality patterns relatively than overfitting particular analysis standards. This can be a crucial benefit for real-world deployment the place necessities evolve.
- Compute concerns
RFT required 4–8 rollouts per coaching pattern, growing compute prices in comparison with SFT. This overhead is amplified when utilizing non-zero reasoning effort settings. Nonetheless, for mission-critical functions the place alignment high quality instantly impacts enterprise outcomes—equivalent to authorized contract assessment, monetary compliance, or healthcare documentation, the efficiency good points justify the extra compute prices.
Conclusion
Reinforcement Advantageous-Tuning (RFT) with LLM-as-a-judge represents a robust method to aligning LLMs for domain-specific functions. As demonstrated in our authorized contract assessment case research, this technique delivers important enhancements over each base fashions and conventional supervised fine-tuning (SFT) approaches, with RFT reaching the very best mixture scores throughout all analysis dimensions. For groups constructing mission-critical AI techniques the place alignment high quality instantly impacts enterprise outcomes, RFT with LLM-as-a-judge provides a compelling path ahead. The methodology’s explainability, flexibility, and superior efficiency make it significantly invaluable for complicated domains like authorized assessment (or Monetary Companies or Healthcare) the place delicate nuances matter.
Organizations contemplating this method ought to begin small—validate their decide design on curated benchmarks, confirm infrastructure resilience, and scale steadily whereas monitoring for reward hacking. With correct implementation, RFT can rework succesful base fashions into extremely specialised, production-ready techniques that persistently ship aligned, reliable outputs.
References:
- Amazon Nova Developer Information for Amazon Nova 2
- Nova Forge SDK- GitHub
- Reinforcement Advantageous-Tuning (RFT) with Amazon Nova fashions
Disclaimer:
The authorized contract assessment use case described on this submit is for technical demonstration functions solely. AI-generated contract evaluation will not be an alternative choice to skilled authorized recommendation. Seek the advice of certified authorized counsel for authorized issues.
Concerning the authors

{kind=link}