


When constructing AI brokers, builders battle with organizing reminiscence throughout periods, which ends up in irrelevant context retrieval and safety vulnerabilities. AI brokers that keep in mind context throughout periods want greater than solely storage. They want organized, retrievable, and safe reminiscence. In Amazon Bedrock AgentCore Reminiscence, namespaces decide how long-term reminiscence data are organized, retrieved, and who can entry them. Getting the namespace design proper is crucial to constructing an efficient reminiscence system.
On this publish, you’ll learn to design namespace hierarchies, select the fitting retrieval patterns, and implement AWS Id and Entry Administration (IAM)-based entry management for AgentCore Reminiscence. If you happen to’re new to AgentCore Reminiscence, we suggest studying our introductory weblog publish first: Amazon Bedrock AgentCore Reminiscence: Constructing context-aware brokers.
What are namespaces?
Namespaces are hierarchical paths that manage long-term reminiscence data inside an AgentCore Reminiscence useful resource. Consider them like listing paths in a file system. They supply logical construction, allow scoped retrieval, and assist entry management.
When AgentCore Reminiscence extracts long-term reminiscence data out of your conversations, every reminiscence report is saved below a namespace. For instance, a consumer’s preferences may stay below /actor/customer-123/preferences/, whereas their session summaries is likely to be saved at /actor/customer-123/session/session-789/abstract/. With this construction, you’ll be able to retrieve reminiscence data at precisely the fitting degree of granularity.
If you happen to’ve labored with partition keys in Amazon DynamoDB or folder constructions in Amazon Easy Storage Service (Amazon S3), the psychological mannequin transfers properly. Simply as you assume by means of entry patterns earlier than selecting a partition key or designing your S3 folder hierarchy, you must assume by means of your retrieval patterns earlier than designing your namespace construction. Decide:
- Who must entry these recollections: A single consumer? All customers of an agent?
- Granularity of retrieval you want: Is it per-session summaries? Cross-session preferences?
- Isolation boundaries that matter: Ought to one consumer’s recollections ever be seen to a different? Agent-scoped recollections?
The principle distinction from a partition secret is that namespaces assist hierarchical retrieval along with actual match. You possibly can question at every degree of the hierarchy, not solely on the leaf degree. You should use a well-designed namespace to retrieve recollections scoped to a single session, a single consumer throughout periods, or a broader grouping, from the identical reminiscence useful resource. Namespaces are logical groupings inside the similar underlying storage. They supply organizational construction and entry management, however long-term reminiscence data throughout completely different namespaces co-exist inside the similar reminiscence useful resource. Your hierarchy is your major device for organizing knowledge for efficient retrieval patterns.
Namespace templates and backbone
When making a reminiscence useful resource, you outline namespace templates utilizing the namespaceTemplate discipline inside every technique configuration. Templates assist three pre-defined variables:
{actorId}– resolves to the actor identifier from the occasions being processed{sessionId}– resolves to the session identifier from the occasions{memoryStrategyId}– resolves to the technique identifier
Right here’s an instance of making a reminiscence useful resource with namespace templates:
When occasions arrive for actorId=customer-456 in sessionId=session-789, the resolved namespaces change into:
/actor/customer-456/details//actor/customer-456/session/session-789/abstract/
Namespace design per reminiscence technique
Every reminiscence technique has completely different scoping wants, and the namespace design ought to replicate how that knowledge can be accessed. Beneath are some frequent namespace design patterns for various reminiscence methods.
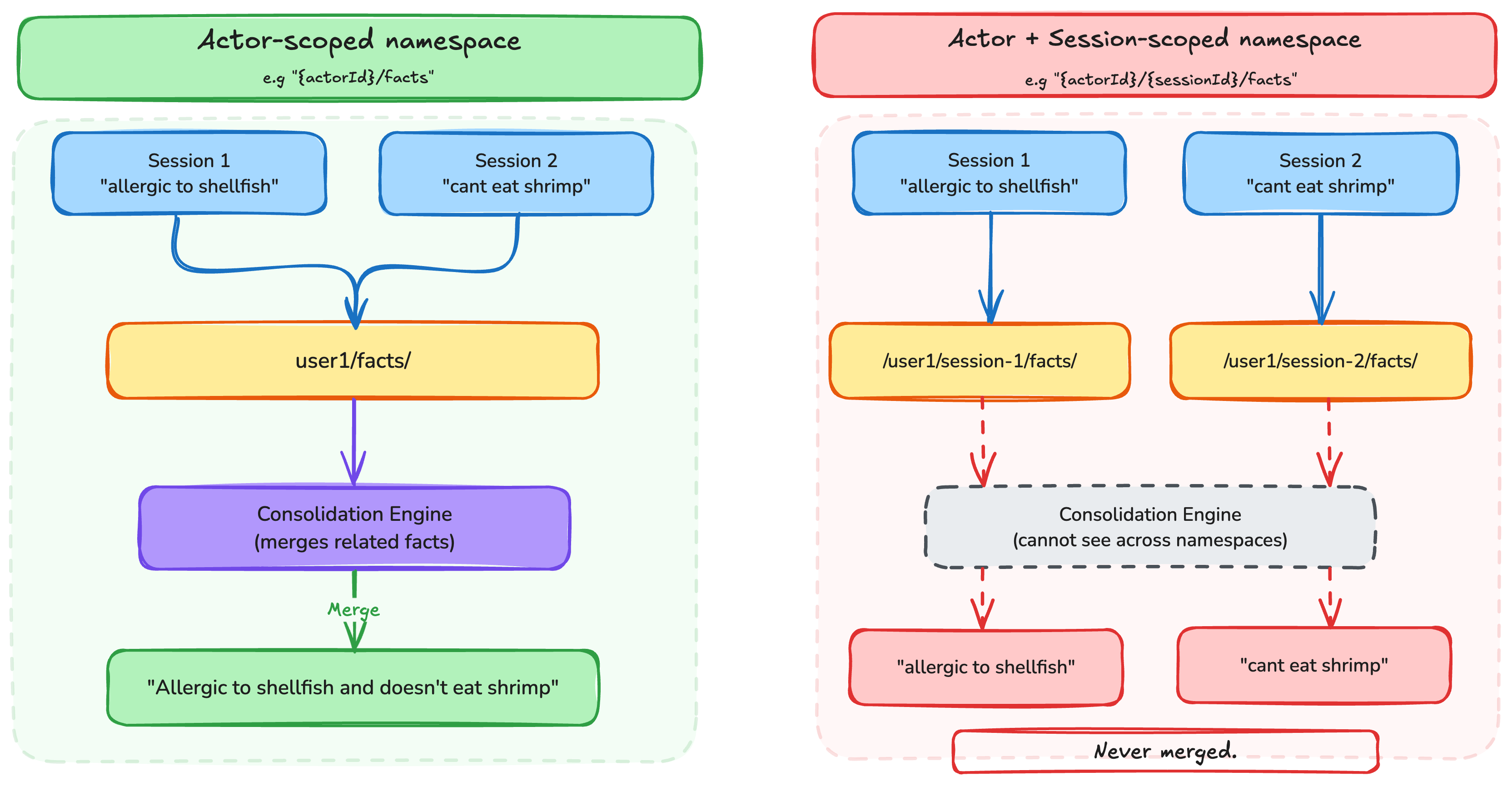
1. Semantic and consumer preferences: Actor-scoped
Semantic reminiscence captures details and data from conversations (for instance, “The client’s firm has 500 staff”). Consumer Desire Reminiscence captures decisions and kinds (for instance, “Consumer prefers Python for improvement work”). Each reminiscence varieties accumulate over time and are related throughout periods. A truth realized in January ought to nonetheless be retrievable in March. For these methods, scope the namespace to the actor:
This implies the details and preferences for a given consumer are consolidated below a single namespace, no matter which session they have been extracted from. The consolidation engine merges associated recollections inside the similar namespace. Take a look at determine 1 for an instance of how scoping impacts the consolidation logic.
The next diagram illustrates how actor-scoped semantic and choice recollections are organized:
In some use circumstances, an admin may have to retrieve info throughout actors whereas protecting recollections organized per actor. For instance, a buyer assist agent may have to lookup identified points reported by different clients, or a gross sales agent may want to seek out related buyer profiles throughout its consumer base. For such circumstances, construction the namespace with the actor identifier as a baby of the reminiscence sort quite than because the dad or mum:
With this inverted construction, you should use namespacePath="/customer-issues/" to retrieve frequent points raised throughout all clients, whereas nonetheless sustaining a per-actor group. A question scoped to namespace="/customer-issues/customer-123/" returns solely that actor’s reported points, preserving isolation when wanted.
2. Abstract: Session-scoped
Abstract reminiscence creates working narratives of conversations, capturing details and selections. As a substitute of feeding a whole dialog historical past into the big language mannequin’s (LLM) context window, you’ll be able to retrieve a compact abstract that preserves the important thing info whereas considerably lowering token utilization. As a result of summaries are inherently tied to a selected dialog, they need to embody the session identifier:/actor/{actorId}/session/{sessionId}/abstract/This scoping signifies that every session will get its personal abstract, whereas nonetheless being organized below the actor for cross-session retrieval when wanted.
3. Episodic: Session-scoped with reflection hierarchy
Episodic reminiscence captures full reasoning traces, together with the aim, steps taken, outcomes, and reflections. As a result of every episode represents what occurred throughout a selected interplay, episodes needs to be scoped to the session, much like summaries. For instance, a flight reserving agent may retailer an episode capturing the way it looked for flights, in contrast choices, dealt with a fare class restriction, and finally rebooked the client on an alternate route. That episode belongs to the session the place it occurred. Reflections are cross-episode insights saved at a dad or mum degree. They generalize learnings throughout periods, as an illustration “when a fare class restriction blocks a modification, instantly seek for different flights quite than simply explaining the coverage.” The namespace for reflections should be a sub-path of the namespace for episodes:
Retrieval patterns
Retrieval APIs
AgentCore Reminiscence gives three major retrieval APIs for long-term reminiscence, every suited to completely different entry patterns. Selecting the best one is essential to constructing efficient brokers.
1. Semantic search with RetrieveMemoryRecords
Use RetrieveMemoryRecords to seek out recollections which might be semantically related to a question. That is the first retrieval technique throughout agent interactions, surfacing essentially the most related recollections based mostly on that means, quite than actual textual content matching.
The search question can come from two sources:
- Straight from the consumer question – Move the consumer’s query as-is when it naturally maps to the type of info saved in reminiscence. For instance, if the consumer asks “What’s my price range?”, that question works properly for retrieving choice or truth recollections.
- LLM-generated question – For extra complicated eventualities, have your agent’s LLM formulate a focused search question. That is helpful when the consumer’s uncooked enter doesn’t immediately map to saved recollections. For instance, if the consumer says “Assist me plan my subsequent journey,” the LLM may generate a search question like “journey preferences, vacation spot historical past, price range constraints” to retrieve essentially the most related recollections. Word that this provides latency.
2. Direct retrieval with ListMemoryRecords
Use ListMemoryRecords when you should enumerate recollections inside a selected namespace comparable to, displaying a consumer’s saved preferences in a console UI, auditing what recollections exist, or performing bulk operations.
3. GetMemoryRecord and DeleteMemoryRecord
When you understand the precise reminiscence report ID (for instance, from a earlier record or retrieve name), use GetMemoryRecord for direct lookup or DeleteMemoryRecord to take away a selected reminiscence:
These are helpful for reminiscence administration workflows which might be used to assist customers view, appropriate, or delete particular recollections by means of your utility’s UI.
Namespace vs. NamespacePath: Precise match vs. hierarchical retrieval
AgentCore Reminiscence gives two distinct fields for scoping retrieval, and understanding the distinction is important for proper conduct.
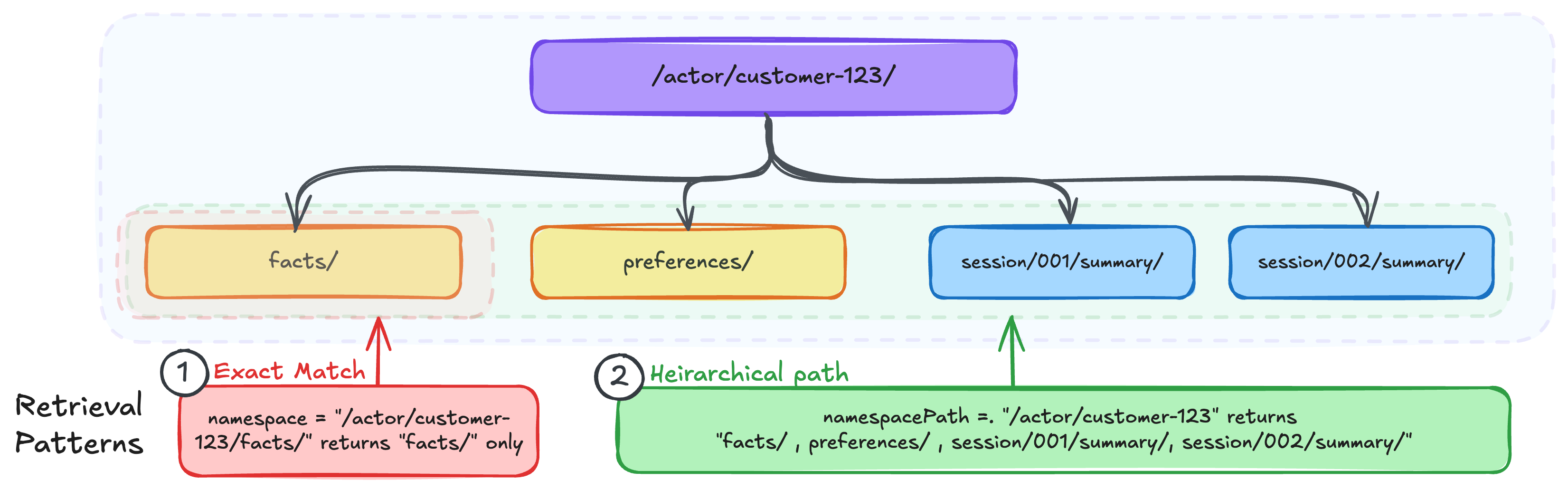
1. namespace — Precise match
The namespace discipline performs an actual match. It returns solely reminiscence data saved at that exact namespace path.
That is the fitting alternative when you understand precisely which namespace you wish to question and wish exact scoping. For instance, retrieving solely a consumer’s preferences with out pulling of their details or summaries.
2. namespacePath — Hierarchical retrieval
The namespacePath discipline performs a hierarchical match, returning the reminiscence data whose namespace falls below the required path.
That is helpful if you wish to search throughout the consumer’s recollections no matter sort, or when constructing options like “present me every part we find out about this buyer.” Word that it’s necessary that you simply assume by means of your isolation and retrieval patterns to make it possible for tree traversal doesn’t expose unintended knowledge.
When to make use of which
| State of affairs | API | Subject | Instance | |
| 1 | Retrieve semantically related consumer preferences | RetrieveMemoryRecords | namespace | /actor/customer-123/preferences/ |
| 2 | Retrieve a selected session abstract | ListMemoryRecords | namespace | /actor/customer-123/session/session-001/abstract/ |
| 3 | Checklist all preferences for a consumer | ListMemoryRecords | namespace | /actor/customer-123/preferences/ |
| 4 | Search throughout a consumer’s recollections | RetrieveMemoryRecords | namespacePath | /actor/customer-123/ |
| 5 | Checklist summaries throughout periods for a consumer | ListMemoryRecords | namespacePath | /actor/customer-123/session/ |
Writing IAM insurance policies for namespace entry management
Namespaces combine with AWS Id and Entry Administration (IAM) by means of situation keys that prohibit which namespaces a principal can embody of their Reminiscence API requests.
1. Precise match insurance policies
Use StringEquals with the bedrock-agentcore:namespace situation key to limit entry to a selected namespace:
This coverage makes certain {that a} consumer can solely retrieve recollections from their very own preferences namespace, utilizing the userId principal tag (injected) for dynamic scoping.
2. Hierarchical retrieval insurance policies
Use StringLike with the bedrock-agentcore:namespacePath situation key for hierarchical entry:
With this, a consumer can carry out hierarchical retrieval throughout their namespaces (details, preferences, summaries) whereas serving to forestall entry to different customers’ knowledge.
Conclusion
Namespace design is foundational to constructing efficient reminiscence methods with AgentCore Reminiscence. Very like designing a key schema for a database or a prefix construction in object storage, pondering by means of your entry patterns upfront helps you create a namespace hierarchy that helps exact retrieval, clear isolation between customers, and IAM-based entry management.The important thing takeaways:
- Suppose by means of your entry patterns and isolation boundaries earlier than developing with namespace templates
- Scope semantic and choice recollections to the actor (
/actor/{actorId}/) for cross-session consolidation - Scope summaries to the session (
/actor/{actorId}/session/{sessionId}/) since they’re conversation-specific (the place wanted comparable to summaries or episodes) - Use
namespacefor actual match when you understand the exact path, andnamespacePathfor hierarchical retrieval when you should search throughout a subtree - Use main and trailing slashes in namespace paths to maintain them constant and assist forestall prefix collisions
- Use IAM situation keys (
bedrock-agentcore:namespaceandbedrock-agentcore:namespacePath) to manage what namespaces might be requested
To get began, go to the next sources:
In regards to the authors

{kind=link}
{kind=link}