


Graph databases have revolutionized how organizations handle complicated, interconnected knowledge. Nonetheless, specialised question languages resembling Gremlin typically create a barrier for groups trying to extract insights effectively. Not like conventional relational databases with well-defined schemas, graph databases lack a centralized schema, requiring deep technical experience for efficient querying.
To handle this problem, we discover an method that converts pure language to Gremlin queries, utilizing Amazon Bedrock fashions resembling Amazon Nova Professional. This method helps enterprise analysts, knowledge scientists, and different non-technical customers entry and work together with graph databases seamlessly.
On this submit, we define our methodology for producing Gremlin queries from pure language, evaluating completely different strategies and demonstrating methods to consider the effectiveness of those generated queries utilizing giant language fashions (LLMs) as judges.
Answer overview
Reworking pure language queries into Gremlin queries requires a deep understanding of graph constructions and the domain-specific information encapsulated throughout the graph database. To attain this, we divided our method into three key steps:
- Understanding and extracting graph information
- Structuring the graph just like text-to-SQL processing
- Producing and executing Gremlin queries
The next diagram illustrates this workflow.
Step 1: Extract graph information
A profitable question technology framework should combine each graph information and area information to precisely translate pure language queries. Graph information encompasses structural and semantic info extracted instantly from the graph database. Particularly, it consists of:
- Vertex labels and properties – A list of vertex sorts, names, and their related attributes
- Edge labels and properties – Details about edge sorts and their attributes
- One-hop neighbors for every vertex – Capturing native connectivity info, resembling direct relationships between vertices
With this graph-specific information, the framework can successfully cause in regards to the heterogeneous properties and sophisticated connections inherent to graph databases.
Area information captures extra context that augments the graph information and is tailor-made particularly to the applying area. It’s sourced in two methods:
- Buyer-provided area information – For instance, the client kscope.ai helped specify these vertices that characterize metadata and may by no means be queried. Such constraints are encoded to information the question technology course of.
- LLM-generated descriptions – To reinforce the system’s understanding of vertex labels and their relevance to particular questions, we use an LLM to generate detailed semantic descriptions of vertex names, properties, and edges. These descriptions are saved throughout the area information repository and supply extra context to enhance the relevance of the generated queries.
Step 2: Construction the graph as a text-to-SQL schema
To enhance the mannequin’s comprehension of graph constructions, we undertake an method just like text-to-SQL processing, the place we assemble a schema representing vertex sorts, edges, and properties. This structured illustration enhances the mannequin’s potential to interpret and generate significant queries.
The query processing part transforms pure language enter into structured parts for question technology. It operates in three levels:
- Entity recognition and classification – Identifies key database parts within the enter query (resembling vertices, edges, and properties) and categorizes the query primarily based on its intent
- Context enhancement – Enriches the query with related info from the information part, so each graph-specific and domain-specific context is correctly captured
- Question planning – Maps the improved query to particular database parts wanted for question execution
The context technology part makes certain the generated queries precisely replicate the underlying graph construction by assembling the next:
- Ingredient properties – Retrieves attributes of vertices and edges together with their knowledge sorts
- Graph construction – Facilitates alignment with the database’s topology
- Area guidelines – Applies enterprise constraints and logic
Step 3: Generate and execute Gremlin queries
The ultimate step is question technology, the place the LLM constructs a Gremlin question primarily based on the extracted context. The method follows these steps:
- The LLM generates an preliminary Gremlin question.
- The question is executed inside a Gremlin engine.
- If the execution is profitable, outcomes are returned.
- If execution fails, an error message parsing mechanism analyzes the returned errors and refines the question utilizing LLM-based suggestions.
This iterative refinement makes certain the generated queries align with the database’s construction and constraints, enhancing total accuracy and value.
Immediate template
Our last immediate template is as follows:
Evaluating LLM-generated queries to floor fact
We applied an LLM-based analysis system utilizing Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock as a choose to evaluate each question technology and execution outcomes for Amazon Nova Professional and a benchmark mannequin. The system operates in two key areas:
- Question analysis – Assesses correctness, effectivity, and similarity to ground-truth queries; calculates precise matching part percentages; and gives an total score primarily based on predefined guidelines developed with area consultants
- Execution analysis – Initially used a single-stage method to match generated outcomes with floor fact, then enhanced to a two-stage analysis course of:
- Merchandise-by-item verification towards floor fact
- Calculation of total match proportion
Testing throughout 120 questions demonstrated the framework’s potential to successfully distinguish right from incorrect queries. The 2-stage method significantly improved the reliability of execution end result analysis by conducting thorough comparability earlier than scoring.
Experiments and outcomes
On this part, we focus on the experiments we performed and their outcomes.
Question similarity
Within the question analysis case, we suggest two metrics: question precise match and question total score. An actual match rating is calculated by figuring out matching vs. non-matching parts between generated and floor fact queries. The next desk summarizes the scores for question precise match.
| Straightforward | Medium | Laborious | Total | |
| Amazon Nova Professional | 82.70% | 61% | 46.60% | 70.36% |
| Benchmark Mannequin | 92.60% | 68.70% | 56.20% | 78.93% |
An total score is supplied after contemplating components together with question correctness, effectivity, and completeness as instructed within the immediate. The general score is on scale 1–10. The next desk summarizes the scores for question total score.
| Straightforward | Medium | Laborious | Total | |
| Amazon Nova Professional | 8.7 | 7 | 5.3 | 7.6 |
| Benchmark Mannequin | 9.7 | 8 | 6.1 | 8.5 |
One limitation within the present question analysis setup is that we rely solely on the LLM’s potential to match floor fact towards LLM-generated queries and arrive on the last scores. In consequence, the LLM can fail to align with human preferences and under- or over-penalize the generated question. To handle this, we advocate working with an issue professional to incorporate domain-specific guidelines within the analysis immediate.
Execution accuracy
To calculate accuracy, we evaluate the outcomes of the LLM-generated Gremlin queries towards the outcomes of floor fact queries. If the outcomes from each queries match precisely, we depend the occasion as right; in any other case, it’s thought of incorrect. Accuracy is then computed because the ratio of right question executions to the full variety of queries examined. This metric gives a simple analysis of how properly the model-generated queries retrieve the anticipated info from the graph database, facilitating alignment with the supposed question logic.
The next desk summarizes the scores for execution outcomes depend match.
| Straightforward | Medium | Laborious | Total | |
| Amazon Nova Professional | 80% | 50% | 10% | 60.42% |
| Benchmark Mannequin | 90% | 70% | 30% | 74.83% |
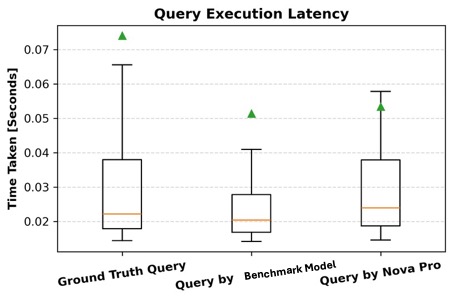
Question execution latency
Along with accuracy, we consider the effectivity of generated queries by measuring their runtime and evaluating it with the bottom fact queries. For every question, we file the runtime in milliseconds and analyze the distinction between the generated question and the corresponding floor fact question. A decrease runtime signifies a extra optimized question, whereas vital deviations would possibly counsel inefficiencies in question construction or execution planning. By contemplating each accuracy and runtime, we achieve a extra complete evaluation of question high quality, ensuring the generated queries are right and performant throughout the graph database. The next field plot showcases question execution latency with respect to time for the bottom fact question and the question generated by Amazon Nova Professional. As illustrated, all three varieties of queries exhibit comparable runtimes, with comparable median latencies and overlapping interquartile ranges. Though the bottom fact queries show a barely wider vary and a better outlier, the median values throughout all three teams stay shut. This means that the model-generated queries are on the similar stage as human-written ones when it comes to execution effectivity, supporting the declare that AI-generated queries are of comparable high quality and don’t incur extra latency overhead.
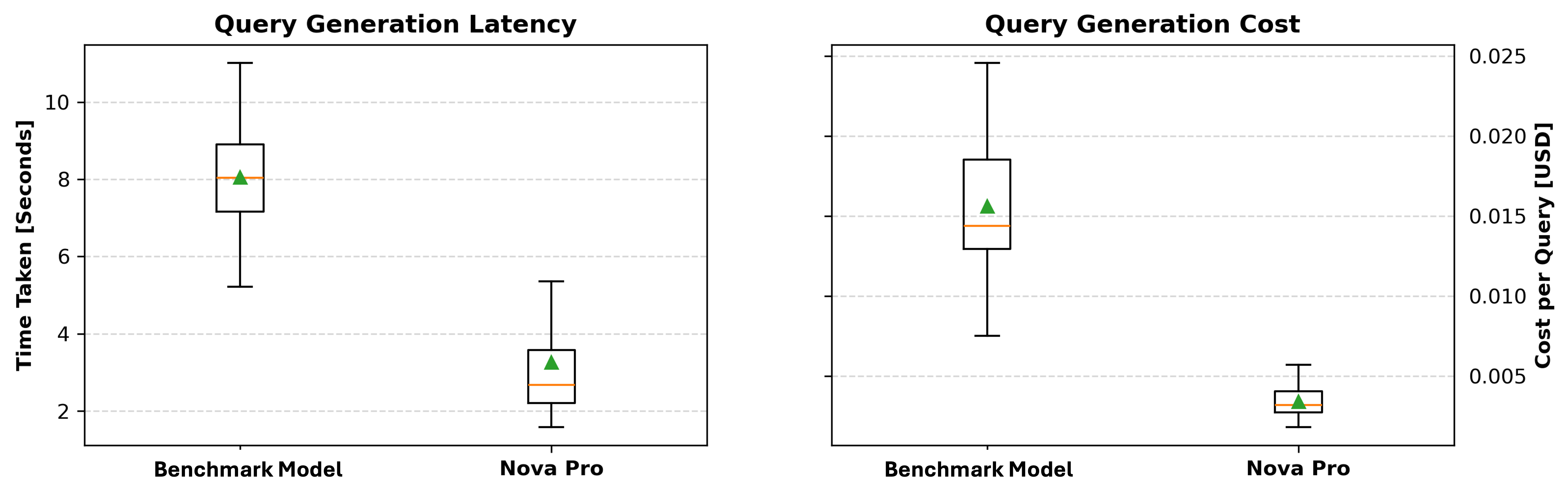
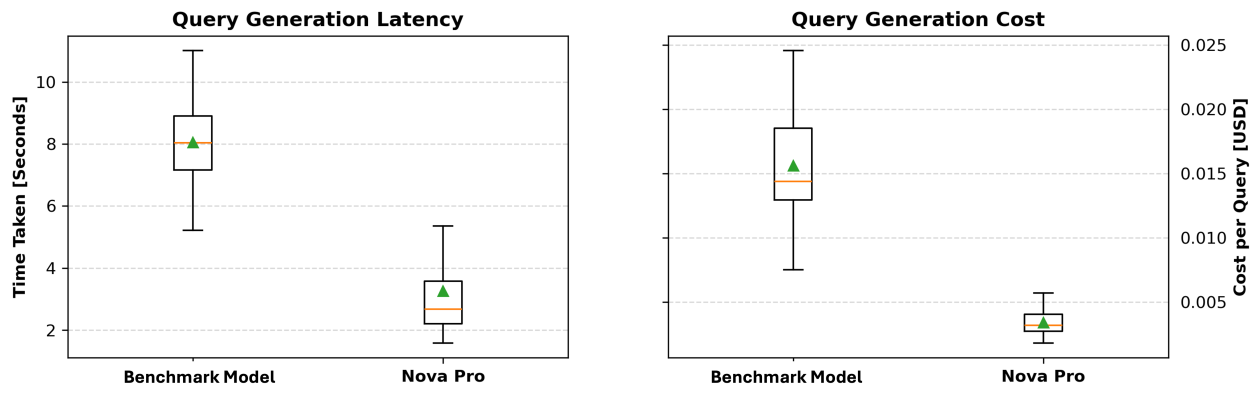
Question technology latency and value
Lastly, we evaluate the time taken to generate every question and calculate the associated fee primarily based on token consumption. Extra particularly, we measure the question technology time and monitor the variety of tokens used, as a result of most LLM-based APIs cost primarily based on token utilization. By analyzing each the technology pace and token price, we are able to decide whether or not the mannequin is environment friendly and cost-effective. These outcomes present insights in deciding on the optimum mannequin that balances question accuracy, execution effectivity, and financial feasibility.
As proven within the following plots, Amazon Nova Professional persistently outperforms the benchmark mannequin in each technology latency and value. Within the left plot, which depicts question technology latency, Amazon Nova Professional demonstrates a considerably decrease median technology time, with most values clustered between 1.8–4 seconds, in comparison with the benchmark mannequin’s broader vary from round 5–11 seconds. The appropriate plot, illustrating question technology price, reveals that Amazon Nova Professional maintains a a lot smaller price per question—centered properly beneath $0.005—whereas the benchmark mannequin incurs greater and extra variable prices, reaching as much as $0.025 in some instances. These outcomes spotlight Amazon Nova Professional’s benefit when it comes to each pace and affordability, making it a robust candidate for deployment in time-sensitive or large-scale methods.
Conclusion
We experimented with all 120 floor fact queries supplied to us by kscope.ai and achieved an total accuracy of 74.17% in producing right outcomes. The proposed framework demonstrates its potential by successfully addressing the distinctive challenges of graph question technology, together with dealing with heterogeneous vertex and edge properties, reasoning over complicated graph constructions, and incorporating area information. Key parts of the framework, resembling the combination of graph and area information, the usage of Retrieval Augmented Technology (RAG) for question plan creation, and the iterative error-handling mechanism for question refinement, have been instrumental in reaching this efficiency.
Along with enhancing accuracy, we’re actively engaged on a number of enhancements. These embrace refining the analysis methodology to deal with deeply nested question outcomes extra successfully and additional optimizing the usage of LLMs for question technology. Furthermore, we’re utilizing the RAGAS-faithfulness metric to enhance the automated analysis of question outcomes, leading to higher reliability and consistency in assessing the framework’s outputs.
In regards to the authors
 Mengdie (Flora) Wang is a Knowledge Scientist at AWS Generative AI Innovation Middle, the place she works with clients to architect and implement scalable Generative AI options that deal with their distinctive enterprise challenges. She makes a speciality of mannequin customization strategies and agent-based AI methods, serving to organizations harness the complete potential of generative AI expertise. Previous to AWS, Flora earned her Grasp’s diploma in Pc Science from the College of Minnesota, the place she developed her experience in machine studying and synthetic intelligence.
Mengdie (Flora) Wang is a Knowledge Scientist at AWS Generative AI Innovation Middle, the place she works with clients to architect and implement scalable Generative AI options that deal with their distinctive enterprise challenges. She makes a speciality of mannequin customization strategies and agent-based AI methods, serving to organizations harness the complete potential of generative AI expertise. Previous to AWS, Flora earned her Grasp’s diploma in Pc Science from the College of Minnesota, the place she developed her experience in machine studying and synthetic intelligence.
 Jason Zhang has experience in machine studying, reinforcement studying, and generative AI. He earned his Ph.D. in Mechanical Engineering in 2014, the place his analysis centered on making use of reinforcement studying to real-time optimum management issues. He started his profession at Tesla, making use of machine studying to car diagnostics, then superior NLP analysis at Apple and Amazon Alexa. At AWS, he labored as a Senior Knowledge Scientist on generative AI options for patrons.
Jason Zhang has experience in machine studying, reinforcement studying, and generative AI. He earned his Ph.D. in Mechanical Engineering in 2014, the place his analysis centered on making use of reinforcement studying to real-time optimum management issues. He started his profession at Tesla, making use of machine studying to car diagnostics, then superior NLP analysis at Apple and Amazon Alexa. At AWS, he labored as a Senior Knowledge Scientist on generative AI options for patrons.
 Rachel Hanspal is a Deep Studying Architect at AWS Generative AI Innovation Middle, specializing in end-to-end GenAI options with a deal with frontend structure and LLM integration. She excels in translating complicated enterprise necessities into progressive functions, leveraging experience in pure language processing, automated visualization, and safe cloud architectures.
Rachel Hanspal is a Deep Studying Architect at AWS Generative AI Innovation Middle, specializing in end-to-end GenAI options with a deal with frontend structure and LLM integration. She excels in translating complicated enterprise necessities into progressive functions, leveraging experience in pure language processing, automated visualization, and safe cloud architectures.
 Zubair Nabi is the CTO and Co-Founding father of Kscope, an Built-in Safety Posture Administration (ISPM) platform. His experience lies on the intersection of Large Knowledge, Machine Studying, and Distributed Techniques, with over a decade of expertise constructing software program, knowledge, and AI platforms. Zubair can be an adjunct school member at George Washington College and the writer of Professional Spark Streaming: The Zen of Actual-Time Analytics Utilizing Apache Spark. He holds an MPhil from the College of Cambridge.
Zubair Nabi is the CTO and Co-Founding father of Kscope, an Built-in Safety Posture Administration (ISPM) platform. His experience lies on the intersection of Large Knowledge, Machine Studying, and Distributed Techniques, with over a decade of expertise constructing software program, knowledge, and AI platforms. Zubair can be an adjunct school member at George Washington College and the writer of Professional Spark Streaming: The Zen of Actual-Time Analytics Utilizing Apache Spark. He holds an MPhil from the College of Cambridge.
 Suparna Pal – CEO & Co-Founding father of kscope.ai – 20+ years of journey of constructing progressive platforms & options for Industrial, Well being Care and IT operations at PTC, GE, and Cisco.
Suparna Pal – CEO & Co-Founding father of kscope.ai – 20+ years of journey of constructing progressive platforms & options for Industrial, Well being Care and IT operations at PTC, GE, and Cisco.
 Wan Chen is an Utilized Science Supervisor at AWS Generative AI Innovation Middle. As a ML/AI veteran in tech business, she has big selection of experience on conventional machine studying, recommender system, deep studying and Generative AI. She is a stronger believer of Superintelligence and may be very passionate to push the boundary of AI analysis and utility to reinforce human life and drive enterprise progress. She holds Ph.D in Utilized Arithmetic from College of British Columbia and had labored as postdoctoral fellow in Oxford College.
Wan Chen is an Utilized Science Supervisor at AWS Generative AI Innovation Middle. As a ML/AI veteran in tech business, she has big selection of experience on conventional machine studying, recommender system, deep studying and Generative AI. She is a stronger believer of Superintelligence and may be very passionate to push the boundary of AI analysis and utility to reinforce human life and drive enterprise progress. She holds Ph.D in Utilized Arithmetic from College of British Columbia and had labored as postdoctoral fellow in Oxford College.
 Mu Li is a Principal Options Architect with AWS Vitality. He’s additionally the Worldwide Tech Chief for the AWS Vitality & Utilities Technical Area Neighborhood (TFC), a neighborhood of 300+ business and technical consultants. Li is keen about working with clients to attain enterprise outcomes utilizing expertise. Li has labored with clients emigrate all-in to AWS from on-prem and Azure, launch the Manufacturing Monitoring and Surveillance business resolution, deploy ION/OpenLink Endur on AWS, and implement AWS-based IoT and machine studying workloads. Exterior of labor, Li enjoys spending time along with his household, investing, following Houston sports activities groups, and catching up on enterprise and expertise.
Mu Li is a Principal Options Architect with AWS Vitality. He’s additionally the Worldwide Tech Chief for the AWS Vitality & Utilities Technical Area Neighborhood (TFC), a neighborhood of 300+ business and technical consultants. Li is keen about working with clients to attain enterprise outcomes utilizing expertise. Li has labored with clients emigrate all-in to AWS from on-prem and Azure, launch the Manufacturing Monitoring and Surveillance business resolution, deploy ION/OpenLink Endur on AWS, and implement AWS-based IoT and machine studying workloads. Exterior of labor, Li enjoys spending time along with his household, investing, following Houston sports activities groups, and catching up on enterprise and expertise.

{kind=link}