


At AWS, we’re reworking our vendor and buyer journeys by utilizing generative synthetic intelligence (AI) throughout the gross sales lifecycle. We envision a future the place AI seamlessly integrates into our groups’ workflows, automating repetitive duties, offering clever suggestions, and liberating up time for extra strategic, high-value interactions. Our discipline group consists of customer-facing groups (account managers, options architects, specialists) and inside assist capabilities (gross sales operations).
Prospecting, alternative development, and buyer engagement current thrilling alternatives to make the most of generative AI, utilizing historic information, to drive effectivity and effectiveness. Customized content material shall be generated at each step, and collaboration inside account groups shall be seamless with a whole, up-to-date view of the client. Our inside AI gross sales assistant, powered by Amazon Q Enterprise, shall be obtainable throughout each modality and seamlessly combine with methods similar to inside data bases, buyer relationship administration (CRM), and extra. Will probably be in a position to reply questions, generate content material, and facilitate bidirectional interactions, all whereas repeatedly utilizing inside AWS and exterior information to ship well timed, personalised insights.
Via this sequence of posts, we share our generative AI journey and use circumstances, detailing the structure, AWS companies used, classes realized, and the impression of those options on our groups and prospects. On this first publish, we discover Account Summaries, one in all our preliminary manufacturing use circumstances constructed on Amazon Bedrock. Account Summaries equips our groups to be higher ready for buyer engagements. It combines data from numerous sources into complete, on-demand summaries obtainable in our CRM or proactively delivered based mostly on upcoming conferences. From the interval of September 2023 to March 2024, sellers leveraging GenAI Account Summaries noticed a 4.9% improve in worth of alternatives created.
The enterprise alternative
Information typically resides throughout a number of inside methods, similar to CRM and monetary instruments, and exterior sources, making it difficult for account groups to achieve a complete understanding of every buyer. Manually connecting these disparate datasets could be time-consuming, presenting a chance to enhance how we uncover priceless insights and determine alternatives. With out proactive insights and proposals, account groups can miss alternatives and ship inconsistent buyer experiences.
Use case overview
Utilizing generative AI, we constructed Account Summaries by seamlessly integrating each structured and unstructured information from numerous sources. This consists of gross sales collateral, buyer engagements, exterior net information, machine studying (ML) insights, and extra. The result’s a complete abstract tailor-made for our sellers, obtainable on-demand in our CRM and proactively delivered by way of Slack based mostly on upcoming conferences.
Account Summaries supplies a 360-degree account narrative with customizable sections, showcasing well timed and related details about prospects. Key sections embody:
- Government abstract – A concise overview highlighting the most recent buyer updates, superb for fast, high-level briefings.
- Group overview – Evaluation of exterior group and business information together with citations to sources, offering account groups with well timed dialogue subjects and positioning methods.
- Product consumption – Summaries of how prospects are utilizing AWS companies over time.
- Alternative pipeline – Overview of open and stalled alternatives, together with accomplice engagements and up to date buyer interactions.
- Investments and assist – Info on buyer points, promotional applications, assist circumstances, and product function requests.
- AI-driven suggestions – By combining generative AI with ML, we ship clever ideas for merchandise, companies, relevant use circumstances, and subsequent steps. Suggestions embody citations to supply supplies, empowering account groups to extra successfully drive buyer methods.
The next screenshot exhibits a pattern account abstract. All information on this instance abstract is fictitious.
Resolution impression
Since its inception in 2023, greater than 100,000 GenAI Account Summaries have been generated, and AWS sellers report a mean of 35 minutes saved per GenAI Account Abstract. That is boosting productiveness and liberating up time for buyer engagements. The impression goes past simply effectivity. Since its inception in September 2023 up by way of March 2024, roughly one-third of surveyed sellers reported that GenAI Account Summaries had a constructive impression on their strategy to a buyer, and sellers leveraging GenAI Account Summaries noticed a 4.9% improve in worth of alternatives created.
The impression of this use case has been significantly pronounced amongst groups who assist a lot of prospects. Customers similar to specialists who transfer between a number of accounts have seen a dramatic enchancment of their capacity to rapidly perceive and add worth to numerous buyer conditions. Throughout account transitions, they permit new account managers to quickly stand up up to now on inherited accounts. At occasions, our groups now strategy buyer interactions armed with complete, up-to-date data on demand. Account Summaries can also be now foundational to different downstream mechanisms like account planning and government briefing heart (EBC) conferences.
Resolution overview
This illustrates our strategy to implementing generative AI capabilities throughout the gross sales and buyer lifecycle. It’s constructed on numerous information sources and a sturdy infrastructure layer for information retrieval, prompting, and LLM administration. This modular construction supplies a scalable basis for deploying a broad vary of AI-powered use circumstances, starting with Account Summaries.
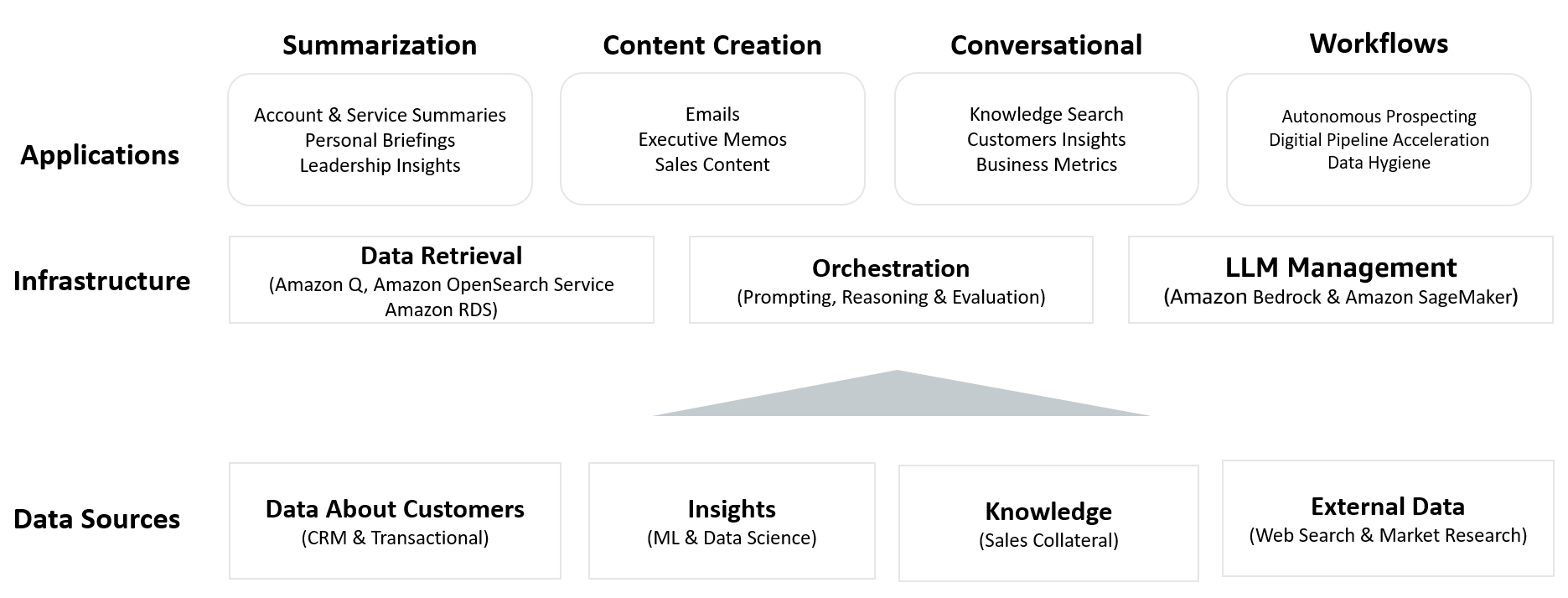
Constructing generative AI options like Account Summaries on AWS affords important technical benefits, significantly for organizations already utilizing AWS companies. You’ll be able to combine current information from AWS information lakes, Amazon Easy Storage Service (Amazon S3) buckets, or Amazon Relational Database Service (Amazon RDS) cases with companies similar to Amazon Bedrock and Amazon Q. For our Account Summaries use case, we use each Amazon Titan and Anthropic Claude fashions on Amazon Bedrock, profiting from their distinctive strengths for various points of abstract technology.
Our strategy to mannequin choice and deployment is each strategic and versatile. We fastidiously select fashions based mostly on their particular capabilities and the necessities of every abstract part. This enables us to optimize for components similar to accuracy, response time, and cost-efficiency. The structure we’ve developed permits seamless mixture and switching between completely different fashions, even inside a single abstract technology course of. This multi-model strategy lets us benefit from one of the best options of every mannequin, leading to extra complete and nuanced summaries.
This versatile mannequin choice and mixture functionality, coupled with our current AWS infrastructure, accelerates time to market, reduces advanced information migrations and potential failure factors, and permits us to repeatedly incorporate state-of-the-art language fashions as they develop into obtainable.
Our system integrates numerous information sources with refined information indexing and retrieval processes, and makes use of fastidiously crafted prompting methods. We’ve additionally applied strong methods to mitigate hallucinations, offering reliability in our generated summaries. Constructed on AWS with asynchronous processing, the answer incorporates a number of high quality assurance measures and is regularly refined by way of a complete suggestions loop, all whereas sustaining stringent safety and privateness requirements.
Within the following sections, we assessment every element, together with information sources, information indexing and retrieval, prompting methods, hallucination mitigation methods, high quality assurance processes, and the underlying infrastructure and operations.
Information sources
Account Summaries depends on 4 key classes of knowledge:
- Information about prospects – Structured details about the client’s AWS journey, together with service metrics, progress tendencies, and assist historical past
- ML insights – Insights generated from analyzing patterns in structured enterprise information and unstructured interplay logs
- Inner data bases – Unstructured information like gross sales performs, case research, and product data, repeatedly up to date to mirror the most recent AWS choices and greatest practices
- Exterior information – Actual-time information, public monetary filings, and business stories to supply a complete understanding of the client’s enterprise panorama
By bringing collectively these numerous information sources, we create a wealthy, multidimensional view of every account that goes past what’s attainable with conventional information evaluation.
To take care of the integrity of our core information, we don’t retain or use the prompts or the ensuing account abstract for mannequin coaching. As an alternative, after a abstract is produced and delivered to the vendor, the generated content material is completely deleted.
Information indexing and retrieval
We begin with indexing and retrieving each structured and unstructured information, which permits us to offer complete summaries that mix quantitative information with qualitative insights.
The indexing course of consists of the next levels:
- Doc preprocessing – Clear and normalize textual content from numerous sources
- Chunking – Break paperwork into manageable items (1,200 tokens with 50-token overlap)
- Vectorization – Convert textual content chunks into vector representations utilizing an embeddings mannequin
- Storage – Index vectors and metadata within the database for fast retrieval
The retrieval course of includes the next levels:
- Question vectorization – Convert consumer queries or context into vector representations
- Similarity search – Use k-nearest neighbors (k-NN) to seek out related doc chunks
- Metadata filtering – Apply extra filters based mostly on structured information (similar to date ranges or product classes)
- Reranking – Use a cross-encoder mannequin to refine the relevance of retrieved chunks
- Context integration – Mix retrieved data with the massive language mannequin (LLM) immediate
The next are key implementation concerns:
- Balancing structured and unstructured information – Utilizing structured information to information and filter searches inside unstructured content material, and mixing quantitative metrics with qualitative insights for complete summaries
- Scalability – Designing our system to deal with rising volumes of information and concurrent requests, and contemplating partitioning methods for our rising vector database
- Sustaining information freshness – Implementing methods to often replace our index with new data and thought of real-time indexing for vital, fast-changing information factors
- Steady relevance tuning – Ongoing refinement of our retrieval course of based mostly on consumer suggestions and efficiency metrics, and experimentation with completely different embedding fashions and similarity measures
- Privateness and safety – Utilizing row-level safety entry controls to restrict consumer entry to data
By thoughtfully implementing this indexing and retrieval system, we’ve created a strong basis for Account Summaries. This strategy permits us to dynamically mix structured inside enterprise information with related unstructured content material, offering our discipline groups with complete, up-to-date, and context-rich summaries for each buyer engagement.
Prompting
Nicely-crafted prompts improve the accuracy and relevance of generated responses, scale back hallucinations, and permit for personalisation based mostly on particular use circumstances. Finally, prompting serves because the vital interface that makes certain Retrieval Augmented Technology (RAG) methods produce coherent, factual, and tailor-made outputs by successfully utilizing each saved data and the capabilities of LLMs. Prompting performs a vital function in RAG methods by bridging the hole between retrieved data and consumer intent. It guides the retrieval course of, contextualizes the fetched information, and instructs the language mannequin on the best way to use this data successfully.
The next diagram illustrates the prompting framework for Account Summaries, which begins by gathering information from numerous sources. This data is used to construct a immediate with related context after which fed into an LLM, which generates a response. The ultimate output is a response tailor-made to the enter information and refined by way of iteration.
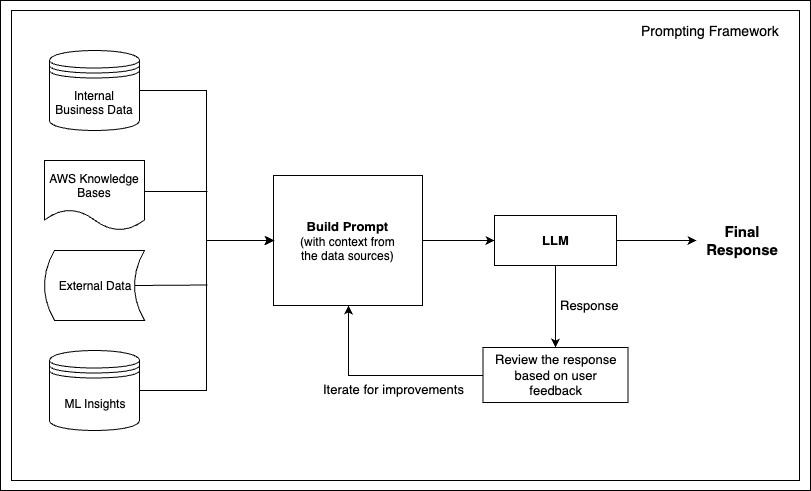
We arrange our prompting greatest practices into two most important classes:
- Content material and construction:
- Constraint specification – Outline content material, tone, and format constraints related to AWS gross sales contexts. For instance, “Present a abstract that excludes delicate monetary information and maintains a proper tone.”
- Use of delimiters – Make use of XML tags to separate directions, context, and technology areas. For instance, <directions> Please summarize the important thing factors from the next passage: </directions> <information> [Insert passage here] </information>.
- Modular prompts – Break up prompts into section-specific chunks for enhanced accuracy and lowered latency, as a result of it permits the LLM to deal with a smaller context at a time. For instance, “Separate prompts for government abstract and alternative pipeline sections.”
- Position context – Begin every immediate with a transparent function definition. For instance, “You might be an AWS Account Supervisor getting ready for a buyer assembly.”
- Language and tone:
- Skilled framing – Use well mannered, skilled language in prompts. For instance, “Please present a concise abstract of the client’s cloud adoption journey.”
- Particular directives – Embrace unambiguous directions. For instance, “Summarize in a single paragraph” quite than “Present a brief abstract.”
- Constructive framing – Body directions positively. For instance, “Write knowledgeable electronic mail” as a substitute of “Don’t be unprofessional.”
- Clear restrictions – Specify necessary limitations upfront. For instance, “Reply with out speculating or guessing. Don’t make up any statistics.”
Think about the next system design and optimization methods:
- Architectural concerns:
- Multi-stage prompting – Use preliminary prompts for information retrieval, adopted by particular prompts for abstract technology.
- Dynamic templates – Adapt immediate templates based mostly on retrieved buyer data.
- Mannequin choice – Steadiness efficiency with value, selecting acceptable fashions for various abstract sections.
- Asynchronous processing – Run LLM calls for various abstract sections in parallel to scale back general latency.
- High quality and enchancment:
- Output validation – Implement rigorous fact-checking earlier than counting on generated summaries. For instance, “Cross-reference generated figures with golden supply enterprise information.”
- Consistency checks – Be sure that directions don’t contradict one another or the offered information. For instance, “Overview prompts to make sure we’re not asking for detailed financials whereas additionally instructing to exclude delicate information.”
- Step-by-step considering – For advanced summaries, instruct the mannequin to assume by way of steps to scale back hallucinations.
- Suggestions and iteration – Repeatedly analyze efficiency, collect consumer suggestions, experiment, and iteratively enhance prompts and processes.
Multi-model strategy
Though crafting efficient prompts is essential, equally necessary is choosing the proper fashions to course of these prompts and generate correct, related summaries. Our multi-model strategy is essential to reaching this purpose. By utilizing a number of fashions, particularly Amazon Titan and Anthropic Claude on Amazon Bedrock, we’re in a position to optimize numerous points of abstract technology, leading to extra complete, correct, and tailor-made outputs.
The collection of acceptable fashions for various duties is guided by a number of key standards. First, we consider the particular capabilities of every mannequin, taking a look at their distinctive strengths in dealing with sure kinds of queries or information. Subsequent, we assess the mannequin’s accuracy, which is its capacity to generate factual and related content material. And lastly, we contemplate pace and value, that are additionally essential components.
Our structure is designed to permit for versatile mannequin switching and mixture. That is achieved by way of a modular strategy the place every part of the abstract could be generated independently after which mixed right into a cohesive complete. With steady efficiency monitoring and suggestions mechanisms in place, we’re in a position to refine our mannequin choice and prompting methods over time.
As new fashions develop into obtainable on Amazon Bedrock, we’ve got a structured analysis course of in place. This includes benchmarking new fashions in opposition to our present choices throughout numerous metrics, operating A/B assessments, and progressively incorporating high-performing fashions into our manufacturing pipeline.
Mitigating hallucinations and implementing high quality
LLMs generally hallucinate as a result of they optimize for probably the most possible textual content response to a immediate, balancing numerous parts like syntax, grammar, fashion, data, reasoning, and emotion. This typically results in trade-offs, ensuing within the insertion of invented information, making the outputs appear convincing however inaccurate. We applied a number of methods to handle widespread kinds of hallucinations:
- Incomplete information difficulty – LLMs could invent data when missing needed context.
- Resolution – We offer complete datasets and express directions to make use of solely offered data. We additionally preprocess information to take away null factors and embody conditional directions for obtainable information factors.
- Imprecise directions difficulty – Ambiguous prompts can result in guesswork and hallucinations.
- Resolution – We use detailed, particular prompts with clear and structured directions to attenuate ambiguity.
- Ambiguous context difficulty – Unclear context can lead to believable however inaccurate particulars.
- Resolution – We make clear context in prompts, specifying actual particulars required and utilizing XML tags to tell apart between context, duties, and directions.
We deployed a multi-faceted strategy to offer high quality and accuracy with Account Summaries:
- Automated metrics – These automated metrics present a quantitative basis for our high quality assurance course of, permitting us to rapidly determine potential points in generated summaries earlier than they bear human assessment:
- Cosine similarity – Measures the similarity between the enter dataset and the generated response by calculating the cosine of the angle between their vector representations. This helps make sure that the abstract content material aligns carefully with the enter information.
- BLEU (Bilingual Analysis Understudy) – Evaluates the standard of the response by calculating what number of n-grams within the response match these within the enter information. It focuses on precision, measuring how a lot of the generated content material is current within the reference information.
- ROUGE (Recall-Oriented Understudy for Gisting Analysis) – Compares phrases and phrases current in each the response and enter information, assessing how a lot related data from the enter is included within the response.
- Numbers checking – Identifies numerical information in each the enter and generated paperwork, figuring out their intersection and flagging potential hallucinations. This helps catch any fabricated or misrepresented quantitative data within the summaries.
- Human assessment – The ultimate outputs and the intermediate steps, together with immediate formulations and information preprocessing, are a part of the human assessment course of. This consists of evaluating a set of responses, checking for accuracy, hallucinations, completeness, adherence to constraints, and compliance with safety and authorized necessities. This collaborative strategy makes certain Account Summaries meets the particular wants of our discipline groups, precisely represents AWS companies, and responsibly handles buyer data. Our human assessment course of is complete and built-in all through the event lifecycle of the Account Summaries resolution, involving a various group of stakeholders:
- Discipline sellers and the Account Summaries product staff – These personas collaborate from the early levels on immediate engineering, information choice, and supply validation. AWS information groups make sure that the data used is correct, updated, and appropriately utilized.
- Software safety (AppSec) groups – These groups are engaged to information, assess, and mitigate potential safety dangers, ensuring the answer adheres to AWS safety requirements.
- Finish-users – Finish-users are required to assessment content material created by the LLM for accuracy previous to utilizing the content material.
- Steady suggestions loop – We’ve applied a sturdy, multi-channel suggestions system to repeatedly enhance Account Summaries:
- In-app suggestions – Customers can present suggestions at each the abstract and particular person part ranges, permitting for granular insights into the effectiveness of various parts.
- Every day vendor interactions – Our groups interact in common conversations (one-on-one and thru a devoted Slack channel) with our discipline groups, gathering real-time suggestions and requests for brand spanking new options and datasets.
- Proactive follow-up – We personally attain out to and shut the loop with each single occasion of adverse suggestions, constructing belief and making a cycle of steady suggestions.
This feeds into our refinement course of for current summaries and performs a vital function in prioritizing our product roadmap. We additionally make sure that this suggestions reaches the related groups throughout AWS that handle information and insights. This enables them to handle any points with their fashions, increase datasets, or refine their insights based mostly on real-world utilization and discipline staff wants. Provided that our generative AI resolution brings collectively information from numerous sources, this suggestions loop is essential for bettering not simply Account Summaries, but in addition the underlying information and fashions that feed into it. This strategy has been instrumental in sustaining excessive consumer satisfaction, driving steady enchancment of Account Summaries.
Infrastructure and operations
The robustness and effectivity of our Account Summaries resolution are underpinned by an structure that makes use of AWS companies to offer scalability, reliability, and safety whereas optimizing for efficiency. Key parts embody asynchronous processing to handle response occasions, a multi-tiered strategy to dealing with requests, and strategic use of companies like AWS Lambda and Amazon DynamoDB. We’ve additionally applied complete monitoring and alerting methods to keep up excessive availability and rapidly deal with any points. The next diagram illustrates this structure.
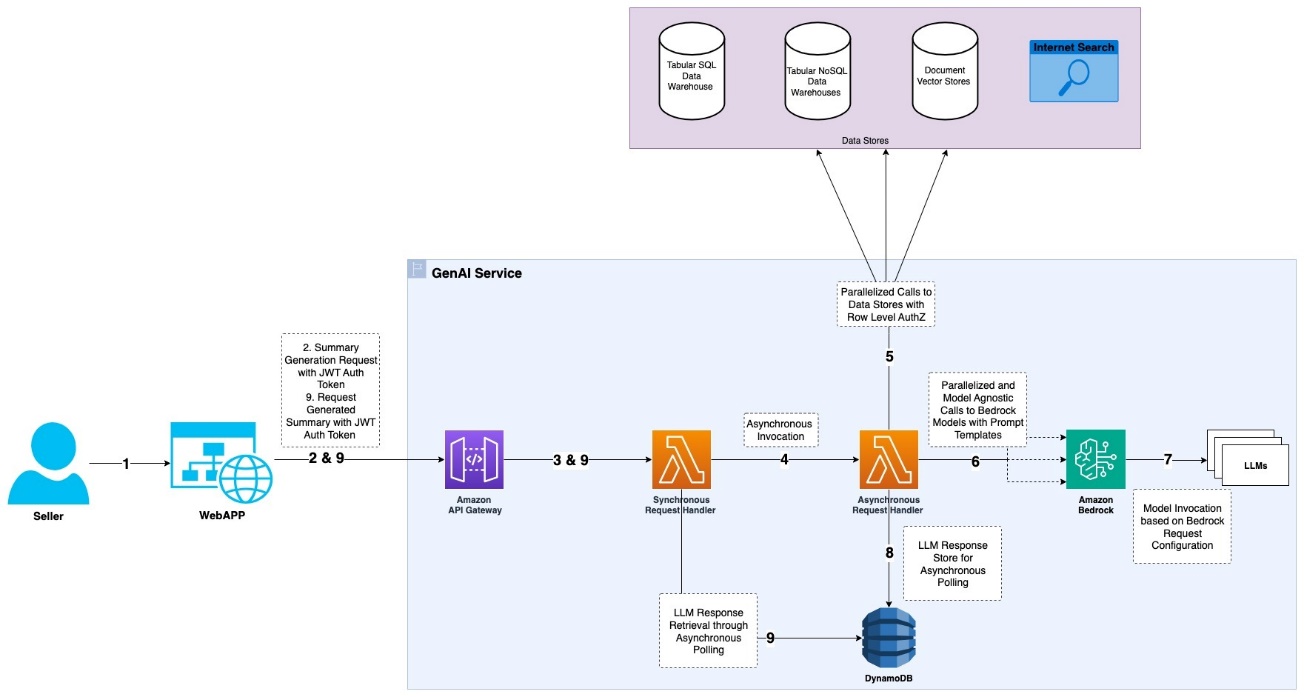
Within the following subsections, we define our API design, authentication mechanisms, response time optimization methods, and operational practices that collectively allow us to ship high-quality, well timed account summaries at scale.
API design
Account abstract technology requests are dealt with asynchronously to remove consumer wait occasions for responses. This strategy addresses potential delays from downstream information sources and Amazon Bedrock, which may prolong response occasions to a number of seconds. Two Lambda capabilities handle a vendor’s summarization request: Synchronous Request Handler and Asynchronous Request Handler.
When a vendor initiates a summarization request by way of the online utility interface, the request is routed to the Synchronous Request Handler Lambda perform. The perform generates a requestId, validates the enter offered by the vendor, invokes the Asynchronous Request Handler perform asynchronously, and sends an acknowledgment to the vendor together with the requestId for monitoring the request’s progress.
The Asynchronous Request Handler perform gathers information from numerous information sources in parallel. It then invokes the Amazon Bedrock LLM in parallel, utilizing the LLM mannequin configuration and a immediate template populated with the gathered information. Amazon Bedrock invokes the suitable LLM fashions based mostly on the configuration to generate summarized content material. For this use case, we make the most of each the Amazon Titan and Anthropic Claude fashions, profiting from their distinctive strengths for various points of the abstract technology. The Asynchronous Request Handler perform shops ends in a DynamoDB database together with the generated requestId.
Lastly, the online utility periodically polls for the summarized account abstract utilizing the generated requestId. The Synchronous Request Handler perform retrieves the summarized content material from DynamoDB and responds to the vendor with the abstract when the request is happy.
Authentication
The vendor is authenticated within the net utility utilizing a centralized authentication system. All requests to the generative AI service are accompanied by a JWT, generated from the authentication system. The consumer’s authorization to entry the generative AI service is predicated on their identification, which is verified utilizing the JWT. When the generative AI service gathers information from numerous information sources, it makes use of the consumer’s identification, utilizing row-level safety by limiting entry to solely the info that the consumer is permitted to entry.
Response time optimization
To reinforce response occasions, we make the most of a smaller LLM mannequin similar to Anthropic Claude Prompt on Amazon Bedrock, which is thought for its quicker response charges. Bigger fashions are reserved for prompts requiring extra in-depth insights. The account abstract consists of a number of sections, every generated by operating a number of prompts independently and in parallel. Information fetching for these prompts can also be carried out in parallel to attenuate response time.
Operational practices
All failures inside the account abstract are tracked by way of operational metrics dashboards and alerts. On-call schedules are in place to handle these points promptly. The staff repeatedly displays and strives to enhance response occasions. For every main function launch, load assessments are carried out to verify predicted request charges stay inside the limits for all downstream sources.
Constructing a manufacturing use case: Classes realized
Our expertise with implementing generative AI at scale affords priceless insights for organizations embarking on the same journey:
- Choose the proper first use case – One of the widespread questions we’ve obtained is how we prioritized and landed on the place to start out. Though this will appear trivial, looking back it had a major impression in incomes belief with the group. Launching a transformative know-how like this at scale must be profitable—and for that, it should be “appropriate” and helpful.
- Prioritize use circumstances successfully – We evaluated utilizing the next components:
- Enterprise impression – There are various fascinating purposes of generative AI, however we prioritized this use case as a result of discipline groups spend a major period of time researching data and knew that even small enhancements at scale would have important impression.
- Information availability – Probably the most vital facet of any generative AI use case is the standard and reliability of the underlying information. We recognized and assessed the supply and trustworthiness of the info sources required for Account Summaries, ensuring it was correct, updated, and had the proper entry permissions in place. We additionally began with the info we already had, and over time built-in extra datasets and introduced in exterior information.
- Tech readiness – We evaluated the maturity and capabilities of the generative AI applied sciences obtainable to us on the time. LLMs had demonstrated distinctive efficiency in duties similar to textual content summarization and technology, which aligned completely with the necessities of Account Summaries.
- Foster steady studying – Within the early levels of our generative AI journey, we inspired our groups to experiment and construct prototypes throughout numerous domains. This hands-on expertise allowed our builders and information scientists to achieve sensible data and understanding of the capabilities and limitations of generative AI. We proceed this custom even at this time as a result of we all know how briskly new capabilities are being developed and we want our groups to maintain tempo with this alteration so we are able to construct one of the best merchandise for our discipline groups.
- Embrace iterative improvement – Generative AI product improvement is inherently iterative, requiring a steady cycle of experimentation and refinement. Our improvement course of revolved round crafting and fine-tuning prompts that might generate correct, related, and actionable insights. We engaged in intensive immediate engineering, experimenting with completely different immediate buildings, fashions, and output codecs to realize the specified outcomes.
- Implement efficient enablement and alter administration – We applied a phased strategy to deployment, beginning with a small group of early adopters and progressively increasing to the broader group. We established channels for customers to offer suggestions, report points, and counsel enhancements, fostering a tradition of steady enchancment. We targeted on nurturing a tradition that embraces AI-assisted work, emphasizing that the know-how is a instrument to reinforce discipline capabilities.
- Set up clear metrics and KPIs – We outlined particular, measurable outcomes to gauge the success of Account Summaries. These metrics included consumer adoption charges, retention, time saved per abstract generated, and impression on buyer engagements. Common evaluation of those key efficiency indicators (KPIs) guided our ongoing improvement efforts.
- Foster cross-functional collaboration – The success of our Account Summaries resolution relied closely on collaboration between numerous groups, together with information scientists, engineers, and gross sales representatives throughout AWS. This cross-functional strategy make sure that all points of the answer had been totally thought-about and optimized.
Conclusion
This publish is the primary in a sequence that explores how generative AI and ML are revolutionizing our discipline groups’ work and buyer engagements. In upcoming posts, we dive into numerous use circumstances that rework completely different points of the gross sales journey, together with:
- AI gross sales assistant powered by Amazon Q – We’ll discover our AI gross sales assistant, obtainable throughout completely different modalities and seamlessly integrating with our different methods. You’ll be taught the way it solutions questions, generates content material, and facilitates bidirectional interactions, all whereas repeatedly utilizing inside and exterior information to ship well timed, personalised insights.
- Autonomous brokers for prospecting and buyer engagement – We’ll showcase how AI-powered brokers are reworking prospecting, alternative development, and buyer engagement to drive effectivity and effectiveness.
We’re excited concerning the potential of those applied sciences to automate duties, present suggestions, and unlock time for strategic interactions. We encourage you to discover these prospects, experiment with AWS AI companies, and embark by yourself transformation journey. Keep tuned for our upcoming posts, the place we’ll proceed to unfold the story of how AI is reshaping the Gross sales & Advertising group at AWS.
In regards to the Authors

Rupa Boddu is the Principal Tech Product Supervisor main Generative AI technique and improvement for the AWS Gross sales and Advertising group. She has efficiently launched AI/ML purposes throughout AWS and collaborates with government groups of AWS prospects to form their AI methods. Her profession spans management roles throughout startups and controlled industries, the place she has pushed cloud transformations, led M&A integrations, and held world management positions encompassing COO obligations, gross sales, software program improvement, and infrastructure.
 Raj Aggarwal is the GM of GenAI & Income Acceleration for the AWS GTM group. Raj is answerable for growing the Gen AI technique and merchandise to remodel discipline capabilities, GTM motions, and the vendor and buyer journeys throughout the worldwide AWS Gross sales & Advertising group. His staff has constructed and launched high-impact, manufacturing purposes at-scale, and served as a key design accomplice for a lot of of Amazon’s GenAI merchandise. Previous to this, Raj constructed and exited two corporations. As Founder/CEO of Localytics, the main cellular analytics & messaging supplier, he grew it to $25M ARR with 200+ workers.
Raj Aggarwal is the GM of GenAI & Income Acceleration for the AWS GTM group. Raj is answerable for growing the Gen AI technique and merchandise to remodel discipline capabilities, GTM motions, and the vendor and buyer journeys throughout the worldwide AWS Gross sales & Advertising group. His staff has constructed and launched high-impact, manufacturing purposes at-scale, and served as a key design accomplice for a lot of of Amazon’s GenAI merchandise. Previous to this, Raj constructed and exited two corporations. As Founder/CEO of Localytics, the main cellular analytics & messaging supplier, he grew it to $25M ARR with 200+ workers.
 Asa Kalavade leads AWS Discipline Experiences, overseeing instruments and processes for the AWS GTM group throughout all roles and buyer engagement levels. Over the previous two years, she led a change that consolidated tons of of disparate methods right into a streamlined, role-based expertise, incorporating generative AI to reimagine the client journey. Beforehand, as GM for the AWS hybrid storage portfolio, Asa launched a number of key companies, together with AWS File Gateway, AWS Switch Household, and AWS DataSync. Earlier than becoming a member of AWS, she based two venture-backed startups in Boston.
Asa Kalavade leads AWS Discipline Experiences, overseeing instruments and processes for the AWS GTM group throughout all roles and buyer engagement levels. Over the previous two years, she led a change that consolidated tons of of disparate methods right into a streamlined, role-based expertise, incorporating generative AI to reimagine the client journey. Beforehand, as GM for the AWS hybrid storage portfolio, Asa launched a number of key companies, together with AWS File Gateway, AWS Switch Household, and AWS DataSync. Earlier than becoming a member of AWS, she based two venture-backed startups in Boston.

{kind=link}