


Language-based fashions (LFMs) and large-scale language fashions (LLMs) have demonstrated the power to effectively deal with a number of duties with a single, fastened mannequin. This work has motivated the event of image-based fashions (IFMs) in laptop imaginative and prescient, which goal to encode common data from pictures into embedding vectors. Nonetheless, these strategies pose challenges in video evaluation. One strategy treats a video as a sequence of pictures, sampling, embedding, and mixing every body. Nonetheless, this strategy has issue capturing detailed movement and small adjustments between frames. This makes it obscure the continual move of knowledge in a video, particularly when monitoring object movement and small variations between frames.
Present works have tried to beat these challenges utilizing two principal approaches primarily based on the Imaginative and prescient Transformer structure (ViT). The primary strategy makes use of distillation utilizing a high-performance IFM equivalent to CLIP as a instructor, and the second strategy is predicated on masks modeling, the place the mannequin predicts lacking data from partial enter. Nonetheless, each approaches have limitations. Distillation-based strategies equivalent to UMT and InternVideo2 wrestle on motion-sensitive benchmarks equivalent to One thing-One thing-v2 and Diving-48. Masks modeling-based strategies equivalent to V-JEPA carry out poorly on appearance-centric benchmarks equivalent to Kinetics-400 and Moments-in-Time. These limitations spotlight the issue of capturing the looks and movement of objects in movies.
A staff from Twelve Labs proposed a novel mannequin, TWLV-I, that gives embedding vectors for movies capturing look and movement. Regardless of being educated solely on publicly obtainable datasets, TWLV-I performs properly on motion recognition benchmarks that target look and movement. Moreover, the mannequin achieves state-of-the-art efficiency on video-centric duties, equivalent to temporal and spatio-temporal motion localization, and temporal motion segmentation. The present analysis methodology is enhanced to investigate TWLV-I and different video-based fashions (VFMs) utilizing novel analytical approaches and strategies to seek out the mannequin’s capability to discriminate movies primarily based on the course of movement, unbiased of look.
TWLV-I employs the ViT structure and is on the market in a Base model with 86M parameters and a Giant model with 307M parameters. The mannequin tokenizes the enter video into patches, processes them with a transformer, and swimming pools the ensuing patch-wise embeddings to acquire a world video embedding. Moreover, pre-training datasets embody Kinetics-710, HowTo360K, WebVid10M, and varied picture datasets. The coaching goal of TWLV-I integrates the strengths of distillation-based and masks modeling-based approaches with completely different reconstruction goal methods. The mannequin makes use of two body sampling strategies to beat computational constraints: (a) uniform embedding for brief movies and (b) multi-clip embedding for lengthy movies.
The outcomes obtained with TWLV-I present a major efficiency enchancment over present fashions in motion recognition duties. Based mostly on the typical top-1 accuracy of linear probes throughout 5 motion recognition benchmarks, TWLV-I outperforms VJEPA (ViT-L) by 4.6% factors and UMT (ViT-L) by 7.7% factors when utilizing solely publicly obtainable datasets for pre-training. The mannequin outperforms DFN (ViT-H) by 7.2% factors, V-JEPA (ViT-H) by 2.7% factors, and InternVideo2 (ViT-g) by 2.8% factors. The researchers additionally offered the embedding vectors generated by TWLV-I from broadly used video benchmarks, in addition to the analysis supply code that enables direct use of those embeddings.
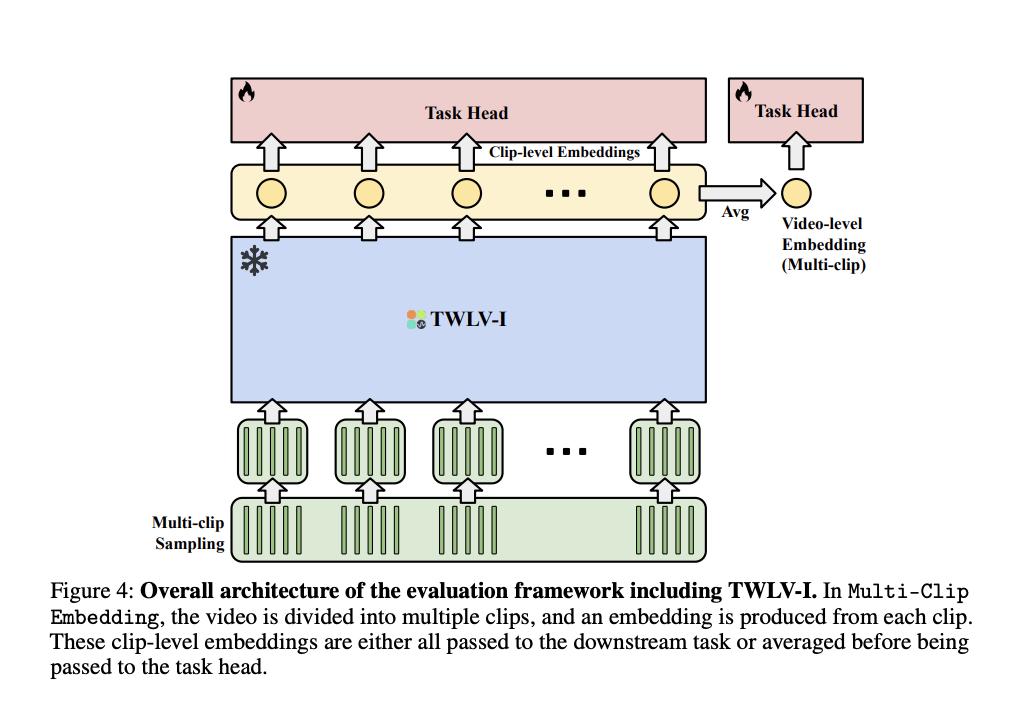
The staff at Twelve Labs proposed a brand new mannequin, TWLV-I, designed to offer embedding vectors for movies capturing look and movement. TWLV-I is a strong video-based mannequin that displays wonderful efficiency in movement and look understanding. It’s anticipated that the TWLV-I mannequin and its embeddings will probably be broadly utilized in varied functions. Moreover, the analysis and evaluation strategies will probably be actively adopted within the video-based mannequin area. Sooner or later, it’s anticipated that these strategies will information analysis within the video understanding subject and additional the event of extra complete video evaluation fashions.
Test it out paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, do not forget to comply with us. Twitter And our Telegram Channel and LinkedIn GroupsUp. In the event you like our work, you’ll love our Newsletter..
Be a part of us! 49k+ ML Subreddits
Try our upcoming AI webinars right here

Sajjad Ansari is a closing yr undergraduate scholar at Indian Institute of Expertise Kharagpur. As a know-how fanatic, he delves into sensible functions of AI with a deal with understanding the influence of AI know-how and its influence on the actual world. He goals to precise complicated AI ideas in a transparent and comprehensible method.

{kind=link}