


Many organizations are archiving giant media libraries, analyzing contact heart recordings, making ready coaching information for AI, or processing on-demand video for closed captioning. As information volumes enhance considerably, the price of managed automated speech recognition (ASR) companies can rapidly change into the first constraint to scalability.
To handle this price scalability problem, we NVIDIA Parakeet-TDT-0.6B-v3 Fashions are deployed by way of AWS Batch on GPU-accelerated cases. Parakeet-TDT’s token and length transducer structure concurrently predicts textual content tokens and their durations, intelligently skipping silence and redundant processing. This permits inference speeds which might be orders of magnitude quicker than real-time. Allow transcription at scale by paying just for brief bursts of computing somewhat than the complete size of the audio. Audio for lower than 1 cent per hour Based mostly on the benchmarks described on this submit.
This submit describes constructing a scalable, event-driven transcription pipeline that mechanically processes audio recordsdata uploaded to Amazon Easy Storage Service (Amazon S3), and exhibits how you should utilize Amazon EC2 Spot Situations and buffered streaming inference to additional cut back prices.
Mannequin options
Parakeet-TDT-0.6B-v3, launched in August 2025, is an open-source multilingual ASR mannequin that gives excessive accuracy throughout 25 European languages with automated language detection and versatile licensing beneath CC-BY-4.0. Based on Metrics published by NVIDIAthis mannequin maintains a phrase error charge (WER) of 6.34% in clear situations, 11.66% WER at 0 dB SNR, and helps as much as 3 hours of speech utilizing native consideration mode.
The 25 supported languages embrace Bulgarian, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, German, Greek, Hungarian, Italian, Latvian, Lithuanian, Maltese, Polish, Portuguese, Romanian, Slovak, Slovenian, Spanish, Swedish, Russian, and Ukrainian. This reduces the necessity for separate fashions and language-specific configurations when serving Europe’s worldwide financial system. For deployment on AWS, the mannequin requires a GPU-enabled occasion with a minimal of 4 GB VRAM, though 8 GB supplies higher efficiency. G6 cases (NVIDIA L4 GPU) provide the most effective worth/efficiency ratio for test-based inference workloads. This mannequin additionally performs effectively on G5 (A10G), G4dn (T4), and most throughput P5 (H100) or P4 (A100) cases.
answer structure
The method begins whenever you add an audio file to your S3 bucket. This triggers an Amazon EventBridge rule that sends the job to AWS Batch. AWS Batch provisions GPU-accelerated compute assets, and the provisioned cases pull container photographs containing pre-cached fashions from Amazon Elastic Container Registry (Amazon ECR). The inference script downloads the file, processes it, and uploads a timestamped JSON transcript to an output S3 bucket. The structure scales to zero when idle, so prices are solely incurred throughout energetic compute.
For extra details about the final structure elements, see our earlier submit, Whisper Audio Transcription with AWS Batch and AWS Inferentia.
Determine 1. Occasion-driven audio transcription pipeline utilizing Amazon EventBridge and AWS Batch
Conditions
- Create an AWS account when you do not have already got one and sign up. Create a consumer with full administrative privileges utilizing AWS IAM Identification Middle, as described in Including a Consumer.
- Set up the AWS Command Line Interface (AWS CLI) in your native improvement machine and create an administrator consumer profile as described in Setting Up the AWS CLI.
- set up docker in your native machine.
- create a clone GitHub repository to your native machine.
Constructing a container picture
The repository incorporates Docker recordsdata that construct streamlined container photographs optimized for inference efficiency. This picture makes use of Amazon Linux 2023 as a base, installs Python 3.12, and pre-caches the Parakeet-TDT-0.6B-v3 mannequin through the construct to cut back obtain delays at runtime.
Push to Amazon ECR
The repository consists of an updateImage.sh script that handles surroundings discovery (CodeBuild or EC2), builds the container picture, optionally creates an ECR repository, permits vulnerability scanning, and pushes the picture. Run it like this:./updateImage.sh
Deploying the answer
This answer makes use of an AWS CloudFormation template (deployment.yaml) to provision your infrastructure. The buildArch.sh script automates the deployment by discovering the AWS Area, gathering VPC, subnet, and safety group data, and deploying the CloudFormation stack.
./buildArch.shBelow the hood:
The CloudFormation template creates an AWS Batch compute surroundings with G6 and G5 GPU cases, a job queue, a job definition that references an ECR picture, and enter and output S3 buckets with EventBridge notifications enabled. You will additionally create an EventBridge rule to set off a Batch job on S3 uploads, an Amazon CloudWatch agent configuration for GPU/CPU/Reminiscence monitoring, and an IAM function with a least privilege coverage. AWS Batch permits you to choose an Amazon Linux 2023 GPU picture by specifying it. ImageType: ECS_AL2023_NVIDIA Inside your computing surroundings configuration.
Alternatively, you may deploy immediately from the AWS CloudFormation console utilizing the launch hyperlink offered within the repository’s README.
Configuring a spot occasion
Amazon EC2 Spot Situations can additional cut back prices by working your workloads on unused EC2 capability at reductions of as much as 90%, relying on the occasion sort. To allow Spot Situations, modify your compute surroundings. deployment.yaml:
You possibly can allow this by setting –parameter-overrides. UseSpotInstances=Sure when working aws cloudformation deploy. of SPOT_PRICE_CAPACITY_OPTIMIZED The allocation technique selects the Spot Occasion pool that’s least prone to be interrupted and has the bottom doable worth. Diversifying your occasion sorts (G6 xlarge, G6 2xlarge, G5 xlarge) will increase Spot availability. Setting MinvCpus: 0 zero-scales the surroundings when idle, so there isn’t a price throughout workloads. ASR jobs are stateless and idempotent, making them good for spots. When an occasion is reclaimed, AWS Batch mechanically retries the job (as much as 2 retries configured within the job definition).
Reminiscence administration for lengthy audio
The reminiscence consumption of the Parakeet-TDT mannequin will increase linearly with the size of the audio. The Quick Conformer encoder should generate and retailer an entire audio sign characteristic illustration, making a direct dependency the place doubling the audio size nearly doubles the VRAM utilization. Based on the mannequin card, in case you are cautious sufficient, this mannequin can deal with as much as 24 minutes with 80GB of VRAM.
NVIDIA addresses this as follows: native consideration Modes that assist as much as 3 hours of audio on 80 GB A100:
Buffered streaming inference
Use buffered streaming inference for audio longer than 3 hours, or to cost-effectively course of lengthy audio on normal {hardware} resembling g6.xlarge. Tailored from NVIDIA NeMo streaming inference examplethis method processes audio in overlapping chunks somewhat than loading the whole context into reminiscence.
To keep up transcription high quality at chunk boundaries, we configure 20-second chunks with 5-second left context and 3-second proper context (altering these parameters can cut back accuracy, so experiment to search out the optimum configuration; decreasing chunk_secs will enhance processing time).
Processing audio with a hard and fast chunk dimension decouples VRAM utilization from the full size of the audio, permitting a single g6.xlarge occasion to course of a 10-hour file with the identical reminiscence footprint as a 10-minute file.
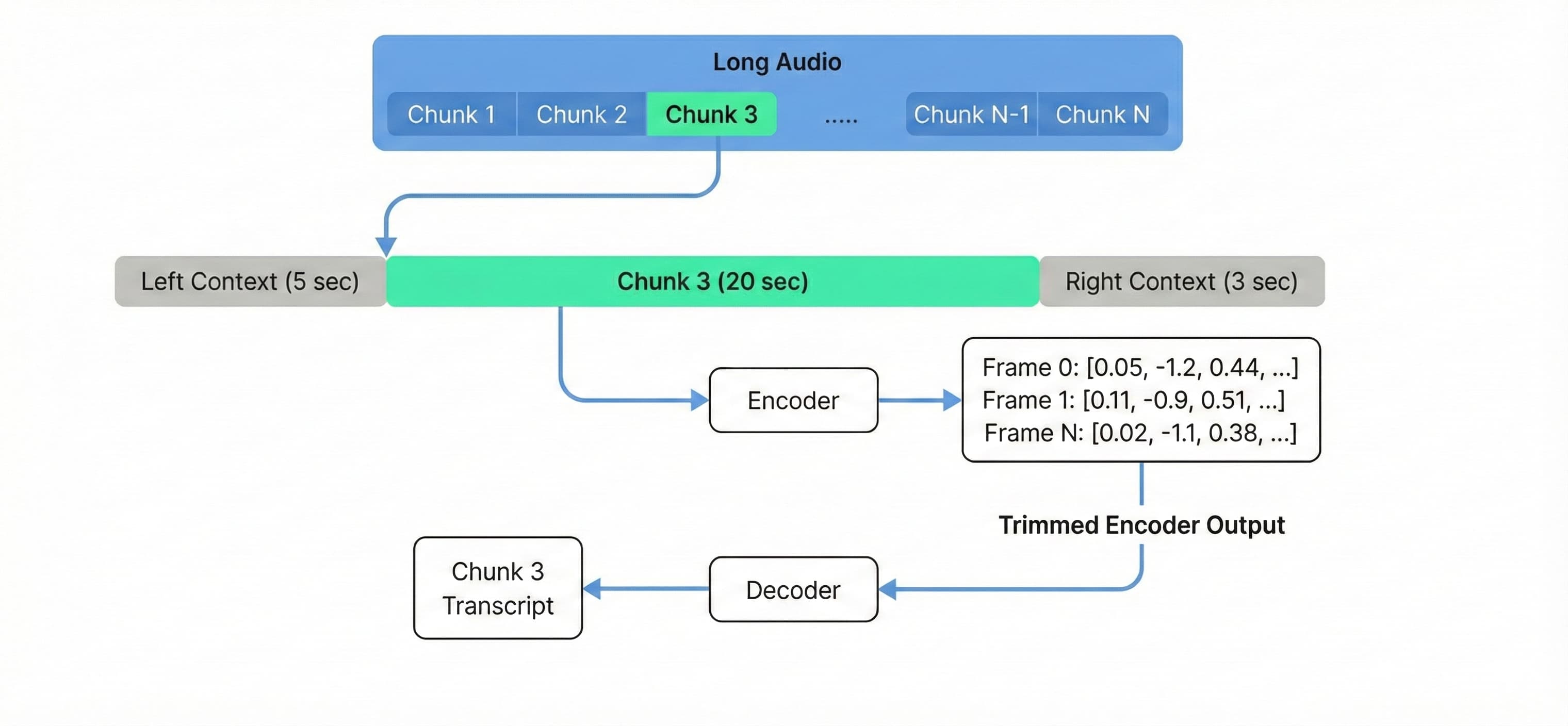
Determine 2. Buffered streaming inference processes audio in overlapping chunks with fixed reminiscence utilization.
To allow and deploy buffered streaming, EnableStreaming=Sure Parameter.
Testing and monitoring
To validate our answer at scale, we ran an experiment utilizing 1,000 similar 50-minute audio recordsdata. NASA pre-flight crew press conferencedistributed throughout 100 g6.xlarge cases processing 10 recordsdata every.
 Determine 3. Run a batch job on 100 g6.xlarge cases concurrently.
Determine 3. Run a batch job on 100 g6.xlarge cases concurrently.
This deployment consists of an Amazon CloudWatch agent configuration that collects GPU utilization, energy consumption, VRAM utilization, CPU utilization, reminiscence consumption, and disk utilization at 10 second intervals. These metrics seem beneath the CWAgent namespace and can help you construct dashboards for real-time monitoring.
Efficiency and value evaluation
To confirm the effectivity of the structure, we benchmarked the system utilizing a number of long-form audio recordsdata.
The Parakeet-TDT-0.6B-v3 mannequin achieved uncooked inference velocity. 0.24 seconds per minute of audio. Nevertheless, an entire pipeline additionally consists of overhead resembling loading the mannequin into reminiscence, loading audio, pre-processing the enter, and post-processing the output. Due to this overhead, long-running audio performs the most effective price optimization to maximise processing time.
Benchmark outcomes (g6.xlarge):
- Audio size: 3 hours 25 minutes (205 minutes)
- Whole length of the job: 100 seconds
- Efficient processing velocity: 0.49 seconds per minute of audio
- Price breakdown
You possibly can estimate the associated fee per minute of audio processing primarily based on the pricing within the us-east-1 area for g6.xlarge cases.
| worth mannequin | Price per hour (g6.xlarge)* | Price per minute of voice |
|---|---|---|
| on demand | ~$0.805 | **$0.00011** |
| spot occasion | ~$0.374 | **$0.00005** |
*Costs are estimates primarily based on US-East-1 charges on the time of writing. Spot costs fluctuate by availability zone and are topic to alter.
This comparability brings worth to large-scale transcription and highlights the financial advantages of a self-hosted strategy for high-volume workloads in comparison with managed API companies.
cleansing
To keep away from future fees, delete the assets created by this answer.
- Empty all S3 buckets (enter, output, logs).
- Delete the CloudFormation stack.
aws cloudformation delete-stack --stack-name batch-gpu-audio-transcription
- Delete the ECR repository and container photographs if crucial.
For detailed cleanup directions, see cleanup section README for the repository.
conclusion
On this submit, you realized methods to construct an audio transcription pipeline that processes audio at scale at a charge of cents per hour. By combining NVIDIA’s Parakeet-TDT-0.6B-v3 mannequin with AWS Batch and EC2 Spot Situations, you may transcribe throughout 25 European languages with automated language detection, decreasing prices in comparison with different options. Buffered streaming inference know-how extends this functionality to various lengths of audio on normal {hardware}, and an event-driven structure mechanically scales from scratch to deal with various workloads.
First, study the next pattern code. GitHub repository.
Concerning the writer

{kind=link}