


Within the visual view language fashions (VLM), the power to bridge the hole between visible notion and logical code execution has historically confronted efficiency trade-offs. Many fashions are good at describing pictures, however battle to translate that visible info into the rigorous syntax required for software program engineering. Zhipu AI’s (Z.ai) GLM-5V-Turbo This can be a imaginative and prescient coding mannequin particularly designed to handle this within the following methods: Native multimodal coding Coaching paths optimized for agent workflows.
Documented coaching and design decisions: native multimodal fusion
The core technical options of GLM-5V-Turbo are: Native multimodal fusion. In lots of earlier technology techniques, imaginative and prescient and language had been handled as separate pipelines, with the imaginative and prescient encoder producing a textual description for the language mannequin to course of. GLM-5V-Turbo makes use of a local method. That’s, it’s designed to grasp multimodal inputs resembling pictures, movies, design drafts, and complicated doc layouts as major information throughout the coaching section.
Mannequin efficiency is supported by two particular documented design decisions.
- CogViT imaginative and prescient encoder: This part is accountable for processing visible enter, guaranteeing that spatial hierarchy and advantageous visible particulars are preserved.
- MTP (Multi-Token Prediction) structure: This alternative is meant to enhance inference effectivity and inference. That is necessary when your mannequin must output lengthy code sequences or must navigate a fancy GUI setting.
With these decisions, the mannequin 200K context windowThis permits it to course of giant quantities of knowledge, resembling intensive technical documentation or lengthy video recordings of software program interactions, whereas supporting excessive output capability for code technology.
Mixed reinforcement studying for over 30 duties
One of many key challenges in VLM improvement is the “seesaw” impact, the place bettering the visible recognition of a mannequin can result in a degradation of programming logic. To alleviate this, GLM-5V-Turbo was developed utilizing: 30+ Duties Collaborative Reinforcement Studying (RL).
This coaching methodology includes optimizing the mannequin throughout 30 totally different duties concurrently. These duties span a number of areas important to engineering.
- STEM reasoning: Preserve the logical and mathematical foundations obligatory for programming.
- Visible grounding: Skill to precisely establish coordinates and properties of components inside a visible interface.
- Video evaluation: Interpretation of temporal adjustments. Required for debugging animations and understanding the person circulation of recorded classes.
- Utilizing the instrument: Permits fashions to work together with exterior software program instruments and APIs.
Through the use of collaborative RL, the mannequin achieves a steadiness between visible and programmable options. That is significantly related to: GUI agent—An AI system should “perceive” the graphical person interface and generate the required code or instructions to work together with it.
Integration with OpenClaw and Claude code
The utility of GLM-5V-Turbo is highlighted by its optimization for particular agent ecosystems. This mannequin doesn’t operate as a common function AI; deep adaptation inside the workflow open claw and claude code.
Optimized for OpenClaw workflows
OpenClaw is an open-source framework designed for constructing brokers that run inside a graphical person interface. GLM-5V-Turbo Built-in and optimized for OpenClaw workflowsserves as the muse for duties resembling setting deployment, improvement, and evaluation. These situations use the mannequin’s potential to deal with design drafts and doc format to automate the setup and operation of the software program setting.
Visually grounded coding with Claude Code
The mannequin too Work with frameworks like Claude Code to allow visually-based coding workflows.. That is particularly helpful in “claw situations” the place builders might have to supply screenshots of bugs or mockups of recent options. As a result of GLM-5V-Turbo natively understands multimodal enter, it may possibly interpret visible layouts and supply code options primarily based on visible proof offered by the person.
Benchmarking and efficiency verification
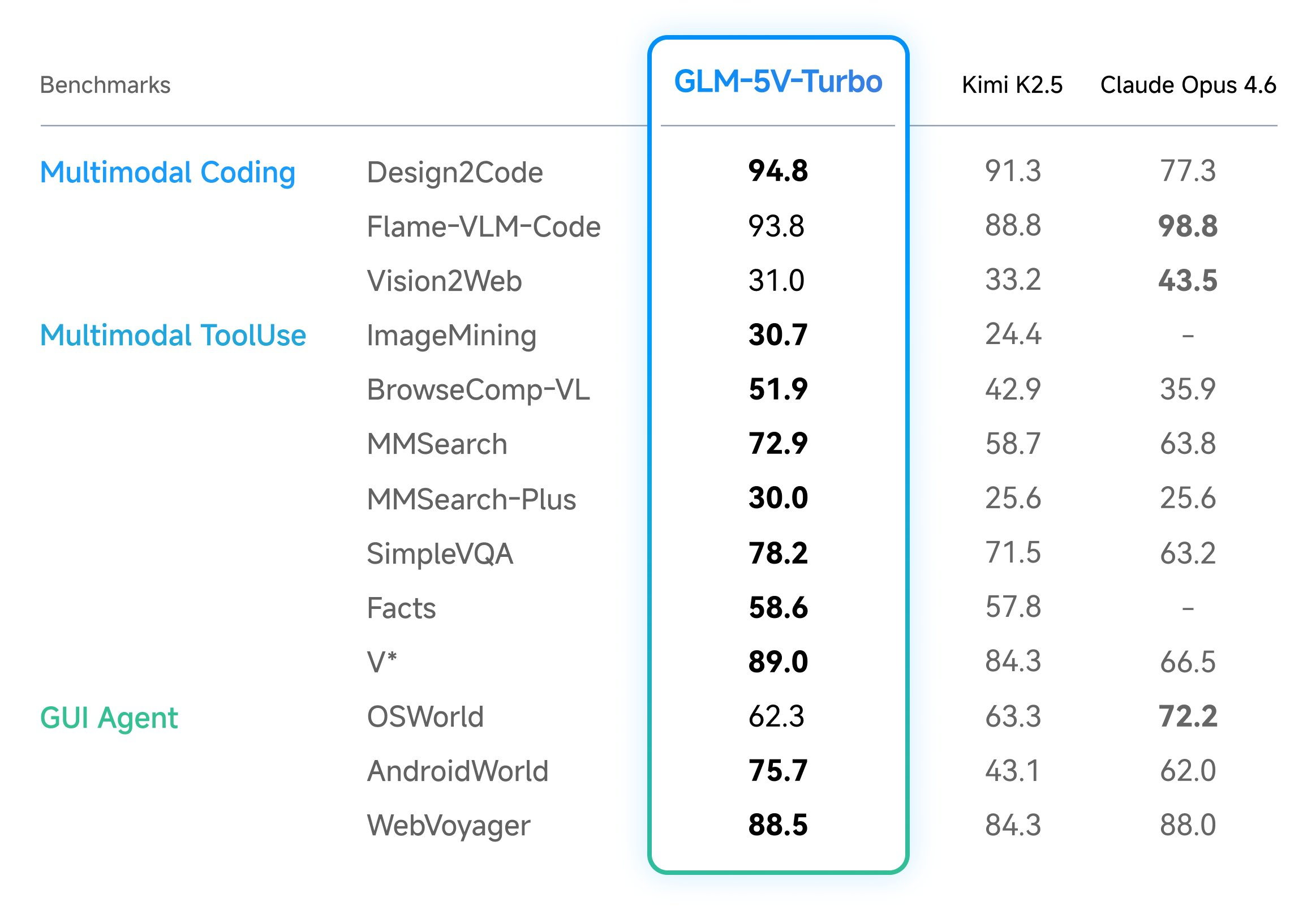
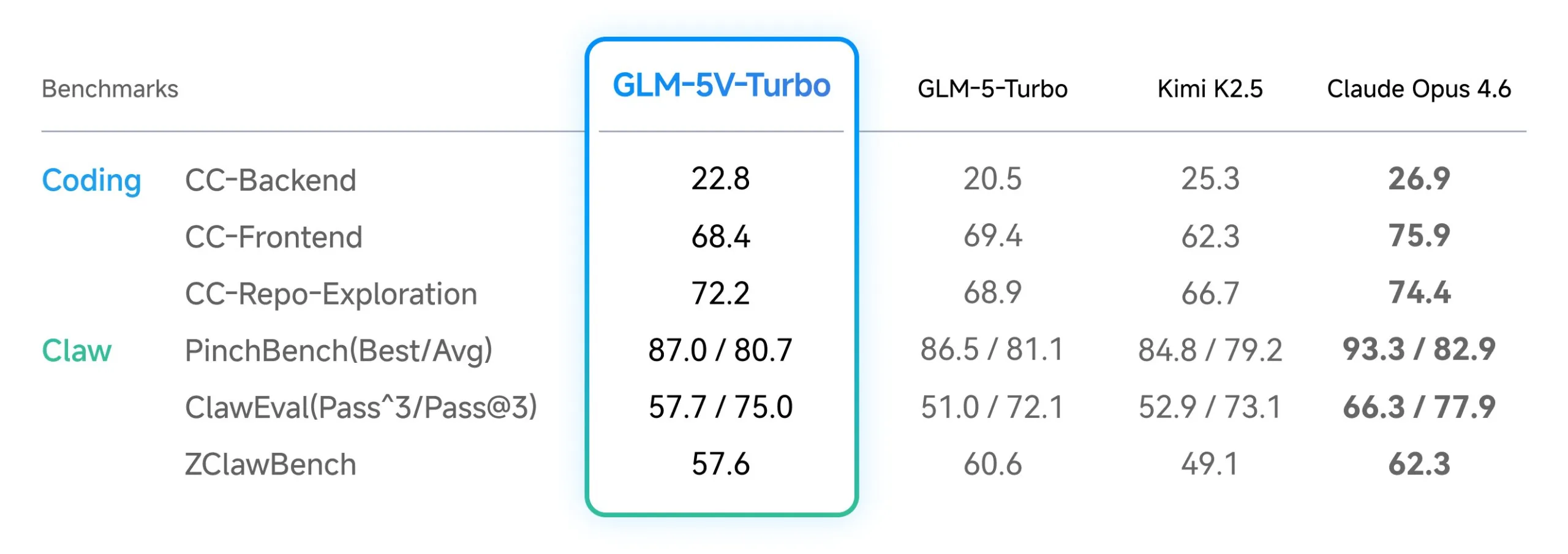
The effectiveness of those design decisions is measured by means of a set of core benchmarks centered on multimodal coding and power utilization. For engineers evaluating fashions, The main focus is on three documented benchmarks.
| benchmark | technical focus |
| CC Bench-V2 | Consider multimodal coding throughout backend, frontend, and repository-level duties. |
| ZClaw Bench | Measure the effectiveness of your mannequin in OpenClaw-specific agent situations. |
| cloeval | Check mannequin efficiency in multistep execution and setting interactions. |
These metrics present that GLM-5V-Turbo maintains the very best efficiency in duties that require high-fidelity doc format understanding and the power to visually manipulate advanced interfaces.
Essential factors
- Native multimodal fusion: Natively perceive picture, video, and doc layouts. CogViT imaginative and prescient encoderenabling direct “Imaginative and prescient-to-Code” execution with out intermediate textual content description.
- Optimization by agent: This mannequin is particularly built-in for the next purposes: open claw and claude code Workflow, grasp the “acknowledge → plan → execute” loop for autonomous setting interplay.
- Excessive-throughput structure: appropriate for reasoning MTP (Multi-Token Prediction) structure, help 200K context window and as much as the utmost 128K output tokens For repository-wide duties.
- Balanced coaching: by means of Mixed reinforcement studying for over 30 dutiesmaintains rigorous programming logic and STEM reasoning whereas extending visible recognition capabilities.
- benchmark: It supplies SOTA efficiency with specialised agent leaderboards resembling: CC Bench-V2 (coding/repository exploration) and ZClaw Bench (GUI agent interplay).
Please examine technical details and try it here. Additionally, be at liberty to comply with us Twitter Do not forget to affix us 120,000+ ML subreddits and subscribe our newsletter. cling on! Are you on telegram? You can now also participate by telegram.

{kind=link}