


With a big selection of Nova customization choices, the journey to customization and transitioning between platforms has historically been intricate, necessitating technical experience, infrastructure setup, and appreciable time funding. This disconnect between potential and sensible purposes is exactly what we aimed to handle. Nova Forge SDK makes massive language mannequin (LLM) customization accessible, empowering groups to harness the complete potential of language fashions with out the challenges of dependency administration, picture choice, and recipe configuration. We view customization as a continuum inside the scaling ladder, due to this fact, the Nova Forge SDK helps all customization choices, starting from diversifications based mostly on Amazon SageMaker AI to deep customization utilizing Amazon Nova Forge capabilities.
Within the final submit, we launched the Nova Forge SDK and the best way to get began with it together with the conditions and setup directions. On this submit, we stroll you thru the method of utilizing the Nova Forge SDK to coach an Amazon Nova mannequin utilizing Amazon SageMaker AI Coaching Jobs. We consider our mannequin’s baseline efficiency on a StackOverFlow dataset, use Supervised High quality-Tuning (SFT) to refine its efficiency, after which apply Reinforcement High quality Tuning (RFT) on the custom-made mannequin to additional enhance response high quality. After every sort of fine-tuning, we consider the mannequin to indicate its enchancment throughout the customization course of. Lastly, we deploy the custom-made mannequin to an Amazon SageMaker AI Inference endpoint.
Subsequent, let’s perceive the advantages of Nova Forge SDK by going by means of a real-world state of affairs of computerized classification of Stack Overflow questions into three well-defined classes (HQ, LQ EDIT, LQ CLOSE).
Case examine: classify the given query into the right class
Stack Overflow has 1000’s of questions, various enormously in high quality. Mechanically classifying query high quality helps moderators prioritize their efforts and information customers to enhance their posts. This answer demonstrates the best way to use the Amazon Nova Forge SDK to construct an automatic high quality classifier that may distinguish between high-quality posts, low-quality posts requiring edits, and posts that ought to be closed. We use the Stack Overflow Question Quality dataset containing 60,000 questions from 2016-2020, categorised into three classes:
HQ(Excessive High quality): Nicely-written posts with out editsLQ_EDIT(Low High quality – Edited): Posts with unfavourable scores and a number of neighborhood edits, however stay openLQ_CLOSE(Low High quality – Closed): Posts closed by the neighborhood with out edits
For our experiments, we randomly sampled 4700 questions and break up them as follows:
| Cut up | Samples | Proportion | Function |
| Coaching (SFT) | 3,500 | ~75% | Supervised fine-tuning |
| Analysis | 500 | ~10% | Baseline and post-training analysis |
| RFT | 700 + (3,500 from SFT) | ~15% | Reinforcement fine-tuning |
For RFT, we augmented the 700 RFT-specific samples with all 3,500 SFT samples (whole: 4,200 samples) to forestall catastrophic forgetting of supervised capabilities whereas studying from reinforcement alerts.
The experiment consists of 4 foremost phases: baseline analysis to measure out-of-the-box efficiency, supervised fine-tuning (SFT) to show domain-specific patterns, and reinforcement fine-tuning (RFT) on SFT checkpoint to optimize for particular high quality metrics and at last deployment to Amazon SageMaker AI. For fine-tuning, every stage builds upon the earlier one, with measurable enhancements at each step.
We used a standard system immediate for all of the datasets:
This can be a stack overflow query from 2016-2020 and it may be categorised into three classes:
* HQ: Excessive-quality posts with out a single edit.
* LQ_EDIT: Low-quality posts with a unfavourable rating, and a number of neighborhood edits. Nonetheless, they continue to be open after these adjustments.
* LQ_CLOSE: Low-quality posts that had been closed by the neighborhood with out a single edit.
You're a technical assistant who will classify the query from customers into any of above three classes. Reply with solely the class identify: HQ, LQ_EDIT, or LQ_CLOSE.
**Don't add any rationalization, simply give the class as output**.
Stage 1: Set up baseline efficiency
Earlier than fine-tuning, we set up a baseline by evaluating the pre-trained Nova 2.0 mannequin on our analysis set. This provides us a concrete baseline for measuring future enhancements. Baseline analysis is vital as a result of it helps you perceive the mannequin’s out-of-the-box capabilities, establish efficiency gaps, set measurable enchancment targets, and validate that fine-tuning is important.
Set up the SDK
You’ll be able to set up the SDK with a easy pip command:
Import the important thing modules:
Put together evaluation information
The Amazon Nova Forge SDK supplies highly effective information loading utilities that deal with validation and transformation mechanically. We start by loading our analysis dataset and remodeling it to the format anticipated by Nova fashions:
The CSVDatasetLoader class handles the heavy lifting of knowledge validation and format conversion. The question parameter maps to your enter textual content (the Stack Overflow query), response maps to the bottom fact label, and system incorporates the classification directions that information the mannequin’s conduct.
Subsequent, we use the CSVDatasetLoader to remodel your uncooked information into the anticipated format for Nova mannequin analysis:
The reworked information can have the next format:
Earlier than importing to Amazon Easy Storage Service (Amazon S3), validate the reworked information by working the loader.validate() methodology. This lets you catch any formatting points early, reasonably than ready till they interrupt the precise analysis.
Lastly, we are able to save the dataset to Amazon S3 utilizing the loader.save_data() methodology, in order that it may be utilized by the analysis job.
Run baseline analysis
With our information ready, we initialize our SMTJRuntimeManager to configure the runtime infrastructure. We then initialize a NovaModelCustomizer object and name baseline_customizer.consider() to launch the baseline analysis job:
For classification duties, we use the GEN_QA analysis process, which treats classification as a generative process the place the mannequin generates a category label. The exact_match metric from GEN_QA straight corresponds to classification accuracy, the proportion of predictions that precisely match the bottom fact label. The total record of benchmark duties could be retrieved from the EvaluationTask enum, or seen in the Amazon Nova User Guide.
Understanding the baseline outcomes
After the job completes, outcomes are saved to Amazon S3 on the specified output path. The archive incorporates per-sample predictions with log chances, aggregated metrics throughout your entire analysis set, and uncooked mannequin predictions for detailed evaluation.
Within the following desk, we see the aggregated metrics for all of the analysis samples from the output of the analysis job (be aware that BLEU is on a scale of 0-100):
| Metric | Rating |
| ROUGE-1 | 0.1580 (±0.0148) |
| ROUGE-2 | 0.0269 (±0.0066) |
| ROUGE-L | 0.1580 (±0.0148) |
| Actual Match (EM) | 0.1300 (±0.0151) |
| Quasi-EM (QEM) | 0.1300 (±0.0151) |
| F1 Rating | 0.1380 (±0.0149) |
| F1 Rating (Quasi) | 0.1455 (±0.0148) |
| BLEU | 0.4504 (±0.0209) |
The bottom mannequin achieves solely 13.0% exact-match accuracy on this 3-class classification process, whereas random guessing would yield 33.3%. This clearly demonstrates the necessity for fine-tuning and establishes a quantitative baseline for measuring enchancment.
As we see within the subsequent part, that is largely because of the mannequin ignoring the formatting necessities of the issue, the place a verbose response together with explanations and analyses is taken into account invalid. We are able to derive the format-independent classification accuracy by parsing our three labels from the mannequin’s output textual content, utilizing the next classification_accuracy utility perform.
Nonetheless, even with a permissive metric, which ignores verbosity, we get solely a 52.2% classification accuracy. This clearly signifies the necessity for fine-tuning to enhance the efficiency of the bottom mannequin.
Conduct baseline failure evaluation
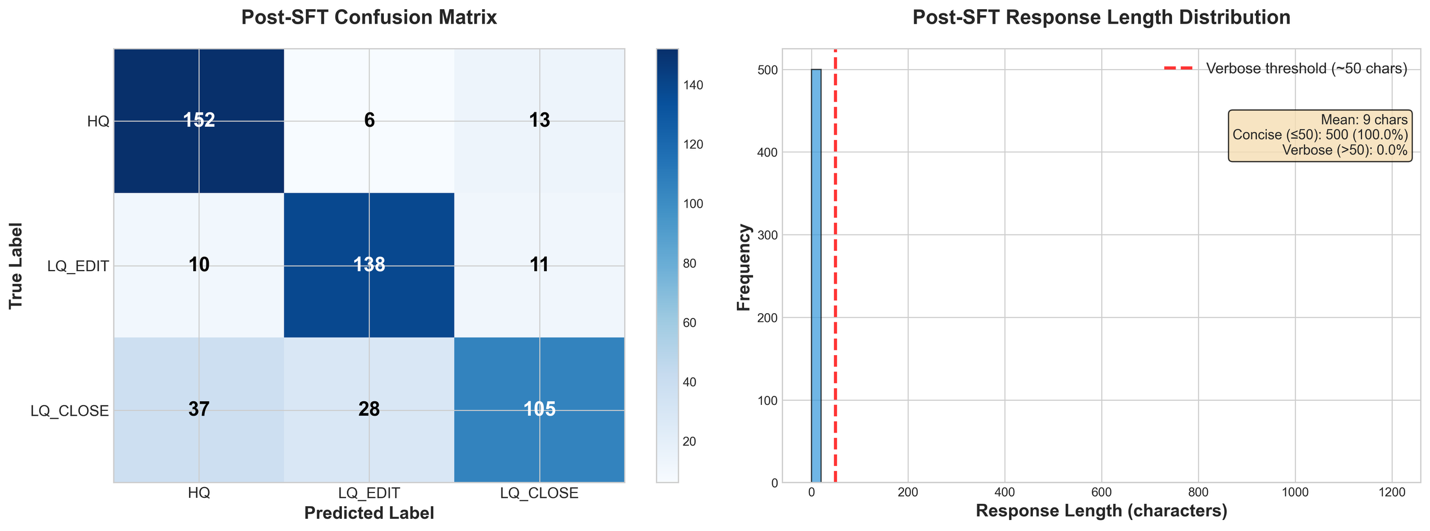
The next picture exhibits a failure evaluation on the baseline. From the response size distribution, we observe that every one responses included verbose explanations and reasoning regardless of the system immediate requesting solely the class identify. As well as, the baseline confusion matrix compares the true label (y axis) with the generated label (x axis); the LLM has a transparent bias in direction of classifying messages as Excessive High quality no matter their precise classification.
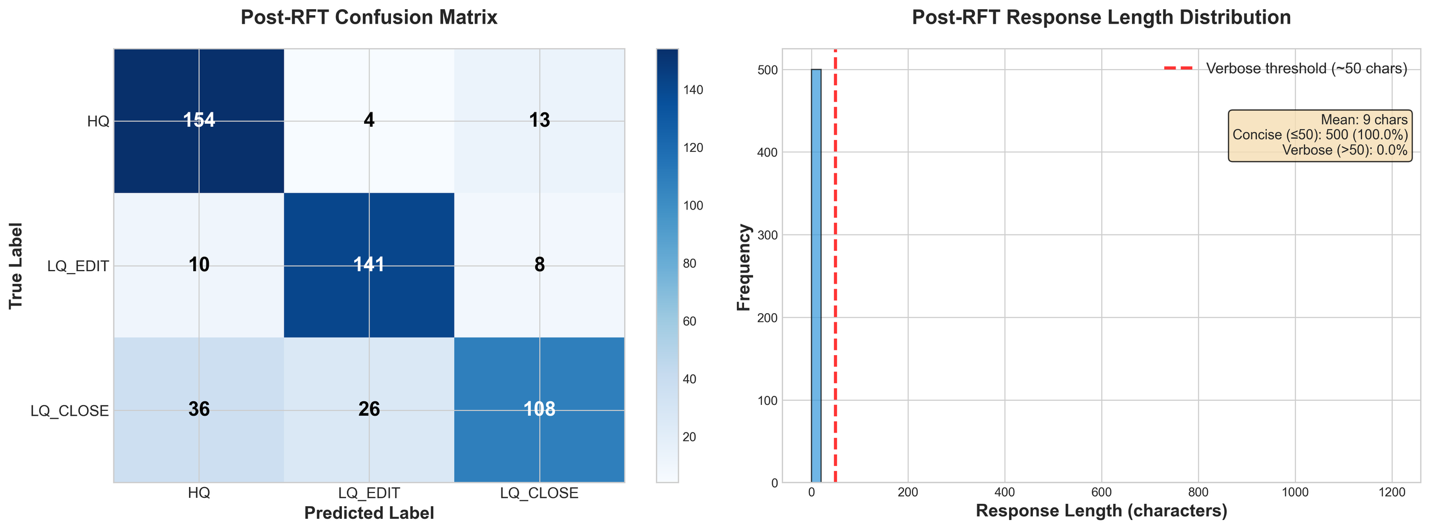
Given these baseline outcomes of each instruction-following failures and classification bias towards HQ, we now apply Supervised High quality-Tuning (SFT) to assist the mannequin perceive the duty construction and output format, adopted by Reinforcement Studying (RL) with a reward perform that penalizes the undesirable behaviors.
Stage 2: Supervised fine-tuning
Now that now we have accomplished our baseline and carried out the failure house evaluation, we are able to use Supervised High quality Tuning to enhance our efficiency. For this instance, we use a Parameter Environment friendly High quality-Tuning method, as a result of it’s a method that provides us preliminary alerts on fashions studying functionality.
Information preparation for supervised fine-tuning
With the Nova Forge SDK, we are able to convey our datasets and use the SDKs information preparation helper features to curate the SFT datasets with in-build information validations.
As earlier than, we use the SDK’s CSVDatasetLoader to load our coaching CSV information and rework it into the required format:
After this transformation, every row of our dataset will probably be structured within the Converse API format, as proven within the following picture:
We additionally validate the dataset to substantiate that it matches the required format for coaching:
Now that now we have our information well-formed and within the right format, we are able to break up it into coaching, validation, and take a look at information, and add all three to Amazon S3 for our coaching jobs to reference.

{kind=link}