


Within the trade advice system, Generative search (GR) We change conventional embedding-based nearest neighbor search with large-scale language fashions (LLMs). These fashions characterize objects as Semantic ID (SID)— a discrete token sequence — and treats acquisition as an autoregressive decoding job. Nevertheless, industrial functions typically must strictly observe enterprise logic, akin to imposing content material freshness or stock availability. Customary autoregressive decoding can not natively implement these constraints, so the mannequin typically “hallucinates” invalid or out-of-stock product identifiers.
Accelerator Bottlenecks: Makes an attempt vs. TPU/GPU
To ensure legitimate output, builders usually use prefix bushes (tries) to masks invalid tokens throughout every decoding step. Though conventional trie implementations are conceptually easy, they’re basically inefficient on {hardware} accelerators akin to TPUs and GPUs.
The effectivity hole stems from two fundamental points:
- reminiscence delay: Pointer monitoring buildings end in discontinuous random reminiscence entry patterns. This prevents reminiscence coalescing and prevents you from making the most of the high-bandwidth reminiscence (HBM) bursting capabilities of recent accelerators.
- Compilation incompatibilities: Accelerators depend on static computational graphs (akin to Google’s XLA) for machine studying compilation. Customary makes an attempt use data-dependent management circulate and recursive branching, however these are incompatible with this paradigm and sometimes drive expensive spherical journeys between host units.
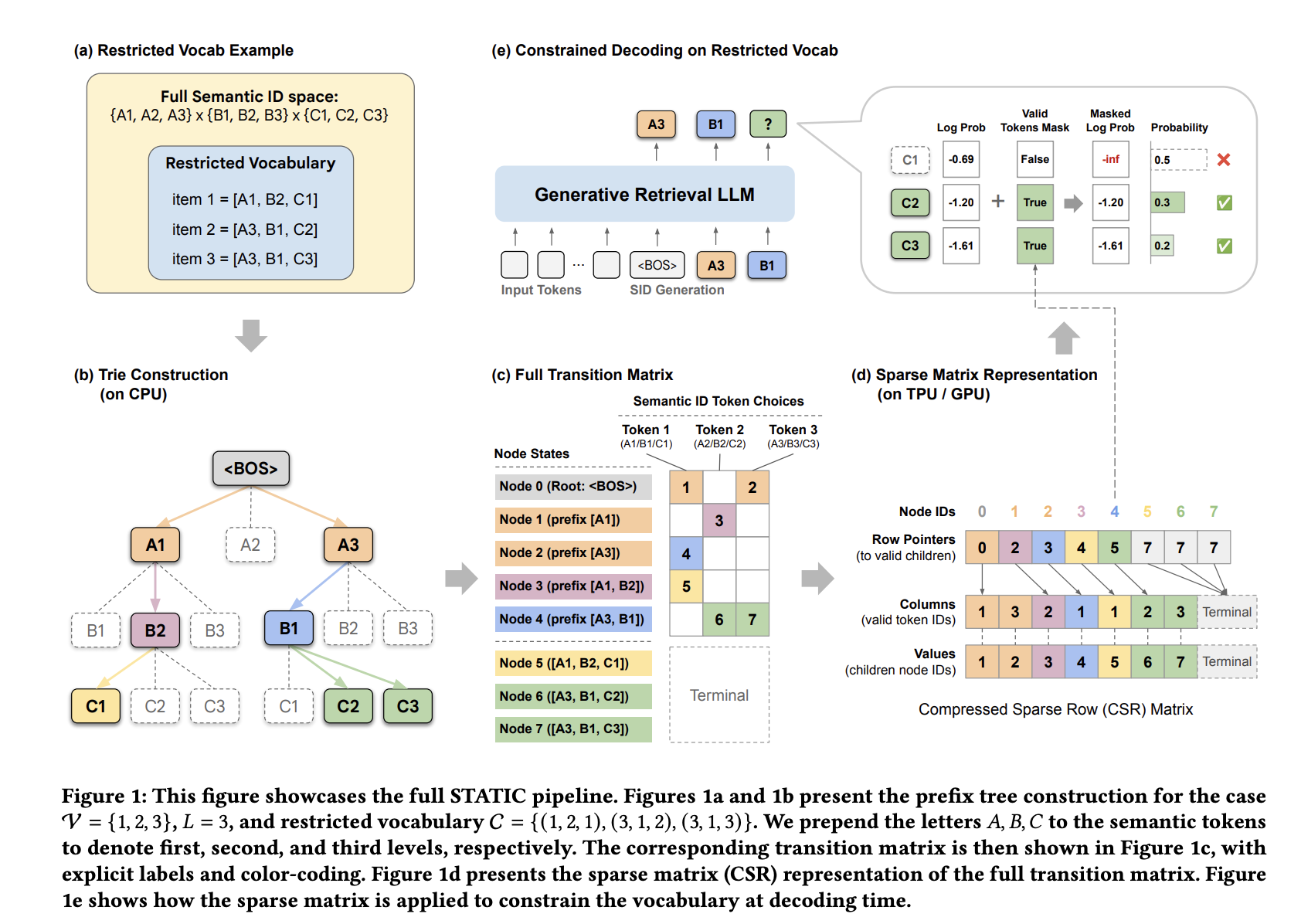
STATIC: Sparse transition matrix quick trie index
Google DeepMind and Youtube Launched by researchers static (Sparse Transition Matrix-Accelerated Trie Index for Constrained Decoding) to resolve these bottlenecks. As a substitute of treating the trie as a graph to be traversed, STATIC flattens it right into a static graph. Compressed sparse rows (CSR) matrix. This transformation permits irregular tree traversals to be carried out as totally vectorized sparse matrix operations.
Hybrid decoding structure
STATIC employs a two-phase lookup technique to stability reminiscence utilization and velocity.
- Excessive-density masking (t-1 d): first issues first dFor =2 layers (highest branching coefficient), STATIC makes use of a bit-packed dense Boolean tensor. This ends in ○(1) Lookup is probably the most computationally costly preliminary step.
- Vectorized Node Transition Kernel (VNTK): For deeper layers (I ≥ 3), STATIC makes use of a branch-free kernel. This kernel performs “speculative slicing” of a set variety of entries (Bt), corresponds to the utmost branching coefficient at that stage. Through the use of fixed-size slices whatever the precise variety of youngsters, your entire decoding course of stays a single static computational graph.
With this method, I/O complexity ○(1) It scales relative to the dimensions of the constraint set, whereas conventional hardware-accelerated binary search strategies scale logarithmically (○(log|C|)).
Efficiency and scalability
batch measurement 2, beam measurement (M)/70, STATIC confirmed vital efficiency enchancment in comparison with present strategies.
| technique | Latency overhead per step (ms) | Share of whole inference time |
| STATIC (ours) | +0.033 | 0.25% |
| Approximate PPV | +1.56 | 11.9% |
| hash bitmap | +12.3 | 94.0% |
| CPU strive | +31.3 | 239% |
| PPV correct | +34.1 | 260% |
STATIC is 948x speedup It outperformed CPU offload makes an attempt and outperformed a exact binary search baseline (PPV). 1033x. Semantic ID vocabulary measurement (|V|) will increase.
For a vocabulary of 20 million objects, the HBM utilization restrict for STATIC is roughly 1.5GB. In follow, as a result of uneven distribution and clustering of semantic IDs, the precise utilization is normally ≤75% of this restrict. rule of thumb for capability planning is roughly: 90 MB HBM for each 1 million constraints.
Introduction outcomes
STATIC was launched on YouTube to implement a “final 7 days” freshness constraint on video suggestions. The system offered a vocabulary of 20 million perishables with 100% compliance.
On-line A/B testing revealed the next:
- a +5.1% improve Contemporary video views in 7 days.
- a +2.9% improve Contemporary video views in 3 days.
- a +0.15% improve By click-through charge (CTR).
Chilly begin efficiency
This framework additionally addresses the “chilly begin” limitation of generative search, i.e. recommending objects that weren’t seen throughout coaching. By constraining the mannequin to the cold-start itemset of the Amazon evaluations dataset, STATIC considerably improved efficiency in comparison with the unconstrained baseline, recording 0.00% Recall@1. These checks used the 1 billion parameter Gemma structure. L = 4 tokens and vocabulary measurement |V|=256.
Vital factors
- vectorized effectivity: STATIC recasts constrained decoding from graph traversal issues into hardware-friendly vectorized sparse matrix operations by flattening the prefix tree right into a static compressed sparse row (CSR) matrix.
- Important speedup: The system achieves a latency of 0.033 ms per step, representing a 948x speedup in comparison with CPU offload makes an attempt and a 47x to 1033x speedup in comparison with the hardware-accelerated binary search baseline. +1
- scalable ○(1) Complexity: By attaining ○(1) I/O complexity relative to constraint set measurement. STATIC maintains excessive efficiency with a low reminiscence footprint of roughly 90 MB per million objects.
- Confirmed ends in manufacturing: Deployment on YouTube demonstrated 100% compliance with enterprise logic constraints, growing new video views by 5.1% and click-through charge by 0.15%.
- chilly begin answer: This framework allows generative search fashions to higher advocate cold-start objects, growing the efficiency of Recall@1 from 0.00% to non-trivial ranges on the Amazon Evaluations benchmark.
Please examine paper and code. Additionally, be happy to observe us Twitter Remember to hitch us 120,000+ ML subreddits and subscribe our newsletter. hold on! Are you on telegram? You can now also participate by telegram.


{kind=link}