


A content material author creates a weblog submit. A content material strategist decides which subjects to cowl. A content material engineer designs the techniques that produce content material and make it discoverable by people and AI.
On this submit, I’ll cowl what content material engineering truly is, its core parts, whose duty it’s, and how one can turn into a fully-fledged Content material Engineer.
Content material engineering is the follow of constructing the techniques that create content material, quite than producing content material piece by piece.
These techniques handle the work that used to take a seat on a author’s plate:
- Researching subjects
- Drafting and enhancing
- Optimizing for search and AI surfaces
- Publishing to a CMS
- Measuring what performs
A content material engineer designs the pipeline that strings these steps collectively utilizing AI, so their workforce can publish extra, sooner, and with out dropping model consistency or high quality.
There are two forms of content material engineer
The time period “content material engineer” will get utilized in two other ways:
The structured content material engineer
This engineer designs taxonomies and metadata schemas so massive organizations can publish constant content material throughout channels, merchandise, and languages. Suppose Dell’s assist docs or IKEA’s product data.
The AI pipeline content material engineer
The AI pipeline content material engineer automates the creation and optimization of content material so it may be discovered by search engine crawlers, AI bots, brokers, and no matter comes subsequent.
This text is in regards to the second sort.
4 overlapping practices outline content material engineering, and most engineers are juggling all of them at as soon as.

Pipeline design
Pipeline design means breaking the editorial course of into discrete, automatable steps.
For instance, a content material distribution pipeline may route a printed article via 5 levels: extracting key factors, producing format-specific variants, adapting every to a selected platform, scheduling publish occasions, and logging efficiency again to a dashboard.
Try Agent A: the new marketing agent from Ahrefs
We’ve just released Agent A, an AI agent platform with unrestricted access to Ahrefs data that can actually do marketing for you.
Run keyword research, analyze your competitors, optimize your content, make technical SEO fixes, and much more—all automatically, using state-of-the-art agentic AI models and Ahrefs’ world-class data.
Learn more about Agent A.
Skill and prompt engineering
Prompts are one-off instructions you give a model for a single task.
Skills are reusable, packaged instructions (often with examples or reference files) that a model can call on whenever a recurring task comes up.
Skills and prompts are how the pipeline knows what to do at each stage.
A drafting skill captures how a good article opens and closes, a citation skill captures the team’s sourcing standards, a formatting skill captures the shortcodes the CMS expects.
With skills and prompts, editorial decisions made once by a senior writer become available to the whole team every time the pipeline runs.
Knowledge and source-of-truth management
Pipelines break down without the right information feeding them.
Knowledge and source of truth (SoT) is the unglamorous foundation everything else rests on: making sure brand guidelines, product details, proprietary research, and SME interviews are structured and connected.
Without this, AI fills the gaps with generic language and information.
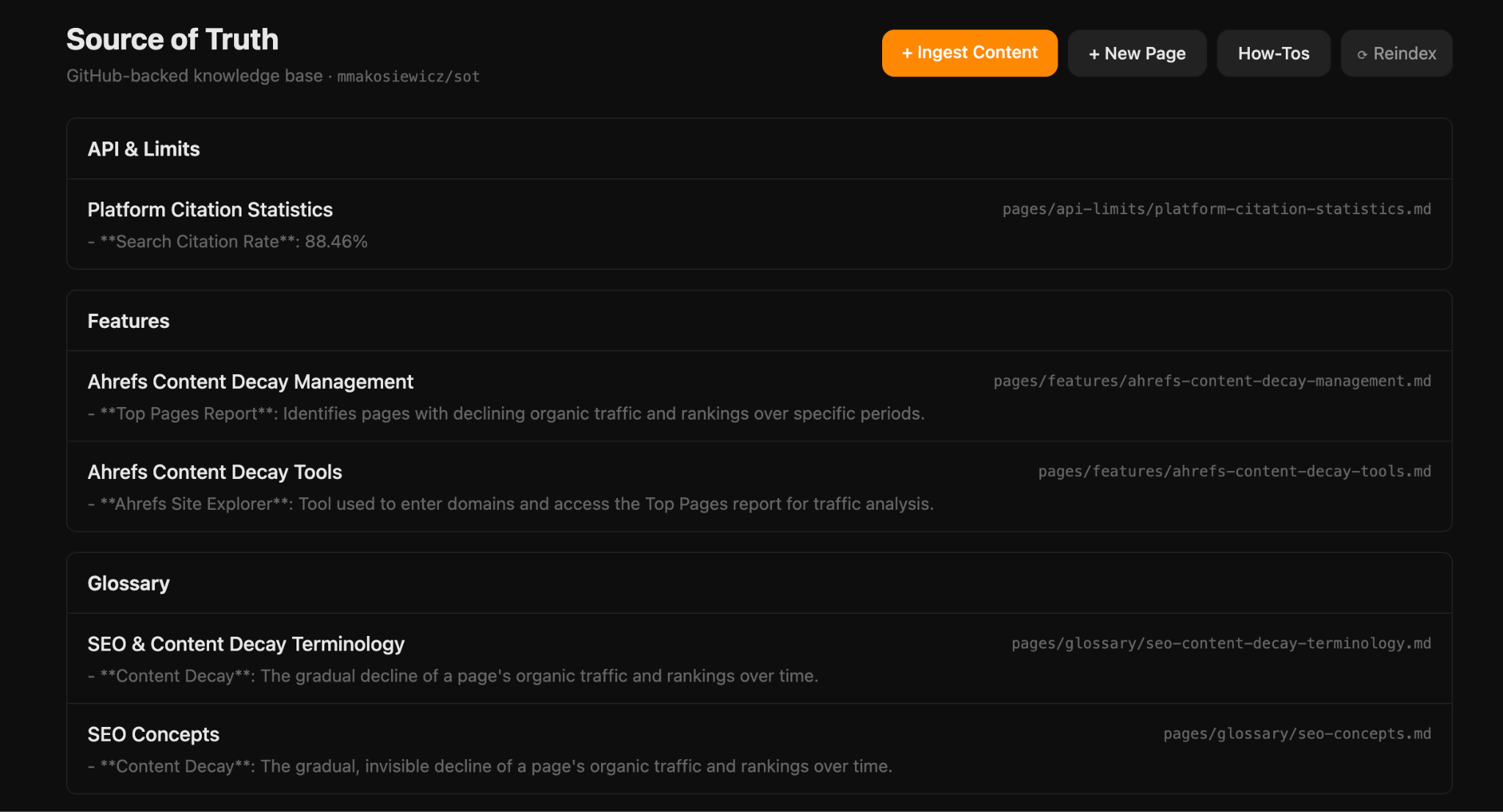
Mateusz’s Source of Truth knowledgebase built in Agent A
Orchestration and governance
Orchestration is the scheduling and triggering that turns a pipeline you manually start into one that runs itself.
Daily refresh jobs, weekly reports, event-triggered workflows.
Governance is the rules that stop it shipping bad work through fact-checking, citation verification, brand-voice enforcement, and human-review checkpoints.
A content material engineer is answerable for constructing and sustaining the AI-powered techniques a content material workforce makes use of to provide, optimize, and distribute work at scale.
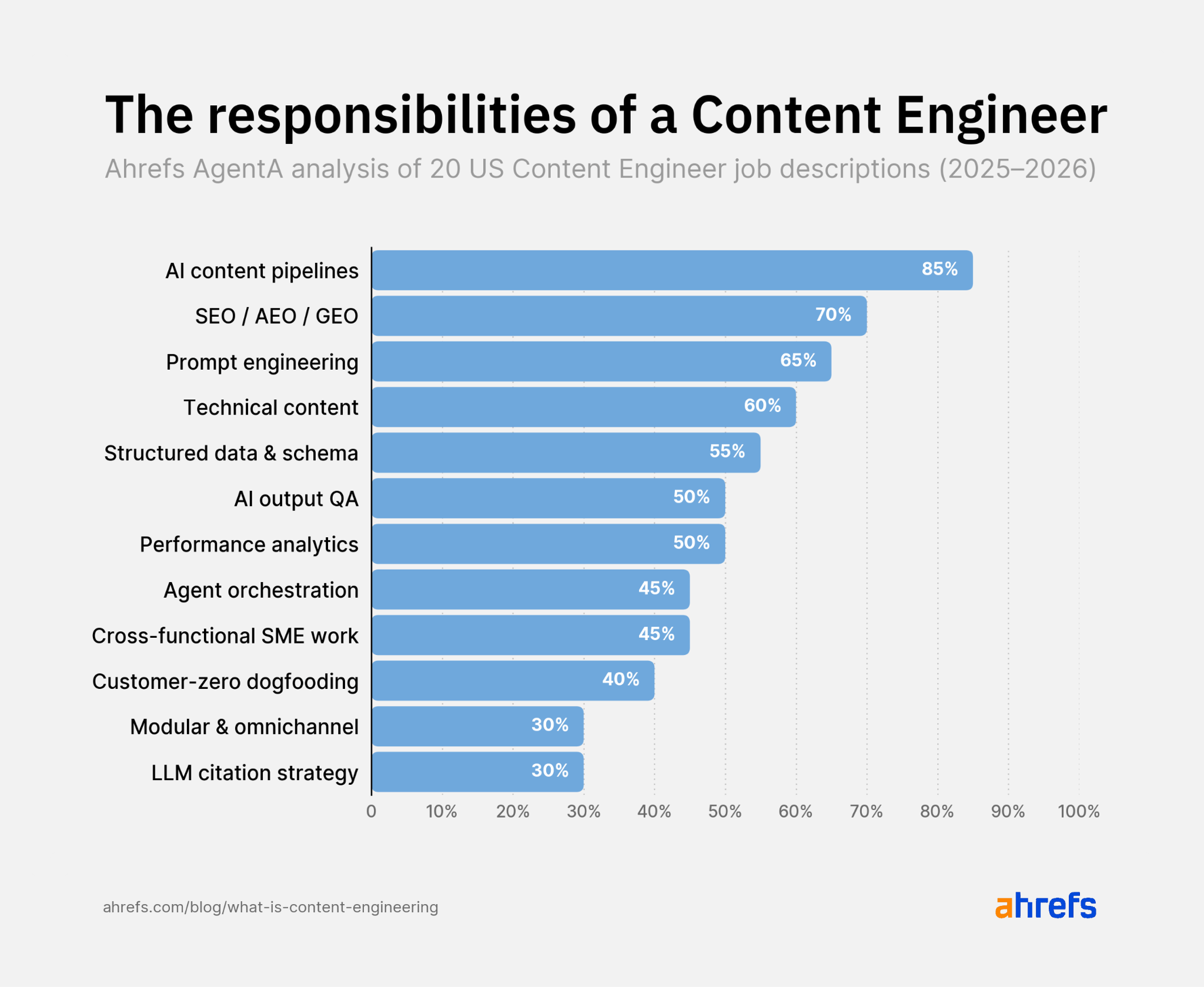
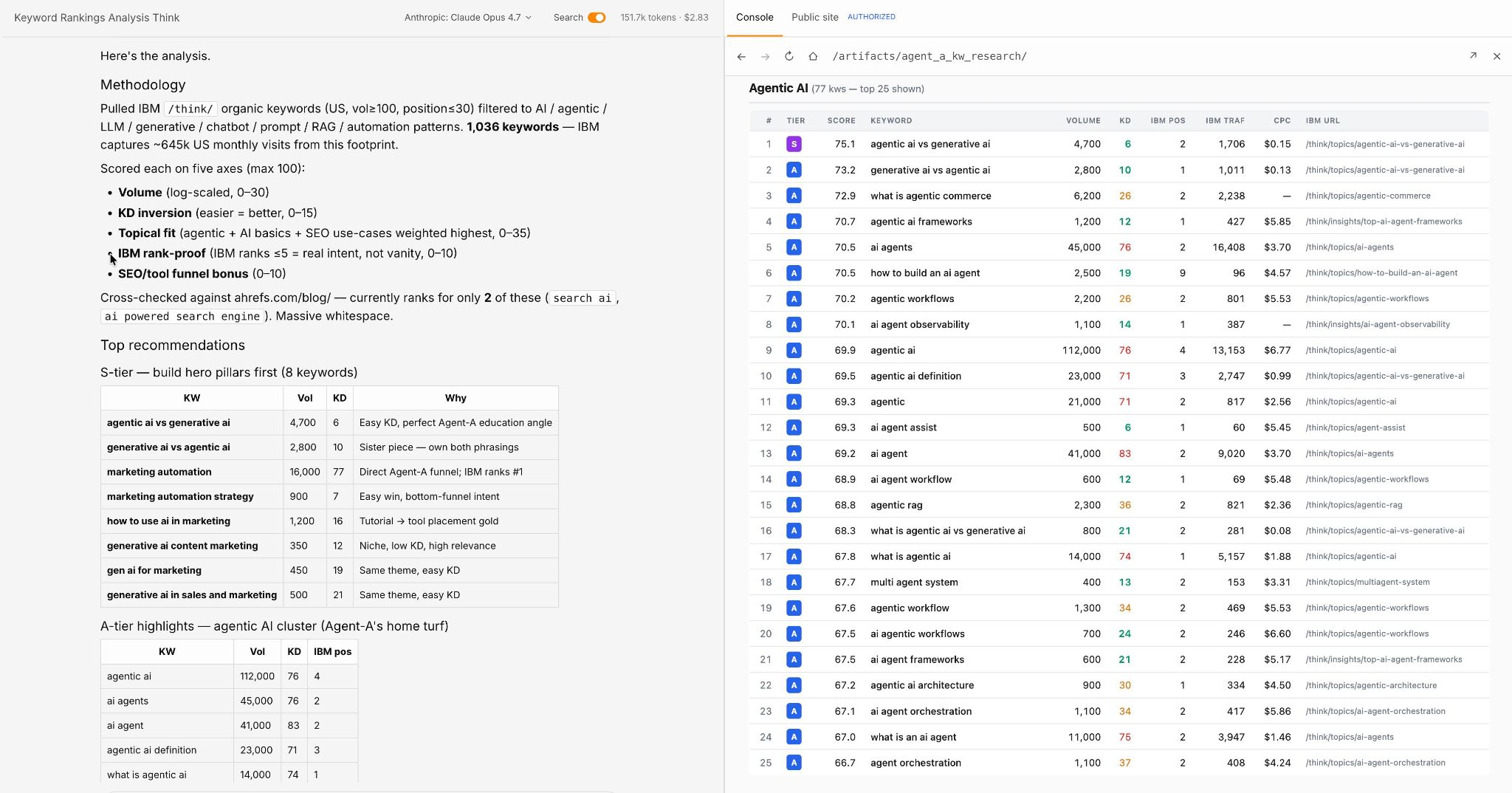
Utilizing Agent A, we analyzed 20 US “Content material Engineer” and “AI Content material Engineer” job descriptions posted in 2025–2026 to see what the function truly consists of.
The defining duty is constructing an AI-augmented content material pipeline (85%)—extra common than writing itself—adopted by website positioning/AEO/GEO (70%) and immediate engineering (65%).
In different phrases, the Content material Engineer is a techniques builder who occurs to jot down, not a author who occurs to make use of AI.
Right here’s a more in-depth take a look at what content material engineers truly do, and the way they assist the remainder of the workforce.

Content material manufacturing
Most content material groups hit a ceiling on what they’ll produce manually. Content material manufacturing engineering raises it.
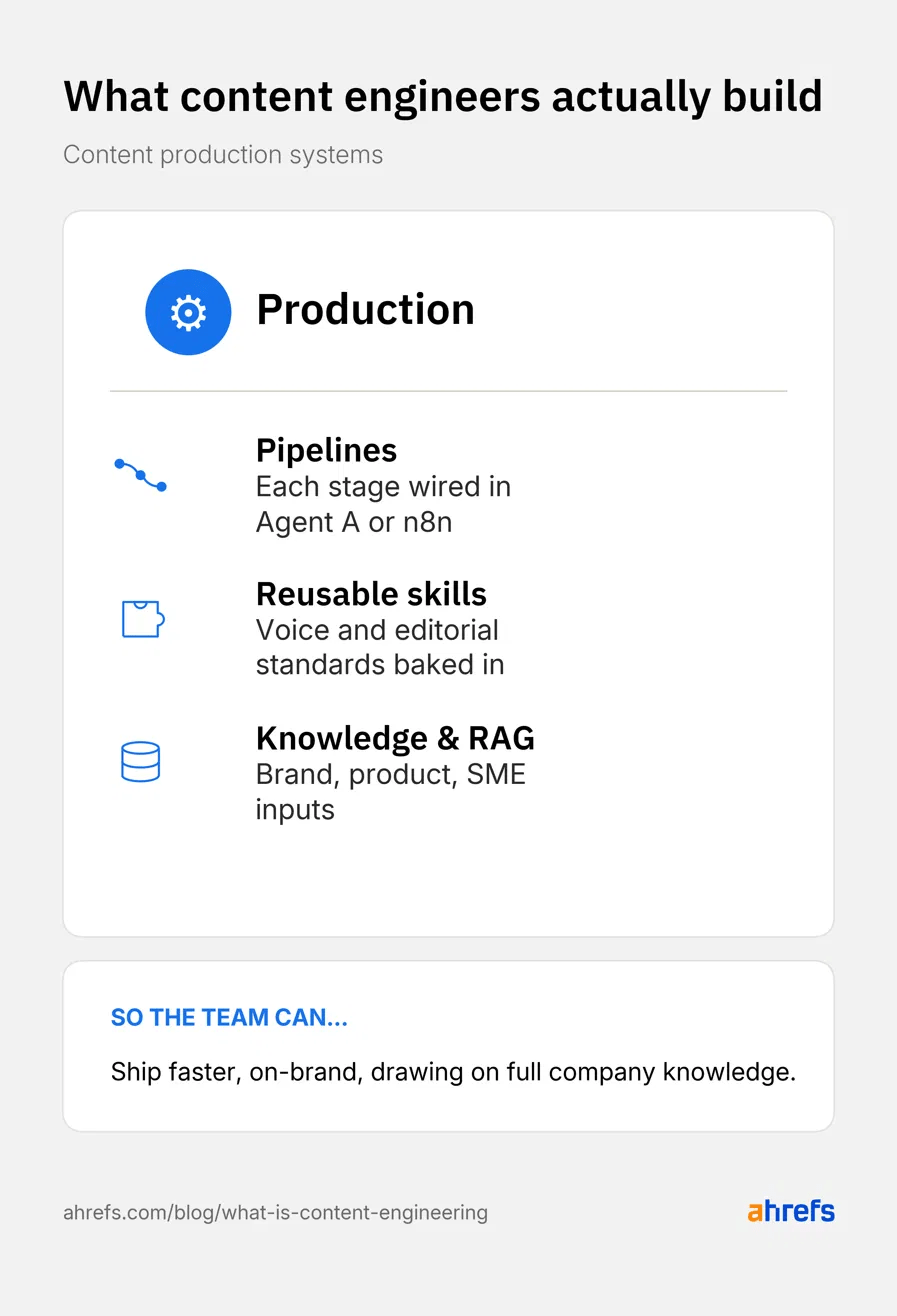
Content material manufacturing engineers assist groups…
Ship sooner
A content material manufacturing engineer builds pipelines that map every stage from analysis to measurement, wired collectively in instruments like Ahrefs’ Agent A or n8n. No person has to begin their content material from scratch.
Produce on-brand output each time
They construct reusable abilities, prompts, and customized directions that codify the workforce’s collective know-how. The entire workforce can name on the identical voice, construction, and editorial requirements.
Draw on the corporate’s full data
They construct inside data bases, Supply of Reality (SoT), and RAG techniques loaded with model pointers, product docs, ICPs, positioning frameworks, proprietary analysis, and SME interviews. The pipeline attracts on the corporate’s full data as a substitute of generic language from coaching knowledge.
Content material upkeep
Content material engineering additionally includes upkeep, which is the work of protecting revealed content material performing over time.
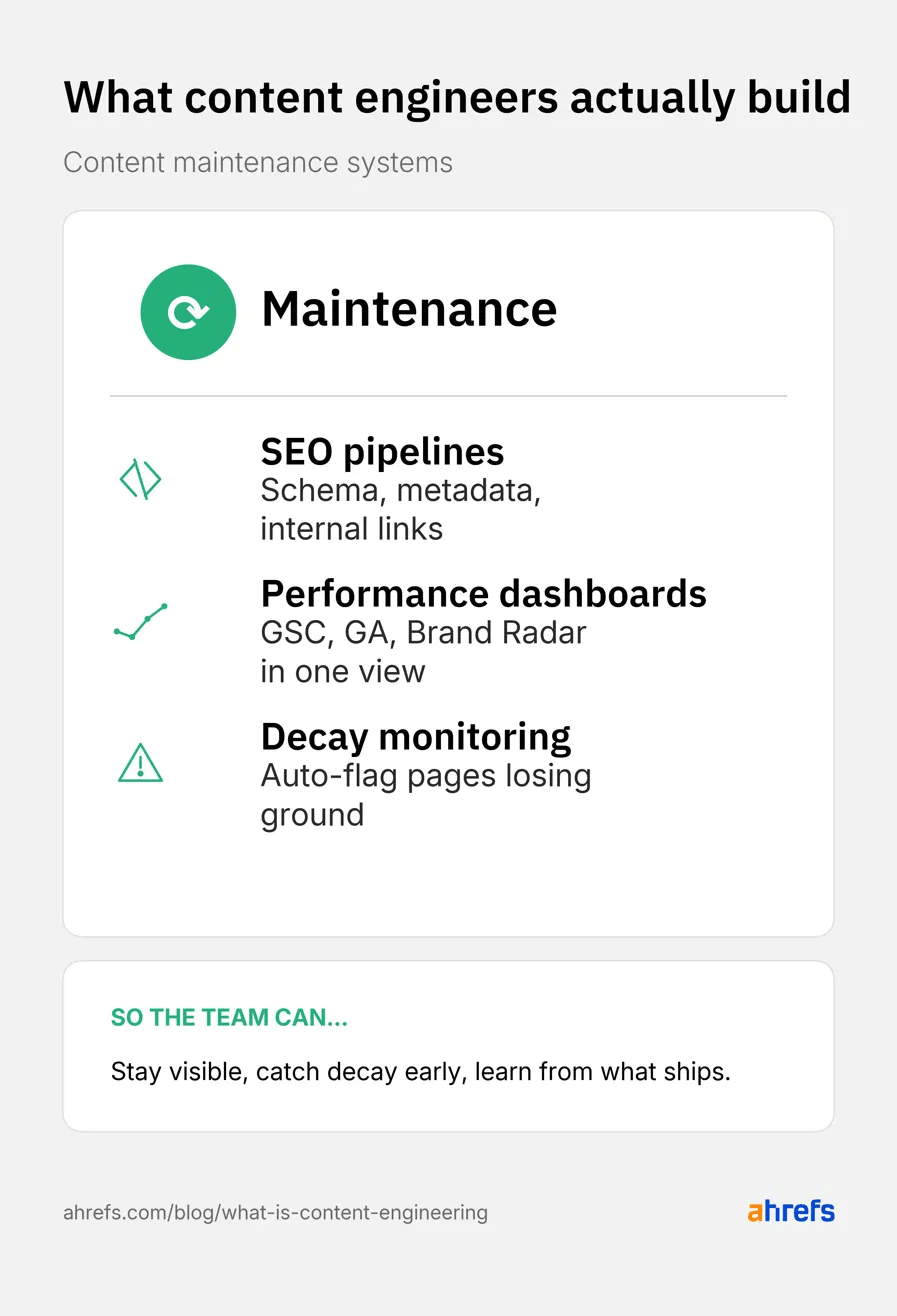
Content material upkeep engineers assist groups…
Keep seen throughout search and AI surfaces
A content material upkeep engineer builds automated website positioning pipelines that set guidelines on construction, schema, metadata, and inside linking on the template degree quite than page-by-page, and schedules refresh cycles so content material stays present and visual on each floor; together with search and AI.
Be taught from what they ship
They construct efficiency dashboards and suggestions loops that pull visitors and AI visibility knowledge from Google Search Console, GA, and Ahrefs Brand Radar into one weekly view. That data drives what gets retired or written next.
Catch decay before it hurts rankings
They build decay monitoring and refresh triggers that flag pages losing rankings, traffic, or AI citations, and queue them for an update. Whether that’s injecting fresher stats, new examples, or additional internal links.
Content distribution
Most content gets published, indexed, then forgotten. Content distribution engineering means the same source material can power a dozen touchpoints.
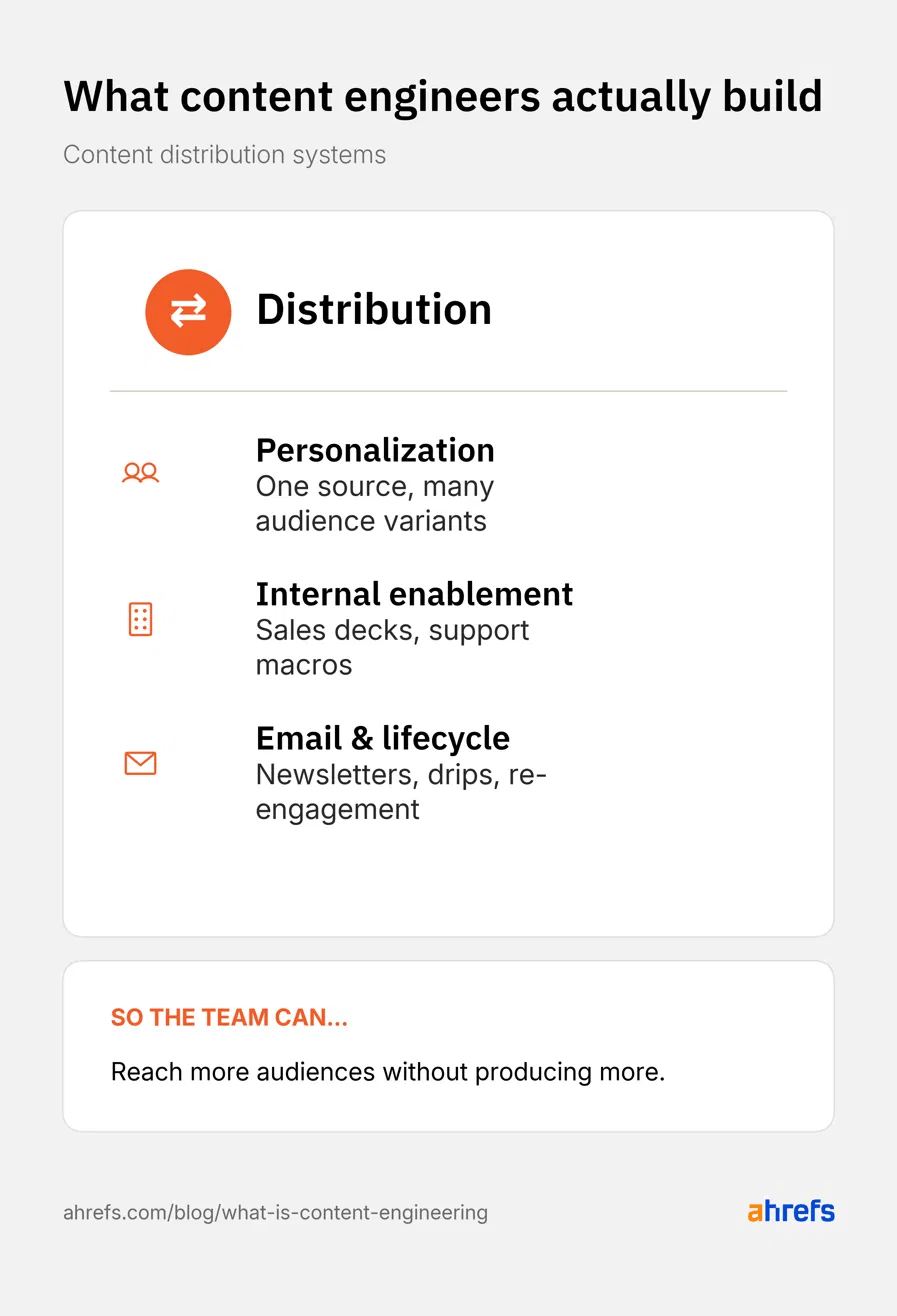
Content distribution engineers help teams…
Tailor content to different audiences
A content distribution engineer builds personalization and segmentation workflows that fork a single source piece into versions catered to different industries, roles, or lifecycle stages. For instance, that looks like local examples and tailored CTAs swapped in automatically.
Activate content beyond marketing
They build internal enablement pipelines that route published content into the systems other teams use: sales decks, battlecards, onboarding emails, support macros. Content stops dying at publish.
Reach readers through owned channels
They build email and lifecycle orchestration workflows that drop relevant content into newsletters, drip campaigns, and re-engagement sequences automatically, based on what’s been published and what each recipient has already read.
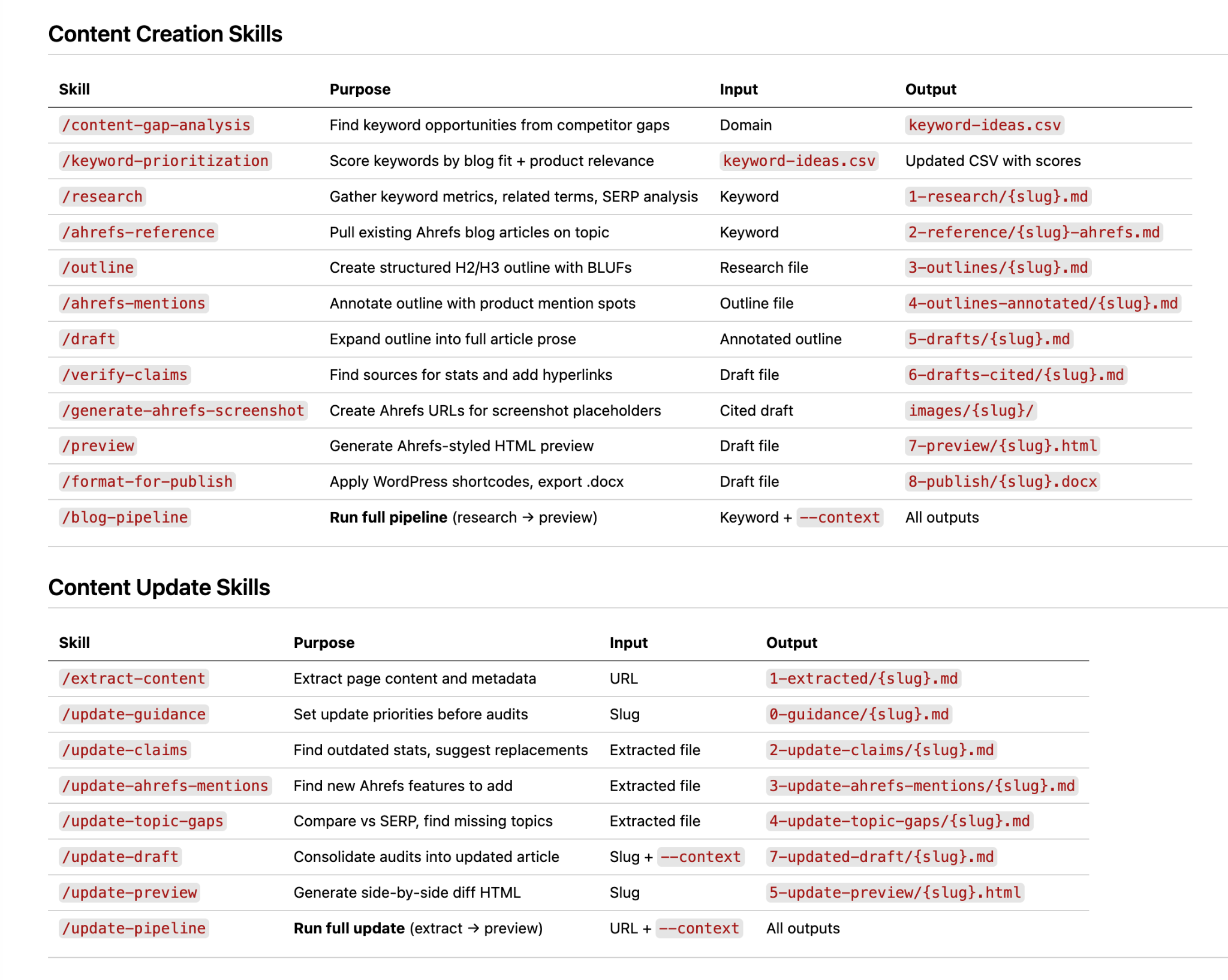
If you wish to construct quite than learn, right here’s the skeleton. Six abilities, one grasp talent.
You may get a V1 operating in a day.
Each pipeline you’ll ever construct is a few variation of this one, simply with extra abilities bolted on.
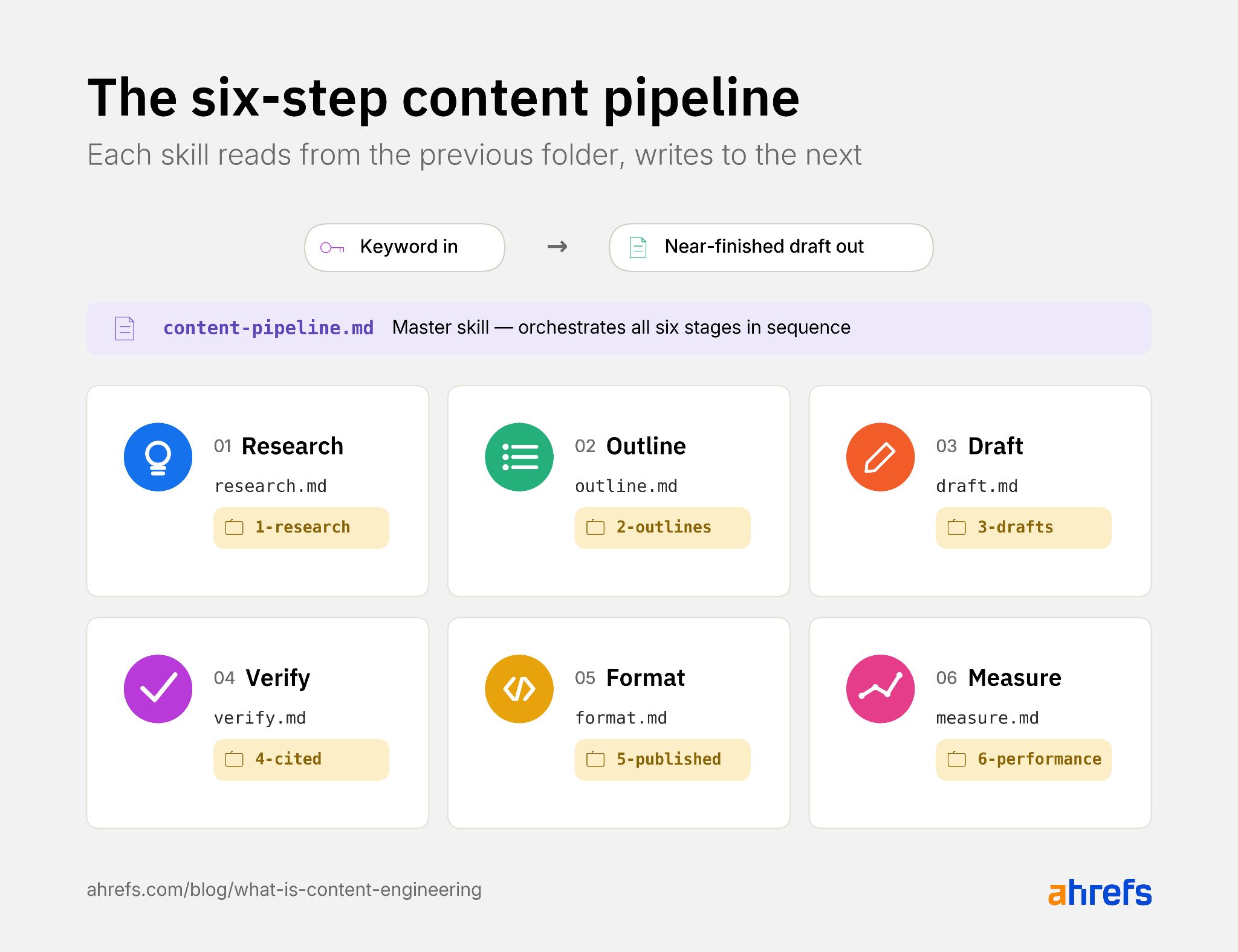
Earlier than you begin
Set up Claude Code, join the Ahrefs MCP, and create a folder referred to as content-pipeline. Inside it, create .claude/abilities/ (the place every talent lives) and 6 subfolders numbered 1-research/ via 6-performance/ (the place every stage’s output goes).
Or log in to Agent A, the place Claude and the Ahrefs connectors are already arrange. Simply ask it to create the folder construction for you.
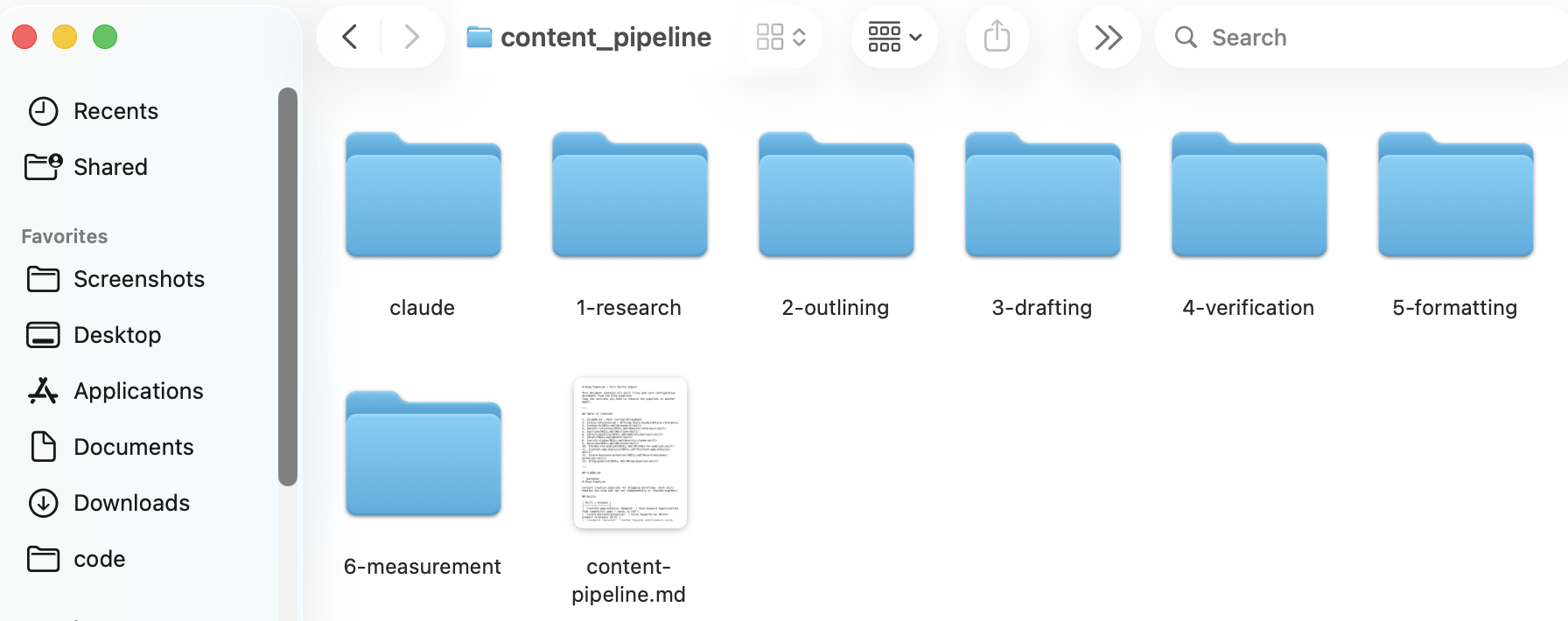
Every talent reads from the earlier folder and writes to the subsequent.
This file construction is the factor that turns a set of abilities right into a system. With out it, you’ll neglect which model of which output got here from which run.
Stage 1: Analysis
This talent takes a key phrase and produces a markdown file with key phrase quantity, problem, guardian subject, the highest 10 SERP outcomes, and the questions report, all pulled stay from an website positioning MCP (e.g. Ahrefs MCP).

The skill itself is just natural language instructions in plain markdown.
When called with a keyword, it tells the AI assistant to query the MCP for these specific reports, format the response as a markdown file with one section per data type, and save to the right folder.
Stage 2: Outlining
This skill reads the research file from stage one and produces an H2/H3 outline with target word counts per section and one-line notes on what each section should cover.
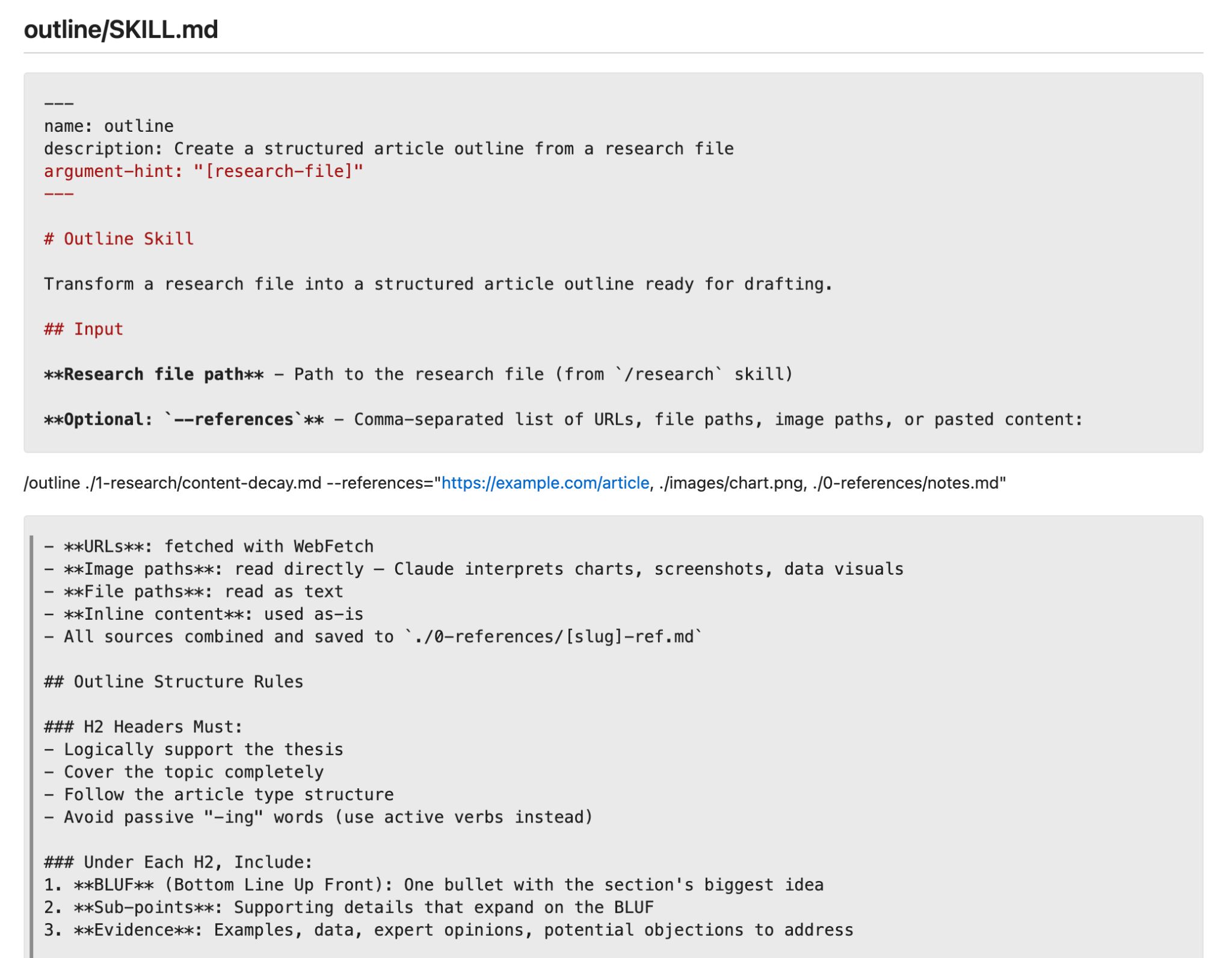
This is where your house style gets encoded; header patterns, section lengths, whether you lead with the answer (BLUF) or build to it.
Editorial decisions a senior writer would normally make on every piece get made once here, and applied automatically every time.
Stage 3: Drafting
This skill reads the outline and produces a full first draft. The draft skill should reference an /examples/ folder containing two or three of your best-published articles.
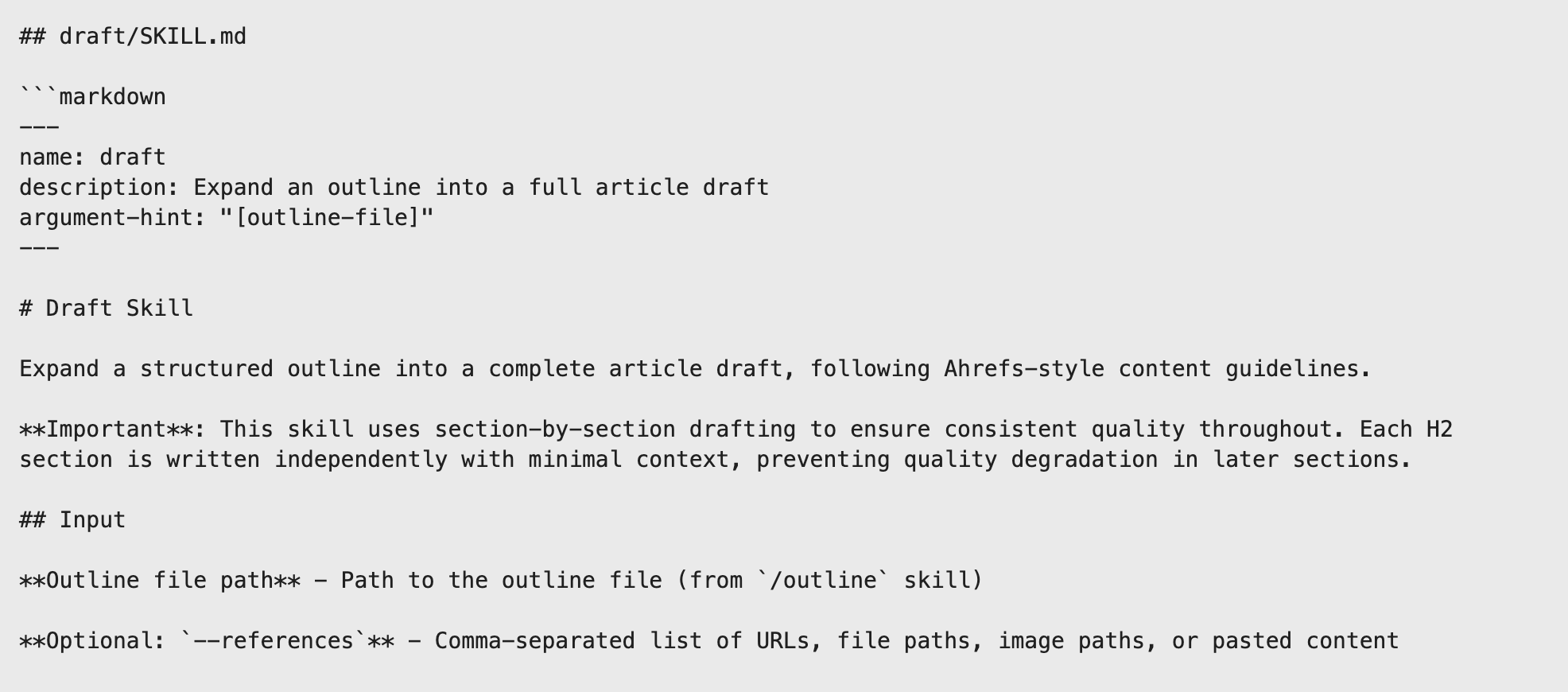
Without this, the output defaults to generic AI-speak.
With it, the system picks up your voice, including your sentence rhythm, paragraph length, and any small stylistic choices that make writing feel like yours.
Stage 4: Verification
This skill scans the draft for unsourced claims and either cites them or flags them.
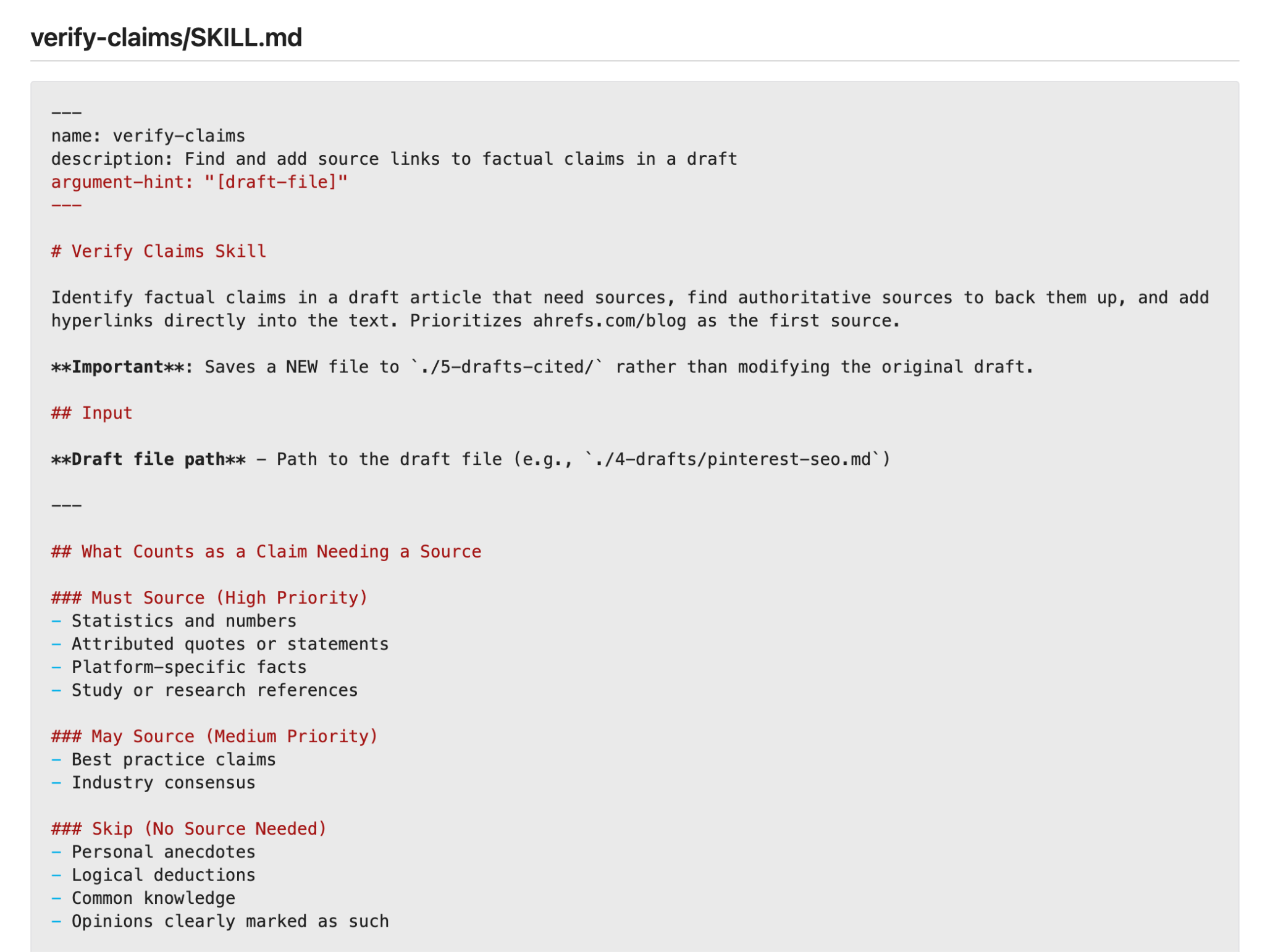
It should look for stats, dates, named studies, and quoted figures, then searches for primary sources for each one.
Found a source? Inline link added.
No source? Claim flagged with [UNVERIFIED] so a human can decide.
This stage is what stops hallucinations reaching publication.
Stage 5: Formatting
This skill applies your CMS’s structural requirements to the verified draft, and outputs a CMS-ready version with shortcodes, schema, and internal links applied.
The further this stage goes, the less manual cleanup happens after publication.
Stage 6: Measurement
This skill runs monthly on each published piece.
You can build it to pull traffic, ranking, and AI citation data from Search Console, GA, and Ahrefs Brand Radar, and flag decaying pieces for refresh.
This is what makes the system learn.
What worked in cycle one informs cycle two; cycle two shapes cycle three, and so on.
After a few iterations, you’ll have a pipeline producing drafts you’d actually publish.
Listed here are 4 suggestions for constructing a workforce of content material engineers…
1. Appoint a head engineer, allow them to show the mannequin—then scale
You don’t want a complete content material engineering operate from day one.
That you must spot the techniques thinker already on the workforce.
As Kieran Flanagan places it, the purpose is to search out one “Claude Code-pilled builder” who packages the workforce’s greatest workflows as abilities and lets everybody else hook up with what they construct.
2. Begin with one particular bottleneck
Decide one costly, repetitive course of to repair first—e.g. refreshing decaying content material or producing pages programmatically.
When you use Ahrefs, you’ve bought a head begin.
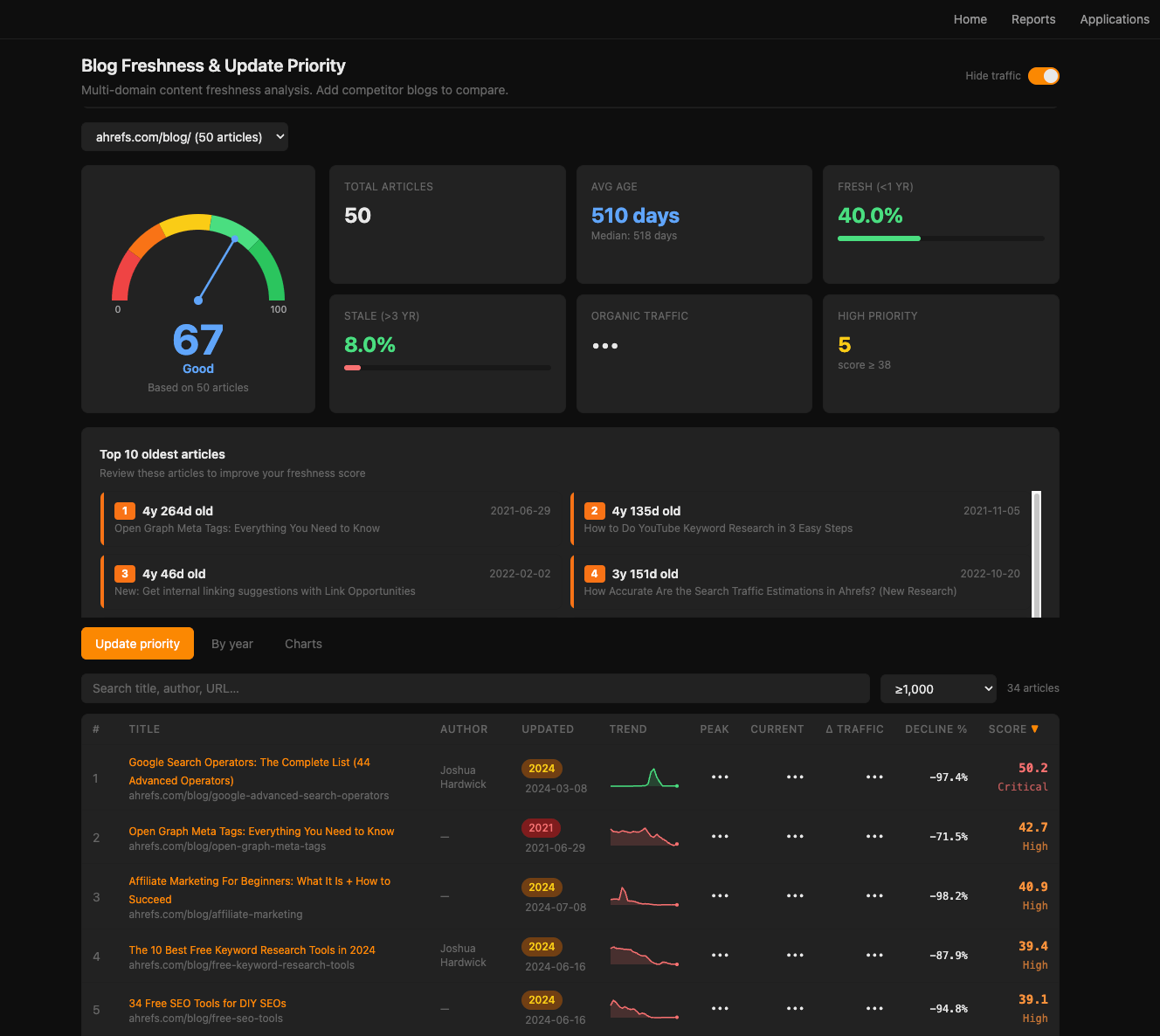
The diagnostic work already lives in your dashboard, and now in Agent A.
For instance, the app below is a ready-to-use Blog Freshness app that was built to flag decaying content.
3. Give them somewhere to build
Claude Code is one route.
Give your head content engineer the tools, data, and ability to fork their projects rather than have the whole team build from scratch and duplicate workload.
4. Measure what time they free up, not what they ship
It’s tempting to judge a content engineer on output volume.
But a better metric is time reclaimed for the rest of the team, whether that’s fewer hours on briefing, fact-checking, refreshing.
Report on what gets done with that freed-up capacity. If your writers are doing fewer rewrites and more original thinking, the role’s working.
I’ve tried engineering all types of content material these days. Some one-click drafts are nearly ship-ready; others I wouldn’t rush to place my title to.
Typically that’s as a result of the pipeline wants fixing, however most frequently it’s as a result of the content material is just not the proper match for engineering within the first place.
AI pipelines work greatest when the construction is predictable, the details are checkable, or the author can truly choose whether or not the output is any good.
Right here’s how I’d categorize the sorts of content material which are well worth the engineering effort.
Repetitive, repurposed, or templated content material
Some content material needs to be written, however doesn’t actually must be written.
The construction is identical each time, and the worth is within the data, not the prose round it.
I’m speaking: launch notes, weekly digests, recurring replace emails, changelog entries, and most repurposing work.
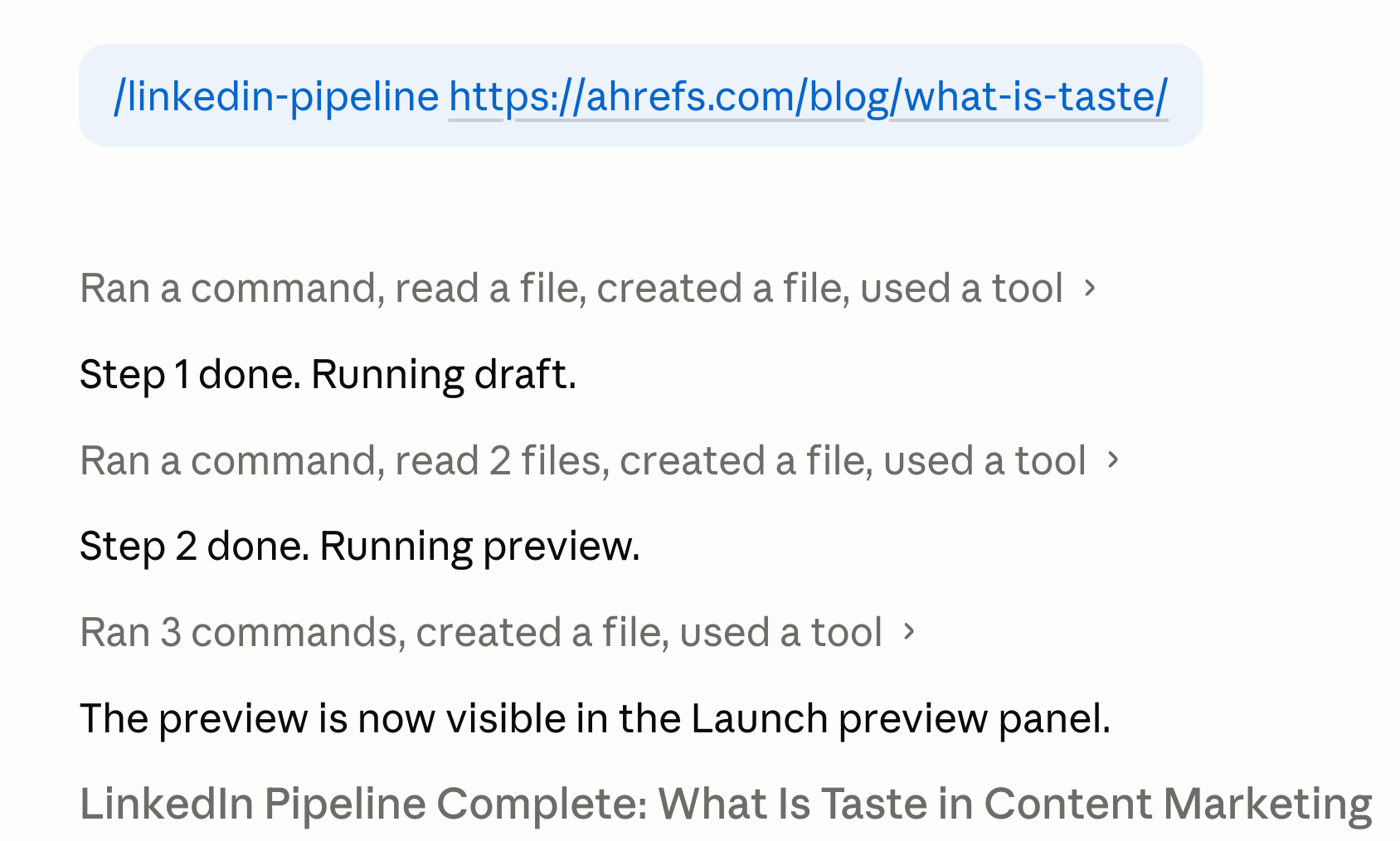
My colleague SQ constructed a talent for precisely this: at any time when a brand new Ahrefs weblog submit publishes, he runs /linkedin-pipeline on the URL in Agent A and generates three to 5 LinkedIn posts off the again of it.
All of them adhere to his voice guidelines, fold-line placement, and hook patterns specified by his talent recordsdata.
Engineering this sort of content material is the simplest win there may be: the pipeline produces it in your voice and the workforce stops spending inventive power on work that doesn’t want it.
Informational content material
How-tos, definitions, explainers, and comparisons are the apparent match for automated content material.
They’ve predictable shapes a system can templatize, details it will possibly verify.
They reply the sorts of queries AI assistants mostly get requested.
Economically, they make sense too. Creating informational content material from scratch has diminishing returns now that greater than 58% of clicks are being eaten by AI.
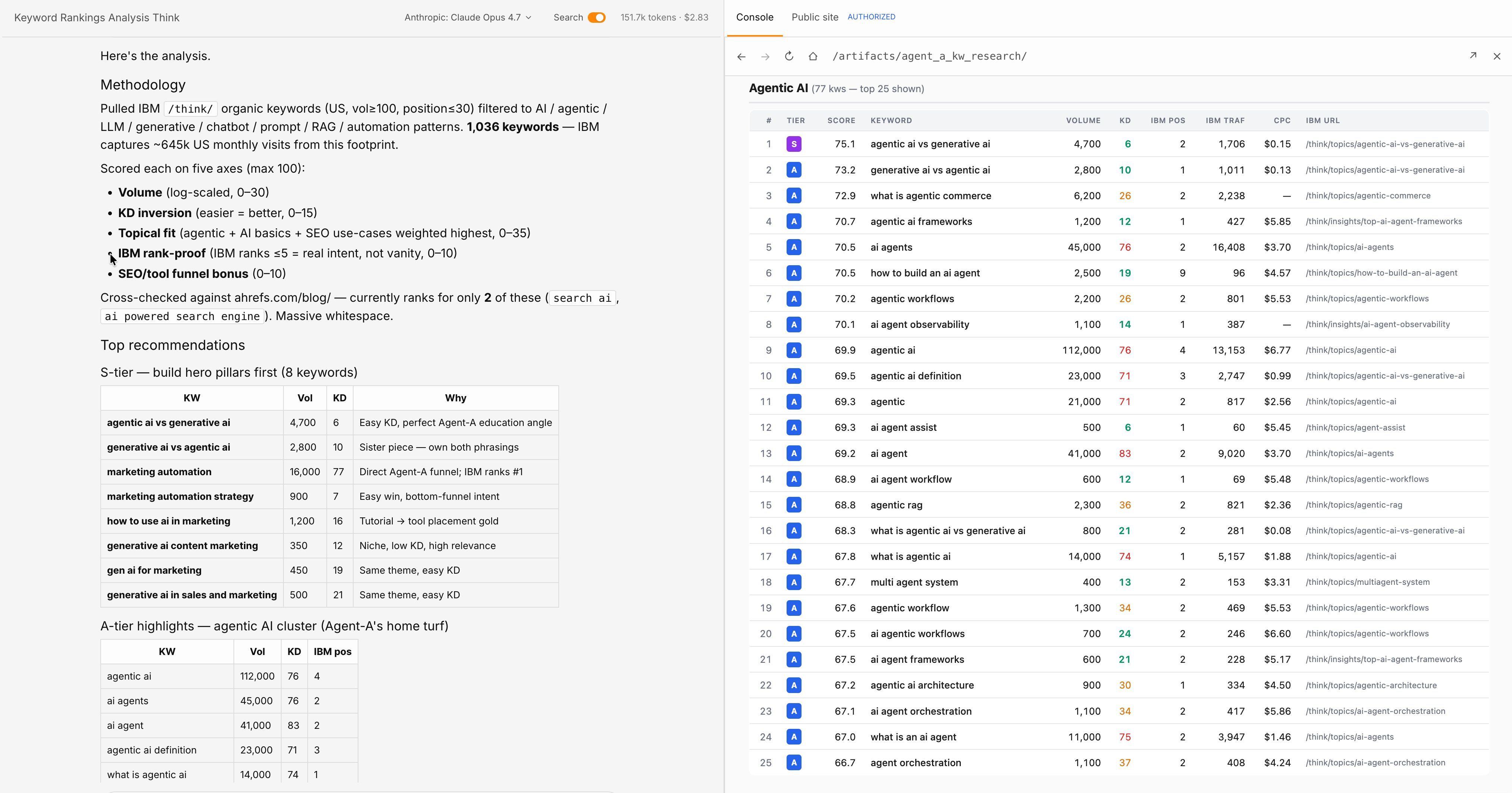
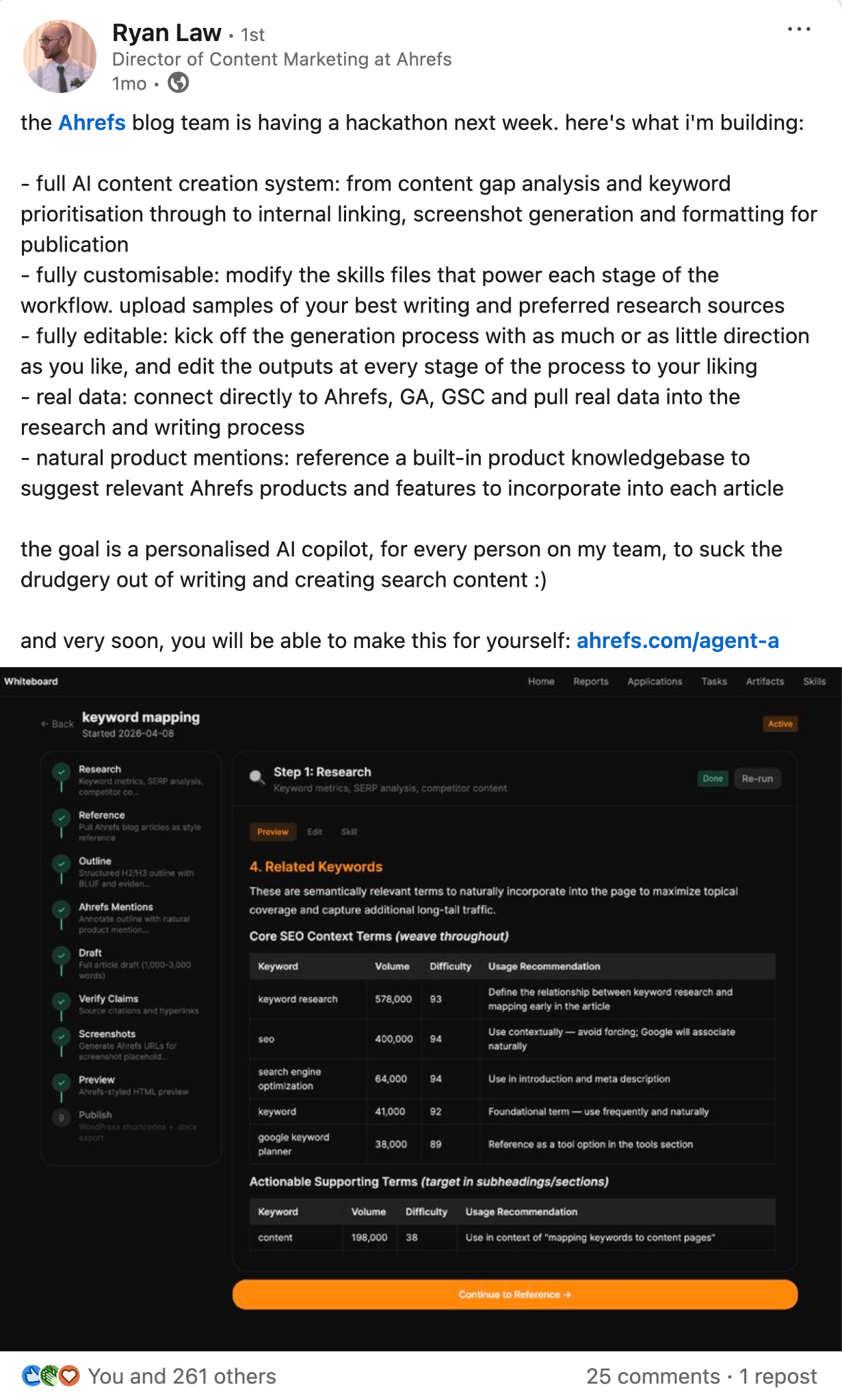
Ryan Law turned the Ahrefs informational content material course of into code: 23 abilities in Claude Code (and now Agent A), one for every stage of how a weblog will get made, plus a grasp talent that runs them end-to-end.
A key phrase goes in, a near-finished draft comes out; normally inside ten minutes.
Every talent outputs its personal file, so any step may be reviewed or re-run with out restarting.
Subjects you already know inside out
When a subject properly sufficient, the system drafts and also you edit—your experience is what stops unhealthy output reaching the web page.
However engineer content material on topics you’re unfamiliar with, and also you’re placing loads of religion in AI being proper about issues you may’t confirm, and that’s how unhealthy content material works its approach onto your web site.
Even when it doesn’t, you find yourself doing all of the fact-checking retrospectively, which simply defeats the entire level. Any time you save on drafting will get added on on the different finish.
“Expertise issues: AI content material is just not, by default, good. This course of works properly as a result of it mirrors our current human editorial course of, constructed from a long time of collective content material advertising and marketing expertise.’ ” —How I Do Content Engineering with Claude Code, Ryan Law, Director of Content material at Ahrefs
Content material that makes use of proprietary knowledge
Techniques constructed round an organization’s inside knowledge—buyer interviews, gross sales name transcripts, product analytics, assist tickets—produce content material no person else can, even on subjects that don’t but have a physique of public writing.
This is likely one of the most defensible types of content material engineering as a result of the moat is the information, not the workflow.
Right here’s a terrific instance of this from Tiffany Kroll, Director of Development at Prerender
“What I’m constructing—Athena—is GTM intelligence that learns from each buyer dialog. Gross sales calls, CS calls, person interviews, podcasts, plus our product utilization knowledge and finally exterior alerts like competitor exercise and class momentum. It watches patterns: when language shifts, when objections begin trending, when gross sales is listening to one factor however advertising and marketing is writing about one thing else. Proper now we run 30+ calls a month and no person mines them. Gross sales hears one factor, advertising and marketing writes one other. Athena closes that loop.”

Evergreen content material with an extended shelf life
AI techniques are solely pretty much as good as the fabric they need to work with.
For established subjects, there’s a long time of writing, analysis, and dialogue the system can pull from.
I engineered a weblog on content decay that took almost no time to edit and ship, and it’s performing pretty well organically.
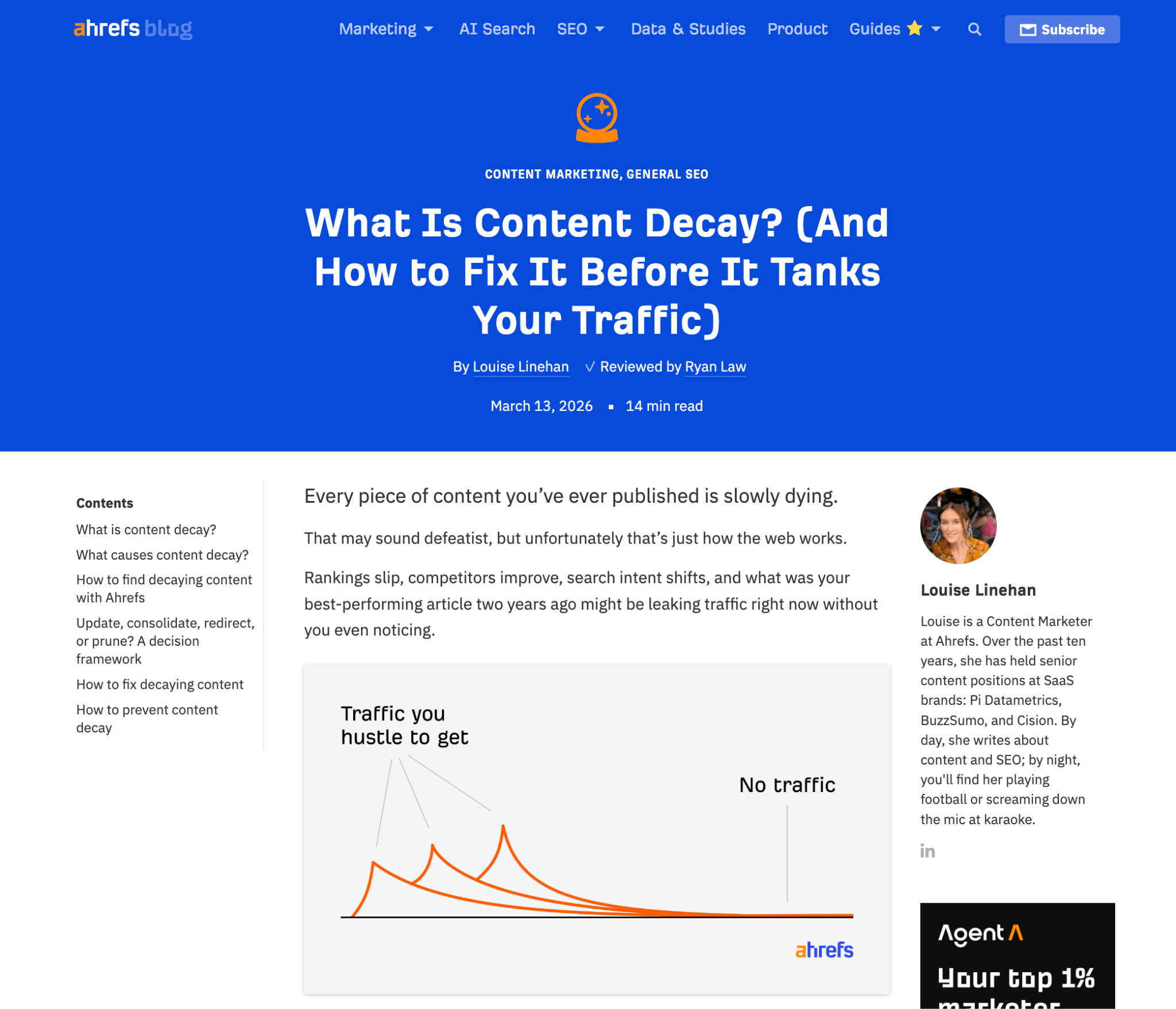
It worked because the principles of content decay haven’t shifted much over the years, so the system had plenty of good material to draw on; and since it’s an evergreen topic, the blog won’t need a major rewrite any time soon.
A blog on the “best AI tools”, on the other hand, would need rewriting every few months to stay relevant.
The whole point of engineering content is that the work compounds.
You build the system once and it keeps producing.
If what it produces needs a constant rewrite, that undermines the whole value of the workflow.
Programmatic content
This is content built at scale from templates—location pages, currency conversion pages, app integrations, glossary entries.
It’s where content engineering pays back hardest, but also where it goes wrong most often.
The pages that work—Wise’s forex conversion pages, Zapier’s app pages, even our personal Prime Web sites pages—succeed as a result of they’re constructed on proprietary knowledge the reader can truly use.
The pages that get penalized by Google are those full of reshuffled SERP content material dressed up as one thing new.
As Ryan Law places it:
“Related, distinctive knowledge is normally what makes the distinction between useful content material and spam.”
When you’ve bought the information to again it up, engineering content material at this scale is precisely what the system is constructed for.
No knowledge or authentic insights? You’re simply scaling spam.
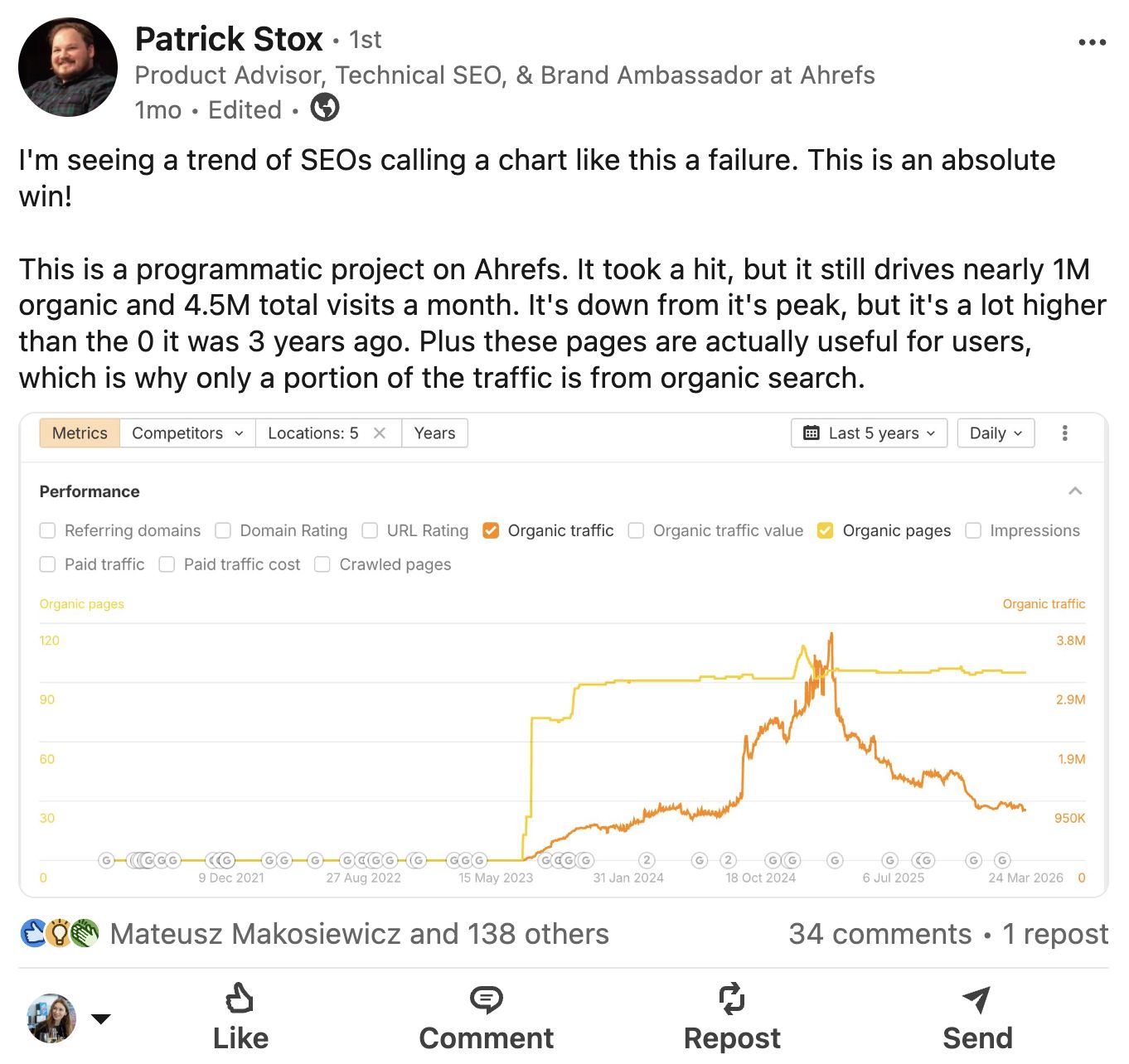
We threw our hat into the ring with our personal programmatic content material. Though visitors has dropped off, we nonetheless get 4.5M extra visits based mostly on the power of our proprietary knowledge.
Content material that updates itself
Auto-detecting when stats are outdated, when linked sources have moved, when rating has slipped, when a competitor has revealed one thing newer.
That is the place the worth of content material engineering is within the upkeep.
Right here’s a first-pass try at that.
I constructed The Weblog Refresh Engine with Agent A.
It doesn’t automatically draft the content once it finds an update opportunity… yet.
But it does do some other pretty cool things.
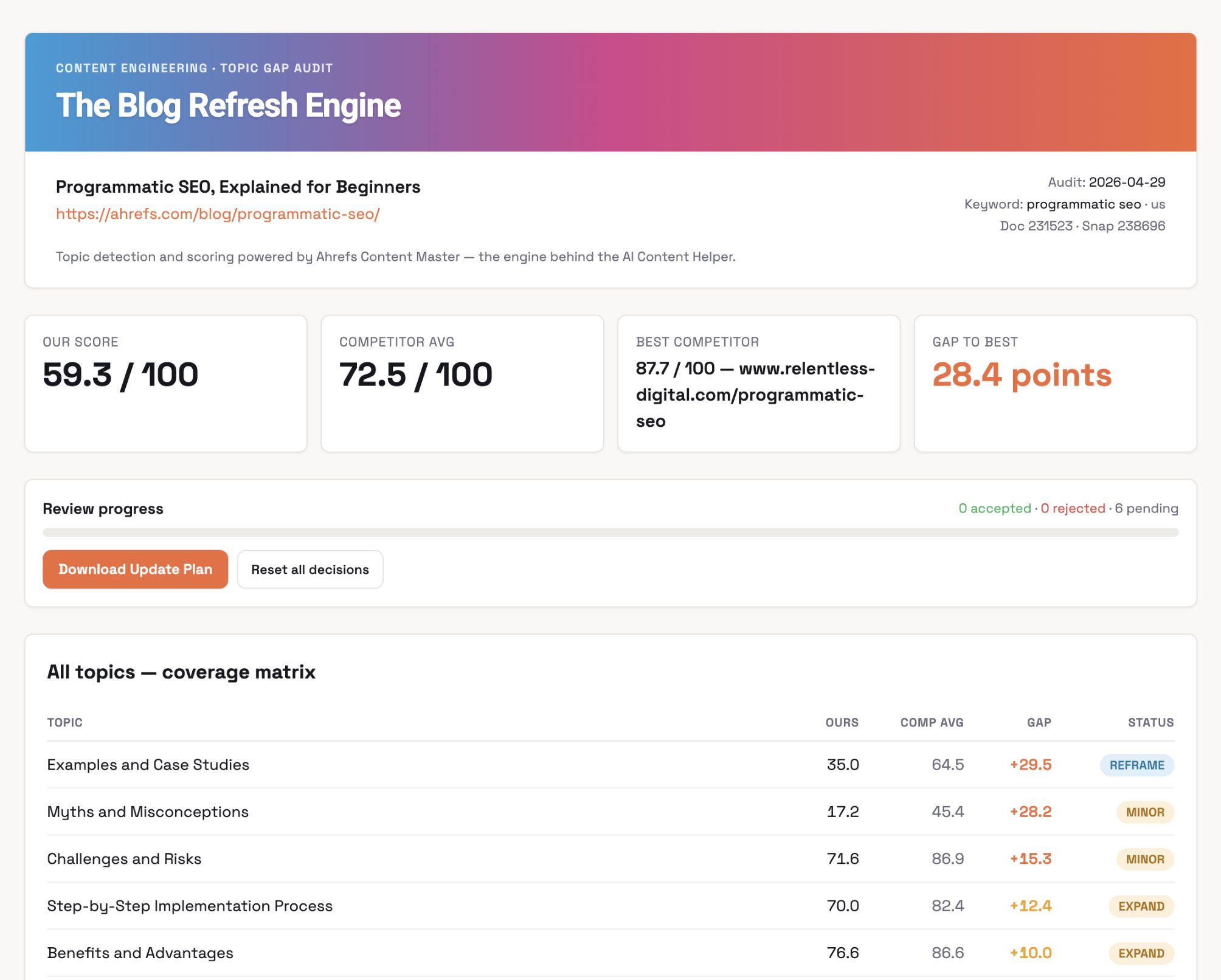
For instance, it looks at an existing blog post, compares it against what’s currently ranking using Ahrefs’ AI Content Helper, and tells you which topics you’re missing or under-covering.
You get a list of accept/reject cards for suggested updates, and for the ones you accept, it drafts replacement paragraphs.
The drafts are the interesting part.
Instead of paraphrasing competitors (the usual failure mode of AI writing tools), it pulls from my own swipe file—every social media post, article, and video clip I’ve saved over the years—and uses those as raw material. 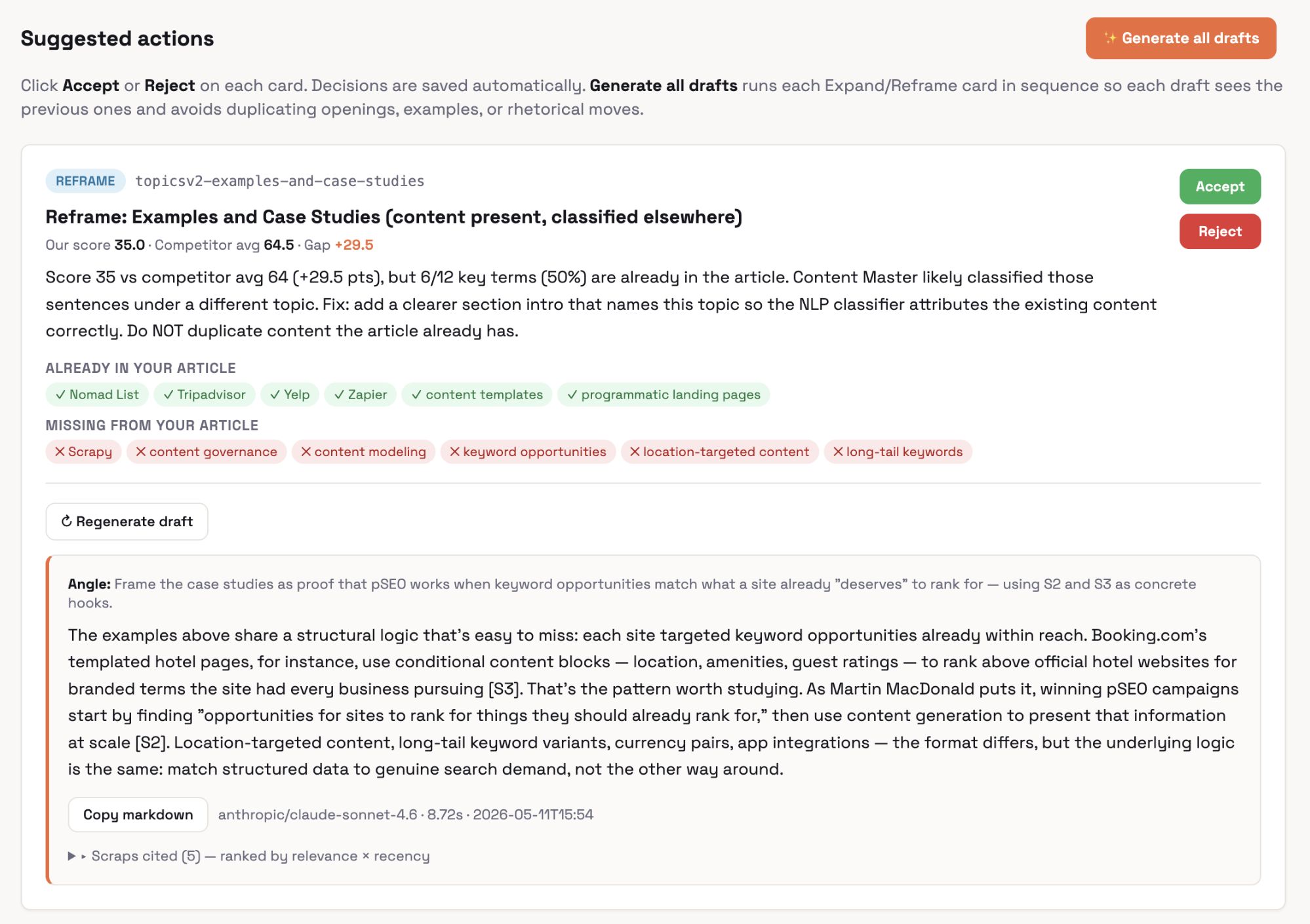
When you tackle a content material engineering function, you’ve bought two choices.
You can begin with a managed AI advertising and marketing agent that handles the infrastructure for you, or you may construct the stack your self.
Managed AI advertising and marketing brokers
In this sort of setting, you construct workflows by describing what you need the agent to do in pure language.
Ahrefs’ personal model is Agent A, which comes with Ahrefs data access built in, so keyword research, SERP analysis, and AI-citation tracking are wired in already.
It’s the fastest way to start if your work centres on SEO and content data.
Your own DIY stack
If you’d rather build from individual parts for more control, deeper customization, or because your stack doesn’t centre on Ahrefs, here’s what you should add to your toolkit.
Knowledge base
This is where the raw material lives. Think brand guidelines, product docs, positioning frameworks, SME interviews. Obsidian, Notion, or Confluence all work; whichever your team already uses is usually the right answer.
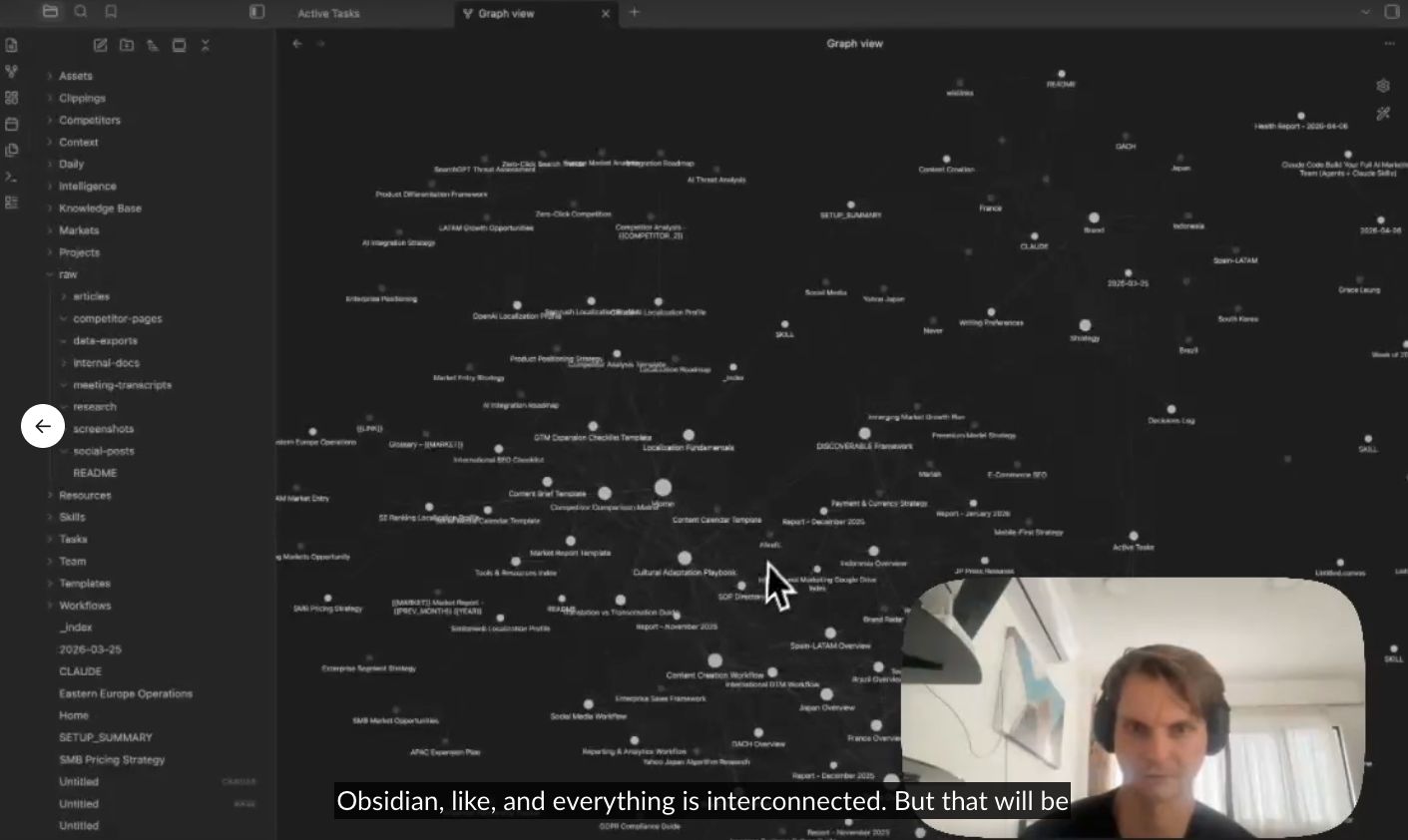
Our Head of International Marketing, Erik Sarissky, has linked his Obsidian to Claude Code and constructed his personal data base
Utilizing Obsidian with Claude Code, you may build an LLM Wiki; a structured, interlinked data base Claude extracts concepts from and updates each time you add a brand new supply. Over time, as a substitute of forgetting what you’ve uploaded, it builds a persistent reminiscence of your context that will get richer with each doc.
AI coding setting
That is the place you construct the pipeline, encode the principles it follows (construction, metadata, formatting, citations), and chain abilities collectively. Claude Code is the most typical start line; Cursor is the choice if you happen to’d quite work in an IDE.
Knowledge sources
Your pipeline wants stay context past your data base. As an illustration, Ahrefs’ API and MCP plug in website positioning and AI knowledge, and Firehose handles something that isn’t behind an API.

Analytics
The information your content material generates shapes what you produce subsequent.
Google Search Console and Google Analytics cowl first-party visitors; Model Radar covers AI search visibility.
Wiring these in creates the suggestions loops that flip a static pipeline into one which improves with each run.
Workflow automation
Claude Code runs in your laptop computer, and the second you shut it, nothing occurs.
As quickly as you want scheduled jobs, webhooks, or something operating when you’re asleep, you want a server. n8n, Make, Gumloop, and Agent A all deal with this natively within the cloud.
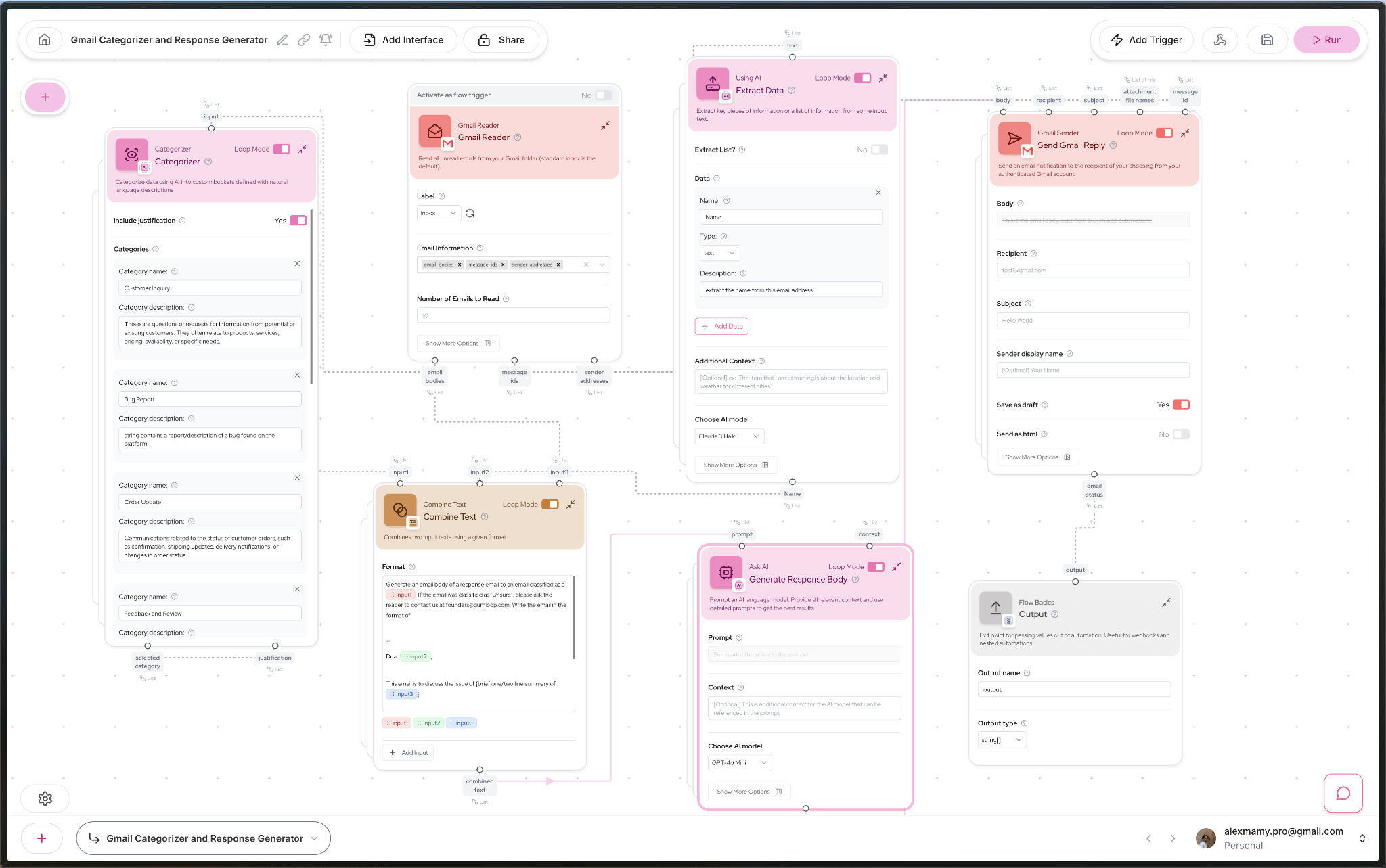
Picture from Reddit thread: I developed an AI workflow that automatically responds to emails and saves 6h/week on Gumloop
Content material administration
Your pipeline has to publish someplace.
Most groups have already got WordPress, Webflow, Sanity, or Contentful in place.
The job is connecting the pipeline to the CMS’s API and pushing as a lot of the formatting work upstream as potential.
Model management
Git and GitHub turn into important the second you will have greater than a handful of abilities or configs.
They allow you to department, evaluation, and roll again modifications the identical approach builders do.
Closing ideas
When you engineer content material properly, you’ll spend much less of your week making content material, and extra of it deciding what’s truly price making.

{kind=link}