


Launched by Cohere AI Labs little ayaa household of small language fashions (SLMs) that redefines multilingual efficiency. Many fashions scale by growing parameters, however Tinyaya 3.35B parameters An structure that delivers cutting-edge translation and era to the world. 70 languages.
This launch contains 5 fashions. Tiny Aya Base (pre-trained), Tiny Aya World (Balanced Instruction Adjustment), and three region-specific variants —earth (Africa/West Asia), fireplace (South Asia), and water (Asia Pacific/Europe).
structure
Tiny Aya is constructed on the Transformer structure, which is purpose-built for high-density decoders. The primary specs are:
- parameters: Complete 3.35B (2.8B non-embedded)
- layer:36
- vocabulary: 262k tokenizer designed for honest language illustration.
- Be aware: Full consideration (3:1 ratio) with interleaved sliding home windows and grouped question consideration (GQA).
- context: 8192 tokens for enter and output.
The mannequin was pretrained 6T token Use a Warmup-Steady-Decay (WSD) schedule. To take care of stability, the group used the next methodology: SwiGLU I ran the activation and eliminated all bias from the dense layer.
Superior post-training: FUSION and SimMerge
To fill the hole in low-resource languages, Cohere used artificial knowledge pipelines.
- Fusion of N (FUSION): The immediate is distributed to the “instructor group” (COMMAND A, GEMMA3-27B-IT, DEEPSEEK-V3). Choose LLM, fuserextract and mixture the strongest parts of the response.
- Regional specialization: The mannequin was fine-tuned in 5 regional clusters (South Asia, Africa, and so forth.).
- simmerge: To forestall a “catastrophic forgetting” of worldwide safety, regional checkpoints have been built-in with the worldwide mannequin utilizing the next strategies: simmergeselects the very best merge operator based mostly on the similarity sign.
Efficiency benchmark
Tiny Aya World constantly beats bigger and related rivals in multilingual duties.
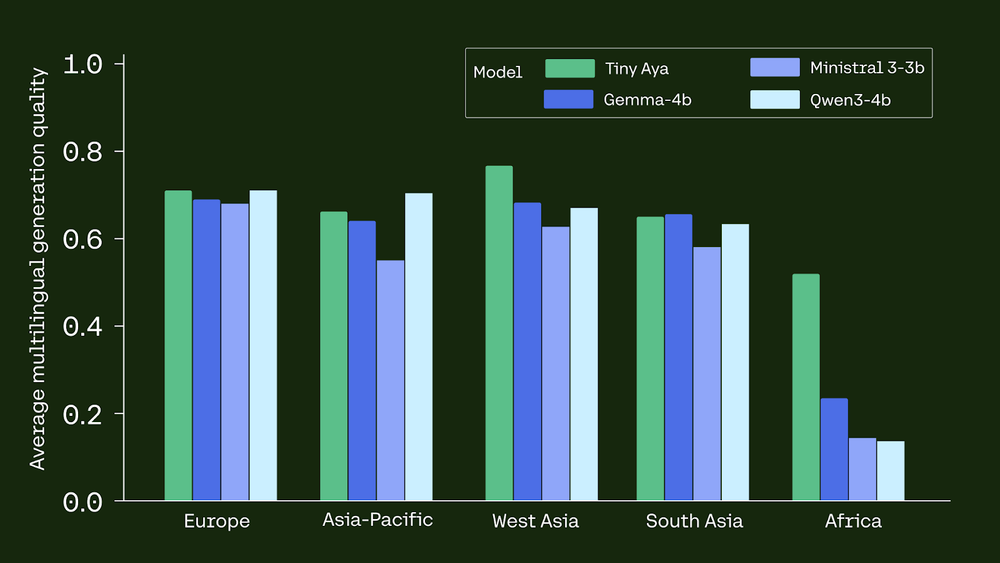
- translation: it exceeds Gemma 3-4B in 46 out of 61 languages above WMT24++.
- inference: in World MGSM African language (arithmetic) benchmark achieved by Tinyaya 39.2% accuracytrivialization Gemma 3-4B (17.6%) and Quen 3-4B (6.25%).
- security: Maintains the very best common protected response charge (91.1%) above multi jail.
- language integrity: the mannequin achieves 94% language accuracyThat’s, they not often change to English when requested to reply in one other language.
On-device deployment
Tiny Aya is optimized for edge computing. use 4-bit quantization (Q4_K_M)the mannequin is 2.14GB Reminiscence footprint.
- iPhone13: 10 tokens/sec.
- iPhone17 professional: 32 tokens/second.
This quantization scheme provides minimal outcomes. 1.4 factors The lowered era high quality makes it a viable resolution for offline, personal, and localized AI purposes.
Necessary factors
- Efficient multilingual expertise: Little Aya is 3.35B parameters A household of fashions that gives cutting-edge translation and high-quality manufacturing throughout your enterprise. 70 languages. This proves that huge scale just isn’t essential for sturdy multilingual efficiency when fashions are designed with intentional knowledge curation.
- Revolutionary coaching pipeline: The mannequin was developed utilizing a brand new technique as follows. Fusion of N (FUSION)a “group of academics” (reminiscent of Command A and DeepSeek-V3) generated artificial knowledge. The choose mannequin then aggregates probably the most highly effective parts to make sure a high-quality coaching sign even for low-resource languages.
- Regional specialization by way of merger: Cohere releases particular variant—Little Aya Earth, Fireplace and Water– Tailor-made for particular areas reminiscent of Africa, South Asia, and Asia Pacific. These have been created by combining regional fine-tuned fashions with world fashions. simmerge Enhance native language efficiency whereas staying protected.
- Glorious benchmark efficiency: Tinyaya World outperforms rivals reminiscent of: Gemma 3-4B By way of translation high quality 46 out of 61 languages With WMT24++. Disparities in mathematical reasoning amongst African languages have additionally been considerably lowered; 39.2% accuracy in comparison with 17.6% for Gemma3-4B.
- Optimized for on-device deployment: This mannequin is very moveable and runs effectively on edge gadgets. it accomplishes ~10 tokens/second For iPhone 13 and 32 tokens/second Use with iPhone 17 Professional Q4_K_M Quantization. This 4-bit quantized format maintains top quality with minimal quantization. 1.4 factors deterioration.
Please test technical details, paper, model weights and playground. Please be happy to comply with us too Twitter Remember to hitch us 100,000+ ML subreddits and subscribe our newsletter. grasp on! Are you on telegram? You can now also participate by telegram.


{kind=link}