


Robbyant, the embodied AI division inside Ant Group, has open sourced LingBot-World, a large-scale world mannequin that turns video technology into an interactive simulator for embodied brokers, self-driving automobiles, and video games. The system is designed to render controllable environments with excessive visible constancy, sturdy dynamics, and lengthy temporal horizons whereas remaining responsive sufficient for real-time management.
From textual content to video and from textual content to the world
Most text-to-video fashions produce quick clips that look practical however behave like passive films. These don’t mannequin how conduct modifications the setting over time. LingBot-World is as a substitute constructed as an action-conditional world mannequin. To be taught the transition dynamics of the digital world, keyboard and mouse inputs together with digicam actions drive the evolution of future frames.
Formally, the mannequin learns a conditional distribution of future video tokens by contemplating previous frames, language prompts, and discrete actions. Throughout coaching, it predicts sequences as much as roughly 60 seconds. Throughout inference, we will autoregressively roll out roughly 10 minutes of coherent video streams whereas maintaining the scene construction steady.
Knowledge engine from net video to interactive trails
The core design of LingBot-World is an built-in information engine. It gives wealthy, tailor-made oversight of how actions change the world, masking a wide range of real-world scenes.
The info acquisition pipeline combines three sources:
- Giant-scale net movies of people, animals, and automobiles in each first and third particular person views.
- Sport information. RGB frames are strictly paired with consumer controls reminiscent of W, A, S, D and digicam parameters.
- Artificial trajectory rendered in Unreal Engine. A clear body, inner and exterior options of the digicam, and object structure are all recognized.
After assortment, this heterogeneous corpus is standardized throughout the profiling stage. Filter decision and size, break up the video into clips, and use geometry and pose fashions to estimate lacking digicam parameters. A imaginative and prescient language mannequin scores clips for high quality, movement magnitude, and examine kind and selects a rigorously chosen subset.
Along with this, a hierarchical captioning module builds three ranges of textual content monitoring.
- Descriptive caption for your complete trajectory together with digicam movement
- Static captions for scenes that describe static setting layouts
- Dense temporal captioning for brief time home windows, specializing in native dynamics
This separation permits the mannequin to disentangle static construction from motion patterns, which is vital for long-term consistency.
Structure, MoE video spine, motion conditioning
LingBot-World begins with Wan2.2, a 14B parameter image-to-video diffusion transformer. This spine already captures highly effective open area video a priori info. The Lobbyant group extends it to a mixture of DiT specialists, together with two specialists. Every skilled has roughly 14B parameters, so the full variety of parameters is 28B, however just one skilled is lively at every denoising step. This scales capability whereas sustaining inference prices much like the dense 14B mannequin.
The curriculum extends the coaching sequence from 5 seconds to 60 seconds. This schedule will increase the proportion of high-noise timesteps, stabilizes the worldwide structure over lengthy contexts, and reduces mode collapse on lengthy rollouts.
To make your mannequin interactive, inject actions immediately into Transformer blocks. Digicam rotation is encoded within the Plücker embedding. Keyboard actions are represented as multi-hot vectors on keys reminiscent of W, A, S, and D. These encodings are fused and handed by way of an adaptive layer normalization module that adjusts the hidden states of DiT. Solely the motion adapter layer is fine-tuned and the principle video spine stays frozen, so the mannequin maintains the visible high quality of its pre-training whereas studying motion responsiveness from a smaller interactive dataset.
The coaching makes use of each an image-to-video continuation process and a video-to-video continuation process. Given a single picture, the mannequin can synthesize future frames. You possibly can lengthen your sequence by specifying partial clips. This generates an inner transition operate that may begin from any level.
LingBot World Quick, distilled for real-time use
The intermediate educated mannequin, LingBot-World Base, nonetheless depends on multi-level diffusion and full temporal consideration, making real-time interactions expensive. Robbyant group introduces LingBot-World-Quick as an accelerated variant.
A quick mannequin is initialized from a high-noise skilled and replaces full temporal consideration with blocking causal consideration. Inside every time block, consideration is bidirectional. When you cross the block, it turns into a cause-and-effect relationship. This design helps key-value caching, permitting the mannequin to autoregressively stream frames at low value.
Distillation makes use of a compelled diffusion technique. Pupil is educated on a small set of goal timesteps, together with timestep 0, so it acknowledges each noisy and clear latent parts. Distribution Matching Distillation is mixed with an adversarial discriminator head. Adversarial loss solely updates the identifier. The scholar community is up to date by distillation loss to stabilize coaching whereas sustaining motion followability and temporal consistency.
In experiments, LingBot World Quick reached 16 frames per second when processing 480p video on a system with 1 GPU node and maintained end-to-end interplay latency of lower than 1 second in real-time management.
Emergent reminiscence and long-term conduct
One of the crucial fascinating properties of LingBot-World is its emergent reminiscence. The mannequin maintains international consistency with out express 3D illustration reminiscent of Gaussian splatting. When the digicam strikes away from a landmark reminiscent of Stonehenge and returns after about 60 seconds, the construction reappears with a constant form. When a automobile exits the body and reenters it later, it doesn’t freeze or reset, and seems in a bodily cheap place.
This mannequin can even preserve very lengthy sequences. The analysis group demonstrates constant video technology for as much as 10 minutes with a steady structure and narrative construction. ]
Comparability of VBench outcomes with different world fashions
For quantitative analysis, the analysis group used VBench on a particular set of 100 generated movies, every longer than 30 seconds. LingBot-World is in comparison with two current world fashions, Yume-1.5 and HY-World-1.5.
Relating to VBench, LingBot World reviews:
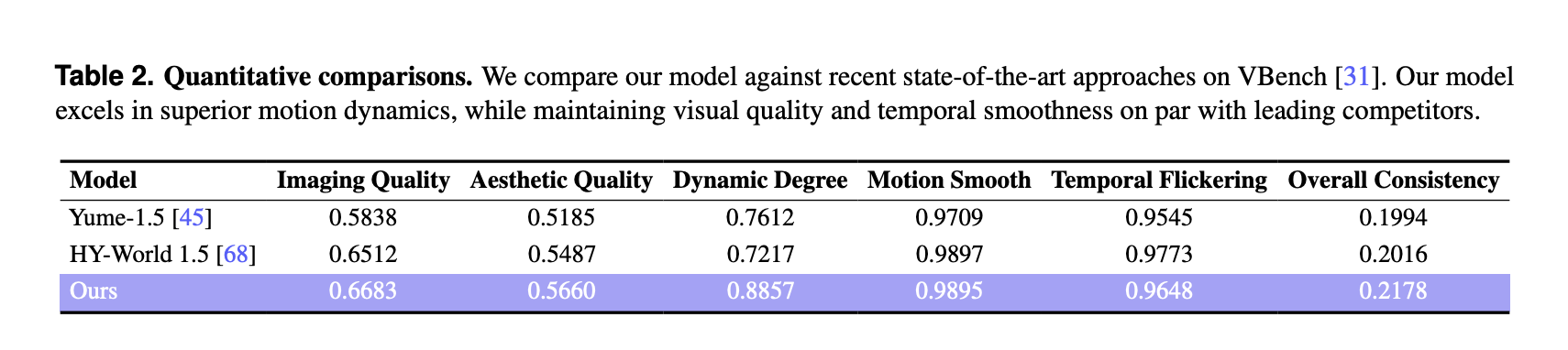
These scores are larger than the baseline for each picture high quality, aesthetic high quality, and dynamics. The dynamicity margin is bigger at 0.8857 in comparison with 0.7612 and 0.7217, indicating richer scene transitions and extra advanced movement in response to consumer enter. The movement smoothness and temporal flicker are akin to the perfect baseline, and our technique achieves the very best total consistency index among the many three fashions.
Separate comparisons with different interactive techniques reminiscent of Matrix-Sport-2.0, Mirage-2, and Genie-3 present that LingBot-World is likely one of the few totally open-source world fashions that mixes widespread area protection, lengthy technology intervals, excessive dynamics, 720p decision, and real-time capabilities.

Purposes, promptable worlds, brokers, and 3D reconstruction
Past video synthesis, LingBot-World is positioned as a testbed for embodied AI. The mannequin helps prompt-enabled world occasions that permit textual content directions to vary climate, lighting, and elegance, and to insert native occasions reminiscent of fireworks or shifting animals over time whereas preserving spatial construction.
You can even practice downstream motion brokers utilizing small imaginative and prescient language motion fashions like Qwen3-VL-2B that predict management insurance policies from photographs. The generated video streams are geometrically constant and can be utilized as enter to 3D reconstruction pipelines, producing steady level clouds for indoor, outside, and artificial scenes.
Essential factors
- LingBot-World is an action-conditional world mannequin that extends text-to-video to text-to-world simulations, with keyboard actions and digicam actions immediately controlling long-form video rollouts of as much as roughly 10 minutes.
- The system is educated on a unified information engine that mixes net movies, action-labeled recreation logs, and Unreal Engine trajectories, in addition to hierarchical narratives, static scenes, and dense temporal captions to separate structure and motion.
- The core spine is constructed from Wan2.2 and is a mix of two specialists of 14B every and 28B parameters of an skilled diffusion transformer with motion adapters which might be fine-tuned whereas the visible spine stays frozen.
- LingBot-World-Quick is a distilled variant that makes use of block causal consideration, diffuse forcing, and distributional matching distillation to attain roughly 16 frames per second at 480p on 1 GPU node, with sub-second end-to-end latencies reported for interactive use.
- On VBench with 100 generated movies over 30 seconds, LingBot-World reviews the very best picture high quality, aesthetic high quality, and diploma of dynamics amongst Yume-1.5 and HY-World-1.5, and the mannequin reveals an emergent reminiscence and steady long-range construction appropriate for embodied brokers and 3D reconstruction.
Please test paper, lipo, Project page and model weights. Please be happy to observe us too Twitter Remember to affix us 100,000+ ML subreddits and subscribe our newsletter. cling on! Are you on telegram? You can now also participate by telegram.

{kind=link}