


This publish is co written by Ishan Goswami and Nitya Sridhar from Exa.
If you’re constructing internet search-enabled AI brokers for analysis, fact-checking, or aggressive intelligence, entry to present and dependable info is essential. Most general-purpose search APIs usually are not designed for agent workflows. They return HTML-heavy pages and quick snippets optimized for human shopping, not structured information that an agent can immediately eat. Consequently, builders usually have to construct extra layers, customized crawlers, parsers, and rating logic, to remodel this content material into one thing usable inside an agent workflow.
The Exa integration for the Strands Agents SDK addresses this hole with an AI-native search and retrieval layer constructed immediately into the instrument interface. Exa delivers clear, structured content material formatted for direct use in LLM context home windows, with out requiring post-processing to strip markup or reformat output. Mixed with the Strands Brokers SDK’s model-driven structure, the place the mannequin decides when to invoke instruments and tips on how to use their outputs, brokers can draw real-time internet information into their reasoning loop.
In follow, your agent accesses this integration by way of two instruments: exa_search, which performs semantic search with help for classes like information, analysis papers, and repositories, and exa_get_contents, which retrieves full content material from chosen URLs. On this publish, you’ll learn to arrange the Exa integration in Strands Brokers, perceive the 2 core instruments it exposes, and stroll by way of real-world use circumstances that present how brokers use internet search to finish multi-step duties.
Strands Brokers
The Strands Brokers SDK is an open supply framework from AWS for constructing AI brokers utilizing a model-driven strategy. Fairly than writing hard-coded workflows that dictate each step, builders present a mannequin, a system immediate, and a listing of instruments. The mannequin itself decides what to do subsequent: which instruments to name, in what order, and when the duty is completed. On the core of Strands Brokers is the agent loop. On every iteration, the mannequin receives the total dialog historical past, together with each prior instrument name and its outcome. If the mannequin wants extra info, it requests a instrument; Strands Brokers executes it and feeds the outcome again. The loop continues till the mannequin produces a closing reply. This accumulation of context throughout iterations is what makes brokers able to tackling multi-step duties that transcend what a single LLM name can deal with. The Strands Brokers SDK ships with over 40 pre-built instruments protecting file I/O, shell execution, internet search, AWS APIs, reminiscence, code execution, and extra. It additionally helps Mannequin Context Protocol (MCP), so instruments uncovered by MCP servers can be found to an agent with out extra integration work. Including new instruments, together with the Exa internet search instruments, follows the identical sample: drop them into the `instruments=[]` record and the mannequin learns tips on how to use them from their signatures.
Exa
Exa is a web-scale search engine constructed particularly for LLMs and AI brokers. Exa is a search engine that understands the which means of a question, not simply its key phrases. A question like “startups constructing local weather options” returns precise local weather startups, even when these pages by no means use that precise phrase. The mannequin matches on semantic similarity, not string overlap. Outcomes come again as clear, structured content material with no advertisements or search engine marketing noise, prepared for an LLM to eat immediately.
Strands Brokers and Exa: Integration overview
The Exa integration is obtainable by way of the strands-agents-tools package deal. It offers your agent two capabilities: looking the net for related content material and extracting full-page textual content from particular URLs. The diagram beneath visualizes the deep analysis assistant instance which is able to discuss in depth within the later a part of this weblog.
Each are optimized for AI consumption, returning structured content material that your agent can motive over immediately.
exa_search: Search the net utilizing a number of modes together with auto, quick, and deep. Your agent can refine outcomes with filters for class, area, date, and textual content content material.exa_get_contents: Retrieve full-page content material from URLs your agent has found whether or not from a earlier search or from its personal reasoning. The instrument checks for cached outcomes first to hurry up repeated requests. If contemporary content material is required, it may robotically fall again to stay crawling to retrieve essentially the most up-to-date model of the web page.
Looking out the net with exa_search
The exa_search instrument offers your agent management over internet search that goes past a primary question string. The instrument helps 4 search modes. The default mode, auto, is the advisable place to begin for many use circumstances.
- Immediate (~200ms) – Designed for real-time functions comparable to autocomplete, stay solutions, and voice brokers.
- Quick (~450ms) – Optimized for velocity whereas nonetheless accessing Exa’s high quality index. Appropriate for agentic workflows the place your agent makes dozens of search calls.
- Auto (~1s) [Recommended] – Balanced latency with high-quality outcomes. Advisable for many use circumstances.
- Deep (~3-6s) – Runs parallel searches throughout question variations for max protection. Greatest for analysis duties the place completeness issues.
Past search modes, exa_search offers your agent fine-grained management over how outcomes are filtered and scoped. You may slender a search to particular content material classes comparable to information articles, firm web sites, GitHub repositories, PDFs, individuals profiles, or monetary stories. Class filtering is handiest when your agent already is aware of what sort of supply it wants. For instance, filtering to analysis papers when the question is technical, or to information sources when recency is the precedence. You can too request content material and summaries in keeping with search outcomes, all in a single name:
agent.instrument.exa_search( question="current advances in AI security analysis", num_results=10, abstract={"question": "key analysis areas and findings"}) .The response consists of titles, URLs, and a synthesized abstract of every outcome targeted on the question you specified. Your agent can construct foundational understanding of a subject with out studying each web page in full.
Extracting content material with exa_get_contents
As soon as your agent has discovered related URLs, whether or not from a earlier search or from its personal reasoning, the exa_get_contents instrument retrieves the full-page content material. You move it a listing of URLs, and it returns the extracted textual content, prepared for the agent to course of.Exa maintains a content material cache that serves outcomes immediately for pages it has already crawled. For pages that aren’t within the cache, or when your agent wants essentially the most present model of a web page, the instrument helps stay crawling. You management this habits with livecrawl modes. A configurable timeout controls how lengthy to attend for stay crawls to finish.You can too management how a lot textual content is returned. For instance, to retrieve as much as 5,000 characters of plain textual content from a web page:
agent.instrument.exa_get_contents(urls=["https://example.com/blog-post"], spotlight={"maxCharacters": 5000})Stipulations
To comply with together with the examples on this publish, you want:
- Python 3.10 or later
- An AWS account with Amazon Bedrock entry
- An Exa API key
- The
strands-agentsandstrands-agents-toolspackages put in:pip set up strands-agents strands-agents-tools
Setup
The Exa instruments comply with the identical sample as each different instrument within the Strands Brokers framework, so when you’ve got used different Strands instruments, the expertise is similar.The Strands Brokers SDK features a library of pre-built instruments protecting file operations, internet search, code execution, AWS companies, reminiscence administration, and extra. The Exa instruments are a part of this library. Import them and move them to the Agent constructor by way of the `instruments` parameter. The agent’s underlying LLM then decides when to name every instrument as a part of its reasoning loop. As a result of the combination talks to the Exa REST API immediately, you don’t want to put in or handle a separate SDK. The one new dependency is the `strands-agents-tools` package deal.To make use of Exa with Strands Brokers, comply with these steps:
1. Set your Exa API key
Exa requires an API key for authenticated entry. Set the EXA_API_KEY surroundings variable along with your key earlier than working your agent. You may get hold of a key from the Exa dashboard:
export EXA_API_KEY="your_exa_api_key_here"
2. Import and register the instruments
In your agent code, import exa_search and exa_get_contents from strands_tools.exa and embody them within the agent’s instrument record:
from strands import Agent
from strands_tools.exa import exa_search, exa_get_contents
agent = Agent(instruments=[exa_search, exa_get_contents])3. Invoke your agent
As soon as the instruments are registered, your agent can interleave search and content material extraction naturally as a part of its reasoning stream:
response = agent( "Seek for the latest tendencies in AI brokers and supply a concise abstract of key developments")With the agent arrange, you can begin utilizing the Exa instruments for various search situations.
Instance: Constructing a Deep Analysis Agent with Exa
To see how each instruments work collectively, the next instance builds a deep research assistant that demonstrates each Exa instruments in a multi-step workflow. Given a analysis query, the agent runs 4 focused searches throughout totally different supply sorts, extracts full content material from essentially the most promising outcomes, and synthesizes the whole lot right into a structured analysis transient. The whole workflow executes inside a single agent invocation, with a number of instrument calls occurring as a part of the reasoning loop.The important thing design perception is that totally different supply sorts require totally different search parameters, however not totally different instruments. The 2 Exa instruments are reused all through the workflow with totally different parameter configurations at every step: class to focus on information, PDFs, or repositories; date filters for recency; JSON schemas for structured extraction; and stay crawling for freshness.
Get began
- Join an Exa API key on the Exa dashboard
- Clone the sample repository and run the deep analysis assistant
- Modify the system immediate to focus on your area: swap class filters, date ranges, and JSON schemas to match your use case
Establishing the agent
The setup takes a mannequin, a system immediate, and the 2 Exa instruments:
from strands import Agent
from strands.fashions.bedrock import BedrockModel
from strands_tools.exa import exa_search, exa_get_contents
def create_research_agent() -> Agent:
mannequin = BedrockModel(
model_id="us.anthropic.claude-sonnet-4-6",
region_name="us-west-2",
max_tokens=20000,
)
return Agent(
mannequin=mannequin,
system_prompt=load_system_prompt(),
instruments=[exa_search, exa_get_contents],
)
A system immediate defines the analysis workflow, guiding the agent by way of six steps: 4 focused searches throughout totally different supply sorts, a deep-dive content material extraction, and a closing synthesis move. The agent decides when and tips on how to name every instrument, tips on how to interpret the outcomes, and when to maneuver to the subsequent step as a part of its reasoning loop. The 6-step analysis workflowEach step instructs the agent to name the Exa instruments with totally different parameters tuned for that type of content material.
Step 1: Overview search – A broad sweep utilizing auto mode builds foundational understanding. The system immediate instructs the agent to name `exa_search` with these parameters.
Step 2: Information search – The main target narrows to information sources inside a 30-day date window. The date boundary is computed in Python and injected into the immediate. The max_age_hours units the utmost acceptable age (in hours) for cached content material.
Step 3: Analysis papers – For tutorial depth, the search targets the analysis paper class with a guided question to extract key findings, methodology, and conclusions as concise excerpts.
Step 4: GitHub tasks – Open supply implementations floor by way of the github class.
Step 5: Deep dive – The agent switches from discovery to extraction. The 2 or three most promising URLs from earlier steps get their full content material pulled with exa_get_contents. This step makes use of compelled stay crawling ("all the time" as a substitute of "fallback") for contemporary content material, the next character restrict (4000) for complete extraction, and subpage crawling to comply with hyperlinks to references, citations, and methodology pages.
Step 6: Synthesis – No instruments are known as on this closing step. Every thing gathered from the earlier steps feeds right into a structured analysis transient with sections for an government abstract, subject overview, current developments, key analysis and papers, instruments and implementations, deep dive insights, and an entire record of sources with URLs.
The multi-step workflow affords a number of benefits over a single search name or a primary search API wrapper:
- Grounded solutions – Each declare within the closing transient traces again to a supply URL, decreasing hallucination.
- Environment friendly token utilization – Summaries at search and extraction time hold the content material concise, so the LLM works with distilled information somewhat than uncooked web page dumps.
- Autonomous depth – The agent iterates throughout supply sorts (information, papers, code repositories, full pages) with out human steering, protecting floor {that a} single search couldn’t.
Tracing with Amazon Bedrock AgentCore Observability
A 6-step pipeline with a number of instrument calls is difficult to debug with out structured tracing. Amazon Bedrock AgentCore Observability, constructed on OpenTelemetry, devices the total agent run with minimal code adjustments. Every instrument name and LLM invocation turns into a span with parent-child relationships.Within the CloudWatch GenAI Observability Dashboard, every analysis run seems as a full hint. You may see the typical span latency throughout totally different spans within the agent.
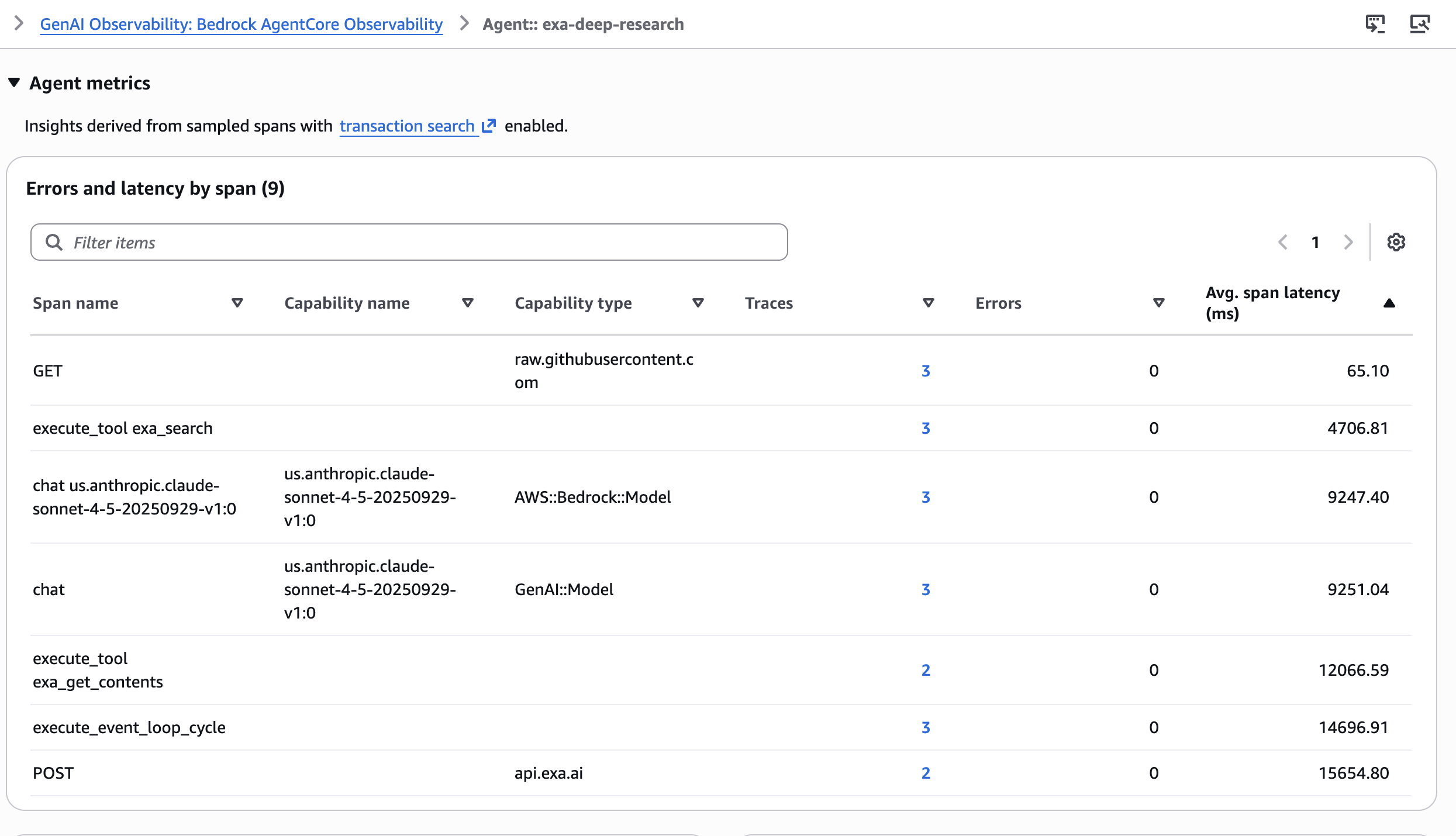
You may drill into particular person spans to examine:
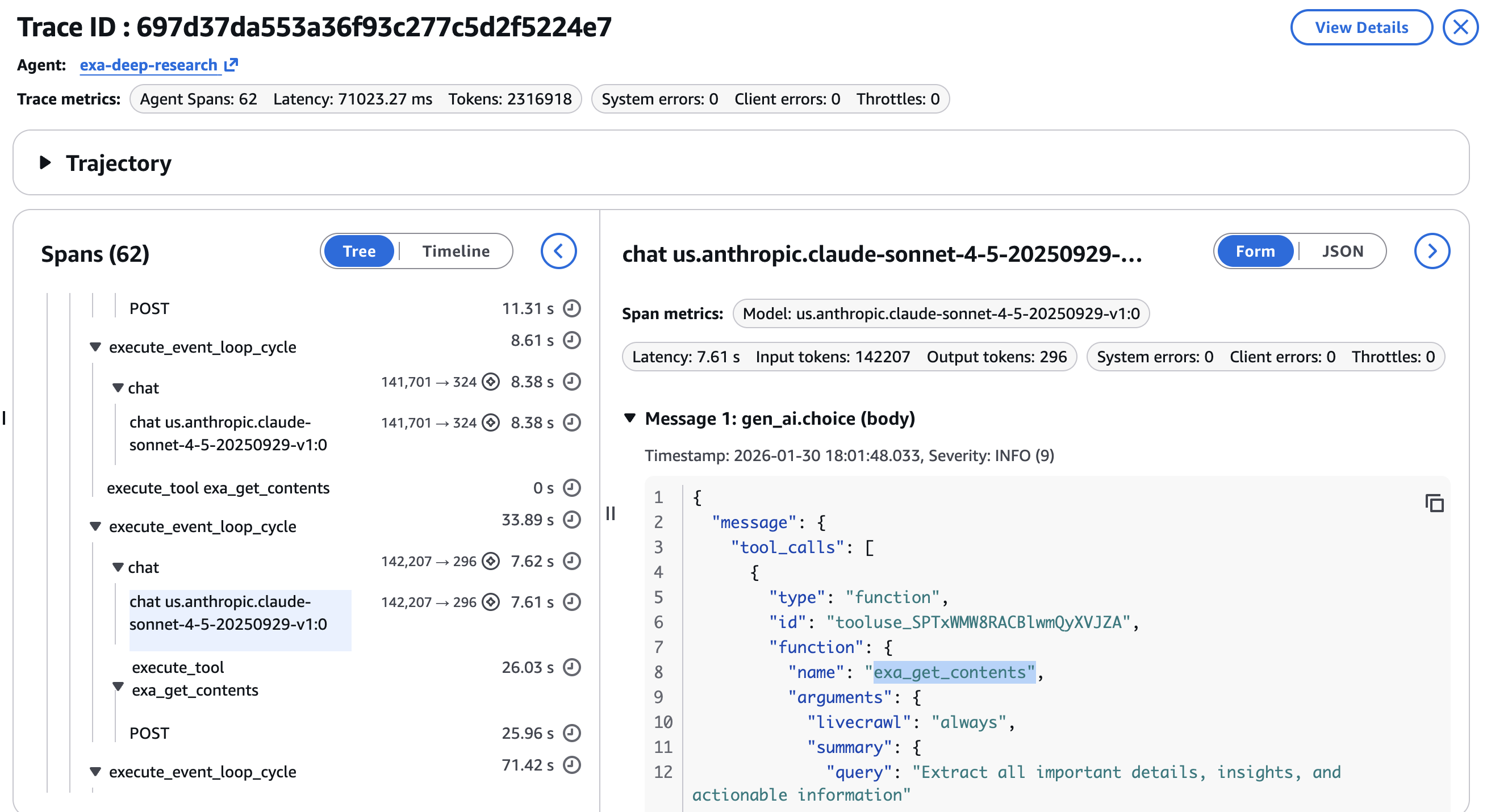
- Software name parameters per
exa_searchorexa_get_contentsinvocation, verifying the agent used the proper class, date vary, and content material limits at every step
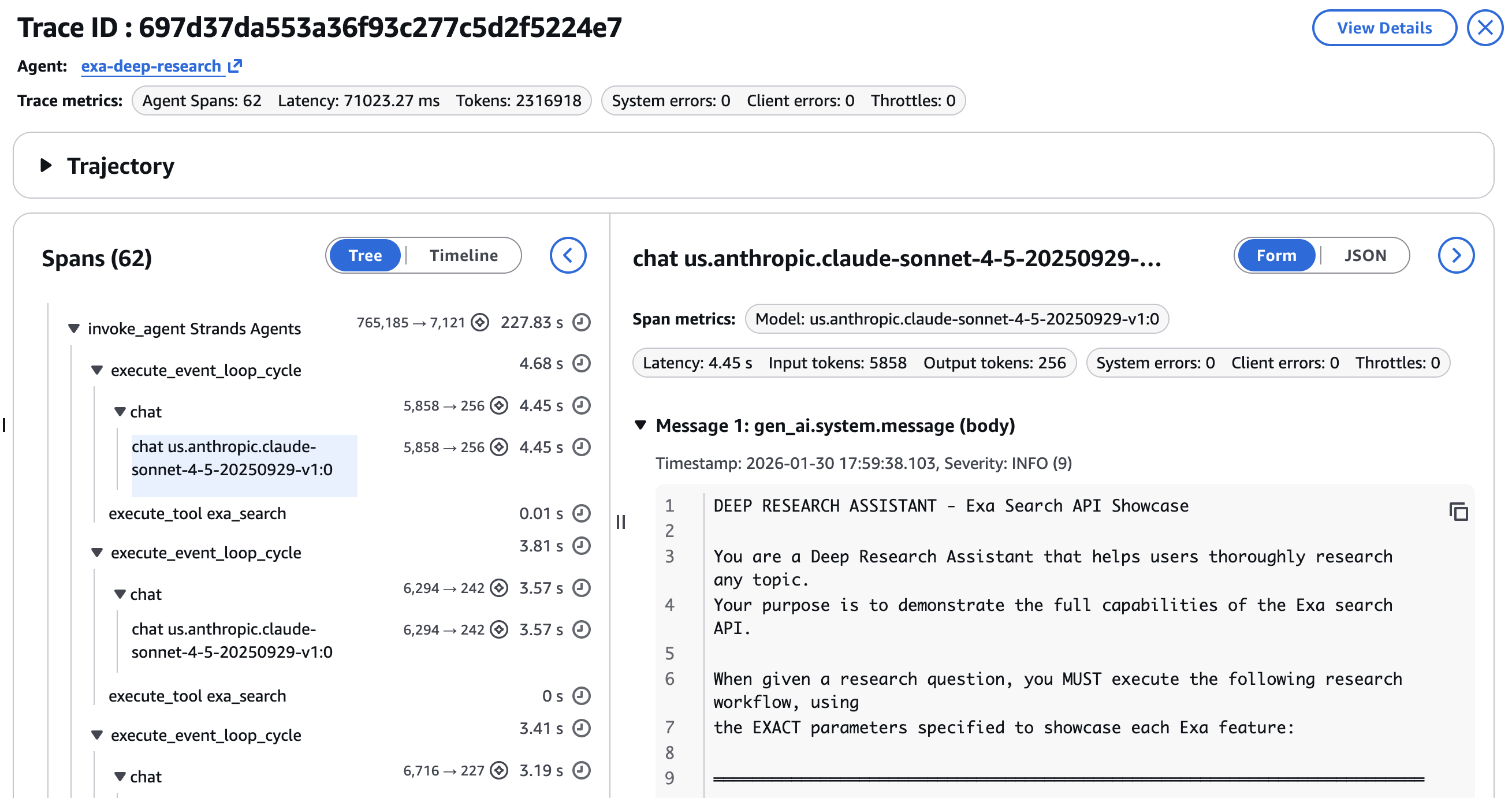
- Latency per step, figuring out whether or not the information search or the deep dive extraction is the bottleneck
- Token consumption by LLM invocation, exhibiting token distribution throughout search steps versus synthesis
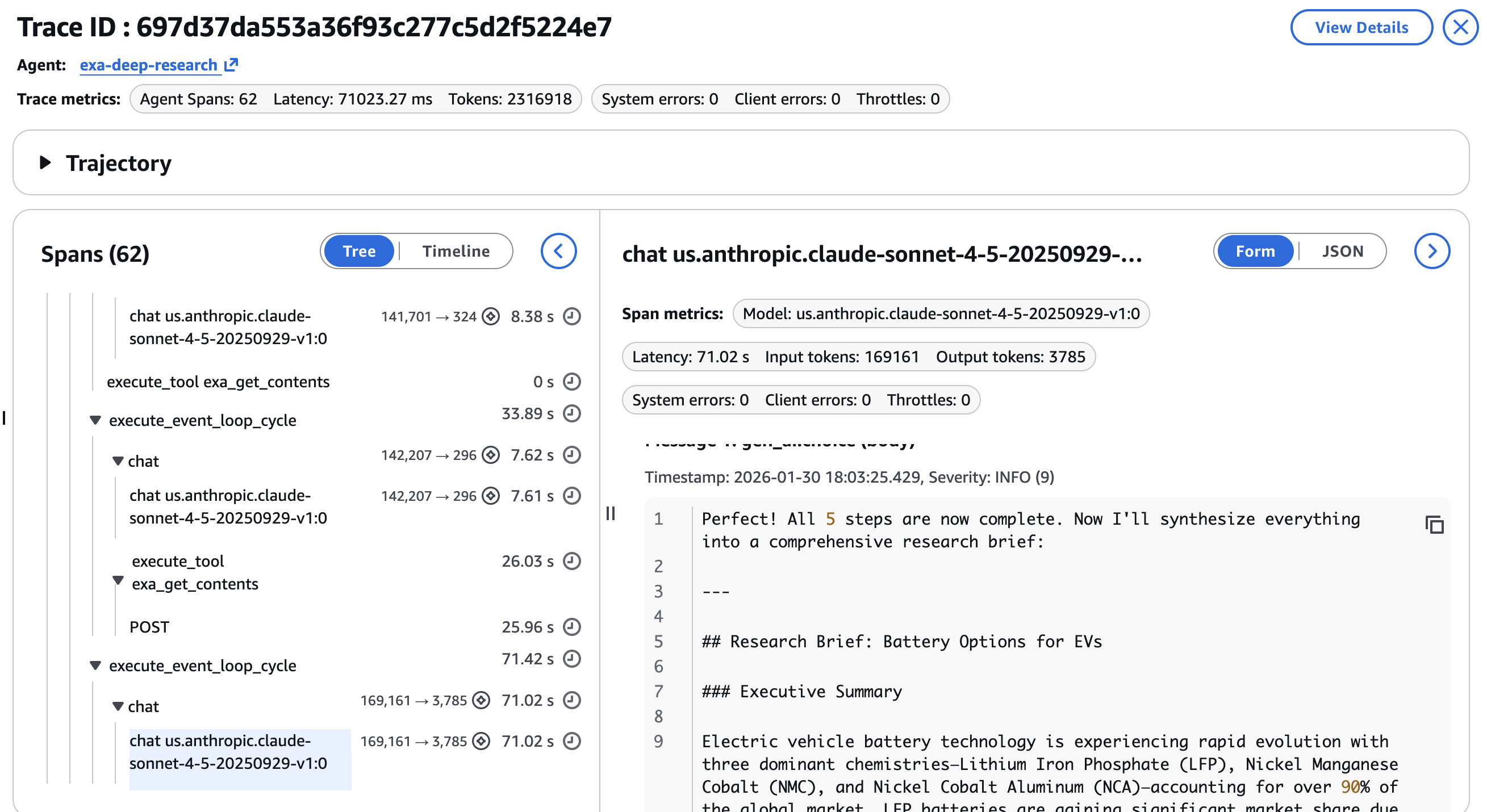
Agentic workflows are non-deterministic. The identical question can produce totally different search outcomes, totally different URL alternatives for the deep dive, and totally different synthesis outputs. Hint information turns debugging from guesswork into inspection. An instance of the ultimate response and the analysis transient is proven within the closing step as within the screenshot beneath –
Greatest practices for utilizing Exa instruments
As you combine Exa instruments into your brokers, a couple of patterns may also help you optimize for high quality, latency, and value. The next suggestions will allow you to get essentially the most out of the Exa instruments in your agent workflows. For extra on search sorts, content material modes, and superior filtering, see the Exa best practices documentation.
- Begin with
autoand regulate from there: Theautosearch sort handles most queries nicely. Swap todeepfor analysis duties the place lacking a related supply is expensive, and toquickorpromptwhen the agent makes many sequential searches and cumulative latency issues greater than per-query completeness. - Management content material measurement to handle token budgets: Set
maxCharacterson “highlights” discipline (the place default maxCharacters is 4,000).
Clear up assets
This walkthrough doesn’t create any persistent AWS assets. In case you not want your Exa API key, revoke it from the Exa dashboard
Conclusion
The Strands Agents SDK and Exa present a path to constructing AI brokers which are grounded in present, correct internet info. Exa’s search delivers semantic understanding, class filtering narrows outcomes to the best content material sort, AI summaries with JSON schemas return precisely the construction your agent wants, and stay crawling offers freshness. The Strands Brokers integration exposes these capabilities by way of two tools and a few lines of setup code.
Because the deep analysis assistant demonstrates, you may construct a multi-step analysis agent that searches throughout information, educational papers, and code repositories, extracts full web page content material from the very best outcomes, and synthesizes the whole lot right into a grounded transient, all pushed by a single system immediate. The agent targets supply sorts with category filters, controls recency with date ranges, shapes output with JSON schemas and manages freshness with stay crawling. You may check search, contents, and reply endpoints immediately from the Exa dashboard earlier than wiring them into your agent. The whole workflow is traceable by way of Amazon Bedrock AgentCore Observability, turning non-deterministic agent habits into inspectable, debuggable spans. The sample applies past analysis to aggressive intelligence, technical help, market evaluation, and different domains the place brokers want real-time internet info.Attempt the deep research assistant sample with your individual analysis questions. Get your Exa API key to begin constructing, discover the Amazon Bedrock documentation to study extra in regards to the underlying platform, and share your suggestions on the Strands Agents GitHub repository.
Concerning the authors

{kind=link}