


PDI Technologies is a worldwide chief within the comfort retail and petroleum wholesale industries. They assist companies across the globe enhance effectivity and profitability by securely connecting their knowledge and operations. With 40 years of expertise, PDI Applied sciences assists clients in all points of their enterprise, from understanding client conduct to simplifying expertise ecosystems throughout the availability chain.
Enterprises face a big problem of creating their information bases accessible, searchable, and usable by AI techniques. Inner groups at PDI Applied sciences had been fighting info scattered throughout disparate techniques together with web sites, Confluence pages, SharePoint websites, and numerous different knowledge sources. To deal with this, PDI Applied sciences constructed PDI Intelligence Question (PDIQ), an AI assistant that provides staff entry to firm information via an easy-to-use chat interface. This answer is powered by a customized Retrieval Augmented Era (RAG) system, constructed on Amazon Net Companies (AWS) utilizing serverless applied sciences. Constructing PDIQ required addressing the next key challenges:
- Mechanically extracting content material from numerous sources with totally different authentication necessities
- Needing the flexibleness to pick, apply, and interchange probably the most appropriate giant language mannequin (LLM) for numerous processing necessities
- Processing and indexing content material for semantic search and contextual retrieval
- Making a information basis that permits correct, related AI responses
- Constantly refreshing info via scheduled crawling
- Supporting enterprise-specific context in AI interactions
On this publish, we stroll via the PDIQ course of circulate and structure, specializing in the implementation particulars and the enterprise outcomes it has helped PDI obtain.
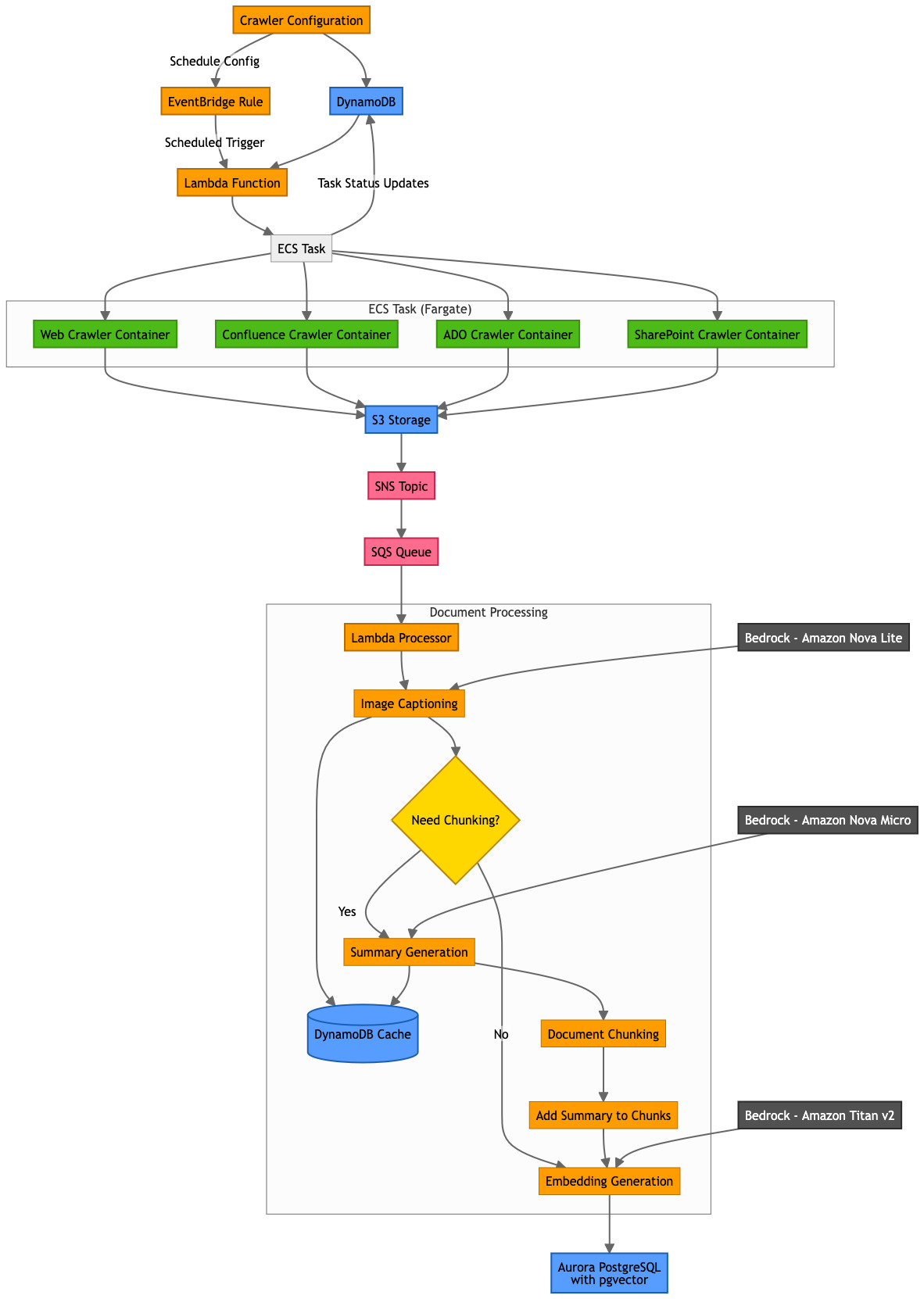
Resolution structure
On this part, we discover PDIQ’s complete end-to-end design. We look at the information ingestion pipeline from preliminary processing via storage to consumer search capabilities, in addition to the zero-trust safety framework that protects key consumer personas all through their platform interactions. The structure consists of those components:
- Scheduler – Amazon EventBridge maintains and executes the crawler scheduler.
- Crawlers – AWS Lambda invokes crawlers which are executed as duties by Amazon Elastic Container Service (Amazon ECS).
- Amazon DynamoDB – Persists crawler configurations and different metadata akin to Amazon Easy Storage Service (Amazon S3) picture location and captions.
- Amazon S3 – All supply paperwork are saved in Amazon S3. Amazon S3 occasions set off the downstream circulate for each object that’s created or deleted.
- Amazon Easy Notification Service (Amazon SNS) – Receives notification from Amazon S3 occasions.
- Amazon Easy Queue Service (Amazon SQS) – Subscribed to Amazon SNS to carry the incoming requests in a queue.
- AWS Lambda – Handles the enterprise logic for chunking, summarizing, and producing vector embeddings.
- Amazon Bedrock – Offers API entry to basis fashions (FMs) utilized by PDIQ:
- Amazon Aurora PostgreSQL-Appropriate Version – Shops vector embeddings.
The next diagram is the answer structure.
Subsequent, we assessment how PDIQ implements a zero-trust safety mannequin with role-based entry management for 2 key personas:
- Directors configure information bases and crawlers via Amazon Cognito consumer teams built-in with enterprise single sign-on. Crawler credentials are encrypted at relaxation utilizing AWS Key Administration Service (AWS KMS) and solely accessible inside remoted execution environments.
- Finish customers entry information bases primarily based on group permissions validated on the software layer. Customers can belong to a number of teams (akin to human sources or compliance) and swap contexts to question role-appropriate datasets.
Course of circulate
On this part, we assessment the end-to-end course of circulate. We break it down by sections to dive deeper into every step and clarify the performance.
Crawlers
Crawlers are configured by Administrator to gather knowledge from a wide range of sources that PDI depends on. Crawlers hydrate the information into the information base in order that this info might be retrieved by finish customers. PDIQ at present helps the next crawler configurations:
- Net crawler – By utilizing Puppeteer for headless browser automation, the crawler converts HTML net pages to markdown format utilizing turndown. By following the embedded hyperlinks on the web site, the crawler can seize full context and relationships between pages. Moreover, the crawler downloads belongings akin to PDFs and pictures whereas preserving the unique reference and presents customers configuration choices akin to charge limiting.
- Confluence crawler – This crawler makes use of Confluence REST API with authenticated entry to extract web page content material, attachments, and embedded pictures. It preserves web page hierarchy and relationships, handles particular Confluence components akin to data bins, notes, and plenty of extra.
- Azure DevOps crawler – PDI makes use of Azure DevOps to handle its code base, monitor commits, and preserve undertaking documentation in a centralized repository. PDIQ makes use of Azure DevOps REST API with OAuth or private entry token (PAT) authentication to extract this info. Azure DevOps crawler preserves undertaking hierarchy, dash relationships, and backlog construction additionally maps work merchandise relationships (akin to mother or father/baby or linked objects), thereby offering an entire view of the dataset.
- SharePoint crawler – It makes use of Microsoft Graph API with OAuth authentication to extract doc libraries, lists, pages, and file content material. The crawler processes MS Workplace paperwork (Phrase, Excel, PowerPoint) into searchable textual content and maintains doc model historical past and permission metadata.
By constructing separate crawler configurations, PDIQ presents simple extensibility into the platform to configure further crawlers on demand. It additionally presents the flexibleness to administrator customers to configure the settings for his or her respective crawlers (akin to frequency, depth, or charge limits).
The next determine exhibits the PDIQ UI to configure the information base.
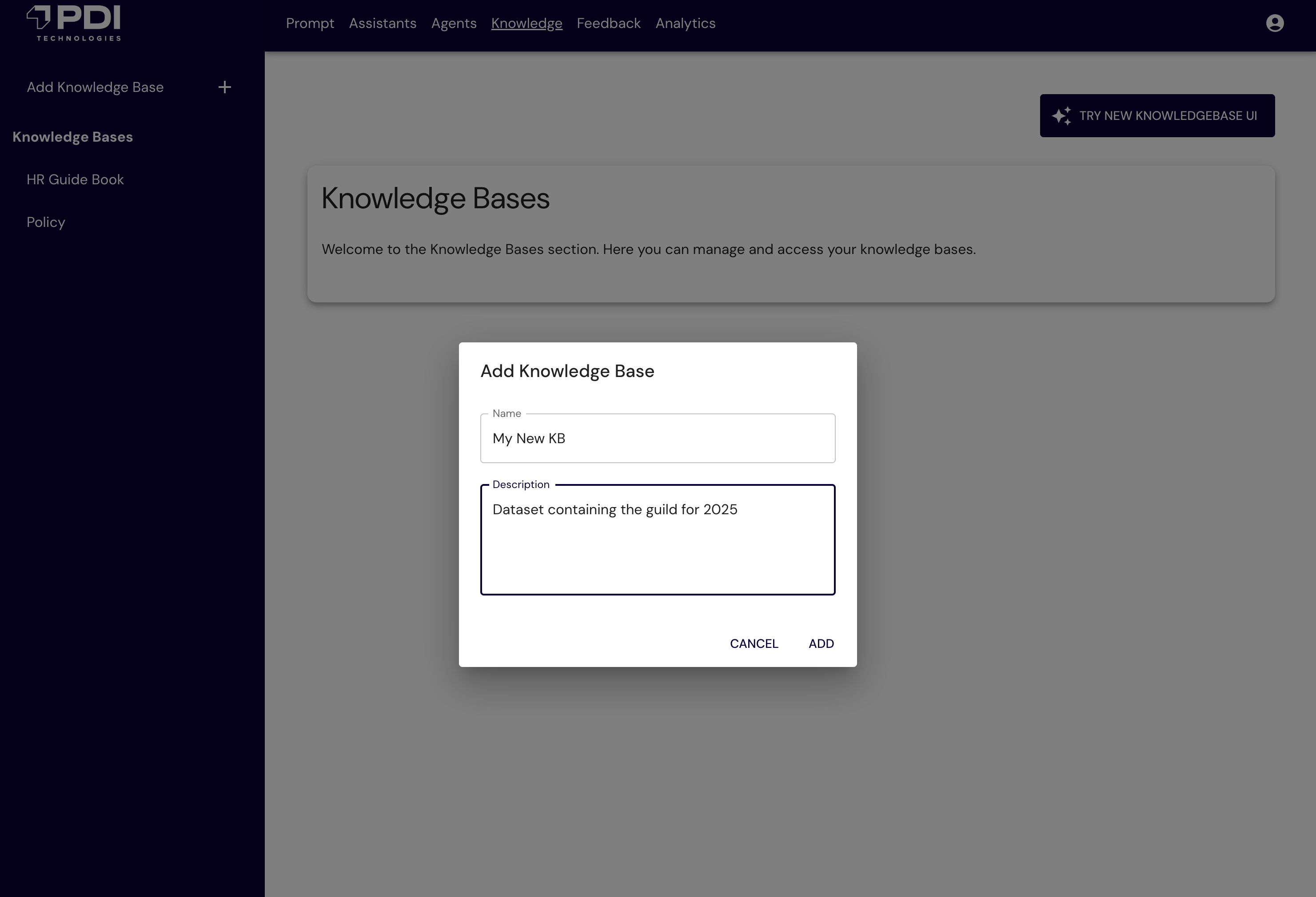
The next determine exhibits the PDI UI to configure your crawler (akin to Confluence).

The next determine exhibits the PDIQ UI to schedule crawlers.

Dealing with pictures
Information crawled is saved in Amazon S3 with correct metadata tags. If the supply is in HTML format, the duty converts the content material into markdown (.md) recordsdata. For these markdown recordsdata, there’s a further optimization step carried out to exchange the pictures within the doc with the Amazon S3 reference location. Key advantages of this method embody:
- PDI can use S3 object keys to uniquely reference every picture, thereby optimizing the synchronization course of to detect modifications in supply knowledge
- You possibly can optimize storage by changing pictures with captions and avoiding the necessity to retailer duplicate pictures
- It gives the flexibility to make the content material of the pictures searchable and relatable to the textual content content material within the doc
- Seamlessly inject unique pictures when rendering a response to consumer inquiry
The next is a pattern markdown file the place pictures are changed with the S3 file location:
Doc processing
That is probably the most vital step of the method. The important thing goal of this step is to generate vector embeddings in order that they can be utilized for similarity matching and efficient retrieval primarily based on consumer inquiry. The method follows a number of steps, beginning with picture captioning, then doc chunking, abstract technology, and embedding technology. To caption the pictures, PDIQ scans the markdown recordsdata to find picture tags <picture>. For every of those pictures, PDIQ scans and generates a picture caption that explains the content material of the picture. This caption will get injected again into the markdown file, subsequent to the <picture> tag, thereby enriching the doc content material. This method presents improved contextual searchability. PDIQ enhances content material discovery by embedding insights extracted from pictures straight into the unique markdown recordsdata. This method ensures that picture content material turns into a part of the searchable textual content, enabling richer and extra correct context retrieval throughout search and evaluation. The method additionally saves prices. To keep away from pointless LLM inference requires very same pictures, PDIQ shops picture metadata (file location and generated captions) in Amazon DynamoDB. This step allows environment friendly reuse of beforehand generated captions, eliminating the necessity for repeated caption technology calls to LLM.
The next is an instance of a picture caption immediate:
The next is a snippet of markdown file that comprises the picture tag, LLM-generated caption, and the corresponding S3 file location:
Now that markdown recordsdata are injected with picture captions, the subsequent step is to interrupt the unique doc into chunks that match into the context window of the embeddings mannequin. PDIQ makes use of Amazon Titan Textual content Embeddings V2 mannequin to generate vectors and shops them in Aurora PostgreSQL-Appropriate Serverless. Based mostly on inner accuracy testing and chunking greatest practices from AWS, PDIQ performs chunking as follows:
- 70% of the tokens for content material
- 10% overlap between chunks
- 20% for abstract tokens
Utilizing the doc chunking logic from the earlier step, the doc is transformed into vector embeddings. The method consists of:
- Calculate chunk parameters – Decide the scale and whole variety of chunks required for the doc primarily based on the 70% calculation.
- Generate doc abstract – Use Amazon Nova Lite to create a abstract of the whole doc, constrained by the 20% token allocation. This abstract is reused throughout all chunks to offer constant context.
- Chunk and prepend abstract – Cut up the doc into overlapping chunks (10%), with the abstract prepended on the high.
- Generate embeddings – Use Amazon Titan Textual content Embeddings V2 to generate vector embeddings for every chunk (abstract plus content material), which is then saved within the vector retailer.
By designing a personalized method to generate a abstract part atop of all chunks, PDIQ ensures that when a specific chunk is matched primarily based on similarity search, the LLM has entry to the whole abstract of the doc and never solely the chunk that matched. This method enriches finish consumer expertise leading to a rise of approval charge for accuracy from 60% to 79%.
The next is an instance of a summarization immediate:
The next is an instance of abstract textual content, accessible on every chunk:
Chunk 1 has a abstract on the high adopted by particulars from the supply:
Chunk 2 has a abstract on the high, adopted by continuation of particulars from the supply:
PDIQ scans every doc chunk and generates vector embeddings. This knowledge is saved in Aurora PostgreSQL database with key attributes, together with a novel information base ID, corresponding embeddings attribute, unique textual content (abstract plus chunk plus picture caption), and a JSON binary object that features metadata fields for extensibility. To maintain the information base in sync, PDI implements the next steps:
- Add – These are web new supply objects that needs to be ingested. PDIQ implements the doc processing circulate described beforehand.
- Replace – If PDIQ determines the identical object is current, it compares the hash key worth from the supply with the hash worth from the JSON object.
- Delete – If PDIQ determines {that a} particular supply doc not exists, it triggers a delete operation on the S3 bucket (
s3:ObjectRemoved:*), which ends up in a cleanup job, deleting the data akin to the important thing worth within the Aurora desk.
PDI makes use of Amazon Nova Professional to retrieve probably the most related doc and generates a response by following these key steps:
- Utilizing similarity search, retrieves probably the most related doc chunks, which embody abstract, chunk knowledge, picture caption, and picture hyperlink.
- For the matching chunk, retrieve the whole doc.
- LLM then replaces the picture hyperlink with the precise picture from Amazon S3.
- LLM generates a response primarily based on the information retrieved and the preconfigured system immediate.
The next is a snippet of system immediate:
Outcomes and subsequent steps
By constructing this personalized RAG answer on AWS, PDI realized the next advantages:
- Versatile configuration choices permit knowledge ingestion at consumer-preferred frequencies.
- Scalable design allows future ingestion from further supply techniques via simply configurable crawlers.
- Helps crawler configuration utilizing a number of authentication strategies, together with username and password, secret key-value pairs, and API keys.
- Customizable metadata fields allow superior filtering and enhance question efficiency.
- Dynamic token administration helps PDI intelligently stability tokens between content material and summaries, enhancing consumer responses.
- Consolidates numerous supply knowledge codecs right into a unified format for streamlined storage and retrieval.
PDIQ gives key enterprise outcomes that embody:
- Improved effectivity and determination charges – The instrument empowers PDI help groups to resolve buyer queries considerably sooner, typically automating routine points and offering rapid, exact responses. This has led to much less buyer ready on case decision and extra productive brokers.
- Excessive buyer satisfaction and loyalty – By delivering correct, related, and customized solutions grounded in stay documentation and firm information, PDIQ elevated buyer satisfaction scores (CSAT), web promoter scores (NPS), and total loyalty. Prospects really feel heard and supported, strengthening PDI model relationships.
- Price discount – PDIQ handles the majority of repetitive queries, permitting restricted help workers to deal with expert-level circumstances, which improves productiveness and morale. Moreover, PDIQ is constructed on serverless structure, which routinely scales whereas minimizing operational overhead and value.
- Enterprise flexibility – A single platform can serve totally different enterprise items, who can curate the content material by configuring their respective knowledge sources.
- Incremental worth – Every new content material supply provides measurable worth with out system redesign.
PDI continues to reinforce the appliance with a number of deliberate enhancements within the pipeline, together with:
- Construct further crawler configuration for brand spanking new knowledge sources (for instance, GitHub).
- Construct agentic implementation for PDIQ to be built-in into bigger complicated enterprise processes.
- Enhanced doc understanding with desk extraction and construction preservation.
- Multilingual help for world operations.
- Improved relevance rating with hybrid retrieval strategies.
- Skill to invoke PDIQ primarily based on occasions (for instance, supply commits).
Conclusion
PDIQ service has reworked how customers entry and use enterprise information at PDI Applied sciences. By utilizing Amazon serverless companies, PDIQ can routinely scale with demand, scale back operational overhead, and optimize prices. The answer’s distinctive method to doc processing, together with the dynamic token administration and the customized picture captioning system, represents important technical innovation in enterprise RAG techniques. The structure efficiently balances efficiency, price, and scalability whereas sustaining safety and authentication necessities. As PDI Applied sciences proceed to increase PDIQ’s capabilities, they’re excited to see how this structure can adapt to new sources, codecs, and use circumstances.
In regards to the authors
 Samit Kumbhani is an Amazon Net Companies (AWS) Senior Options Architect within the New York Metropolis space with over 18 years of expertise. He at present companions with impartial software program distributors (ISVs) to construct extremely scalable, progressive, and safe cloud options. Exterior of labor, Samit enjoys enjoying cricket, touring, and biking.
Samit Kumbhani is an Amazon Net Companies (AWS) Senior Options Architect within the New York Metropolis space with over 18 years of expertise. He at present companions with impartial software program distributors (ISVs) to construct extremely scalable, progressive, and safe cloud options. Exterior of labor, Samit enjoys enjoying cricket, touring, and biking.
 Jhorlin De Armas is an Architect II at PDI Applied sciences, the place he leads the design of AI-driven platforms on Amazon Net Companies (AWS). Since becoming a member of PDI in 2024, he has architected a compositional AI service that permits configurable assistants, brokers, information bases, and guardrails utilizing Amazon Bedrock, Aurora Serverless, AWS Lambda, and DynamoDB. With over 18 years of expertise constructing enterprise software program, Jhorlin makes a speciality of cloud-centered architectures, serverless platforms, and AI/ML options.
Jhorlin De Armas is an Architect II at PDI Applied sciences, the place he leads the design of AI-driven platforms on Amazon Net Companies (AWS). Since becoming a member of PDI in 2024, he has architected a compositional AI service that permits configurable assistants, brokers, information bases, and guardrails utilizing Amazon Bedrock, Aurora Serverless, AWS Lambda, and DynamoDB. With over 18 years of expertise constructing enterprise software program, Jhorlin makes a speciality of cloud-centered architectures, serverless platforms, and AI/ML options.
 David Mbonu is a Sr. Options Architect at Amazon Net Companies (AWS), serving to horizontal enterprise software ISV clients construct and deploy transformational options on AWS. David has over 27 years of expertise in enterprise options structure and system engineering throughout software program, FinTech, and public cloud corporations. His current pursuits embody AI/ML, knowledge technique, observability, resiliency, and safety. David and his household reside in Sugar Hill, GA.
David Mbonu is a Sr. Options Architect at Amazon Net Companies (AWS), serving to horizontal enterprise software ISV clients construct and deploy transformational options on AWS. David has over 27 years of expertise in enterprise options structure and system engineering throughout software program, FinTech, and public cloud corporations. His current pursuits embody AI/ML, knowledge technique, observability, resiliency, and safety. David and his household reside in Sugar Hill, GA.

{kind=link}