


Chroma 1.0 is a real-time Speech-to-Speech interplay mannequin that takes audio as enter and returns audio as output whereas preserving speaker identification throughout a number of turns of dialog. It’s delivered as the primary open-source, end-to-end voice interplay system that mixes low-latency interactions with high-fidelity, personalised voice cloning from simply seconds of reference audio.
This mannequin operates straight on discrete audio representations quite than textual content transcripts. It targets the identical use instances as industrial real-time brokers, however with a compact 4B-parameter dialog core and a design that treats speaker similarity as a major goal quite than as an auxiliary characteristic. Chroma can generate audio greater than twice quicker than playback, with a reported 10.96% relative enchancment in speaker similarity in comparison with a human baseline and a real-time issue (RTF) reaching 0.43.
Cascaded ASR ➡️ LLM ➡️ TTS ➡️ Finish-to-end from S2S
Most manufacturing assistants nonetheless use a three-stage pipeline, automated speech recognition to transform speech to textual content, giant language fashions for inference, and text-to-speech synthesis. Though this construction is versatile, when the system collapses speech into textual content, it introduces delays and loses paralinguistic info equivalent to timbre, emotion, talking fee, and prosody. In real-time interactions, this lack of acoustic element has a direct damaging affect on speaker constancy and naturalness.
Chroma follows a brand new class of speech synthesis methods that map between sequences of codec tokens. Audio tokenizers and neural codecs generate quantized acoustic codes. The language mannequin then responds by inferring a sequence that interleaves the textual content tokens and audio code with out specific intermediate transcription. This situations the mannequin on prosody and speaker identification all through the processing chain.
Structure, Reasoner + Speech Era Stack
Chroma 1.0 has two main subsystems. Chroma Reasoner handles multimodal understanding and textual content technology. The voice stack, Chroma Spine, Chroma Decoder, and Chroma Codec Decoder, converts that semantic output into personalised response speech.
Chroma Reasoner is constructed on the Qwen-omni sequence of Thinker modules and makes use of the Qwen2 Audio encoding pipeline. Course of textual content and audio enter on a shared entrance finish, mix with cross-modal consideration, and modify over time utilizing Time aligned Multimodal Rotary Place Embedding (TM-RoPE). The output is a set of hidden states that convey each linguistic content material and acoustic cues (equivalent to rhythm and emphasis).

Chroma Spine is a 1B parameter LLaMA fashion mannequin primarily based on Llama3. That is conditioned to the goal voice utilizing CSM-1B. CSM-1B encodes a brief reference audio clip and its transcript into an embedded immediate that’s added to the start of the sequence. Throughout inference, the token embeddings and hidden state from Reasoner are fed as a unified context, so Spine all the time checks the semantic state of the interplay whereas producing the acoustic code.
To help streaming, the system makes use of a hard and fast 1:2 interleaving schedule. For every textual content token from Reasoner, the spine generates two audio code tokens. This permits the mannequin to begin producing speech as quickly as textual content technology begins, with out having to attend for an entire sentence. This interleaving is the primary mechanism that reduces the time to first token.
Chroma Decoder is a light-weight LLaMA variant with roughly 100 million parameters. The spine predicts solely the primary residual vector quantization codebook for every body, which is a rough illustration. Then, the decoder takes the spine hidden state and the preliminary code and autoregressively predicts the remaining RVQ ranges throughout the similar body. This factorization preserves the temporal construction of lengthy contexts within the spine and limits the decoder to frame-local refinement, lowering computational complexity and bettering detailed prosody and articulation.
The chroma codec decoder concatenates coarse and refined codes and maps them to waveform samples. Following the decoder design of the Mimi vocoder, we use a causal convolutional neural community, so every output pattern relies upon solely on the previous context wanted for streaming. This method makes use of eight codebooks to cut back the variety of autoregressive refinement steps within the decoder whereas preserving sufficient element for speech cloning.
Coaching settings and speech synthesis (S2S) information
Excessive-quality voice interplay information with robust inference alerts is uncommon. Due to this fact, Chroma makes use of an artificial speech synthesis (S2S) pipeline. Reasoner, like LLM, first generates a textual content reply to the consumer’s query. A TTS (Take a look at to Speech) system then synthesizes a goal voice that matches the timbre of the reference voice for these solutions. These artificial pairs prepare the spine and decoder to carry out acoustic modeling and voice cloning. Reasoner stays frozen and acts as a supplier of textual content embedding and multimodal hidden states.
Comparability of voice clone high quality and current methods
The target analysis makes use of the SEED-TTS-EVAL protocol for English CommonVoice audio system. Chroma operates at a sampling fee of 24 kHz and achieves a speaker similarity rating of 0.81. The human baseline is 0.73. CosyVoice-3 reaches 0.72, and most different TTS baselines are beneath human requirements. The analysis staff experiences this as a relative enchancment of 10.96% in comparison with the human baseline. This means that, on this metric, the mannequin captures tremendous paralinguistic particulars extra persistently than human recordings.
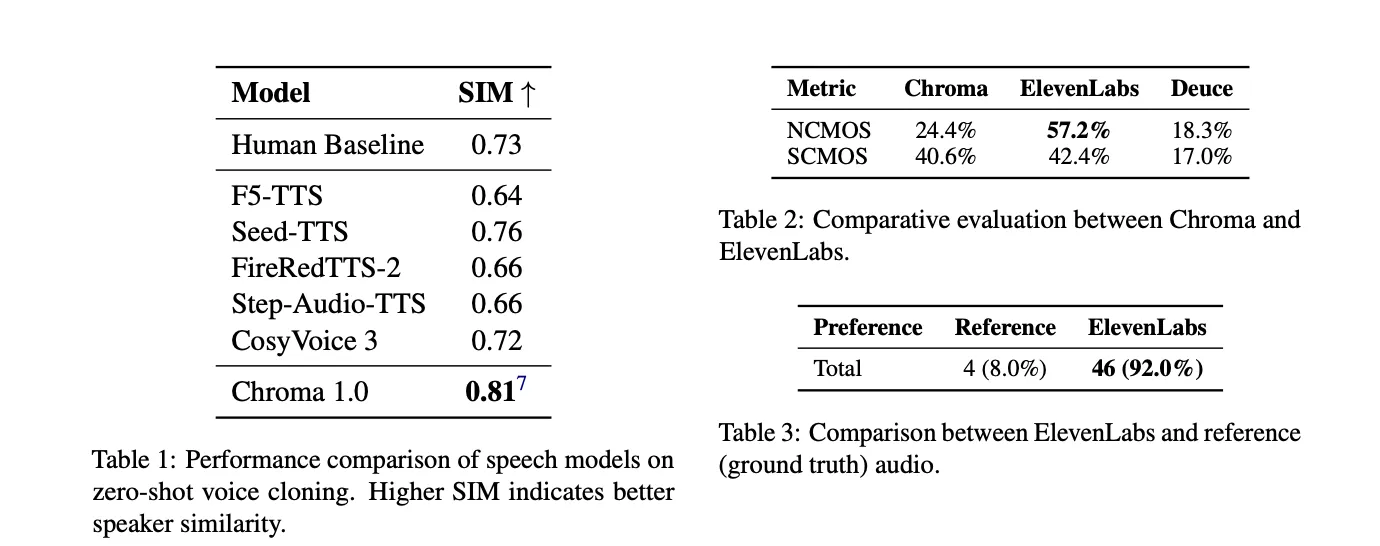
In our subjective analysis, we examine Chroma and Eleven Labs’ eleven_multilingual_v2 mannequin. In pure CMOS, listeners most well-liked Eleven Labs 57.2% of the time, in comparison with 24.4% for Chroma and 18.3% for Deuce. Speaker Similarity In CMOS, the scores had been very shut, with Eleven Lab at 42.4%, Chroma at 40.6%, and Deuce at 17.0%. In a follow-up take a look at asking whether or not the audio sounds extra pure: Elemental Labs or the unique recording, Elemental Labs scored 92.0% versus Floor Reality’s 8.0%, indicating a mismatch between perceived naturalness and speaker constancy.
Latency and real-time habits
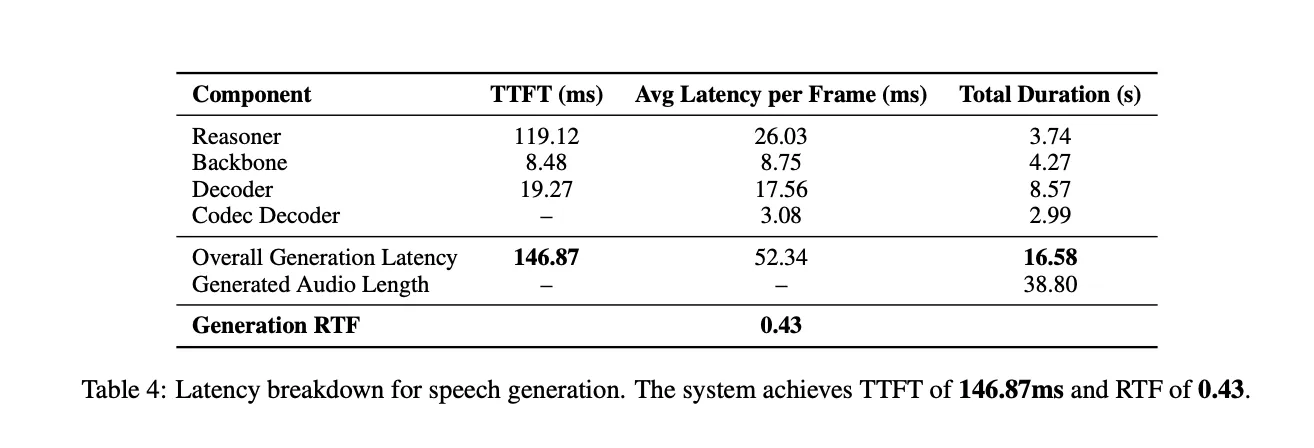
Latency is measured on one simultaneous stream. For a response of 38.80 seconds, the entire technology time is 16.58 seconds and the real-time issue (RTF) is 0.43. On common, Reasoner contributes 119.12 ms TTFT, Spine 8.48 ms, and Decoder 19.27 ms TTFT per body. The codec decoder operates on teams of 4 frames, so TTFT will not be utilized to that element. The general time to first token was 146.87 ms, which is properly beneath 1 second and appropriate for interactive interactions.
Benchmarking spoken dialogue and reasoning
Chroma is evaluated on the essential observe of the URO bench. Despite the fact that we solely use the parameter 4B, the general process completion rating is 57.44%. GLM-4 Voice, a 9B parameter mannequin, ranked first with 69.09%. Chroma ranks second general and outperforms a number of 7B and 0.5B omni baselines in some ways. It reaches 71.14% for Storal, 51.69% for TruthfulQA, and 22.74% for GSM8K. When it comes to oral dialog metrics, it achieved the best scores of 60.26% in MLC and 62.07% in CommonVoice.
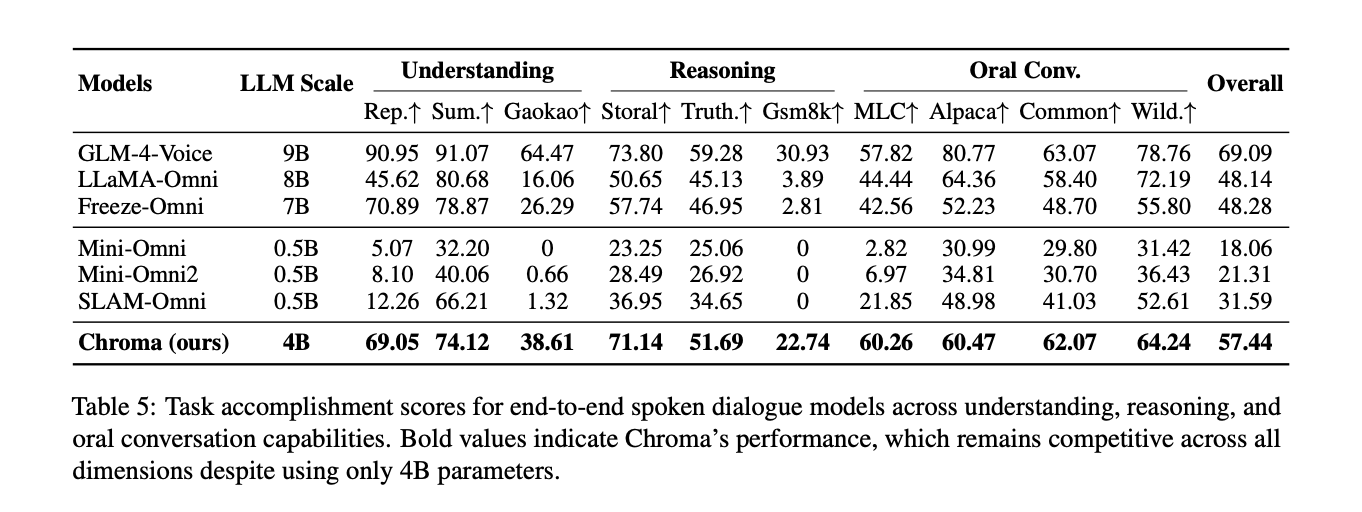
Importantly, Chroma is the one mannequin on this comparability that helps personalised voice cloning. All different methods focus solely on spoken interplay and reasoning. This implies Chroma can carry out high-fidelity voice personalization in real-time whereas delivering aggressive cognitive capabilities.
Vital factors
- Finish-to-end real-time speech-to-speech: Chroma 1.0 is a 4B-parameter voice interplay mannequin that makes use of codec tokens to straight map speech to speech, avoiding specific ASR and TTS phases and preserving prosody and speaker identification all through the pipeline.
- Reasoner and voice stack structure: This method combines a Qwen-based Chroma Reasoner with a 1B LLaMA-style spine, a 100M Chroma Decoder, and a Mimi-based Codec Decoder. Makes use of an interleaved 1:2 text-to-audio token schedule with the RVQ codebook to help streaming and quick first-token instances.
- Highly effective personalised voice cloning: In SEED-TTS-EVAL with CommonVoice audio system, Chroma reaches a speaker similarity rating of 0.81 at 24 kHz, which is reported as a relative enchancment of 10.96 % over the human baseline of 0.73, over CozyVoice 3 and different TTS baselines.
- Sooner than real-time technology with lower than 1 second delay: For single-stream inference on the H200 GPU, the general time-to-first token is roughly 147 ms, and for a 38.80-second response, the mannequin generates audio in 16.58 seconds, with a real-time issue of 0.43, which is greater than 2x quicker than playback.
- Aggressive interplay and reasoning with cloning as a novel characteristic: On the URO Bench Primary observe, Chroma achieved aggressive scores with an general process completion fee of 57.44 % on Storal, TruthfulQA, GSM8K, MLC, and CommonVoice.
Please test paper, model weights, project and playground. Please be at liberty to observe us too Twitter Remember to hitch us 100,000+ ML subreddits and subscribe our newsletter. hold on! Are you on telegram? You can now also participate by telegram.

{kind=link}