


The quickly evolving panorama of large-scale language fashions (LLMs) has targeted totally on decoder-only architectures. Though these fashions have proven good performance throughout a variety of era duties, basic encoder/decoder architectures equivalent to T5 (Textual content-to-Textual content Switch Transformer) stay a well-liked selection for a lot of real-world functions. Encoder-decoder fashions are sometimes higher for summarization, translation, QA, and so on. on account of their excessive inference effectivity, design flexibility, and richer encoder representations to grasp the enter. However, highly effective encoder/decoder architectures haven’t obtained a lot consideration.
Right this moment we are going to revisit and introduce this structure. T5 Gemmaa brand new assortment of encoder-decoder LLMs developed by changing a pre-trained decoder-specific mannequin into an encoder-decoder structure by means of a way known as adaptation. T5Gemma relies on the Gemma 2 framework and consists of tailored Gemma 2 2B and 9B fashions and a set of newly skilled T5 dimension fashions (Small, Base, Massive, XL). We’re excited to launch the pre-trained and instruction-tuned T5Gemma mannequin to the neighborhood to open up new alternatives for analysis and improvement.
From decoder solely to encoder-decoder
T5Gemma asks the next questions: Can I construct a top-level encoder/decoder mannequin based mostly on a pre-trained decoder-only mannequin? We reply this query by contemplating a way known as . mannequin adaptation. The core concept is to initialize the parameters of the encoder-decoder mannequin utilizing the weights of an already pre-trained decoder-only mannequin and additional adapt them by means of UL2 or PrefixLM-based pre-training.
Overview of our method. Demonstrates find out how to initialize a brand new encoder/decoder mannequin utilizing parameters from a pretrained decoder-only mannequin.
This adaptation methodology is extremely versatile and permits for artistic combos of mannequin sizes. For instance, you possibly can mix a big encoder and a small decoder (for instance, a 9B encoder and a 2B decoder) to create an “unbalanced” mannequin. This lets you fine-tune the trade-off between high quality and effectivity for sure duties, equivalent to summarization, the place a deeper understanding of the enter is extra essential than the complexity of the output produced.
Towards bettering the trade-off between high quality and effectivity
How is T5Gemma performing?
In our experiments, the T5Gemma mannequin achieves efficiency equal to or higher than the decoder-only Gemma mannequin and practically dominates the Pareto frontier of high quality inference effectivity throughout a number of benchmarks, together with SuperGLUE, which measures the standard of the discovered representations.
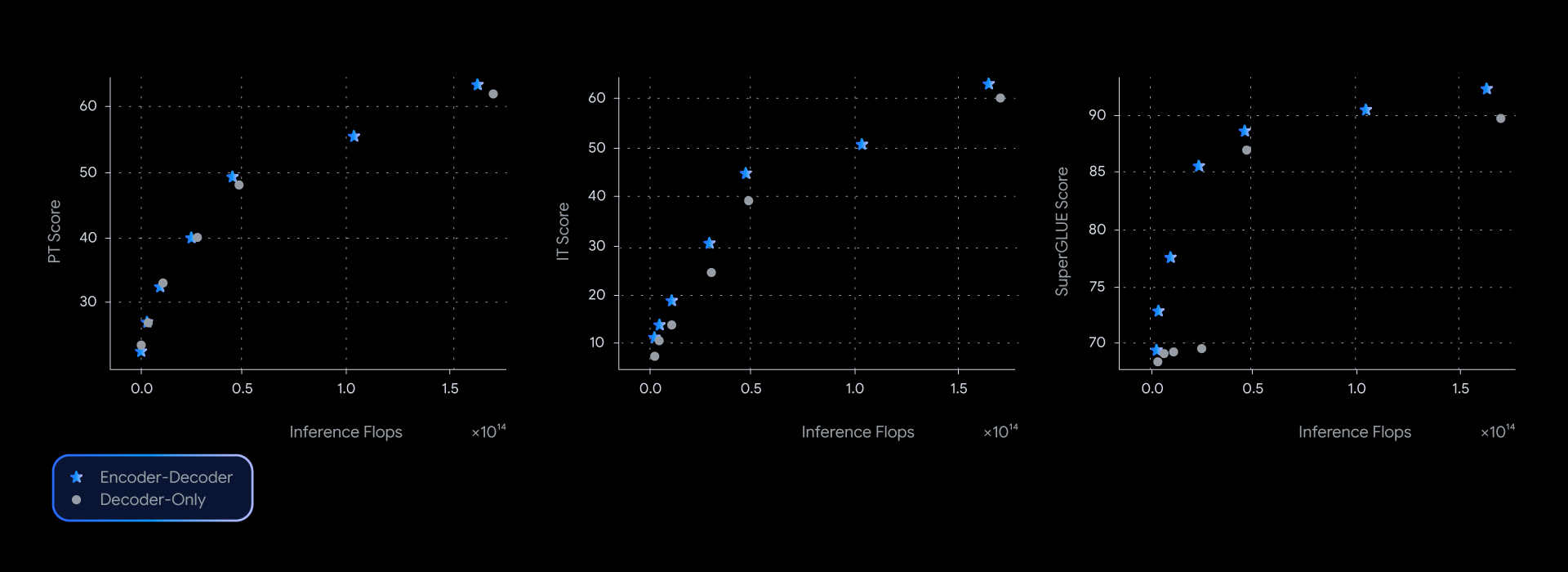
Encoder/decoder fashions constantly present superior efficiency for a given degree of inference computing and lead on the standard effectivity entrance throughout quite a lot of benchmarks.
This efficiency benefit is not only theoretical. It additionally interprets into real-world high quality and pace. When measuring the precise latency of GSM8K (mathematical reasoning), T5Gemma has a transparent win. For instance, T5Gemma 9B-9B achieves greater accuracy than Gemma 2 9B, however has comparable latency. What’s much more spectacular is that although the T5Gemma 9B-2B has considerably improved accuracy in comparison with the 2B-2B mannequin, its latency is about the identical because the a lot decrease Gemma 2 2B mannequin. In the end, these experiments show that encoder and decoder adaptation offers a versatile and highly effective solution to steadiness high quality and inference pace.
Unlock fundamental and fine-tuned options
Might an encoder/decoder LLM have comparable performance to a decoder-only mannequin?
Sure, T5Gemma exhibits promising performance earlier than and after instruction tuning.
After pre-training, T5Gemma achieves spectacular outcomes on complicated duties that require inference. For instance, the T5Gemma 9B-9B scores over 9 factors greater in GSM8K (Mathematical Reasoning) and over 4 factors greater in DROP (Studying Studying) in comparison with the unique Gemma 2 9B mannequin. This sample signifies that if the encoder/decoder structure is initialized by means of adaptation, it might be attainable to create a extra succesful and performant base mannequin.
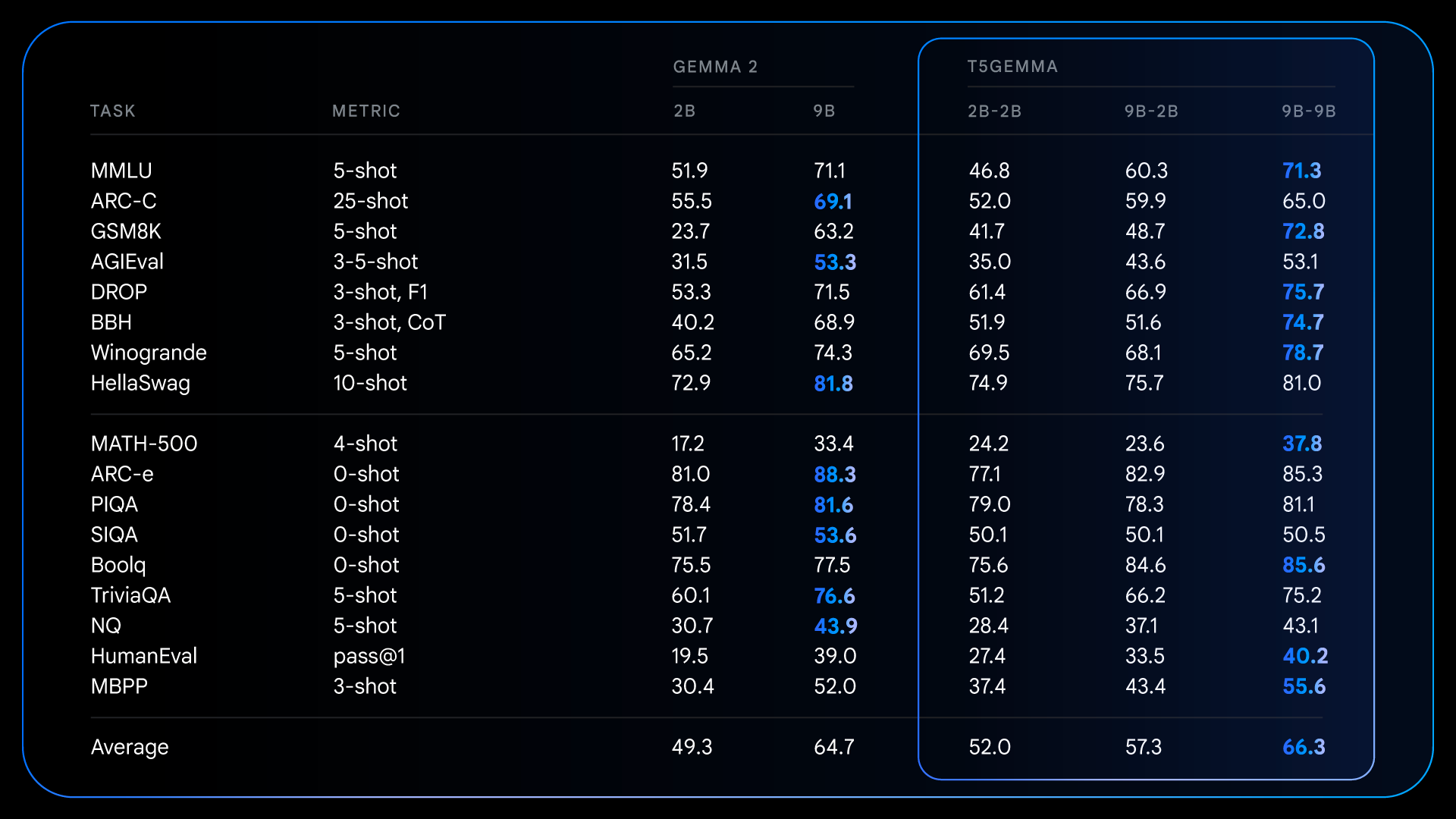
Detailed outcomes for pre-trained fashions. We present how our adaptive mannequin exhibits vital enchancment on a number of inference-intensive benchmarks in comparison with the decoder-only Gemma 2.
These fundamental enhancements by means of pre-training will set you as much as see much more dramatic results as soon as your directions are adjusted. For instance, when evaluating Gemma 2 IT and T5Gemma IT, the general efficiency distinction is far bigger. For T5Gemma 2B-2B IT, the MMLU rating elevated by practically 12 factors over Gemma 2 2B, and the GSM8K rating elevated from 58.0% to 70.7%. An tailored structure not solely doubtlessly offers a greater start line, but in addition responds extra successfully to instruction tuning, finally resulting in a considerably extra succesful and helpful closing mannequin.
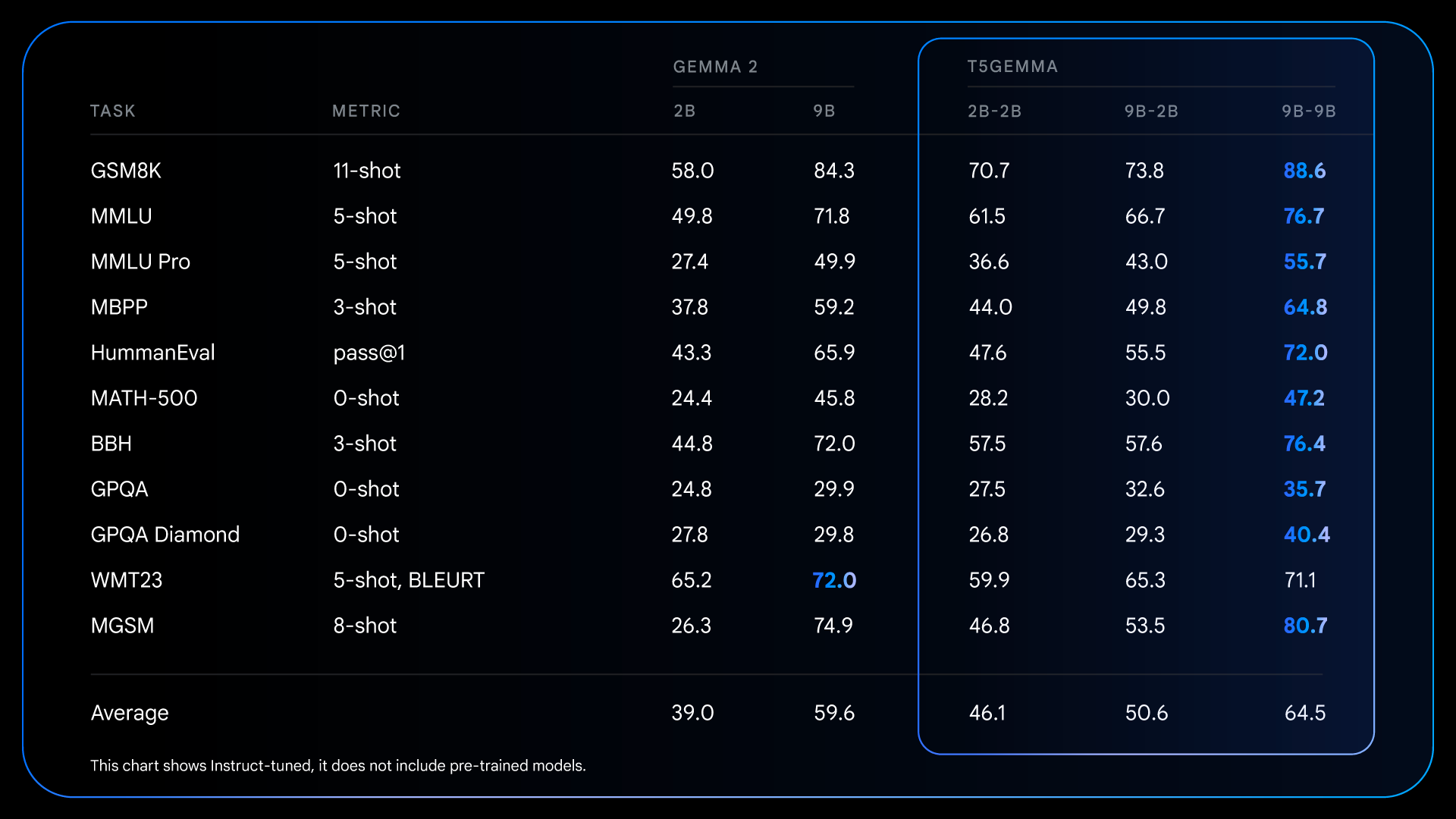
Tremendous-tuning + detailed outcomes for the RLHF mannequin. We show post-training capabilities that considerably amplify the efficiency advantages of encoder/decoder architectures.
Discover the mannequin: T5Gemma checkpoint launch
We’re very excited to introduce this new solution to construct highly effective general-purpose encoder/decoder fashions by adapting pre-trained decoder-specific LLMs like Gemma 2. To speed up additional analysis and allow the neighborhood to construct on this work, we’re happy to launch a set of T5Gemma checkpoints.
The discharge consists of:
- A number of sizes: Checkpoints for T5 dimension fashions (Small, Base, Massive, and XL), Gemma 2-based fashions (2B and 9B), and extra fashions between T5 Massive and T5 XL.
- a number of variants: A pre-trained, instruction-tailored mannequin.
- Versatile configuration: A robust and environment friendly unbalanced 9B-2B checkpoint to discover tradeoffs between encoder and decoder sizes.
- Varied coaching targets: Fashions skilled with PrefixLM or UL2 targets present state-of-the-art generative efficiency or illustration high quality.
We hope these checkpoints can be a helpful useful resource for exploring your mannequin’s structure, effectivity, and efficiency.
Get began with T5Gemma
I am unable to wait to see what you construct with T5Gemma. For extra data please see the next hyperlink:
- Learn beneath to be taught concerning the analysis behind this undertaking. paper.
- You possibly can discover the mannequin’s capabilities and fine-tune it to your personal use case. collaboration note.

{kind=link}