


This put up was written with Bryan Woolgar-O’Neil, Jamie Cockrill and Adrian Cunliffe from Harmonic Safety
Organizations face rising challenges defending delicate information whereas supporting third-party generative AI instruments. Harmonic Security, a cybersecurity firm, developed an AI governance and management layer that spots delicate information in line as workers use AI, giving safety groups the facility to maintain PII, supply code, and payroll data protected whereas the enterprise accelerates.
The next screenshot demonstrates Harmonic Safety’s software program device, highlighting the completely different information leakage detection varieties, together with Worker PII, Worker Monetary Info, and Supply Code.
Harmonic Safety’s answer can also be now out there on AWS Market, enabling organizations to deploy enterprise-grade information leakage safety with seamless AWS integration. The platform supplies prompt-level visibility into GenAI utilization, real-time teaching on the level of threat, and detection of high-risk AI functions—all powered by the optimized fashions described on this put up.
The preliminary model of their system was efficient, however with a detection latency of 1–2 seconds, there was a possibility to additional improve its capabilities and enhance the general consumer expertise. To realize this, Harmonic Safety partnered with the AWS Generative AI Innovation Middle to optimize their system with 4 key targets:
- Scale back detection latency to beneath 500 milliseconds on the ninety fifth percentile
- Keep detection accuracy throughout monitored information varieties
- Proceed to assist EU information residency compliance
- Allow scalable structure for manufacturing hundreds
This put up walks by how Harmonic Safety used Amazon SageMaker AI, Amazon Bedrock, and Amazon Nova Professional to fine-tune a ModernBERT mannequin, attaining low-latency, correct, and scalable information leakage detection.
Resolution overview
Harmonic Safety’s preliminary information leakage detection system relied on an 8 billion (8B) parameter mannequin, which successfully recognized delicate information however incurred 1–2 second latency, which ran near the edge of impacting consumer expertise. To realize sub-500 millisecond latency whereas sustaining accuracy, we developed two classification approaches utilizing a fine-tuned ModernBERT model.
First, a binary classification mannequin was prioritized to detect Mergers & Acquisitions (M&A) content material, a essential class for serving to forestall delicate information leaks. We initially targeted on binary classification as a result of it was the only strategy that may seamlessly combine inside their present system that invokes a number of binary classification fashions in parallel. Secondly, as an extension, we explored a multi-label classification mannequin to detect a number of delicate information varieties (corresponding to billing data, monetary projections, and employment data) in a single move, aiming to scale back the computational overhead of working a number of parallel binary classifiers for larger effectivity. Though the multi-label strategy confirmed promise for future scalability, Harmonic Safety determined to stay with the binary classification mannequin for the preliminary model.The answer makes use of the next key providers:
The next diagram illustrates the answer structure for low-latency inference and scalability.
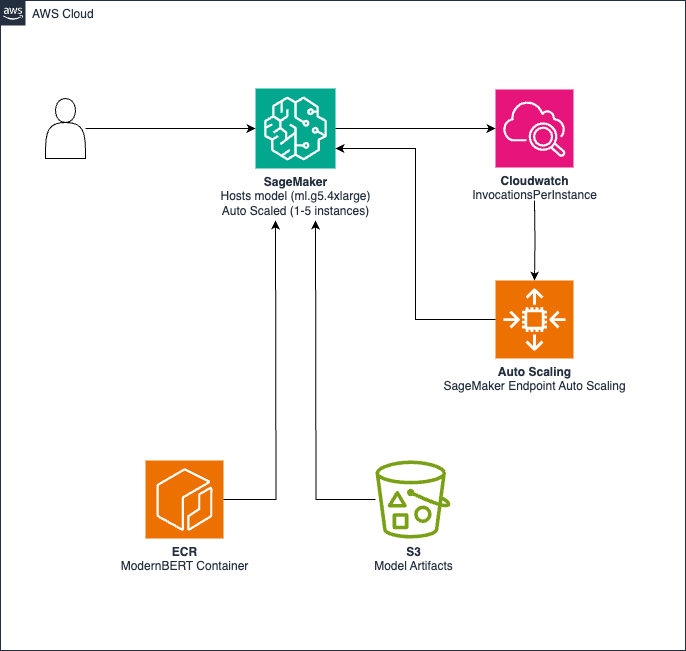
The structure consists of the next parts:
- Mannequin artifacts are saved in Amazon Easy Storage Service (Amazon S3)
- A customized container with inference code is hosted in Amazon Elastic Container Registry (Amazon ECR)
- A SageMaker endpoint makes use of ml.g5.4xlarge cases for GPU-accelerated inference
- Amazon CloudWatch screens invocations, triggering auto scaling to regulate cases (1–5) primarily based on an 830 requests per minute (RPM) threshold.
The answer helps the next options:
- Sub-500 milliseconds inference latency
- EU AWS Area deployment assist
- Computerized scaling between 1–5 cases primarily based on demand
- Price optimization throughout low-usage intervals
Artificial information era
Excessive-quality coaching information for delicate data (corresponding to M&A paperwork and monetary information) is scarce. We used Meta Llama 3.3 70B Instruct and Amazon Nova Professional to generate artificial information, increasing upon Harmonic’s current dataset that included examples of knowledge within the following classes: M&A, billing data, monetary projection, employment data, gross sales pipeline, and funding portfolio. The next diagram supplies a high-level overview of the artificial information era course of.
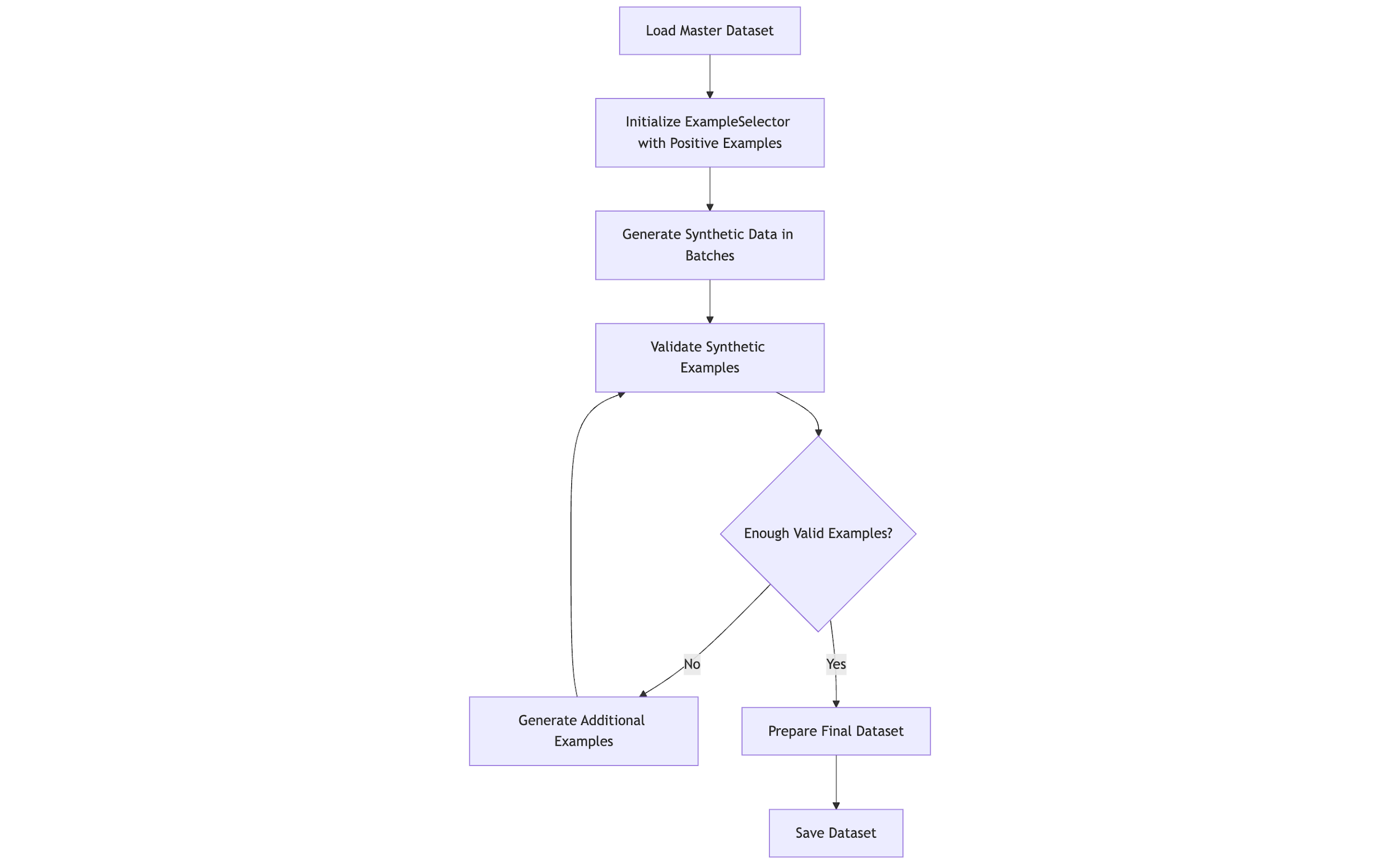
Knowledge era framework
The artificial information era framework is comprised of a collection of steps, together with:
- Sensible instance choice – Okay-means clustering on sentence embeddings helps numerous instance choice
- Adaptive prompts – Prompts incorporate area data, with temperature (0.7–0.85) and top-p sampling adjusted per class
- Close to-miss augmentation – Detrimental examples resembling constructive circumstances to enhance precision
- Validation – An LLM-as-a-judge strategy utilizing Amazon Nova Professional and Meta Llama 3 validates examples for relevance and high quality
Binary classification
For the binary M&A classification process, we generated three distinct sorts of examples:
- Optimistic examples – These contained express M&A data whereas sustaining real looking doc constructions and finance-specific language patterns. They included key indicators like “merger,” “acquisition,” “deal phrases,” and “synergy estimates.”
- Detrimental examples – We created domain-relevant content material that intentionally prevented M&A traits whereas remaining contextually applicable for enterprise communications.
- Close to-miss examples – These resembled constructive examples however fell simply outdoors the classification boundary. As an illustration, paperwork discussing strategic partnerships or joint ventures that didn’t represent precise M&A exercise.
The era course of maintained cautious proportions between these instance varieties, with explicit emphasis on near-miss examples to deal with precision necessities.
Multi-label classification
For the extra complicated multi-label classification process throughout 4 delicate data classes, we developed a classy era technique:
- Single-label examples – We generated examples containing data related to precisely one class to ascertain clear category-specific options
- Multi-label examples – We created examples spanning a number of classes with managed distributions, masking numerous mixtures (2–4 labels)
- Class-specific necessities – For every class, we outlined necessary components to keep up express fairly than implied associations:
- Monetary projections – Ahead-looking income and development information
- Funding portfolio – Particulars about holdings and efficiency metrics
- Billing and fee data – Invoices and provider accounts
- Gross sales pipeline – Alternatives and projected income
Our multi-label era prioritized real looking co-occurrence patterns between classes whereas sustaining enough illustration of particular person classes and their mixtures. Consequently, artificial information elevated coaching examples by 10 instances (binary) and 15 instances (multi-label) extra. It additionally improved the category steadiness as a result of we made positive to generate the information with a extra balanced label distribution.
Mannequin fine-tuning
We fine-tuned ModernBERT fashions on SageMaker to attain low latency and excessive accuracy. In contrast with decoder-only fashions corresponding to Meta Llama 3.2 3B and Google Gemma 2 2B, ModernBERT’s compact dimension (149M and 395M parameters) translated into sooner latency whereas nonetheless delivering increased accuracy. We subsequently chosen ModernBERT over fine-tuning these options. As well as, ModernBERT is likely one of the few BERT-based fashions that helps context lengths of as much as 8,192 tokens, which was a key requirement for our undertaking.
Binary classification mannequin
Our first fine-tuned mannequin used ModernBERT-base, and we targeted on binary classification of M&A content material.We approached this process methodically:
- Knowledge preparation – We enriched our M&A dataset with the synthetically generated information
- Framework choice – We used the Hugging Face transformers library with the Coach API in a PyTorch atmosphere, working on SageMaker
- Coaching course of – Our course of included:
- Stratified sampling to keep up label distribution throughout coaching and analysis units
- Specialised tokenization with sequence lengths as much as 3,000 tokens to match what the consumer had in manufacturing
- Binary cross-entropy loss optimization
- Early stopping primarily based on F1 rating to stop overfitting.
The consequence was a fine-tuned mannequin that might distinguish M&A content material from non-sensitive data with a better F1 rating than the 8B parameter mannequin.
Multi-label classification mannequin
For our second mannequin, we tackled the extra complicated problem of multi-label classification (detecting a number of delicate information varieties concurrently inside single textual content passages).We fine-tuned a ModernBERT-large mannequin to establish numerous delicate information varieties like billing data, employment data, and monetary projections in a single move. This required:
- Multi-hot label encoding – We transformed our classes into vector format for simultaneous prediction.
- Focal loss implementation – As a substitute of ordinary cross-entropy loss, we carried out a customized FocalLossTrainer class. In contrast to static weighted loss capabilities, Focal Loss adaptively down-weights easy examples throughout coaching. This helps the mannequin think about difficult circumstances, considerably enhancing efficiency for much less frequent or harder-to-detect courses.
- Specialised configuration – We added configurable class thresholds (for instance, 0.1 to 0.8) for every class chance to find out label project as we noticed various efficiency in several choice boundaries.
This strategy enabled our system to establish a number of delicate information varieties in a single inference move.
Hyperparameter optimization
To search out the optimum configuration for our fashions, we used Optuna to optimize key parameters. Optuna is an open-source hyperparameter optimization (HPO) framework that helps discover one of the best hyperparameters for a given machine studying (ML) mannequin by working many experiments (referred to as trials). It makes use of a Bayesian algorithm referred to as Tree-structured Parzen Estimator (TPE) to decide on promising hyperparameter mixtures primarily based on previous outcomes.
The search area explored quite a few mixtures of key hyperparameters, as listed within the following desk.
| Hyperparameter | Vary |
| Studying fee | 5e-6–5e-5 |
| Weight decay | 0.01–0.5 |
| Warmup ratio | 0.0–0.2 |
| Dropout charges | 0.1–0.5 |
| Batch dimension | 16, 24, 32 |
| Gradient accumulation steps | 1, 4 |
| Focal loss gamma (multi-label solely) | 1.0–3.0 |
| Class threshold (multi-label solely) | 0.1–0.8 |
To optimize computational assets, we carried out pruning logic to cease under-performing trials early, so we may discard configurations that have been much less optimum. As seen within the following Optuna HPO historical past plot, trial 42 had probably the most optimum parameters with the very best F1 rating for the binary classification, whereas trial 32 was probably the most optimum for the multi-label.
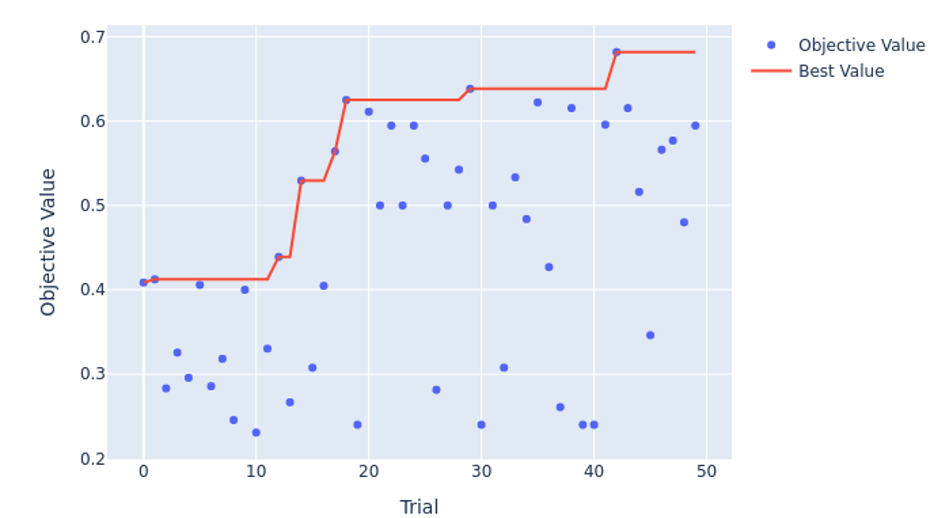
Furthermore, our evaluation confirmed that dropout and studying fee have been crucial hyperparameters, accounting for 48% and 21% of the variance of the F1 rating for the binary classification mannequin. This defined why we seen the mannequin overfitting shortly throughout earlier runs and stresses the significance of regularization.
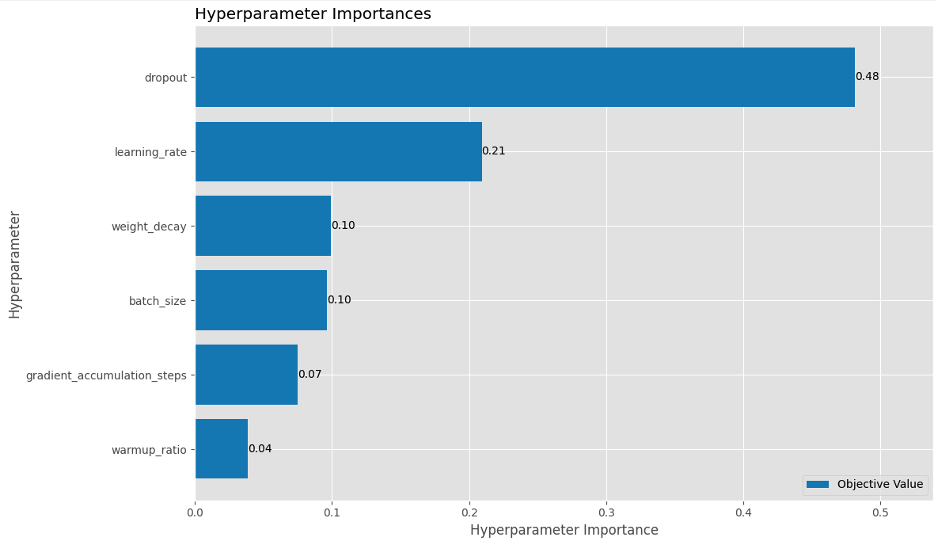
After the optimization experiments, we found the next:
- We have been capable of establish the optimum hyperparameters for every process
- The fashions converged sooner throughout coaching
- The ultimate efficiency metrics confirmed measurable enhancements over configurations we examined manually
This allowed our fashions to attain a excessive F1 rating effectively by working hyperparameter tuning in an automatic style, which is essential for manufacturing deployment.
Load testing and autoscaling coverage
After fine-tuning and deploying the optimized mannequin to a SageMaker real-time endpoint, we carried out load testing to validate the efficiency and autoscaling beneath stress to satisfy Harmonic Safety’s latency, throughput, and elasticity wants. The targets of the load testing have been:
- Validate latency SLA with a median of lower than 500 milliseconds and P95 of roughly 1 second various hundreds
- Decide throughput capability with most RPM utilizing ml.g5.4xlarge cases inside latency SLA
- Inform the auto scaling coverage design
The methodology concerned the next:
- Site visitors simulation – Locust simulated concurrent consumer visitors with various textual content lengths (50–9,999 characters)
- Load sample – We stepped ramp-up assessments (60–2,000 RPM, 60 seconds every) and recognized bottlenecks and stress-tested limits
As proven within the following graph, we discovered that the utmost throughput beneath a latency of 1 second was 1,185 RPM, so we determined to set the auto scaling threshold to 70% of that at 830 RPM.
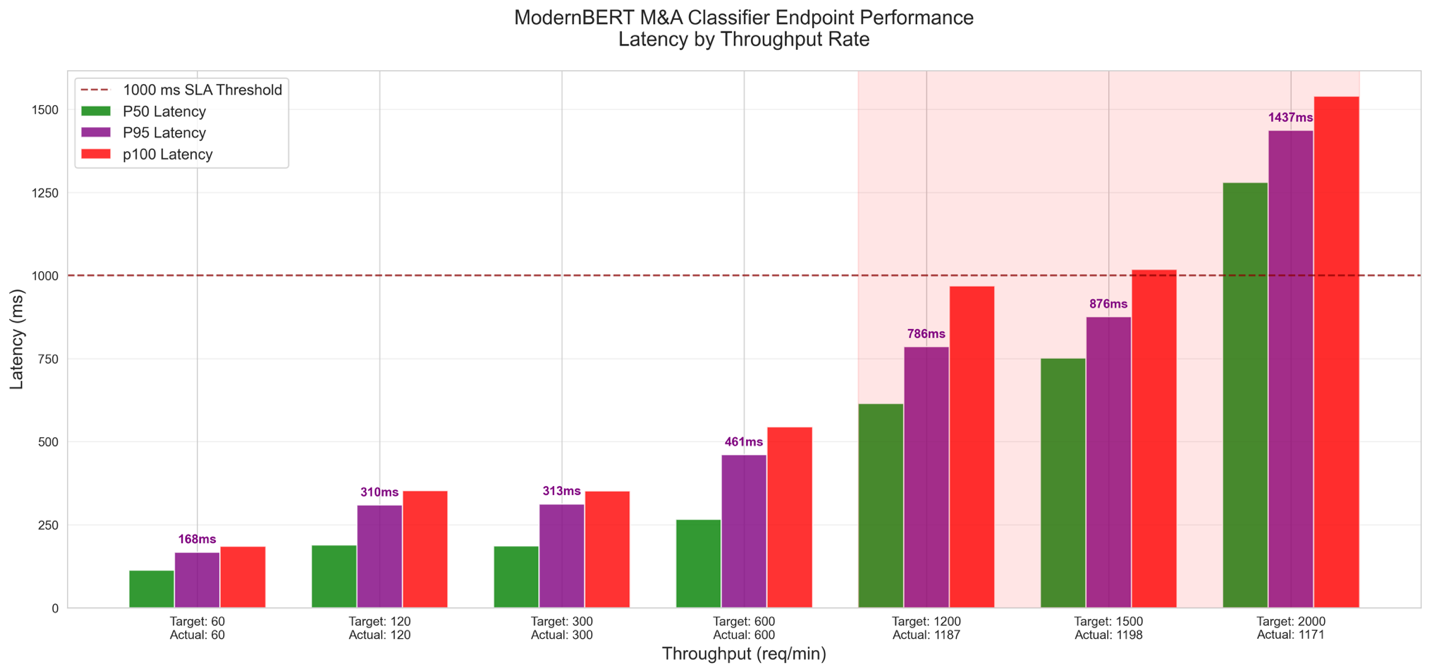
Primarily based on the efficiency noticed throughout load testing, we configured a target-tracking auto scaling coverage for the SageMaker endpoint utilizing Utility Auto Scaling. The next determine illustrates this coverage workflow.

The important thing parameters outlined have been:
- Metric –
SageMakerVariantInvocationsPerInstance(830 invocations/occasion/minute) - Min/Max Cases – 1–5
- Cooldown – Scale-out 300 seconds, scale-in 600 seconds
This target-tracking coverage adjusts cases primarily based on visitors, sustaining efficiency and cost-efficiency. The next desk summarizes our findings.
| Mannequin | Requests per Minute |
|---|---|
| 8B mannequin | 800 |
| ModernBERT with auto scaling (5 cases) | 1,185-5925 |
| Extra capability (ModernBERT vs. 8B mannequin) | 48%-640% |
Outcomes
This part showcases the numerous impression of the fine-tuning and optimization efforts on Harmonic Safety’s information leakage detection system, with a main deal with attaining substantial latency reductions. Absolute latency enhancements are detailed first, underscoring the success in assembly the sub-500 millisecond goal, adopted by an outline of efficiency enhancements. The next subsections present detailed outcomes for binary M&A classification and multi-label classification throughout a number of delicate information varieties.
Binary classification
We evaluated the fine-tuned ModernBERT-base mannequin for binary M&A classification in opposition to the baseline 8B mannequin, launched within the answer overview. Essentially the most hanging achievement was a transformative discount in latency, addressing the preliminary 1–2 second delay that risked disrupting consumer expertise. This leap to sub-500 millisecond latency is detailed within the following desk, marking a pivotal enhancement in system responsiveness.
| Mannequin | median_ms | p95_ms | p99_ms | p100_ms |
|---|---|---|---|---|
| Modernbert-base-v2 | 46.03 | 81.19 | 102.37 | 183.11 |
| 8B mannequin | 189.15 | 259.99 | 286.63 | 346.36 |
| Distinction | -75.66% | -68.77% | -64.28% | -47.13% |
Constructing on this latency breakthrough, the next efficiency metrics replicate share enhancements in accuracy and F1 rating.
| Mannequin | Accuracy Enchancment | F1 Enchancment |
| ModernBERT-base-v2 | +1.56% | +2.26% |
| 8B mannequin | – | – |
These outcomes spotlight that ModernBERT-base-v2 delivers a groundbreaking latency discount, complemented by modest accuracy and F1 enhancements of 1.56% and a couple of.26%, respectively, aligning with Harmonic Safety’s targets to reinforce information leakage detection with out impacting consumer expertise.
Multi-label classification
We evaluated the fine-tuned ModernBERT-large mannequin for multi-label classification in opposition to the baseline 8B mannequin, with latency discount because the cornerstone of this strategy. Essentially the most vital development was a considerable lower in latency throughout all evaluated classes, attaining sub-500 millisecond responsiveness and addressing the earlier 1–2 second bottleneck. The latency outcomes proven within the following desk underscore this essential enchancment.
| Dataset | mannequin | median_ms | p95_ms | p99_ms |
| Billing and fee | 8B mannequin | 198 | 238 | 321 |
| ModernBERT-large | 158 | 199 | 246 | |
| Distinction | -20.13% | -16.62% | -23.60% | |
| Gross sales pipeline | 8B mannequin | 194 | 265 | 341 |
| ModernBERT-large | 162 | 243 | 293 | |
| Distinction | -16.63% | -8.31% | -13.97% | |
| Monetary projections | 8B mannequin | 384 | 510 | 556 |
| ModernBERT-large | 160 | 275 | 310 | |
| Distinction | -58.24% | -46.04% | -44.19% | |
| Funding portfolio | 8B mannequin | 397 | 498 | 703 |
| ModernBERT-large | 160 | 259 | 292 | |
| Distinction | -59.69% | -47.86% | -58.46% |
This strategy additionally delivered a second key profit: a discount in computational parallelism by consolidating a number of classifications right into a single move. Nevertheless, the multi-label mannequin encountered challenges in sustaining constant accuracy throughout all courses. Though classes like Monetary Projections and Funding Portfolio confirmed promising accuracy good points, others corresponding to Billing and Cost and Gross sales Pipeline skilled vital accuracy declines. This means that, regardless of its latency and parallelism benefits, the strategy requires additional improvement to keep up dependable accuracy throughout information varieties.
Conclusion
On this put up, we explored how Harmonic Safety collaborated with the AWS Generative AI Innovation Middle to optimize their information leakage detection system attaining transformative outcomes:
Key efficiency enhancements:
- Latency discount: From 1–2 seconds to beneath 500 milliseconds (76% discount at median)
- Throughput improve: 48%–640% extra capability with auto scaling
- Accuracy good points: +1.56% for binary classification, with maintained precision throughout classes
By utilizing SageMaker, Amazon Bedrock, and Amazon Nova Professional, Harmonic Safety fine-tuned ModernBERT fashions that ship sub-500 millisecond inference in manufacturing, assembly stringent efficiency targets whereas supporting EU compliance and establishing a scalable structure.
This partnership showcases how tailor-made AI options can deal with essential cybersecurity challenges with out hindering productiveness. Harmonic Safety’s answer is now out there on AWS Market, enabling organizations to undertake AI instruments safely whereas defending delicate information in actual time. Trying forward, these high-speed fashions have the potential so as to add additional controls for added AI workflows.
To be taught extra, contemplate the next subsequent steps:
- Strive Harmonic Safety – Deploy the answer straight from AWS Market to guard your group’s GenAI utilization
- Discover AWS providers – Dive into SageMaker, Amazon Bedrock, and Amazon Nova Professional to construct superior AI-driven safety options. Go to the AWS Generative AI web page for assets and tutorials.
- Deep dive into fine-tuning – Discover the AWS Machine Studying Weblog for in-depth guides on fine-tuning LLMs for specialised use circumstances.
- Keep up to date – Subscribe to the AWS Podcast for weekly insights on AI improvements and sensible functions.
- Join with consultants – Be a part of the AWS Associate Community to collaborate with consultants and scale your AI initiatives.
- Attend AWS occasions – Register for AWS re: Invent. to discover cutting-edge AI developments and community with trade leaders.
By adopting these steps, organizations can harness AI-driven cybersecurity to keep up strong information safety and seamless consumer experiences throughout numerous workflows.
Concerning the authors
 Babs Khalidson is a Deep Studying Architect on the AWS Generative AI Innovation Centre in London, the place he makes a speciality of fine-tuning massive language fashions, constructing AI brokers, and mannequin deployment options. He has over 6 years of expertise in synthetic intelligence and machine studying throughout finance and cloud computing, with experience spanning from analysis to manufacturing deployment.
Babs Khalidson is a Deep Studying Architect on the AWS Generative AI Innovation Centre in London, the place he makes a speciality of fine-tuning massive language fashions, constructing AI brokers, and mannequin deployment options. He has over 6 years of expertise in synthetic intelligence and machine studying throughout finance and cloud computing, with experience spanning from analysis to manufacturing deployment.
 Vushesh Babu Adhikari is a Knowledge scientist on the AWS Generative AI Innovation middle in London with in depth experience in creating Gen AI options throughout numerous industries. He has over 7 years of expertise spanning throughout a various set of industries together with Finance , Telecom , Info Expertise with specialised experience in Machine studying & Synthetic Intelligence.
Vushesh Babu Adhikari is a Knowledge scientist on the AWS Generative AI Innovation middle in London with in depth experience in creating Gen AI options throughout numerous industries. He has over 7 years of expertise spanning throughout a various set of industries together with Finance , Telecom , Info Expertise with specialised experience in Machine studying & Synthetic Intelligence.
 Zainab Afolabi is a Senior Knowledge Scientist on the AWS Generative AI Innovation Centre in London, the place she leverages her in depth experience to develop transformative AI options throughout numerous industries. She has over 9 years of specialised expertise in synthetic intelligence and machine studying, in addition to a ardour for translating complicated technical ideas into sensible enterprise functions.
Zainab Afolabi is a Senior Knowledge Scientist on the AWS Generative AI Innovation Centre in London, the place she leverages her in depth experience to develop transformative AI options throughout numerous industries. She has over 9 years of specialised expertise in synthetic intelligence and machine studying, in addition to a ardour for translating complicated technical ideas into sensible enterprise functions.
 Nuno Castro is a Sr. Utilized Science Supervisor on the AWS Generative AI Innovation Middle. He leads Generative AI buyer engagements, serving to AWS clients discover probably the most impactful use case from ideation, prototype by to manufacturing. He’s has 19 years expertise within the subject in industries corresponding to finance, manufacturing, and journey, main ML groups for 11 years.
Nuno Castro is a Sr. Utilized Science Supervisor on the AWS Generative AI Innovation Middle. He leads Generative AI buyer engagements, serving to AWS clients discover probably the most impactful use case from ideation, prototype by to manufacturing. He’s has 19 years expertise within the subject in industries corresponding to finance, manufacturing, and journey, main ML groups for 11 years.
 Christelle Xu is a Senior Generative AI Strategist who leads mannequin customization and optimization technique throughout EMEA throughout the AWS Generative AI Innovation Middle, working with clients to ship scalable Generative AI options, specializing in continued pre-training, fine-tuning, reinforcement studying, and coaching and inference optimization. She holds a Grasp’s diploma in Statistics from the College of Geneva and a Bachelor’s diploma from Brigham Younger College.
Christelle Xu is a Senior Generative AI Strategist who leads mannequin customization and optimization technique throughout EMEA throughout the AWS Generative AI Innovation Middle, working with clients to ship scalable Generative AI options, specializing in continued pre-training, fine-tuning, reinforcement studying, and coaching and inference optimization. She holds a Grasp’s diploma in Statistics from the College of Geneva and a Bachelor’s diploma from Brigham Younger College.
 Manuel Gomez is a Options Architect at AWS supporting generative AI startups throughout the UK and Eire. He works with mannequin producers, fine-tuning platforms, and agentic AI functions to design safe and scalable architectures. Earlier than AWS, he labored in startups and consulting, and he has a background in industrial applied sciences and IoT. He’s significantly occupied with how multi-modal AI could be utilized to actual trade issues.
Manuel Gomez is a Options Architect at AWS supporting generative AI startups throughout the UK and Eire. He works with mannequin producers, fine-tuning platforms, and agentic AI functions to design safe and scalable architectures. Earlier than AWS, he labored in startups and consulting, and he has a background in industrial applied sciences and IoT. He’s significantly occupied with how multi-modal AI could be utilized to actual trade issues.
 Bryan Woolgar-O’Neil is the co-founder & CTO at Harmonic Safety. With over 20 years of software program improvement expertise, the final 10 have been devoted to constructing the Risk Intelligence firm Digital Shadows, which was acquired by Reliaquest in 2022. His experience lies in creating merchandise primarily based on cutting-edge software program, specializing in making sense of enormous volumes of knowledge.
Bryan Woolgar-O’Neil is the co-founder & CTO at Harmonic Safety. With over 20 years of software program improvement expertise, the final 10 have been devoted to constructing the Risk Intelligence firm Digital Shadows, which was acquired by Reliaquest in 2022. His experience lies in creating merchandise primarily based on cutting-edge software program, specializing in making sense of enormous volumes of knowledge.
 Jamie Cockrill is the Director of Machine Studying at Harmonic Safety, the place he leads a crew targeted on constructing, coaching, and refining Harmonic’s Small Language Fashions.
Jamie Cockrill is the Director of Machine Studying at Harmonic Safety, the place he leads a crew targeted on constructing, coaching, and refining Harmonic’s Small Language Fashions.
 Adrian Cunliffe is a Senior Machine Studying Engineer at Harmonic Safety, the place he focuses on scaling Harmonic’s Machine Studying engine that powers Harmonic’s proprietary fashions.
Adrian Cunliffe is a Senior Machine Studying Engineer at Harmonic Safety, the place he focuses on scaling Harmonic’s Machine Studying engine that powers Harmonic’s proprietary fashions.

{kind=link}
{kind=link}