


Generative AI fashions proceed to increase in scale and functionality, rising the demand for sooner and extra environment friendly inference. Purposes want low latency and constant efficiency with out compromising output high quality. Amazon SageMaker AI introduces new enhancements to its inference optimization toolkit that convey EAGLE based mostly adaptive speculative decoding to extra mannequin architectures. These updates make it simpler to speed up decoding, optimize efficiency utilizing your personal information and deploy higher-throughput fashions utilizing the acquainted SageMaker AI workflow.
EAGLE, brief for Extrapolation Algorithm for Higher Language-model Effectivity, is a method that quickens massive language mannequin decoding by predicting future tokens instantly from the hidden layers of the mannequin. Whenever you information optimization utilizing your personal utility information, the enhancements align with the precise patterns and domains you serve, producing sooner inference that displays your actual workloads quite than generic benchmarks. Primarily based on the mannequin structure, SageMaker AI trains EAGLE 3 or EAGLE 2 heads.
Observe that this coaching and optimization is just not restricted to only a one time optimization operation. You can begin by using the datasets offered by SageMaker for the preliminary coaching, however as you proceed to assemble and gather your personal information you can too fine-tune utilizing your personal curated dataset for extremely adaptive, workload-specific efficiency. An instance can be using a device equivalent to Information Seize to curate your personal dataset over time from real-time requests which are hitting your hosted mannequin. This may be an iterative characteristic with a number of cycles of coaching to constantly enhance efficiency.
On this publish we’ll clarify find out how to use EAGLE 2 and EAGLE 3 speculative decoding in Amazon SageMaker AI.
Resolution overview
SageMaker AI now gives native help for each EAGLE 2 and EAGLE 3 speculative decoding, enabling every mannequin structure to use the method that greatest matches its inside design. To your base LLM, you may make the most of both SageMaker JumpStart fashions or convey your personal mannequin artifacts to S3 from different mannequin hubs, equivalent to HuggingFace.
Speculative decoding is a broadly employed method for accelerating inference in LLMs with out compromising high quality. This methodology includes utilizing a smaller draft mannequin to generate preliminary tokens, that are then verified by the goal LLM. The extent of the speedup achieved by speculative decoding is closely depending on the collection of the draft mannequin.
The sequential nature of recent LLMs makes them costly and gradual, and speculative decoding has confirmed to be an efficient resolution to this downside. Strategies like EAGLE enhance upon this by reusing options from the goal mannequin, main to raised outcomes. Nonetheless, a present development within the LLM neighborhood is to extend coaching information to spice up mannequin intelligence with out including inference prices. Sadly, this method has restricted advantages for EAGLE. This limitation is because of EAGLE’s constraints on characteristic prediction. To deal with this, EAGLE-3 is launched, which predicts tokens instantly as an alternative of options and combines options from a number of layers utilizing a method referred to as training-time testing. These modifications considerably enhance efficiency and permit the mannequin to completely profit from elevated coaching information.
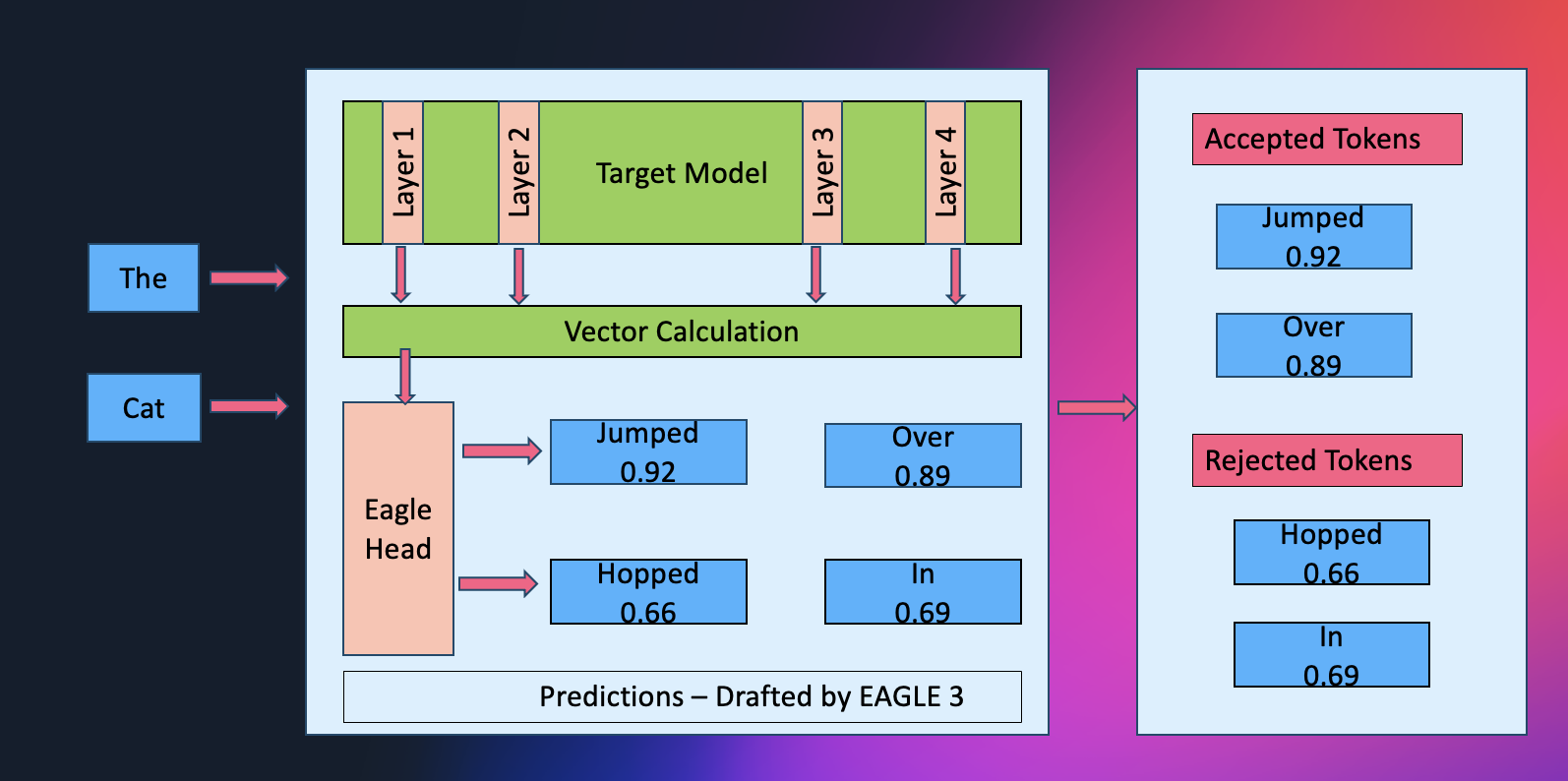
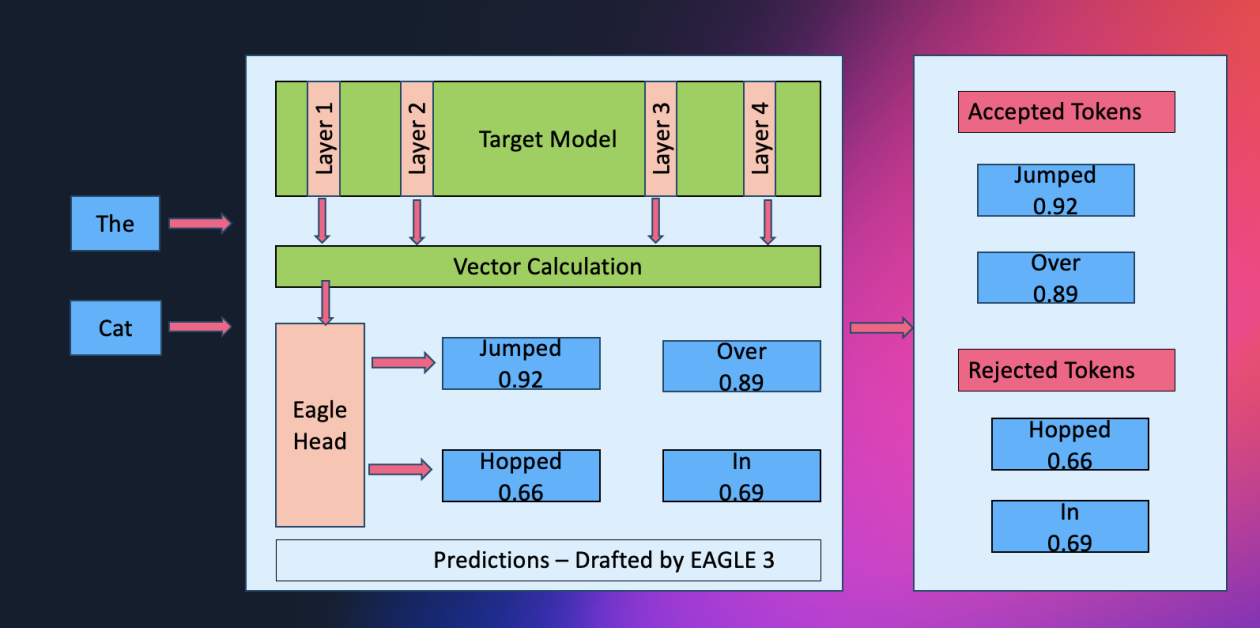
To provide clients most flexibility, SageMaker helps each main workflow for constructing or refining an EAGLE mannequin. You possibly can prepare an EAGLE mannequin totally from scratch utilizing the SageMaker curated open dataset, or prepare it from scratch with your personal information to align speculative conduct along with your visitors patterns. You too can begin from an current EAGLE base mannequin: both retraining it with the default open dataset for a quick, high-quality baseline, or fine-tuning that base mannequin with your personal dataset for extremely adaptive, workload-specific efficiency. As well as, SageMaker JumpStart offers absolutely pre-trained EAGLE fashions so you may start optimizing instantly with out getting ready any artifacts.
The answer spans six supported architectures and features a pre-trained, pre-cached EAGLE base to speed up experimentation. SageMaker AI additionally helps broadly used coaching information codecs, particularly ShareGPT and OpenAI chat and completions, so current corpora can be utilized instantly. Prospects may present the info captured utilizing their very own SageMaker AI endpoints offered the info is within the above specified codecs. Whether or not you depend on the SageMaker open dataset or convey your personal, optimization jobs sometimes ship round a 2.5x thoughput over commonplace decoding whereas adapting naturally to the nuances of your particular use case.
All optimization jobs routinely produce benchmark outcomes providing you with clear visibility into latency and throughput enhancements. You possibly can run all the workflow utilizing SageMaker Studio or the AWS CLI and also you deploy the optimized mannequin by the identical interface you already use for traditional SageMaker AI inference.
SageMaker AI at the moment helps LlamaForCausalLM, Qwen3ForCausalLM, Qwen3MoeForCausalLM, Qwen2ForCausalLM and GptOssForCausalLM with EAGLE 3, and Qwen3NextForCausalLM with EAGLE 2. You should use one optimization pipeline throughout a mixture of architectures whereas nonetheless gaining the advantages of model-specific conduct.
How EAGLE works contained in the mannequin
Speculative decoding could be considered like a seasoned chief scientist guiding the circulation of discovery. In conventional setups, a smaller “assistant” mannequin runs forward, rapidly sketching out a number of attainable token continuations, whereas the bigger mannequin examines and corrects these recommendations. This pairing reduces the variety of gradual, sequential steps by verifying a number of drafts directly.
EAGLE streamlines this course of even additional. As an alternative of relying on an exterior assistant, the mannequin successfully turns into its personal lab accomplice: it inspects its inside hidden-layer representations to anticipate a number of future tokens in parallel. As a result of these predictions come up from the mannequin’s personal realized construction, they are typically extra correct upfront, resulting in deeper speculative steps, fewer rejections, and smoother throughput.
By eradicating the overhead of coordinating a secondary mannequin and enabling extremely parallel verification, this method alleviates reminiscence bandwidth bottlenecks and delivers notable speedups, usually round 2.5x, whereas sustaining the identical output high quality the baseline mannequin would produce.
Working optimization jobs from the SDK or CLI
You possibly can interface with the Optimization Toolkit utilizing the AWS Python Boto3 SDK, Studio UI. On this part we discover using the AWS CLI, the identical API calls will map over to the Boto3 SDK. Right here, the core API requires endpoint creation stay the identical: create_model, create_endpoint_config, and create_endpoint. The workflow we showcase right here begins with mannequin registration utilizing the create_model API name. With the create_model API name you may specify your serving container and stack. You don’t have to create a SageMaker mannequin object and might specify the mannequin information within the Optimization Job API name as properly.
For the EAGLE heads optimization, we specify the mannequin information by pointing in the direction of to the Mannequin Information Supply parameter, for the time being specification of the HuggingFace Hub Mannequin ID is just not supported. Pull your artifacts and add them to an S3 bucket and specify it within the Mannequin Information Supply parameter. By default checks are performed to confirm that the suitable recordsdata are uploaded so you have got the usual mannequin information anticipated for LLMs:
Let’s take a look at a couple of paths right here:
- Utilizing your personal mannequin information with your personal EAGLE curated dataset
- Bringing your personal educated EAGLE that you could be need to prepare extra
- Carry your personal mannequin information and use SageMaker AI built-in datasets
1. Utilizing your personal mannequin information with your personal EAGLE curated dataset
We will begin an optimization job with the create-optimization-job API name. Right here is an instance with a Qwen3 32B mannequin. Observe that you would be able to convey your personal information or additionally use the built-in SageMaker offered datasets. First we are able to create a SageMaker Mannequin object that specifies the S3 bucket with our mannequin artifacts:
Our optimization name then pulls down these mannequin artifacts if you specify the SageMaker Mannequin and a TrainingDataSource parameter as the next:
2. Bringing your personal educated EAGLE that you could be need to prepare extra
To your personal educated EAGLE you may specify one other parameter within the create_model API name the place you level in the direction of your EAGLE artifacts, optionally you can too specify a SageMaker JumpStart Mannequin ID to drag down the packaged mannequin artifacts.
Equally the optimization API then inherits this mannequin object with the required mannequin information:
3. Carry your personal mannequin information and use SageMaker built-in datasets
Optionally, we are able to make the most of the SageMaker offered datasets:
After completion, SageMaker AI shops analysis metrics in S3 and data the optimization lineage in Studio. You possibly can deploy the optimized mannequin to an inference endpoint with both the create_endpoint API call or within the UI.
Benchmarks
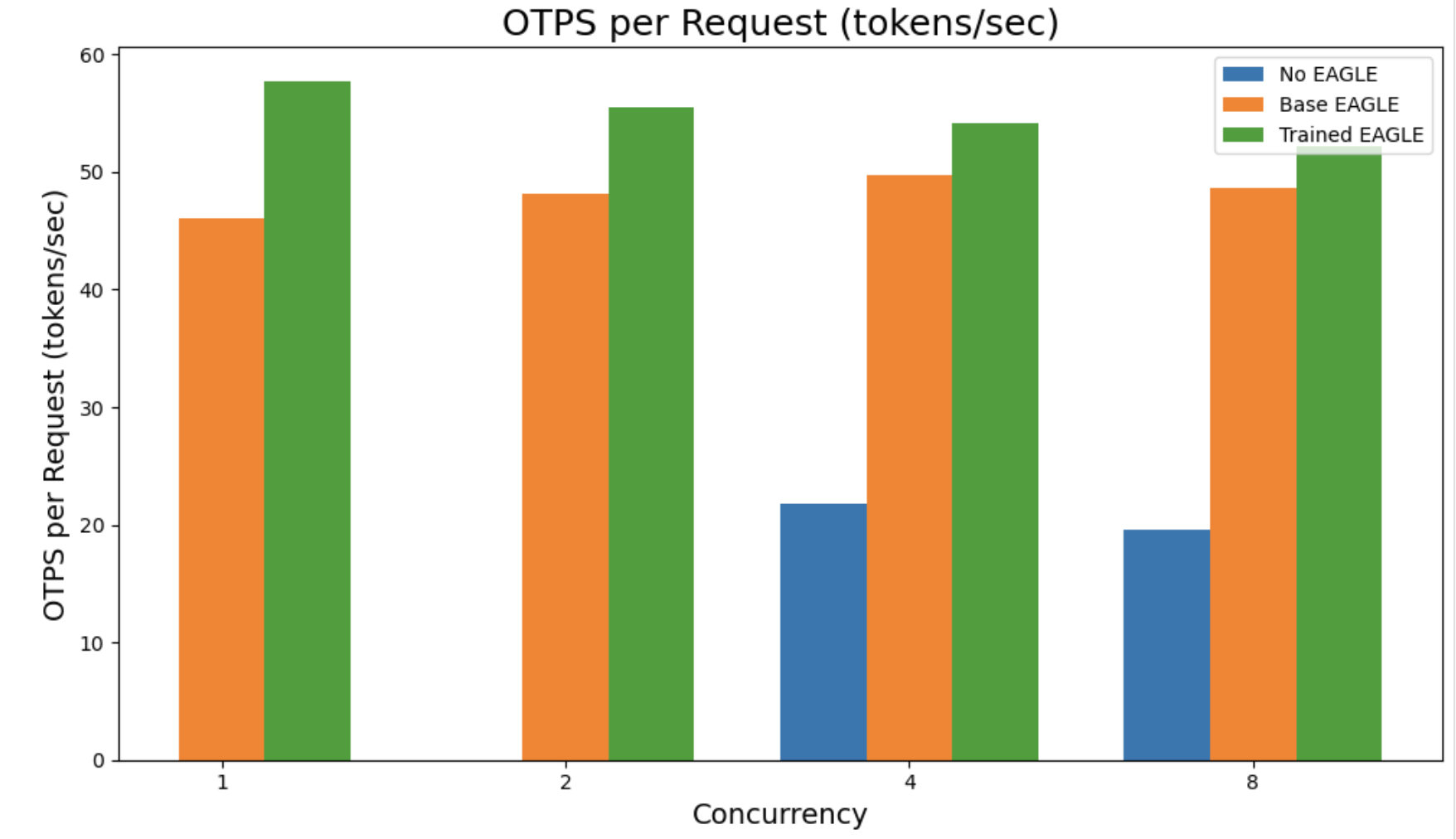
To benchmark this additional we in contrast three states:
- No EAGLE: Base mannequin with out EAGLE as a baseline
- Base EAGLE: EAGLE coaching utilizing built-in datasets offered by SageMaker AI
- Educated EAGLE: EAGLE coaching utilizing built-in datasets offered by SageMaker AI and retraining with personal customized dataset
The numbers displayed beneath are for qwen3-32B throughout metrics equivalent to Time to First Token (TTFT) and total throughput.
| Configuration | Concurrency | TTFT (ms) | TPOT (ms) | ITL (ms) | Request Throughput | Output Throughput (tokens/sec) | OTPS per request (tokens/sec) |
| No EAGLE | 4 | 168.04 | 45.95 | 45.95 | 0.04 | 86.76 | 21.76 |
| No EAGLE | 8 | 219.53 | 51.02 | 51.01 | 0.08 | 156.46 | 19.6 |
| Base EAGLE | 1 | 89.76 | 21.71 | 53.01 | 0.02 | 45.87 | 46.07 |
| Base EAGLE | 2 | 132.15 | 20.78 | 50.75 | 0.05 | 95.73 | 48.13 |
| Base EAGLE | 4 | 133.06 | 20.11 | 49.06 | 0.1 | 196.67 | 49.73 |
| Base EAGLE | 8 | 154.44 | 20.58 | 50.15 | 0.19 | 381.86 | 48.59 |
| Educated EAGLE | 1 | 83.6 | 17.32 | 46.37 | 0.03 | 57.63 | 57.73 |
| Educated EAGLE | 2 | 129.07 | 18 | 48.38 | 0.05 | 110.86 | 55.55 |
| Educated EAGLE | 4 | 133.11 | 18.46 | 49.43 | 0.1 | 214.27 | 54.16 |
| Educated EAGLE | 8 | 151.19 | 19.15 | 51.5 | 0.2 | 412.25 | 52.22 |
Pricing concerns
Optimization jobs run on SageMaker AI coaching situations, you may be billed relying on the occasion sort and job length. Deployment of the ensuing optimized mannequin makes use of commonplace SageMaker AI Inference pricing.
Conclusion
EAGLE based mostly adaptive speculative decoding provides you a sooner and simpler path to enhance generative AI inference efficiency on Amazon SageMaker AI. By working contained in the mannequin quite than counting on a separate draft community, EAGLE accelerates decoding, will increase throughput and maintains technology high quality. Whenever you optimize utilizing your personal dataset, the enhancements replicate the distinctive conduct of your functions, leading to higher end-to-end efficiency. With built-in dataset help, benchmark automation and streamlined deployment, the inference optimization toolkit helps you ship low-latency generative functions at scale.
In regards to the authors
 Kareem Syed-Mohammed is a Product Supervisor at AWS. He’s focuses on enabling generative AI mannequin improvement and governance on SageMaker HyperPod. Previous to this, at Amazon QuickSight, he led embedded analytics, and developer expertise. Along with QuickSight, he has been with AWS Market and Amazon retail as a Product Supervisor. Kareem began his profession as a developer for name middle applied sciences, Native Knowledgeable and Advertisements for Expedia, and administration marketing consultant at McKinsey.
Kareem Syed-Mohammed is a Product Supervisor at AWS. He’s focuses on enabling generative AI mannequin improvement and governance on SageMaker HyperPod. Previous to this, at Amazon QuickSight, he led embedded analytics, and developer expertise. Along with QuickSight, he has been with AWS Market and Amazon retail as a Product Supervisor. Kareem began his profession as a developer for name middle applied sciences, Native Knowledgeable and Advertisements for Expedia, and administration marketing consultant at McKinsey.
 Xu Deng is a Software program Engineer Supervisor with the SageMaker workforce. He focuses on serving to clients construct and optimize their AI/ML inference expertise on Amazon SageMaker. In his spare time, he loves touring and snowboarding.
Xu Deng is a Software program Engineer Supervisor with the SageMaker workforce. He focuses on serving to clients construct and optimize their AI/ML inference expertise on Amazon SageMaker. In his spare time, he loves touring and snowboarding.
 Ram Vegiraju is an ML Architect with the Amazon SageMaker Service workforce. He focuses on serving to clients construct and optimize their AI/ML options on SageMaker. In his spare time, he loves touring and writing.
Ram Vegiraju is an ML Architect with the Amazon SageMaker Service workforce. He focuses on serving to clients construct and optimize their AI/ML options on SageMaker. In his spare time, he loves touring and writing.
 Vinay Arora is a Specialist Resolution Architect for Generative AI at AWS, the place he collaborates with clients in designing cutting-edge AI options leveraging AWS applied sciences. Previous to AWS, Vinay has over twenty years of expertise in finance—together with roles at banks and hedge funds—he has constructed threat fashions, buying and selling programs, and market information platforms. Vinay holds a grasp’s diploma in pc science and enterprise administration.
Vinay Arora is a Specialist Resolution Architect for Generative AI at AWS, the place he collaborates with clients in designing cutting-edge AI options leveraging AWS applied sciences. Previous to AWS, Vinay has over twenty years of expertise in finance—together with roles at banks and hedge funds—he has constructed threat fashions, buying and selling programs, and market information platforms. Vinay holds a grasp’s diploma in pc science and enterprise administration.
 Siddharth Shah is a Principal Engineer at AWS SageMaker, specializing in large-scale mannequin internet hosting and optimization for Massive Language Fashions. He beforehand labored on the launch of Amazon Textract, efficiency enhancements within the model-hosting platform, and expedited retrieval programs for Amazon S3 Glacier. Outdoors of labor, he enjoys climbing, video video games, and pastime robotics.
Siddharth Shah is a Principal Engineer at AWS SageMaker, specializing in large-scale mannequin internet hosting and optimization for Massive Language Fashions. He beforehand labored on the launch of Amazon Textract, efficiency enhancements within the model-hosting platform, and expedited retrieval programs for Amazon S3 Glacier. Outdoors of labor, he enjoys climbing, video video games, and pastime robotics.
 Andy Peng is a builder with curiosity, motivated by scientific analysis and product innovation. He helped construct key initiatives that span AWS SageMaker and Bedrock, Amazon S3, AWS App Runner, AWS Fargate, Alexa Well being & Wellness, and AWS Funds, from 0-1 incubation to 10x scaling. Open-source fanatic.
Andy Peng is a builder with curiosity, motivated by scientific analysis and product innovation. He helped construct key initiatives that span AWS SageMaker and Bedrock, Amazon S3, AWS App Runner, AWS Fargate, Alexa Well being & Wellness, and AWS Funds, from 0-1 incubation to 10x scaling. Open-source fanatic.
 Johna Liu is a Software program Improvement Engineer on the Amazon SageMaker workforce, the place she builds and explores AI/LLM-powered instruments that improve effectivity and allow new capabilities. Outdoors of labor, she enjoys tennis, basketball and baseball.
Johna Liu is a Software program Improvement Engineer on the Amazon SageMaker workforce, the place she builds and explores AI/LLM-powered instruments that improve effectivity and allow new capabilities. Outdoors of labor, she enjoys tennis, basketball and baseball.
 Anisha Kolla is a Software program Improvement Engineer with SageMaker Inference workforce with over 10+ years of trade expertise. She is obsessed with constructing scalable and environment friendly options that empower clients to deploy and handle machine studying functions seamlessly. Anisha thrives on tackling advanced technical challenges and contributing to progressive AI capabilities. Outdoors of labor, she enjoys exploring new Seattle eating places, touring, and spending time with household and pals.
Anisha Kolla is a Software program Improvement Engineer with SageMaker Inference workforce with over 10+ years of trade expertise. She is obsessed with constructing scalable and environment friendly options that empower clients to deploy and handle machine studying functions seamlessly. Anisha thrives on tackling advanced technical challenges and contributing to progressive AI capabilities. Outdoors of labor, she enjoys exploring new Seattle eating places, touring, and spending time with household and pals.

{kind=link}