


If neural networks are making selections in every single place from code editors to security techniques, how will you really see the particular circuitry inside that drives every motion? OpenAI introduces a brand new mechanism of interpretability research study It trains the language mannequin to make use of sparse inside wiring, so you need to use small, express circuits to elucidate the mannequin’s habits.
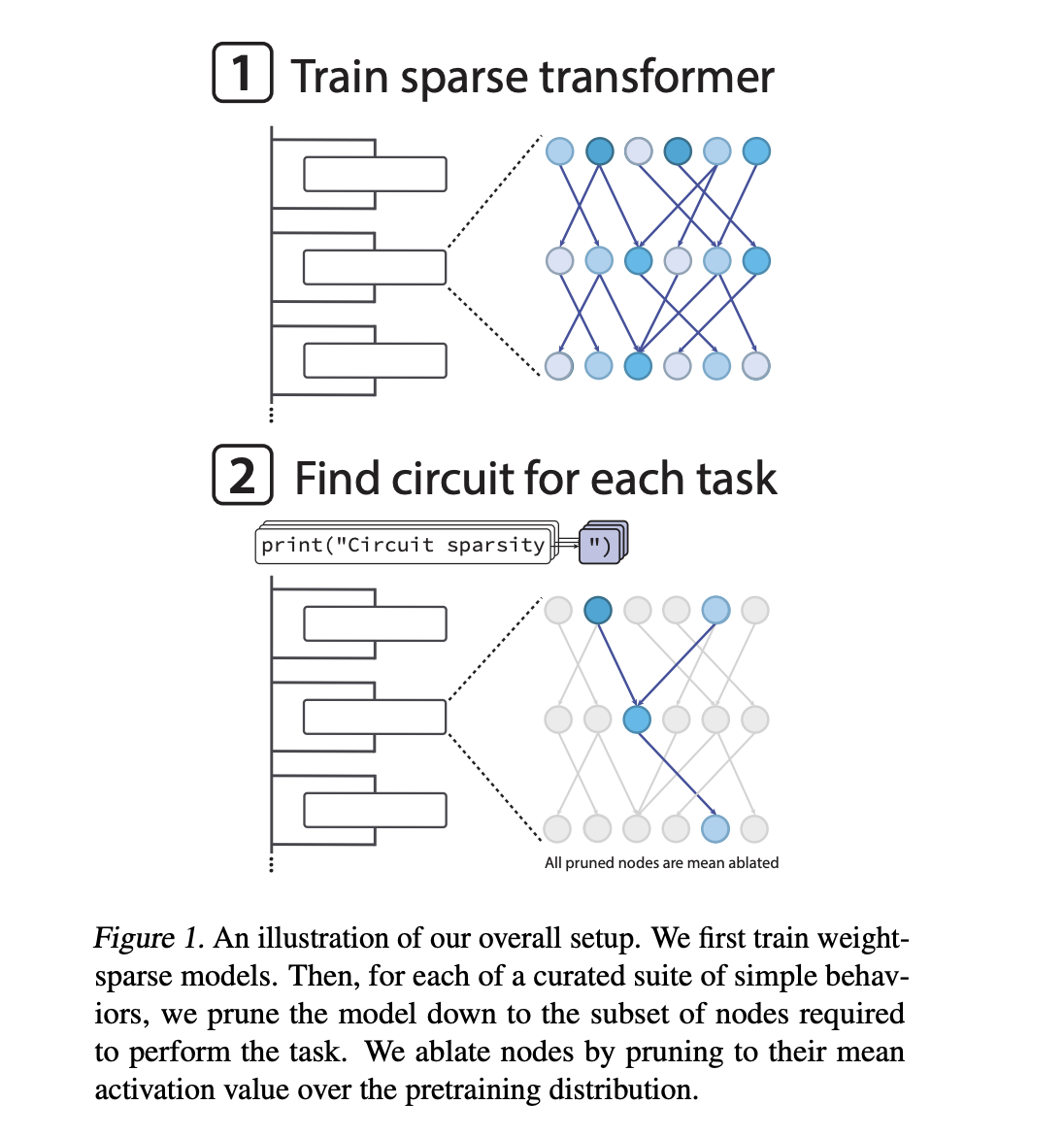
Practice the transformer weight to be sparse
Most Transformer language fashions are dense. Every neuron reads from and writes to many remaining channels, and the options are sometimes superimposed. This makes circuit-level evaluation tough. Earlier OpenAI analysis tried to make use of sparse autoencoders to study sparse characteristic bases on prime of dense fashions. The brand new analysis work as a substitute modified the fundamental mannequin in order that the burden of the transformer itself is sparse.
The OpenAI crew makes use of an structure just like GPT 2 to coach decoder-only transformers. After every optimizer step utilizing the AdamW optimizer, we apply a hard and fast sparsity stage to all weight matrices and biases, together with token embeddings. Solely the most important entry in every matrix is saved. The remainder are set to zero. All through coaching, the annealing schedule steadily reduces the proportion of nonzero parameters till the mannequin reaches the goal sparsity.
On the most excessive settings, roughly 1/a thousandth of the weights are non-zero. Activation can be considerably sparse. For typical node areas, a couple of quarter of activations are non-zero. Due to this fact, even when the mannequin width is giant, the efficient connectivity graph will likely be very skinny. This promotes disentangled options that map cleanly to the remaining channels utilized by the circuit.
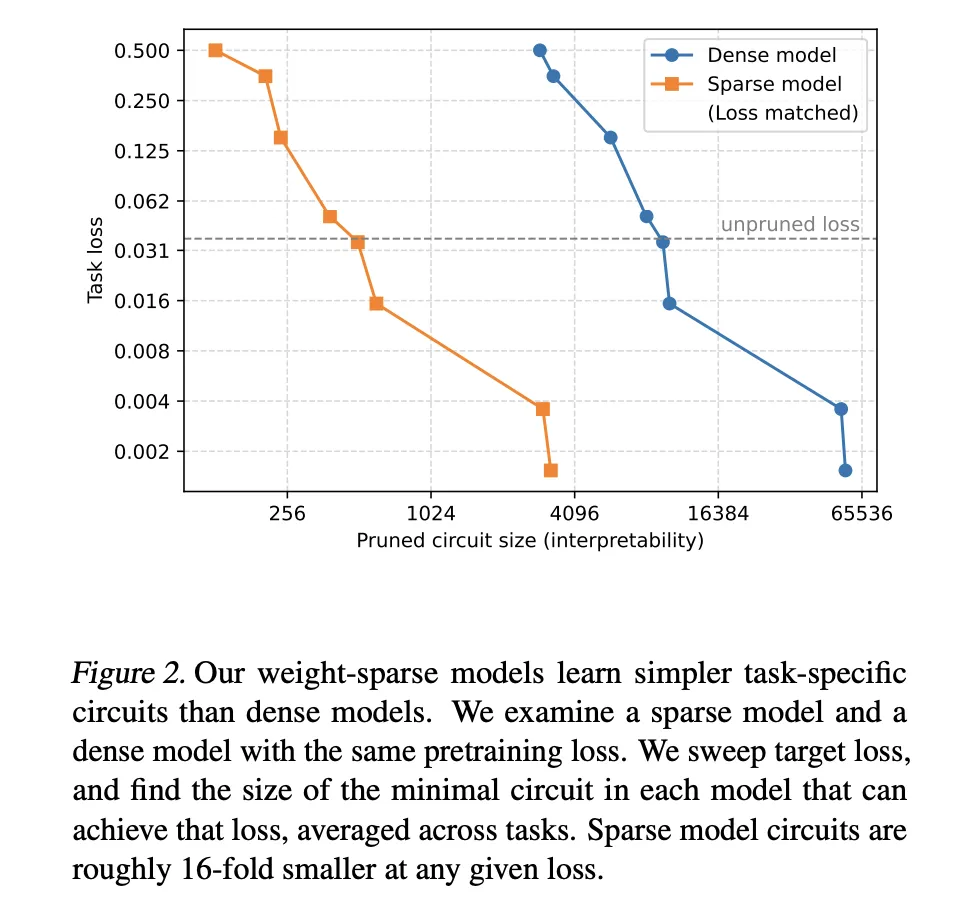
Measuring interpretability with task-specific pruning
To quantify whether or not these fashions are simple to know, the OpenAI crew does not rely solely on qualitative examples. The analysis crew defines a set of easy algorithmic duties primarily based on subsequent token prediction in Python. One instance, single_double_quote, requires the mannequin to shut a Python string with a proper quote. One other instance, set_or_string , requires the mannequin to decide on between .add and += primarily based on whether or not the variable was initialized as a set or a string.
For every job, we discover the smallest subnetwork, referred to as a circuit, that may carry out the duty as much as a hard and fast loss threshold. Pruning is completed on a node-by-node foundation. A node is an MLP neuron in a selected layer, an consideration head, or a residual stream channel in a selected layer. When a node is pruned, its activations are changed by the imply of the pre-training distribution. That is significant ablation.
The search makes use of a steady masks parameter for every node and a Heaviside-style gate optimized with a straight-through estimator, comparable to a surrogate gradient. Circuit complexity is measured because the variety of energetic edges between retained nodes. The principle measure of interpretability is the geometric imply of the variety of edges throughout all duties.
Sparse transformer circuit instance
For the single_double_quote job, the sparse mannequin produces a compact and totally interpretable circuit. Within the preliminary MLP layer, one neuron acts as a quote detector that’s energetic on each single and double quotes. The second neuron acts as a quotation kind classifier that distinguishes between the 2 quotation varieties. The eye head then makes use of these alerts to return to the beginning quote place and replica its kind to the ending place.
In circuit graph phrases, this mechanism makes use of 5 residual channels, two MLP neurons in layer 0, and one consideration head in subsequent layers with one related question key channel and one worth channel. Even when the remainder of the mannequin is ablated, this subgraph will nonetheless resolve the duty. If a few of these edges are eliminated, the mannequin will fail on the duty. Due to this fact, this circuit is adequate and needed within the operational sense outlined within the paper.

For extra advanced habits, comparable to kind monitoring for a variable named present inside a operate physique, the circuit that’s recovered is giant and solely partially understood. The researchers present an instance the place one consideration operation writes a variable identify to the token set() at definition time, and one other consideration operation copies the kind data from that token and makes use of present later. This nonetheless ends in a comparatively small circuit graph.
Necessary factors
- Low weight transformer by design: OpenAI trains a GPT-2 type decoder-only transformer so that the majority weights are zero and about 1 in 1000 weights are non-zero. This enforces sparsity throughout all weights and biases, together with token embeddings, leading to a skinny connectivity graph that’s structurally simpler to investigate.
- Interpretability is measured because the minimal circuit measurement: On this examine, we outline a easy Python next-token job benchmark, and for every job we use node-level pruning with imply removing and straight-through estimator-style masks optimization to search out the smallest subnetwork that reaches a hard and fast loss with respect to energetic edges between nodes.
- Utterly reverse engineered concrete circuit now obtainable: For duties comparable to predicting matching quote characters, the sparse mannequin produces a compact circuit with a number of residual channels, two essential MLP neurons, and one consideration head. Authors can totally reverse engineer these to confirm that they’re adequate and needed for operation.
- Sparsity permits for a lot smaller circuits with mounted capacitance: At matched pre-training loss ranges, the burden sparse mannequin requires a circuit that’s roughly 16 instances smaller than the circuit recovered from the dense baseline. This defines a functionality interpretability frontier the place growing sparsity will increase interpretability whereas barely reducing uncooked functionality.
OpenAI’s work on weight sparse transformers is a sensible step towards making mechanistic interpretability a actuality. By instantly making use of sparsity to the bottom mannequin, this paper transforms summary discussions of circuits into concrete graphs with measurable edge counts, express necessity and sufficiency checks, and reproducible benchmarks on Python’s Subsequent Token job. Though the mannequin is small and inefficient, this system is related for future security audits and workflow debugging. This examine treats interpretability as a first-class design constraint quite than an after-the-fact analysis.
Please examine paper, GitHub repository and technical details. Please be at liberty to test it out GitHub page for tutorials, code, and notebooks. Additionally, be at liberty to observe us Twitter Remember to hitch us 100,000+ ML subreddits and subscribe our newsletter. dangle on! Are you on telegram? You can now also participate by telegram.

Michal Sutter is a knowledge science skilled with a grasp’s diploma in knowledge science from the College of Padova. With a powerful basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at remodeling advanced datasets into actionable insights.

{kind=link}