


How can small fashions discover ways to resolve duties which can be at present failing with out counting on memorized imitation or right rollouts? A staff of researchers from Google Cloud AI Analysis and UCLA has launched a coaching framework.Supervised reinforcement learning (SRL)This enables the 7B scale mannequin to really study from very troublesome arithmetic and agent trajectories that can not be realized with common supervised fine-tuning or outcome-based reinforcement studying RL.
Small open supply fashions similar to Qwen2.5 7B Instruct fail on essentially the most troublesome issues in s1K 1.1 even with good instructor tracing. Once we apply supervised fine-tuning to the total DeepSeek R1 type answer, the mannequin imitates token by token, the sequences are lengthy, the information is just one,000 gadgets, and the ultimate rating is decrease than the bottom mannequin.
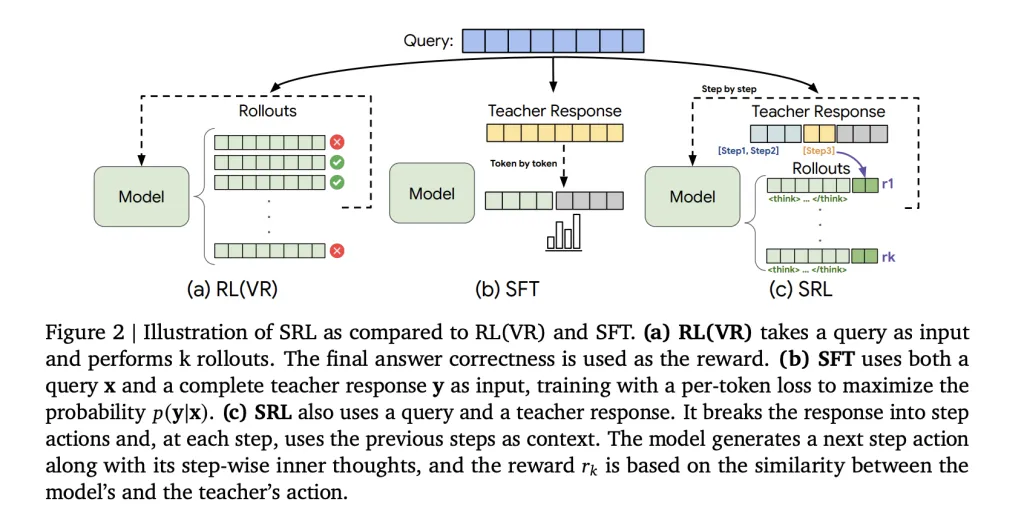
The core concept of “supervised reinforcement studying” SRL
“Supervised Reinforcement Studying” (SRL) maintains RL-style optimization, however injects supervision into the reward channel as an alternative of loss. Every skilled’s trajectory in s1K 1.1 is parsed right into a sequence of actions. For each prefix in that sequence, the researchers create a brand new coaching pattern. The mannequin first generates a non-public inference span wrapped as follows: <suppose> … </suppose>It then outputs the motion of that step and solely this motion is in contrast with the instructor’s motion utilizing a sequence similarity metric primarily based on difflib. Even when the ultimate reply is mistaken, the rewards are wealthy as a result of each step has a rating. The remainder of the textual content, the inference half, is unconstrained, so the mannequin can search its personal chain with out being compelled to repeat the instructor token.
math outcomes
All fashions are initialized from Qwen2.5 7B directions and all educated on the identical s1K 1.1 set in DeepSeek R1 format, so the comparability is clear. The precise numbers in Desk 1 are:
- Base Qwen2.5 7B directions, AMC23 Grasping 50.0, AIME24 Grasping 13.3, AIME25 Grasping 6.7.
- SRL, AMC23 Grasping 50.0, AIME24 Grasping 16.7, AIME25 Grasping 13.3.
- SRL is adopted by RLVR, AMC23 Grasping 57.5, AIME24 Grasping 20.0, AIME25 Grasping 10.0.
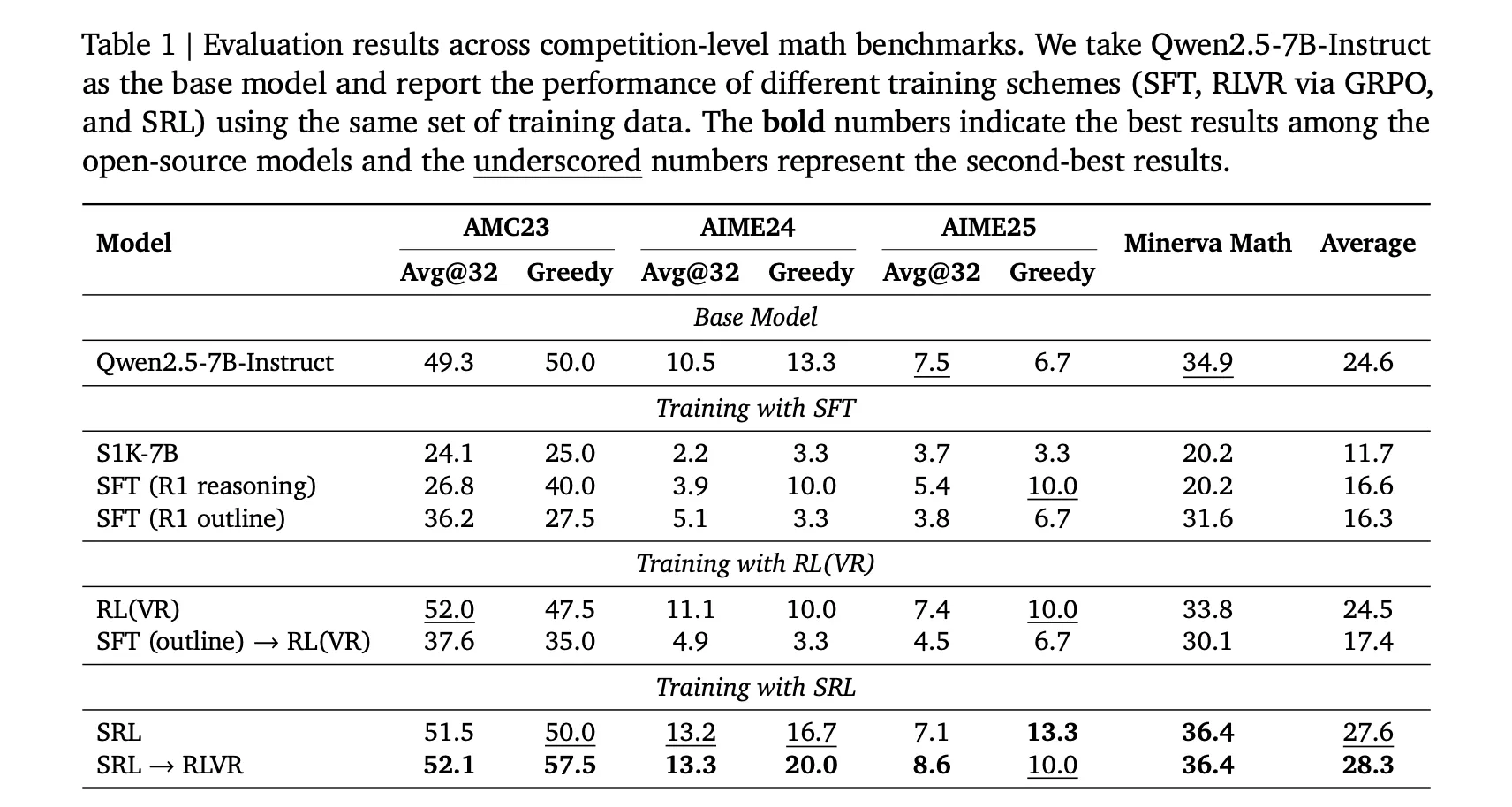
It is a key enchancment, as SRL alone already eliminates SFT degradation and improves AIME24 and AIME25. When RLVR is carried out after SRL, the system reaches the best open supply rating within the examine. The analysis staff states that the very best pipeline is just not SRL alone, however SRL after which RLVR.
Software program engineering achievements
The analysis staff additionally applies SRL to Qwen2.5 Coder 7B directions utilizing 5,000 verified agent trajectories generated by claude 3 7 sonnet. All trajectories are decomposed into step-wise cases, yielding a complete of 134,000 step gadgets. Analysis is finished utilizing SWE Bench Verified. The bottom mannequin will get 5.8 p.c in Oracle file modifying mode and three.2 p.c end-to-end. SWE Fitness center 7B positive aspects 8.4 p.c and 4.2 p.c. SRL positive aspects 14.8 p.c and eight.6 p.c, which is about twice as a lot as the bottom mannequin and clearly greater than the SFT baseline.
Essential factors
- SRL reformulates laborious reasoning as step-by-step motion technology. The mannequin first generates an inner monologue after which outputs a single motion. Solely that motion is rewarded by sequence similarity, so the mannequin receives a sign even when the ultimate reply is mistaken.
- SRL runs on s1K 1.1 information in the identical DeepSeek R1 format as SFT and RLVR, however in contrast to SFT it doesn’t overfit lengthy demonstrations and in contrast to RLVR it doesn’t collapse within the absence of an accurate rollout.
- Relating to arithmetic, the precise order that yields the strongest ends in our analysis is to initialize the Qwen2.5 7B Instruct with SRL, then apply RLVR. This ends in greater inference benchmarks than both technique alone.
- The identical SRL recipe has been generalized to agent software program engineering utilizing 5,000 verified trajectories from claude 3 7 Sonnet 20250219, considerably outperforming each the SWE Bench Verified-based Qwen2.5 Coder 7B Instruct and the SFT-style SWE Fitness center 7B baseline.
- In comparison with different stepwise RL strategies that require further reward fashions, this SRL maintains GRPO-style objectives and solely makes use of actions from skilled trajectories and light-weight string similarity, making it straightforward to carry out on small laborious datasets.
“Supervised Reinforcement Studying” (SRL) is a sensible contribution from the analysis staff. We maintain the GRPO-style reinforcement studying setup, however substitute the delicate outcome-level reward with a supervised step-by-step reward computed instantly from the skilled trajectory. So the mannequin at all times receives informative alerts, even within the D language.troublesome A regime by which each RLVR and SFT stall. It can be crucial that the analysis staff demonstrates SRL in arithmetic and SWE bench validation utilizing the identical recipe, and that essentially the most highly effective configuration is SRL adopted by RLVR, relatively than one or the opposite alone. This makes SRL a practical path for studying duties which can be troublesome for open fashions. Total, SRL is a clear bridge between course of monitoring and RL that open mannequin groups can deploy rapidly.
Please verify paper. Please be happy to test it out GitHub page for tutorials, code, and notebooks. Please be happy to observe us too Twitter Remember to affix us 100,000+ ML subreddits and subscribe our newsletter. grasp on! Are you on telegram? You can now also participate by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a man-made intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information, which is technically sound and simply understood by a large viewers. The platform boasts over 2 million views per thirty days, demonstrating its reputation amongst viewers.

{kind=link}