


Massive-scale language fashions (LLMs) present a number of parameters that permit you to fine-tune their conduct and management how responses are generated. In case your mannequin doesn’t produce the specified output, the issue is usually in how these parameters are configured. On this tutorial, we are going to think about a few of the mostly used ones. max_completion_tokens, temperature, Top_p, presence_penaltyand frequency_penalty — and perceive how every impacts the mannequin’s output.
Putting in dependencies
pip set up openai pandas matplotlibLoading OpenAI API key
import os
from getpass import getpass
os.environ['OPENAI_API_KEY'] = getpass('Enter OpenAI API Key: ')Initializing the mannequin
from openai import OpenAI
mannequin="gpt-4.1"
shopper = OpenAI()Most variety of tokens
Most Tokens is the utmost variety of tokens that the mannequin can generate throughout execution. The mannequin will attempt to keep inside this restrict over all turns. If the required quantity is exceeded, the execution is stopped and marked as incomplete.
Small values (comparable to 16) restrict the mannequin to very brief solutions, whereas giant values (comparable to 80) enable it to supply extra detailed and full responses. Rising this parameter provides the mannequin extra room to refine, clarify, or format its output extra naturally.
immediate = "What's the hottest French cheese?"
for tokens in [16, 30, 80]:
print(f"n--- max_output_tokens = {tokens} ---")
response = shopper.chat.completions.create(
mannequin=mannequin,
messages=[
{"role": "developer", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
max_completion_tokens=tokens
)
print(response.decisions[0].message.content material)temperature
In large-scale language fashions (LLMs), temperature parameters management the variety and randomness of the output produced. Decrease temperature values make the mannequin extra deterministic and concentrate on the probably responses, making it supreme for duties that require precision and consistency. Alternatively, increased values introduce creativity and selection by permitting the mannequin to discover much less doubtless choices. Technically, temperature scales the anticipated token chance with the softmax operate. Rising the temperature flattens the distribution (making the output extra various), whereas lowering the temperature sharpens the distribution (making the output extra predictable).
This code tells LLM to provide 10 completely different solutions (n_choices = 10) to the identical query.What’s one fascinating place price visiting?? ” — throughout varied temperature values. This lets you observe how the variety of responses modifications with temperature. At decrease temperatures, comparable or repeated reactions usually tend to happen, and at increased temperatures, a broader and extra numerous location distribution is exhibited.
immediate = "What's one intriguing place price visiting? Give a single-word reply and assume globally."
temperatures = [0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.5]
n_choices = 10
outcomes = {}
for temp in temperatures:
response = shopper.chat.completions.create(
mannequin=mannequin,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
temperature=temp,
n=n_choices
)
# Gather all n responses in a listing
outcomes[temp] = [response.choices[i].message.content material.strip() for i in vary(n_choices)]
# Show outcomes
for temp, responses in outcomes.gadgets():
print(f"n--- temperature = {temp} ---")
print(responses)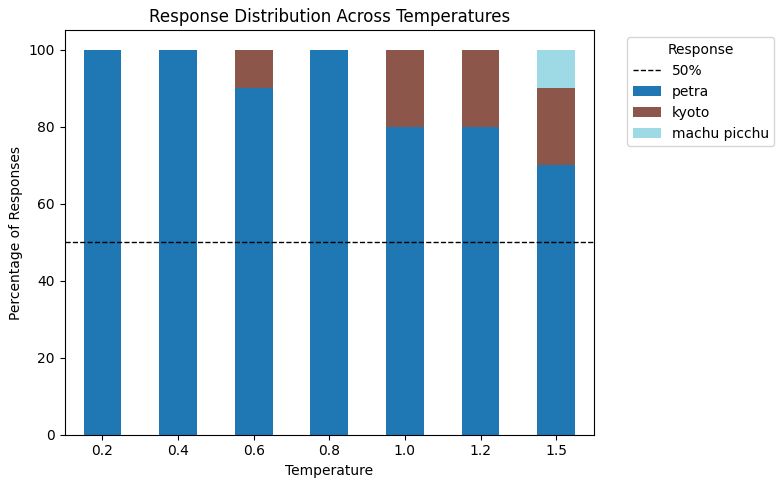
As you may see, because the temperature will increase to 0.6, the responses turn out to be extra numerous and not simply repeat a single reply, “Petra.” At increased temperatures of 1.5, the distribution shifts and we see the next response: Kyotoand machu picchu In the identical approach.
Prime P
Prime P (also referred to as nuclear sampling) is a parameter that controls the variety of tokens that the mannequin considers based mostly on a cumulative chance threshold. This permits the mannequin to concentrate on the probably tokens, usually bettering consistency and output high quality.
Within the following visualization, we first set the temperature worth after which apply the highest P = 0.5 (50%). Which means that solely the highest 50% of the chance mass is retained. Observe that when temperature = 0, the output is deterministic, so Prime P has no impact.
The era course of works as follows.
- Regulate the token chance by making use of temperature.
- We use Prime P to maintain solely probably the most possible tokens that make up 50% of the overall chance mass.
- Renormalize the remaining possibilities earlier than sampling.
Visualize how the chance distribution of tokens modifications throughout completely different temperature values for the query.
“What’s one fascinating place price visiting?”
immediate = "What's one intriguing place price visiting? Give a single-word reply and assume globally."
temperatures = [0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.5]
n_choices = 10
results_ = {}
for temp in temperatures:
response = shopper.chat.completions.create(
mannequin=mannequin,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
temperature=temp,
n=n_choices,
top_p=0.5
)
# Gather all n responses in a listing
results_[temp] = [response.choices[i].message.content material.strip() for i in vary(n_choices)]
# Show outcomes
for temp, responses in results_.gadgets():
print(f"n--- temperature = {temp} ---")
print(responses)
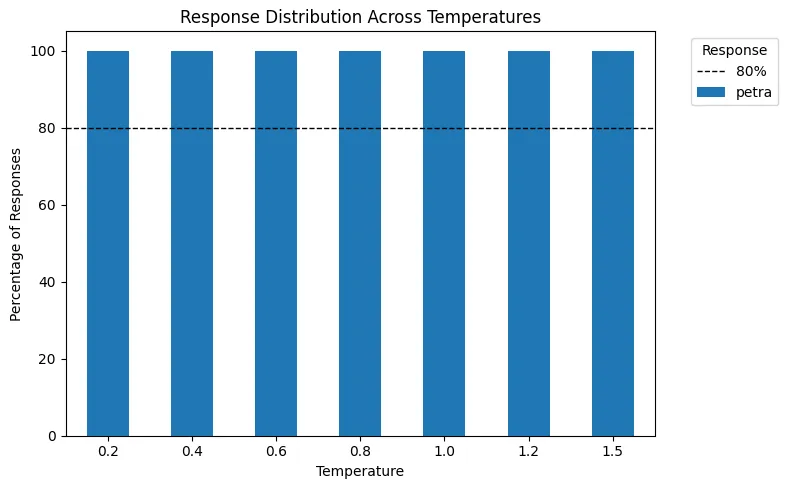
Since Petra constantly accounted for greater than 50% of the overall response chance, making use of Prime P = 0.5 excludes all different choices. In consequence, the mannequin will solely choose “Petra” as the ultimate output in any case.
frequency penalty
The frequency penalty controls how a lot the mannequin avoids repeating the identical phrases or phrases in its output.
Vary: -2 to 2
Default: 0
If the frequency penalty is excessive, the mannequin is penalized for utilizing phrases that it has used earlier than. This encourages selecting new and completely different phrases, making the textual content extra various and fewer repetitive.
Merely put, the upper the frequency penalty, the much less repetition and extra creativity.
Take a look at this utilizing prompts.
“Listing 10 potential titles for fantasy books. Enter simply the title, every title on a brand new line.”
immediate = "Listing 10 potential titles for a fantasy e-book. Give the titles solely and every title on a brand new line."
frequency_penalties = [-2.0, -1.0, 0.0, 0.5, 1.0, 1.5, 2.0]
outcomes = {}
for fp in frequency_penalties:
response = shopper.chat.completions.create(
mannequin=mannequin,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
frequency_penalty=fp,
temperature=0.2
)
textual content = response.decisions[0].message.content material
gadgets = [line.strip("- ").strip() for line in text.split("n") if line.strip()]
outcomes[fp] = gadgets
# Show outcomes
for fp, gadgets in outcomes.gadgets():
print(f"n--- frequency_penalty = {fp} ---")
print(gadgets)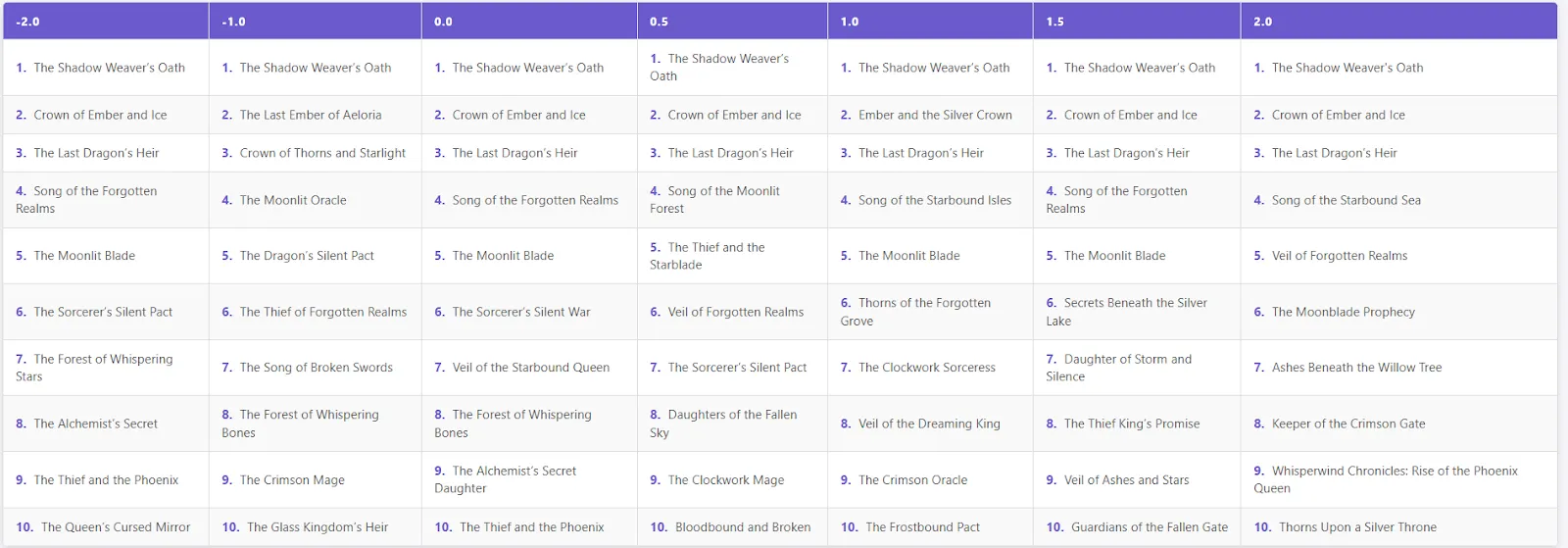
- Low frequency penalty (-2 to 0): Titles are inclined to repeat themselves, and acquainted patterns comparable to “Oath of the Shadowweaver,” “Crown of Ember and Ice,” and “Inheritor of the Final Dragon” usually seem.
- Medium penalty (0.5-1.5): Some repetitions will stay, however the mannequin will start to supply extra numerous and inventive titles.
- Excessive penalty (2.0): The primary three titles are nonetheless the identical, however the mannequin then produces numerous, distinctive, and imaginative e-book names (e.g., “Whisperwind Chronicles: Rise of the Phoenix Queen,” “Ashes Beneath the Willow Tree”).
presence penalty
Presence penalty controls how a lot the mannequin avoids repeating phrases or phrases that already seem within the textual content.
- Vary: -2 to 2
- Default: 0
The next presence penalty forces the mannequin to make use of extra numerous phrases, making the output extra numerous and inventive.
Not like frequency penalties, which accumulate with every repetition, presence penalties are utilized as soon as to phrases which have already occurred, making them much less prone to be repeated within the output. This permits the mannequin to generate textual content with extra selection and originality.
immediate = "Listing 10 potential titles for a fantasy e-book. Give the titles solely and every title on a brand new line."
presence_penalties = [-2.0, -1.0, 0.0, 0.5, 1.0, 1.5, 2.0]
outcomes = {}
for fp in frequency_penalties:
response = shopper.chat.completions.create(
mannequin=mannequin,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
presence_penalty=fp,
temperature=0.2
)
textual content = response.decisions[0].message.content material
gadgets = [line.strip("- ").strip() for line in text.split("n") if line.strip()]
outcomes[fp] = gadgets
# Show outcomes
for fp, gadgets in outcomes.gadgets():
print(f"n--- presence_penalties = {fp} ---")
print(gadgets)
- Low to medium penalty (-2.0 to 0.5)): The titles are considerably various, repeating some frequent fantasy patterns, comparable to “Oath of the Shadowweaver,” “Inheritor of the Final Dragon,” and “Crown of Embers and Ice.”
- Medium penalty (1.0 to 1.5): The primary few widespread titles stay, however later titles present extra creativity and distinctive mixtures. Examples: “Ashes of the Misplaced Kingdom”, “Secret of the Starbound Forest”, “Daughter of Storm and Stone”.
- Most penalty (2.0): The highest three titles will stay the identical, however the remaining might be very numerous and imaginative. Examples: “Moonfire and Thorns”, “Starlight Veil of Ashes”, “Midnight Blade”.
Please verify Full code here. Please be happy to test it out GitHub page for tutorials, code, and notebooks. Please be happy to comply with us too Twitter Do not forget to affix us 100,000+ ML subreddits and subscribe our newsletter. hold on! Are you on telegram? You can now also participate by telegram.

I’m a Civil Engineering graduate from Jamia Millia Islamia, New Delhi (2022) and have a powerful curiosity in information science, particularly neural networks and their functions in varied fields.

{kind=link}