


Put up-training reinforcement studying RL is now the go-to technique for inference-centric LLMs, however in contrast to pre-training, predictive Scaling guidelines. Groups are pouring tens of hundreds of GPU hours into executions and not using a principled option to estimate whether or not their recipes will proceed to enhance with elevated compute. New analysis from Meta, UT Austin, UCL, Berkeley, Harvard, and Periodic Labs computing efficiency framework—Verified >400,000 GPU hours—This fashions the development of RL. sigmoid curve Offers examined recipes, scale RLcomply with these prediction curves to the subsequent level. 100,000 GPU hours.
Apply a sigmoid as an alternative of an influence regulation
Pre-training typically follows an influence regulation (loss versus computation) match. RL fine-tuning goal restricted metrics (e.g. acceptance fee/common compensation). What the analysis workforce confirmed sigmoid match to Evaluating go charges and coaching computing empirically extra strong and secure The ability regulation applies particularly if you wish to: extrapolate from smaller runs For a much bigger price range. These exclude very early noisy regimes (~first 1.5k GPU hours) to use the predictable half that follows. The sigmoid parameter has an intuitive function. Asymptotic efficiency (ceiling)the opposite is effectivity/indexand the opposite is halfway level The place the achieve is quickest.
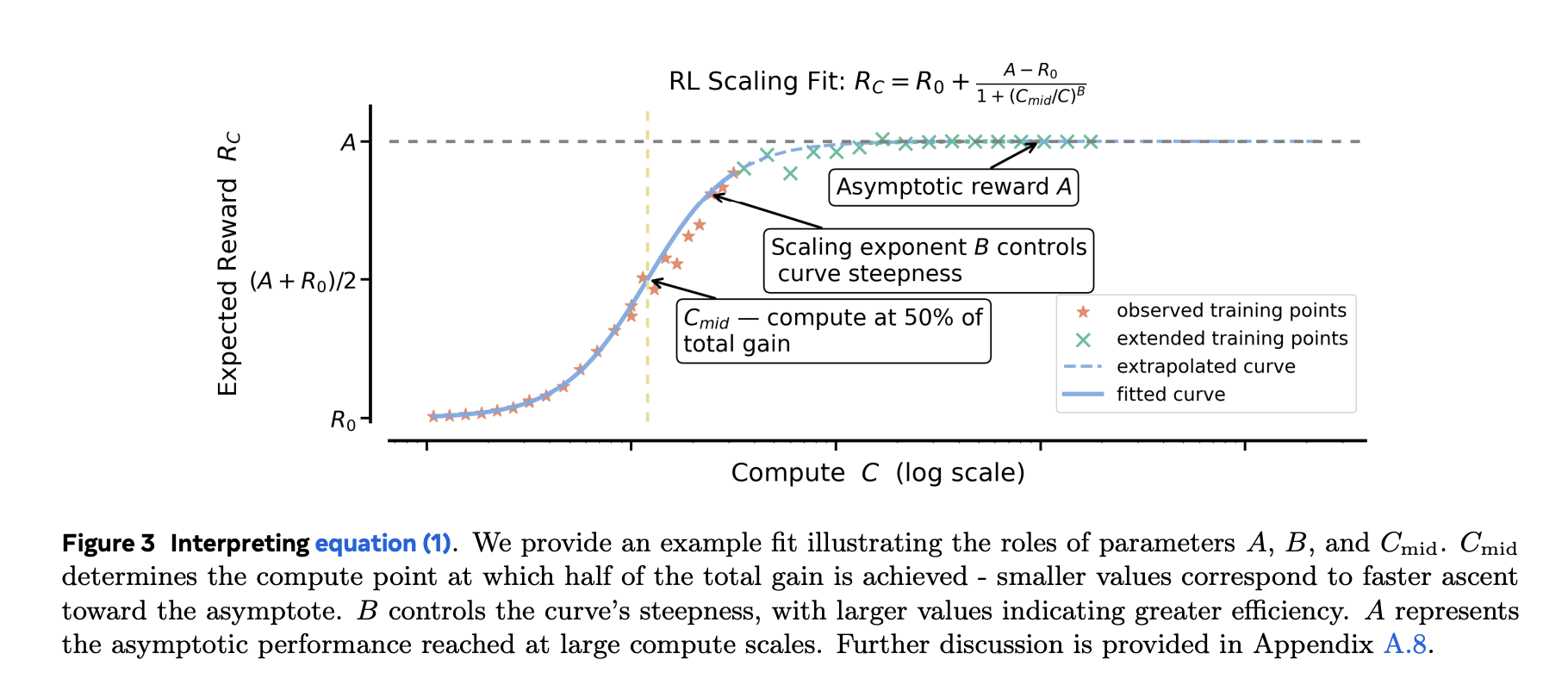
Why it is vital: After about 1-2,000 GPU hours, you may match a curve to foretell whether or not it is price going as much as 10,000-100,000 GPU hours.in entrance It’s going to blow your price range. This research additionally exhibits that power-law becoming can result in deceptive higher bounds, which defeats the aim of early prediction, until fitted solely at very excessive compute.
ScaleRL: A recipe for predictably scaling
ScaleRL is greater than only a new algorithm. it’s Configuration of selections This research yielded secure and extrapolable scaling.
- Asynchronous pipeline RL (cut up generator and coach between GPUs) to realize off-policy throughput.
- Syspo Compute (truncated significance sampling REINFORCE) because the RL loss.
- FP32 accuracy in logits To keep away from discrepancies in numbers between generator and coach.
- Immediate-level loss averaging and Batch-level profit normalization.
- Compelled size interruption Cap the traces of runaway.
- Zero variance filtering (Take away prompts that don’t present slope indicators).
- No constructive resampling (Removes excessive go fee prompts above 0.9 from later epochs).
The analysis workforce examined every element within the following methods: Go away-one-out (LOO) ablation in 16,000 GPU hours Signifies that the curve in ScaleRL is a dependable match extrapolate from 8k → 16kafter which persist at bigger scales (corresponding to extending a single run to the subsequent vary). 100k GPU hours.
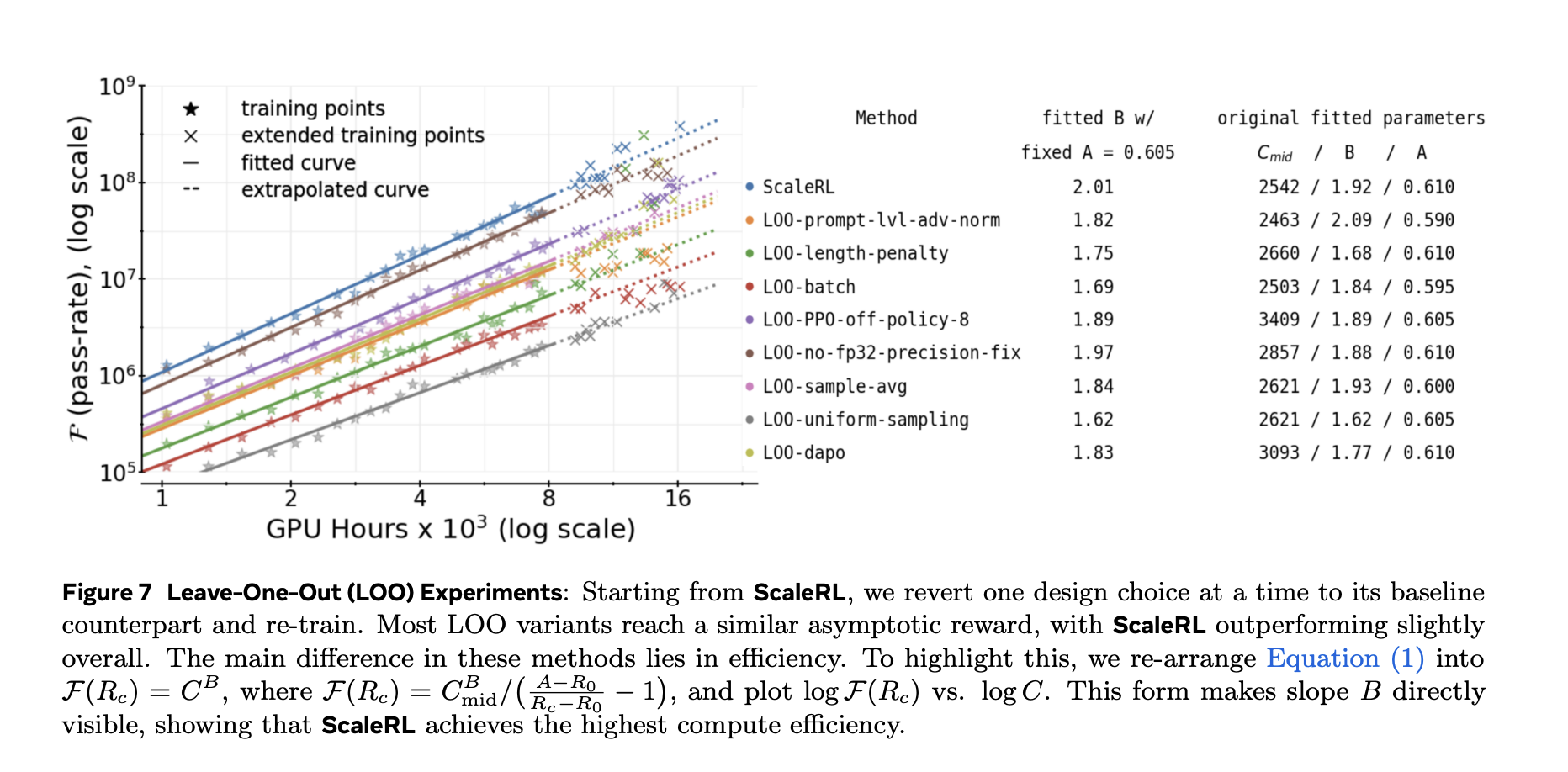
Outcomes and generalization
Two vital demonstrations:
- Predictability at scale: for 8B dense mannequin and Rama-4 17B×16 MoE (“Scout”), prolonged coaching adopted carefully sigmoid extrapolation Derived from the small computing phase.
- downstream switch: Enhancing go fee of IID validation set monitoring Downstream analysis (e.g. AIME-24), suggesting that the computing efficiency curve isn’t an artifact of the dataset.
The research additionally compares trendlines for widespread recipes, e.g. DeepSeek (GRPO), Qwen-2.5 (DAPO), Magistral, MiniMax-M1) and report Asymptotic efficiency and computational effectivity enhancements For ScaleRL in your setup.
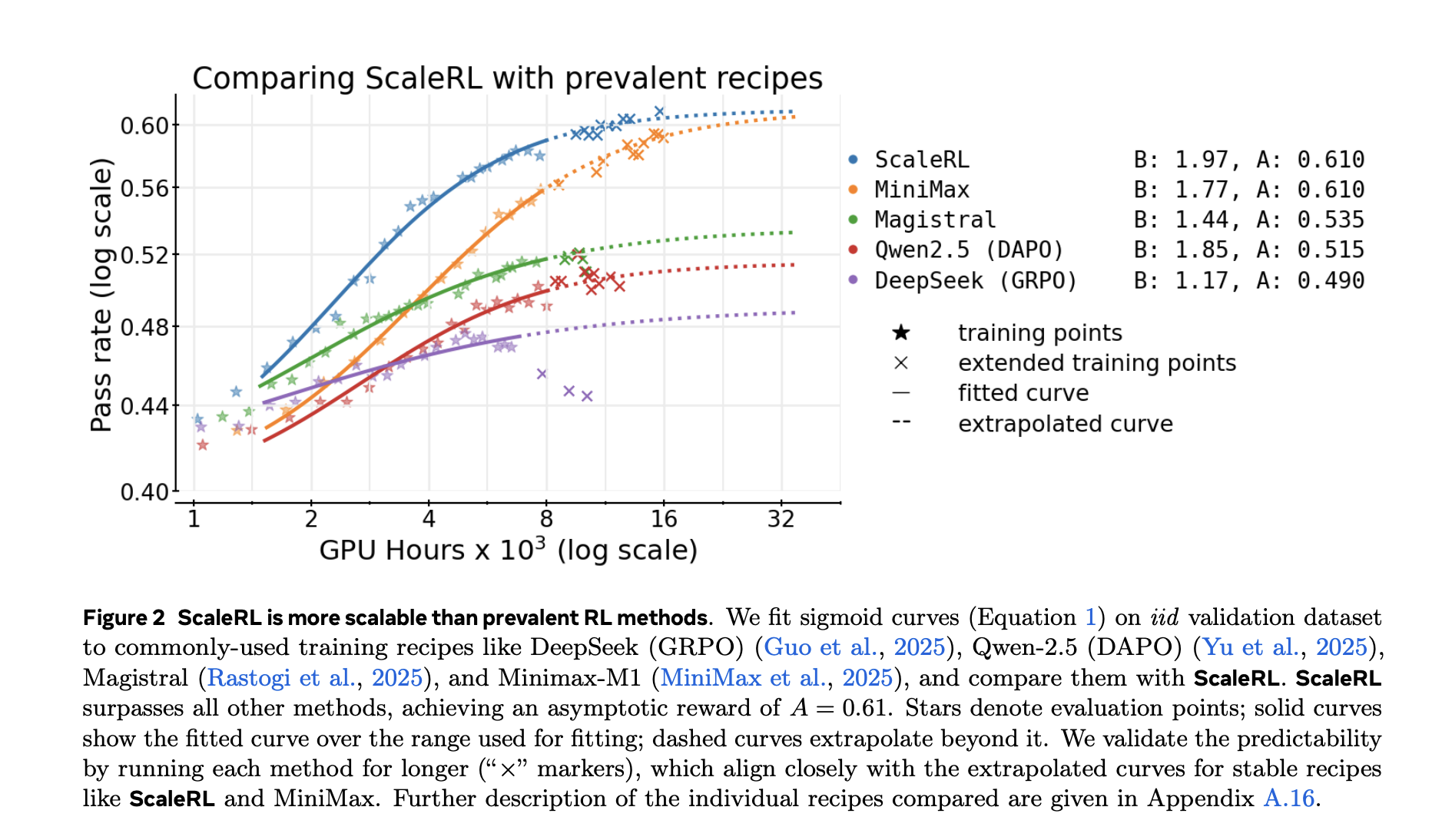
Which knob strikes the ceiling relative to effectivity?
This framework lets you categorize your design selections.
- Ceiling shifter (asymptotes): scaling mannequin dimension (e.g. MoE) and longer era size (to 32,768 tokens) elevate asymptotic Improves efficiency, however could gradual preliminary progress. larger world batch dimension It’s also possible to elevate the ultimate asymptote to stabilize your coaching.
- Effectivity shaper: Aggregation of losses, Profit normalization, information curriculum,and Pipeline exterior coverage change primarily how briskly Transfer nearer to the ceiling, not on the ceiling itself.
Operationally, the analysis workforce advises: Match the curve early and, sealingAfter adjusting the effectivity Knobs can help you attain sooner with fastened computing.
Necessary factors
- The analysis workforce fashions progress after RL coaching as follows. Sigmoid computing efficiency curve (go fee vs. log calculation), which permits for dependable extrapolation, in contrast to energy legal guidelines for restricted metrics.
- greatest observe recipes, scale RLmix pipeline RL-k (asynchronous generator – coach), Syspo loss, FP32 logitprompt-level aggregation, profit normalization, interruption-based size management, zero-variance filtering, and non-positive resampling.
- The analysis workforce used these diversifications to predicted and matched prolonged run as much as 100k GPU hours (8B density) and~50k GPU hours (17B×16 MoE “Scout”) In regards to the validation curve.
- Ablation Present some choices and Asymptotic ceiling (A) (e.g. mannequin scale, longer era lengths, bigger world batches), different options are primarily improved. Computational effectivity (B) (e.g. aggregation/normalization, curriculum, pipelines exterior of coverage).
- The framework gives early prediction Deciding whether or not to scale executions and enhancing in-distribution validation Monitor downstream metrics (e.g., AIME-24), supporting exterior validity.
This effort transforms post-training RL from trial and error to predictable engineering. Match a sigmoid compute efficiency curve (go fee vs. log compute) to foretell returns and determine when to cease or scale. We additionally present a concrete recipe, ScaleRL, that makes use of PipelineRL-style asynchronous era/coaching, CISPO loss, and FP32 logit for stability. This research studies over 400,000 GPU hours of experiments and scaling to 100,000 GPU hours in a single run. The outcomes help a transparent division. For some selections the asymptotes rise. Others primarily enhance computational effectivity. This separation permits the workforce to prioritize modifications that exceed the cap earlier than adjusting the throughput knob.
Please verify paper. Please be at liberty to test it out GitHub page for tutorials, code, and notebooks. Please be at liberty to comply with us too Twitter Remember to affix us 100,000+ ML subreddits and subscribe our newsletter. dangle on! Are you on telegram? You can now also participate by telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of synthetic intelligence for social good. His newest endeavor is the launch of Marktechpost, a man-made intelligence media platform. It stands out for its thorough protection of machine studying and deep studying information, which is technically sound and simply understood by a large viewers. The platform boasts over 2 million views per 30 days, demonstrating its recognition amongst viewers.

{kind=link}